摘要
基于案例的推理(CBR)系统通过检索与给定问题相似的“案例”来解决新问题。如果这样一个系统能够达到很高的精度,它就会因为它的简单性、可解释性和可扩展性而具有吸引力。
在本文中,我们证明了这样一个系统是可实现的推理知识库(KBs)。我们的方法通过从知识库中相似的实体收集推理路径来预测实体的属性。我们的概率模型估计了一条路径在回答关于给定实体的查询时有效的可能性。利用简单的路径统计可以有效地计算出模型的参数,不需要迭代优化。我们的模型是非参数的,随着新的实体和关系被添加到知识库中而动态增长。在多个基准数据集上,我们的方法明显优于其他规则学习方法,并且与最先进的基于嵌入的方法相比表现相当。此外,我们在一个“开放世界”环境中演示了我们模型的有效性,在这个环境中,新实体以在线方式到达,其性能明显优于最先进的方法,几乎与最好的离线方法相匹配。
1Code available at https://github.com/ameyagodbole/Prob-CBR
1.介绍
我们生活在一个不断进化的世界里,有很多异质性,也有不断创造的新实体。例如,描述新实体事实的科学论文和维基百科页面正在不断添加(如COVID-19)。这些新发现进一步引发了对新的事实的推断,每个事实都有自己不同的推理。我们有兴趣为大知识库(KBs)开发这种自动推理系统。
在机器学习中,非参数方法有望处理不断变化的数据(Coverand Hart, 1967;拉斯穆森,2000)。目前大多数KG完形模型通过张量分解或复杂的神经方法学习实体和关系的低维参数表示(Nickel et al., 2011;Bordes等,2013;Socher等,2013;孙等,2019;V ashishth等人,2020年)。另一项工作是从KG中学习Hornclause风格的推理规则,并将它们存储在其参数中(Rockt¨aschel和Riedel, 2017;Das et al., 2018;Minervini等人,2020年)。然而,这些参数化的方法与一组固定的实体一起工作,目前还不清楚这些模型将如何适应新的实体。
本文提出了一种基于k近邻(KNN)的KG推理方法,这让人联想到经典人工智能中的基于案例推理(CBR)。CBR系统通过检索与给定问题相似的“案例”来解决新问题,根据检索到的案例修改解决方案(如有必要),并将其用于新问题(Schank, 1982;1996年,尤其Leake)。对于给定源实体和二元KG关系(如图1中的JOHN VON NEUMAN, PLACE of DEATH, ?)的目标实体查找任务,我们的方法首先检索k个与查询实体相似的实体(案例)。接下来,对于每个检索到的实体,它找到多个KG路径(每个路径是检索到的情况的一个解决方案),到由查询关系连接的实体(例如(RICHARDFEYNMAN, USA)之间的路径)。然而,一个解决方案很少适用于所有查询。例如,尽管路径“出生在”可以预测美国出生的科学家的“死亡地点”(图1),但它并不适用于移民到美国的科学家。为了处理这个问题,我们提出了一种概率CBR方法,该方法学会在给定查询的情况下,根据其先验和精度的估计来对路径进行加权。路径的先验表示其频率,而精度表示该路径将导向正确答案实体的可能性。为了获得路径参数的可靠估计,我们将相似的实体聚在一起,并通过简单的计数统计来计算它们(§2.2.3)
 图1:给定查询(JON VON NEUMANN, PLACE OF DEATH, ?),我们的模型从类似实体(如其他科学家)收集推理路径。然而,并非所有收集的路径都适用于查询,例如路径(' BORN(x, y) ')不适用于VON NEUMANN。这突出了学习类似实体集群的路径权重的重要性。尽管“BORN”可能是PLACE OF DEATH的合理路径,但这并不适用于VON NEUMANN和他的集群中的其他科学家。给定集群的路径的精度参数有助于惩罚“BORN in”路径。注意,节点USA在图中重复了两次,以减少混乱。
图1:给定查询(JON VON NEUMANN, PLACE OF DEATH, ?),我们的模型从类似实体(如其他科学家)收集推理路径。然而,并非所有收集的路径都适用于查询,例如路径(' BORN(x, y) ')不适用于VON NEUMANN。这突出了学习类似实体集群的路径权重的重要性。尽管“BORN”可能是PLACE OF DEATH的合理路径,但这并不适用于VON NEUMANN和他的集群中的其他科学家。给定集群的路径的精度参数有助于惩罚“BORN in”路径。注意,节点USA在图中重复了两次,以减少混乱。
Go for a walk and arrive at the answer: Reasoning over paths in knowledge bases using reinforcement learning
