目录
- 1.了解static吗,static数据存在哪?生命周期什么样的
- 2.了解final吗,讲讲下面这段代码的结果
- 3.讲讲volatile吧
- 4.讲讲两个锁的区别(reentrantlock和synchronized)
- 5.讲讲线程池里线程的创建与销毁,核心线程可以销毁吗?
- 6.高并发怎么减少锁的竞争
- 7.了解类加载机制吗,讲讲下面这段代码运行结果
- 8.hashMap为什么大小是幂次
- 9.euqal和==的区别,equal没有重写的时候默认是什么
- 10.写个sql吧,学号 学生姓名 科目 成绩 班级,选出每个班的每个科目最高分
- 11.linux的tail -f命令里的f是什么意思
- 12.用过grep吗,会正则吗
- 13.mysql 事务的特性
- 14.char和varchar的区别
- 15.如果我一个字段是char(10),我只存三个字节进去,它底层文件占几个字节
- 16.计算机网络:TCP如何保证数据包不丢、不重、不乱、完整性
- 17.arraylist调api找里面值为10的下标
- 18.自动拆箱装箱了解吗
1.了解static吗,static数据存在哪?生命周期什么样的
存放: 静态变量存放在方法区中,并且是被所有线程所共享的
生命周期: 静态变量随着类的加载而加载,也意味着随着类的消失而消失
类的加载经历了5个过程(装载,链接,初始化,使用,卸载)
2.了解final吗,讲讲下面这段代码的结果
String s = "hello2";
final String s2 = "hello";
String s3 = s2+2;
System.out.println(s==s3);
true
常量和常量相加还是常量,并且在串池中,final关键字修饰后则会在编译期就解析为一个常量值放到常量池中
拓展
String s = "hello2";
String s1 = "hello";
String s2 = "2"
String s3 = s1 + s2;
System.out.println(s==s3);
在栈中存在s,s指向字符串常量池中的hello2
在栈中存在s1,s1指向字符串常量池中的hello
在栈中存在s2,s2指向字符串常量池中的2
在栈中存放s3,而s1+s2则会通过StringBuilder中的toString()方法在堆中创建一个hello2
这时就可以看出来s指向字符串常量池中的hello2,而s3则指向堆中的hello2
3.讲讲volatile吧
1.volatile是什么?
volatile是一个轻量级的synchronized,一般作用于变量,在多处理器开发的过程中保证了内存的可见性。相比于synchronized关键字,volatile关键字的执行成本更低,效率更高。
2.volatile的特性有哪些?