Differentiable reasoning on large knowledge bases and natural language
Asimple approach to case-based reasoning in knowledge bases
看看这些模型是否可以动态添加
除了计算这些估计之外,我们的方法不需要进一步训练。总体而言,我们的简单方法优于最近的几种参数规则学习方法(Das等人,2018;Minervini等人,2020年),并在多个数据集上与各种最先进的KG补全方法(Dettmers等人,2018年)具有竞争力。
非参数模型的一个优点是它可以通过调整参数的数量来适应不断增长的数据。本着同样的精神,我们展示了我们的模型可以无缝地处理新实体进入KG的“开放世界”设置。这可以通过几个设计选择实现,例如(a)将实体表示为其关系类型的稀疏(非学习的)向量(§2.2.1),(b)使用在线非参数分层聚类算法(Monath等人,2019),该算法可以有效地重新计算由于新添加的实体而导致的集群分配的变化(§2.3),(c)重新计算每个集群路径的先验和精度参数的简单而有效的方法(§2.2.3)。
目前的KG补全模型学习固定实体集的实体表示,无法处理开放世界设置。事实上,我们证明了,不断用新数据重新训练模型会导致模型性能的严重退化,因为模型会忘记它之前学到的东西。例如,在此设置下,ROTATE模型(Sun等人,2019)的性能(MRR)在WN18RR上下降了11点(绝对)(§3.4)。另一方面,我们表明,对于新数据,我们的模型的性能是一致的,因为它能够与新到达的数据无缝推理。
我们的工作与Das等人(2020)最近的一项并发工作密切相关,他们提出了一个从类似于查询实体的实体收集路径的模型。然而,Das等人(2020)鼓励在KG中频繁出现的路径,并且不学习对查询的路径进行不同的权衡。这通常会导致错误的推断,从而导致低性能。例如,在FB122的test-II评估子集上,所有三元组都可以通过逻辑规则推断出来,Das等人(2020)由于学习错误的规则,得分很低(MRR 63)。另一方面,我们的评分明显更高(94.83 MRR),表明我们可以学习更有效的规则。事实上,我们在几个基准数据集上的表现一直显著优于Das等人(2020)。此外,与我们不同的是,它们不会在具有挑战性的开放世界环境中进行自我测试。
本文的贡献如下:(a)我们提出了一种基于KNN的KG补全方法,从与查询实体相似的实体中收集推理路径。遵循原则性的概率方法(§2.2),我们的模型根据每条路径获得正确答案的可能性来衡量其权重,从而惩罚本质上虚假的路径。(b)我们的模型的参数随着数据的增长而增长,可以使用简单的计数统计有效地估计(§2.3)。除此之外,我们的方法不需要训练。我们表明,我们的简单方法显著优于各种规则学习方法(Das等人,2018;Minervini等人,2020年;Das等人,2020)在许多基准数据集上。(c)我们还表明,我们的模型可以轻松地处理关于新实体的事实的添加,并能够与新添加的数据无缝集成和推理,显著优于基于参数嵌入的模型。
2 Non-parametric Reasoning in KGs
2.1 Notation and Task Description

2.2 Model
给定一个查询,我们的方法从与查询实体相似的实体中收集KG路径类型。每一种路径类型都根据其频率和精度的估计进行加权(§2.2.1)。通过将相似的实体聚类在一起(§2.2.2),我们的模型获得了路径统计的鲁棒估计(§2.2.3)。我们的方法是非参数的,因为 (a)不是将推理规则存储在参数中(Das et al., 2018;Minervini等人,2020),它从k-相似实体(如非参数k-nn分类器(Cover和Hart, 1967))动态地派生它们。(b)我们使用非参数聚类方法将实体聚类在一起,并提供了在将实体添加到KG中时添加/估计参数的有效方法(§2.3)。
2.2.1上下文实体推理
我们的方法首先找到k个与查询实体相似的实体,这些实体至少具有rq类型的边。例如,对于查询(MELINDA GATES, work IN CITY, ?),如果我们观察(WARREN BUFFET, work IN CITY, OMAHA),我们会考虑WARREN BUFFET。我们将这些实体称为“上下文实体”。每个实体都表示为其传出边类型的稀疏向量,即![]() 。如果实体ei有m个不同的传出边类型,那么与这些类型对应的维度被设置为1。这是一种非常简单和灵活的表示实体的方法,我们发现它工作得很好。还要注意的是,随着关于实体的更多数据的添加,这种稀疏表示使得更新嵌入变得非常简单
。如果实体ei有m个不同的传出边类型,那么与这些类型对应的维度被设置为1。这是一种非常简单和灵活的表示实体的方法,我们发现它工作得很好。还要注意的是,随着关于实体的更多数据的添加,这种稀疏表示使得更新嵌入变得非常简单

设Ec,q表示查询q的上下文实体集合。为了计算Ec,q,我们首先根据实体与查询实体的余弦距离对它们进行排序,然后选择距离最小且具有查询关系rq的k个实体。对于每个上下文实体ec,我们收集将ec连接到由边rq(即§2.1中的Pn(ec,rq))连接的实体的路径类型(长度不超过n)。这些提取的路径类型将用于推理查询实体。设Pn(Ec,q,rq) =S Ec∈Ec,q Pn(Ec, rq)表示来自上下文实体的唯一路径类型集合。在给定查询条件下,找到答案实体e2的概率由:
我们对从![]() 中得到的代表路径类型的随机变量进行边缘化处理。
中得到的代表路径类型的随机变量进行边缘化处理。![]() 表示找到给定查询的路径类型的概率。这个术语捕获每种路径类型与查询同时出现的频率,并表示路径类型的先验概率。另一方面,
表示找到给定查询的路径类型的概率。这个术语捕获每种路径类型与查询同时出现的频率,并表示路径类型的先验概率。另一方面,![]() 捕获从查询实体开始遍历路径类型P时,我们得到正确答案而不是其他实体的次数比例。这个术语可以理解为捕获达到正确答案的可能性或推理路径类型的“精确度”。这对于惩罚“虚假的”路径类型是至关重要的,这些路径类型有时会碰巧找到正确的答案实体。例如,对于查询关系 WORKS IN CITY,路径类型(FRIEND∧LIVES IN CITY)朋友/居住城市可能具有较高的先验概率(因为人们通常在他们工作的城市有很多朋友)。然而,对于WORKS IN CITY,这个路径是“假的”,因为他们可能有朋友住在不同的城市,因此这个路径类型不一定会返回正确的答案。
捕获从查询实体开始遍历路径类型P时,我们得到正确答案而不是其他实体的次数比例。这个术语可以理解为捕获达到正确答案的可能性或推理路径类型的“精确度”。这对于惩罚“虚假的”路径类型是至关重要的,这些路径类型有时会碰巧找到正确的答案实体。例如,对于查询关系 WORKS IN CITY,路径类型(FRIEND∧LIVES IN CITY)朋友/居住城市可能具有较高的先验概率(因为人们通常在他们工作的城市有很多朋友)。然而,对于WORKS IN CITY,这个路径是“假的”,因为他们可能有朋友住在不同的城市,因此这个路径类型不一定会返回正确的答案。
2.2.2 Entity Clustering实体聚类
方程1为KG中的每个实体都提供了参数。对于大的kg,这可能很快导致参数爆炸。此外,由于稀疏性,估计每个实体参数会导致噪声估计。相反,我们选择将相似的实体聚集在一起。设c为表示查询实体的集群分配的随机变量。对于路径先验项,我们有

我们假设每个实体都被分配到一个集群中,因此![]() 对于除查询实体所属的集群外的所有集群都为零。其次,我们假设给定实体和聚类的路径的先验概率可以单独从聚类中确定,且与聚类中的每个实体无关。换句话说,如果
对于除查询实体所属的集群外的所有集群都为零。其次,我们假设给定实体和聚类的路径的先验概率可以单独从聚类中确定,且与聚类中的每个实体无关。换句话说,如果![]() 是分配了
是分配了![]() 的集群,那么
的集群,那么![]() 。现在,我们在同一集群中的实体上聚合统计信息,并拥有每个集群的参数,而不是每个实体的参数。我们还证明,这将显著提高性能(§3.3)。类似的论证也适用于路径精度术语,在该术语中,我们计算从集群中的每个实体开始的通往正确答案实体的路径所占的时间比例。
。现在,我们在同一集群中的实体上聚合统计信息,并拥有每个集群的参数,而不是每个实体的参数。我们还证明,这将显著提高性能(§3.3)。类似的论证也适用于路径精度术语,在该术语中,我们计算从集群中的每个实体开始的通往正确答案实体的路径所占的时间比例。
为了进行聚类,我们使用具有平均链接的分层聚类,并使用§2.2.1中定义的实体-实体相似度。我们使用链接函数上的阈值从层次结构中提取非参数的集群数量。聚合聚类已被证明在许多与知识库相关的任务中是有效的,如实体解析(Lee等人,2012;V ashishth等人,2018),总体上优于K-means等平面聚类方法(Green等人,2012;Kobren等人,2017)。通过对关联函数评分设置阈值,从层次聚类中提取出平面聚类。我们从树的根开始执行广度优先搜索,在链接高于给定阈值的节点处停止。搜索停止的节点给出了一个平坦的聚类(参见§a。2,了解更多细节)。
2.2.3 Parameter Estimation参数估计