可见性,有序性(从这两个点依次去答)
3.java内存中可见性的问题
JMM(Java内存模型Java Memory Model,简称JMM)本身是一种抽象的概念并不真实存在

代码展示
public class VolatileSeeDemo {//static boolean flag = true; //不加volatile,没有可见性static volatile boolean flag = true; //加了volatile,保证可见性public static void main(String[] args) {new Thread(() -> {System.out.println(Thread.currentThread().getName() + "\t come in");while (flag) {}System.out.println(Thread.currentThread().getName() + "\t flag被修改为false,退出.....");}, "t1").start();//暂停2秒钟后让main线程修改flag值try {TimeUnit.SECONDS.sleep(2);} catch (InterruptedException e) {e.printStackTrace();}flag = false;System.out.println("main线程修改完成");}
}
问题可能:
- 主线程修改了flag之后没有将其刷新到主内存,所以t1线程看不到。
- 主线程将flag刷新到了主内存,但是t1一直读取的是自己工作内存中flag的值,没有去主内存中更新获取flag最新的值。
我们的诉求:
- 线程中修改了工作内存中的副本之后,立即将其刷新到主内存;
- 工作内存中每次读取共享变量时,都去主内存中重新读取,然后拷贝到工作内存。
解决:
使用volatile修饰共享变量,就可以达到上面的效果,被volatile修改的变量有以下特点:
- 线程中读取的时候,每次读取都会去主内存中读取共享变量最新的值,然后将其复制到工作内存
- 线程中修改了工作内存中变量的副本,修改之后会立即刷新到主内存
4.volatile为啥不具有原子性
volatile变量的复合操作(如i++)不具有原子性
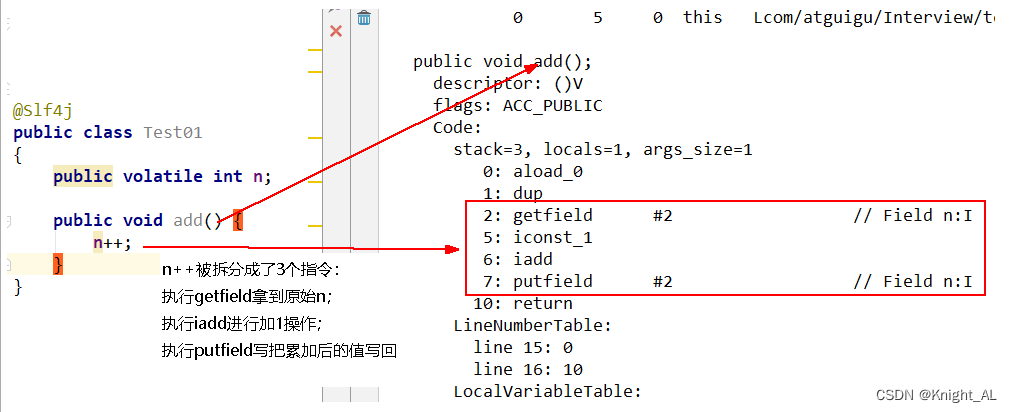
原子性指的是一个操作是不可中断的,即使是在多线程环境下,一个操作一旦开始就不会被其他线程影响。
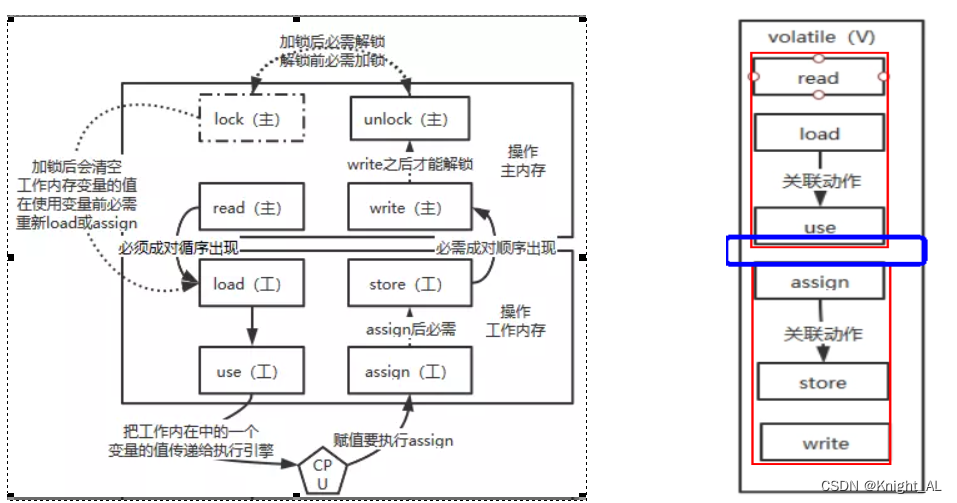
volatile变量的读写过程
read(读取)→load(加载)→use(使用)→assign(赋值)→store(存储)→write(写入)→lock(锁定)→unlock(解锁)
read: 作用于主内存,将变量的值从主内存传输到工作内存,主内存到工作内存
load: 作用于工作内存,将read从主内存传输的变量值放入工作内存变量副本中,即数据加载
use: 作用于工作内存,将工作内存变量副本的值传递给执行引擎,每当JVM遇到需要该变量的字节码指令时会执行该操作
assign: 作用于工作内存,将从执行引擎接收到的值赋值给工作内存变量,每当JVM遇到一个给变量赋值字节码指令时会执行该操作
store: 作用于工作内存,将赋值完毕的工作变量的值写回给主内存
write: 作用于主内存,将store传输过来的变量值赋值给主内存中的变量
由于上述只能保证单条指令的原子性,针对多条指令的组合性原子保证,没有大面积加锁,所以,JVM提供了另外两个原子指令:
lock: 作用于主内存,将一个变量标记为一个线程独占的状态,只是写时候加锁,就只是锁了写变量的过程。
unlock: 作用于主内存,把一个处于锁定状态的变量释放,然后才能被其他线程占用
5.指令禁重排
重排序是指编译器和处理器为了优化程序性能而对指令序列进行重新排序的一种手段,有时候会改变程序语句的先后顺序
不存在数据依赖关系,可以重排序;
存在数据依赖关系,禁止重排序;

编译器优化的重排序: 编译器在不改变单线程串行语义的前提下,可以重新调整指令的执行顺序
指令级并行的重排序: 处理器使用指令级并行技术来讲多条指令重叠执行,若不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序
内存系统的重排序: 由于处理器使用缓存和读/写缓冲区,这使得加载和存储操作看上去可能是乱序执行
案例 :
不存在数据依赖关系,可以重排序===> 重排序OK 。

存在数据依赖关系,禁止重排序===> 重排序发生,会导致程序运行结果不同。

6.重排序会引发什么问题?
在单线程程序中,重排序并不会影响程序的运行结果,而在多线程场景下就不一定了。
class ReorderExample{int a = 0;boolean flag = false;public void writer(){a = 1; // 操作1flag = true; // 操作2}public void reader(){if(flag){ // 操作3int i = a + a; // 操作4}}
}
假设线程1先执行writer()方法,随后线程2执行reader()方法,最后程序一定会得到正确的结果吗?
答案是不一定的,如果代码按照下图的执行顺序执行代码则会出现问题。
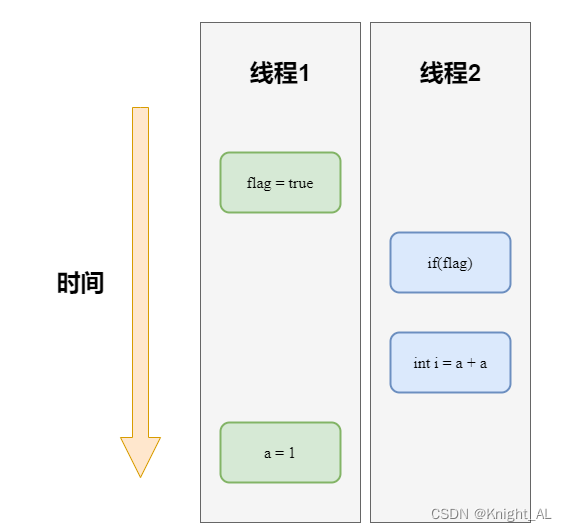
操作1和操作2进行了重排序,线程1先执行flag=true,然后线程2执行操作3和操作4,线程2执行操作4时不能正确读取到a的值,导致最终程序运行结果出问题。这也说明了在多线程代码中,重排序会破坏多线程程序的语义。
7.happens-before规则的区别?

1.当第一个操作为volatile读时,不论第二个操作是什么,都不能重排序。这个操作保证了volatile读之后的操作不会被重排到volatile读之前。
2.当第二个操作为volatile写时,不论第一个操作是什么,都不能重排序。这个操作保证了volatile写之前的操作不会被重排到volatile写之后。
3.当第一个操作为volatile写时,第二个操作为volatile读时,不能重排。
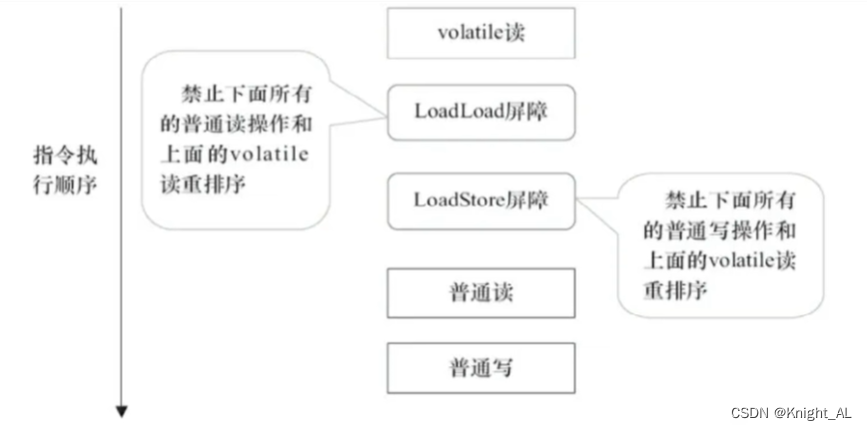
8.Java虚拟机插入内存屏障的策略
读屏障
- 在每个 volatile 读操作的后⾯插⼊⼀个 LoadLoad 屏障
- 在每个 volatile 读操作的后⾯插⼊⼀个 LoadStore 屏障
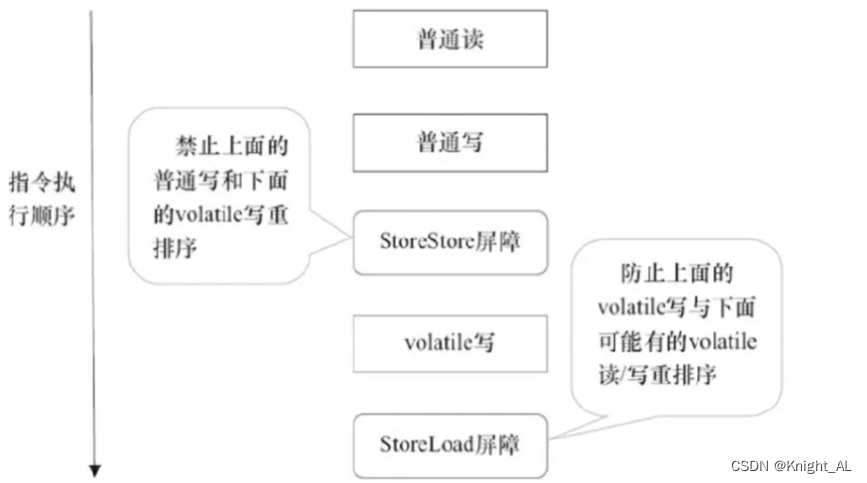
写屏障
- 在每个 volatile 写操作的前⾯插⼊⼀个 StoreStore 屏障
- 在每个 volatile 写操作的后⾯插⼊⼀个 StoreLoad 屏障
加StoreStore位是为保证所有普通写操作都已经刷新到主内存了
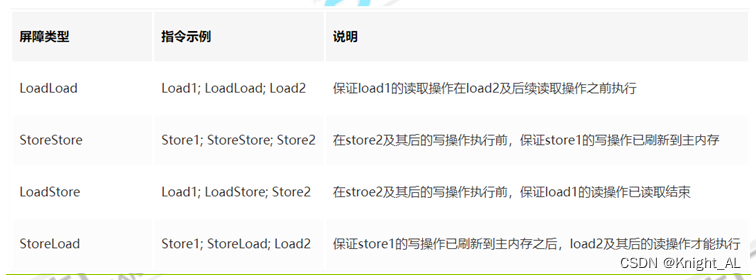
总结

4.讲讲两个锁的区别(reentrantlock和synchronized)
底层实现
- synchronized是JVM层面的锁,也是Java的关键字,通过monitor对象进行完成的。ReentrantLock是JDK提供的API层面的锁
是否需要手动释放
- synchronized不需要用户去手动释放锁,ReentrantLock则需要用户去手动释放锁(lock和unlock)。
是否可中断
- synchronized是不可中断类型的锁,ReentrantLock是可以中断的
是否可以绑定多个条件
- ReentrantLock可以同时绑定多个Condition对象,只需多次调用newCondition方法即可。
- synchronized中,锁对象的wait()和notify()或notifyAll()方法可以实现一个隐含的条件。但如果要和多于一个的条件关联的时候,就不得不额外添加一个锁。
公平锁
- synchronized的锁是非公平锁,ReentrantLock默认情况下也是非公平锁,但可以通过带布尔值的构造函数要求使用公平锁。
5.讲讲线程池里线程的创建与销毁,核心线程可以销毁吗?
线程池的创建:
线程池的常用创建方式主要有两种,通过Executors工厂方法创建和通过new ThreadPoolExecutor方法创建。
Executors工厂方法创建,在工具类 Executors 提供了一些静态的工厂方法
- newSingleThreadExecutor:创建一个单线程的线程池。
- newFixedThreadPool:创建固定大小的线程池。
- newCachedThreadPool:创建一个可缓存的线程池。
- newScheduledThreadPool:创建一个大小无限的线程池。
new ThreadPoolExecutor 方法创建:
- 通过newThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue workQueue,ThreadFactory threadFactory,RejectedExecutionHandler handler)自定义创建
线程池的关闭:
线程池的关闭可以调用线程池中的shutdown或shutdownNow方法进行关闭,它们会遍历线程池中的工作线程,然后调用每个线程的interrupt方法来中断线程。
核心线程可以销毁吗?
在 runWorker 方法中,首先会去执行创建这个 worker 时就有的任务,当执行完这个任务之后, worker 并不会被销毁,而是在 while 循环中, worker 会不断的调用 getTask 方法从阻塞队列中获取任务然后调用 task。run() 来执行任务,这样就达到了复用线程的目的。通过循环条件 while (task != null || (task = getTask()) != null) 可以看出,只要 getTask 方法返回值不为 null ,就会一直循环下去,这个线程也就会一直在执行,从而达到了线程复用的目的
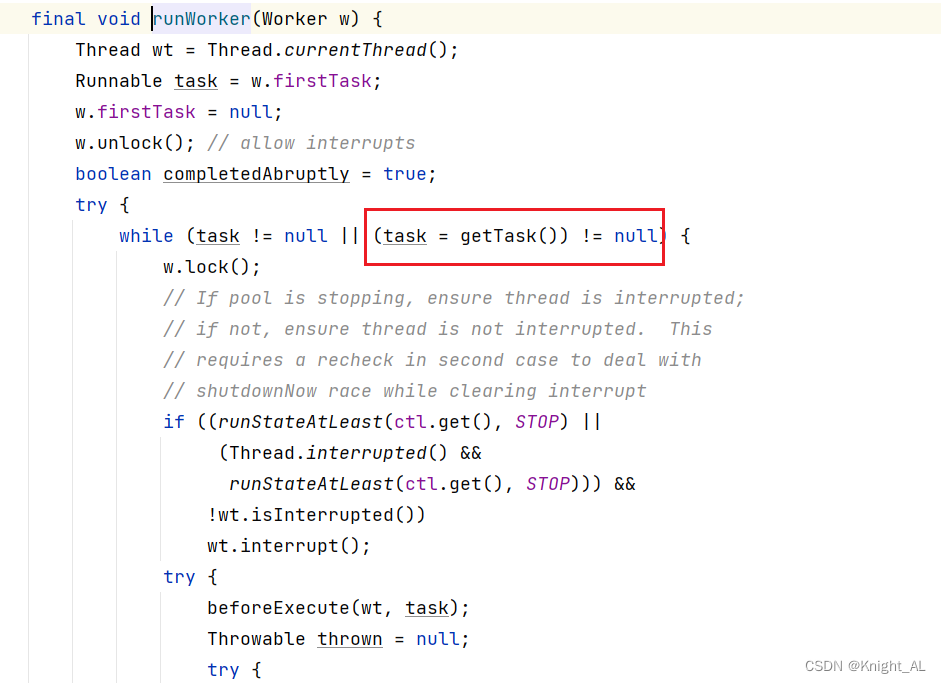
task!=null可能是false
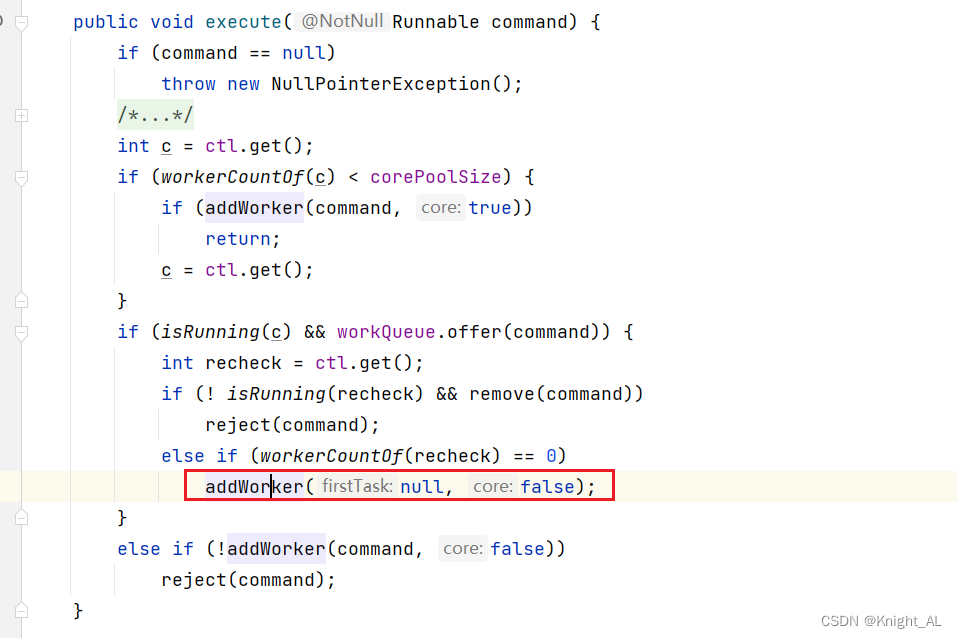
getTask()为啥会一直不为null
allowCoreThreadTimeOut默认为false
allowCoreThreadTimeOut为true该值为true,则线程池数量最后销毁到0个。
那么timed为false
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
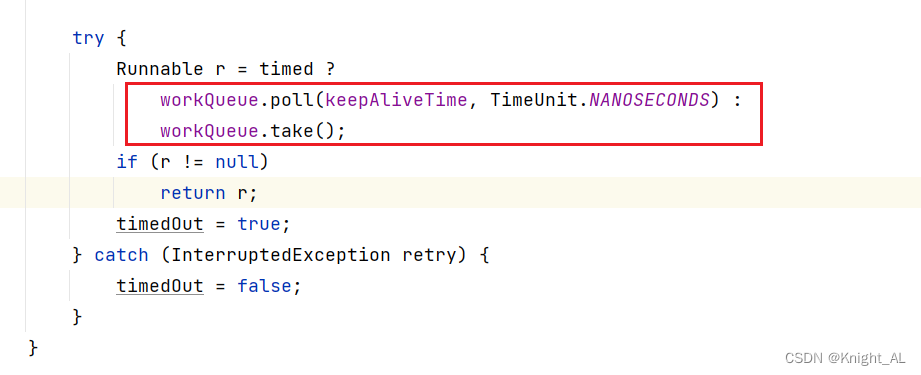
接下来我们会走take方法
poll:移除方法,成功返回出队列的元素,队列里没有就返回null
take:当阻塞队列空时,消费者线程试图从队列里take元素,队列会一直阻塞消费者线程直到队列可用
6.高并发怎么减少锁的竞争
减少锁的持有时间。
减少锁粒度。
锁分离。
锁粗化。
锁消除。
7.了解类加载机制吗,讲讲下面这段代码运行结果
class Father {private String a = "father";public Father() {say();}public void say() {System.out.println("i'm father" + a);}
}
class Sub extends Father {private String a = "child";@Overridepublic void say() {System.out.println("i'm child" + a);}
}
public class Test {public static void main(String[] args) {Father father = new Father();Sub sub = new Sub();}
}
类的加载机制:虚拟机把描述类的数据从class文件加载到内存,并对数据进行校验,转换解析和初始化,最终形成可以被虚拟机直接使用的Java类型,这就是虚拟机的类加载机制。
i'm fatherfather
i'm childnull
大家可以先记住代码执行顺序:
静态代码块(父) > 静态代码块(子) > 实例成员变量(父) > 构造代码块(父) > 构造方法(父) > 实例成员变量(子) > 构造代码块(子) > 构造方法(子)
Father father = new Father();—>private String a = “father”;—>public Father( { say() ;}—>执行say()方法,结果为i’m fatherfather
Sub sub = new Sub();—>private String a = “father”;—>public Father( { say() ;}—>调用子类的say()方法,因为子类的实例成员变量并未初始化,所以结果为i’m childnull
8.hashMap为什么大小是幂次
为了加快哈希计算以及减少哈希冲突
index = HashCode(Key) & (Length - 1)
下面我们以“book”的Key来演示整个过程:
1.计算book的hashcode,结果为十进制的3029737,二进制的101110001110101110 1001。
2.假定HashMap长度是默认的16,计算Length-1的结果为十进制的15,二进制的1111。
3.把以上两个结果做与运算,101110001110101110 1001 & 1111 = 1001,十进制是9,所以 index=9。
可以说,Hash算法最终得到的index结果,完全取决于Key的Hashcode值的最后几位。
9.euqal和==的区别,equal没有重写的时候默认是什么
==
对于基本数据类型, == 比较的是值;对于引用数据类型,== 比较的是内存地址。
eauals
对于没有重写equals方法的类,equals方法和== 作用类似;对于重写过equals方法的类,equals比较的是值。
如果没有重写equal(),那么equals和 == 的作用相同,比较的是对象的地址值。
基本类型包括:byte,short,int,long,char,float,double,Boolean,returnAddress,
引用类型包括:类类型,接口类型和数组。
10.写个sql吧,学号 学生姓名 科目 成绩 班级,选出每个班的每个科目最高分
select max(成绩) from 表名 group by 班级,科目
11.linux的tail -f命令里的f是什么意思
tail(尾巴的意思),用来查看文件最后几行的数据,默认是10行
tail -f filename 会把 filename 文件里的最尾部的内容显示在屏幕上,并且不断刷新,只要 filename 更新就可以看到最新的文件内容。
12.用过grep吗,会正则吗
grep是一个文本过滤器,作用是在文件中查找符合我们要求的内容。
13.mysql 事务的特性
原子性:原子性是指包含事务的操作要么全部执行成功,要么全部失败回滚。
一致性:一致性指事务在执行前后状态是一致的。
隔离性:一个事务所进行的修改在最终提交之前,对其他事务是不可见的。
持久性:数据一旦提交,其所作的修改将永久地保存到数据库中。
14.char和varchar的区别
字符串常用的主要有CHAR和VARCHAR,VARCHAR主要用于存储可变长字符串,相比于定长的CHAR更节省空间。CHAR是定长的,根据定义的字符串长度分配空间。

15.如果我一个字段是char(10),我只存三个字节进去,它底层文件占几个字节
10个,剩余七个会用空格填充。
16.计算机网络:TCP如何保证数据包不丢、不重、不乱、完整性
后续更新
17.arraylist调api找里面值为10的下标
indexOf
18.自动拆箱装箱了解吗
装箱:将基本类型用包装器类型包装起来
拆箱:将包装器类型转换为基本类型