接下来讨论了如何估计路径先验项和精度项。存在着丰富的建模方法来估计它们。例如,根据Chen等人(2018)的研究,我们可以训练神经网络模型来估计![]() 。然而,我们最初的目标是设计一个简单有效的非参数模型,我们通过KG的简单计数统计估计这些参数。
。然而,我们最初的目标是设计一个简单有效的非参数模型,我们通过KG的简单计数统计估计这些参数。

对于群集c中的每个实体,我们考虑通过边缘类型![]() 将
将![]() 连接到其直接连接的实体的路径。路径类型p的优先路径计算为
连接到其直接连接的实体的路径。路径类型p的优先路径计算为![]() 中路径类型的乘以等于p的比例。注意,在公式2中,如果一个路径类型出现多次,我们计算所有实例。例如,对于查询关系WORKS IN CITY,表单(CO WORKER∧WORKS IN CITY)的路径可以出现多次,因为一个人可以有多个不同的同事。只考虑路径类型将导致对这些重要路径的低估。类似地,路径精度概率
中路径类型的乘以等于p的比例。注意,在公式2中,如果一个路径类型出现多次,我们计算所有实例。例如,对于查询关系WORKS IN CITY,表单(CO WORKER∧WORKS IN CITY)的路径可以出现多次,因为一个人可以有多个不同的同事。只考虑路径类型将导致对这些重要路径的低估。类似地,路径精度概率![]() 可以估计为
可以估计为

设![]() 表示从实体ec开始的长度不超过n的路径。注意,与
表示从实体ec开始的长度不超过n的路径。注意,与![]() 不同,
不同,![]() 中的路径不必终止于特定的实体。同样在§2.1中,
中的路径不必终止于特定的实体。同样在§2.1中,![]() 表示路径p的终端实体,
表示路径p的终端实体,![]() 表示通过rq类型的直接边连接到ec的实体集合。因此,在给定rq的情况下,公式3估计了路径p在从ec开始时成功结束于其中一个答案实体的次数的比例。
表示通过rq类型的直接边连接到ec的实体集合。因此,在给定rq的情况下,公式3估计了路径p在从ec开始时成功结束于其中一个答案实体的次数的比例。
使用简单计数统计估计参数有几个优点。首先,它们非常简单,集群中每个实体的统计数据可以并行计算,这使得它们非常节省时间。其次,一旦它们被计算出来,我们的方法就不需要进一步的训练。最后,当添加新数据时,无需从头训练就可以很容易地更新参数。
总之,给定一个查询实体![]() ,我们的方法从k个与e1q相似的实体中收集推理路径。然后在KG中从e1q开始遍历这些推理路径,导致一组候选答案实体。每个候选答案实体的得分是由通向它们的推理路径的加权和(公式1)计算出来的。每条路径的权重是根据给定查询关系的频率(公式2)和精度(公式3)的估计来计算的。下一节将介绍如何扩展开放世界设置的模型,其中将向知识库添加新的实体和事实。
,我们的方法从k个与e1q相似的实体中收集推理路径。然后在KG中从e1q开始遍历这些推理路径,导致一组候选答案实体。每个候选答案实体的得分是由通向它们的推理路径的加权和(公式1)计算出来的。每条路径的权重是根据给定查询关系的频率(公式2)和精度(公式3)的估计来计算的。下一节将介绍如何扩展开放世界设置的模型,其中将向知识库添加新的实体和事实。
2.3 Open-world Setting
非参数模型的一大好处是,它可以通过添加新参数无缝地处理不断增长的数据。世界上不断出现新的实体(例如,关于实体的新维基百科文章经常被创建)。我们考虑这样一种设置(图2),在这种设置中,只有少量事实(边)的新实体不断被添加到KG中。这种设置对参数化模型具有挑战性(Das等人,2018;Sun等人,2019年),因为尚不清楚这些模型如何在不从头再训练的情况下合并新的实体。然而,再训练以获得工业规模的实体嵌入可能是不切实际的(例如,考虑新用户不断加入的Facebook社交图)。接下来,我们展示了我们的方法可以通过以下方式有效地处理这个设置:
(a)增加/更新实体表示
首先,我们需要为新到达的实体创建实体表示。此外,对于一些添加了新边的现有实体(例如图2中的BILL GATES、DURHAM等),它们的表示需要更新。回想一下,我们将实体表示为边缘类型的稀疏向量,因此这一步对于我们的方法来说是微不足道的。
图2:我们考虑一个不断向KG添加新实体和事实的设置。我们的非参数方法可以无缝地与新添加的实体推理,并可以推断关于它们的新事实(例如(MELINDA, WORKS IN CITY, ?)或(DUKE UNIV., LOCATED IN COUNTRY, ?)),而不需要昂贵的培训。

(b)更新集群分配
接下来,需要将新实体添加到类似实体的集群中。此外,已更新的实体的集群分配也可以更改,它们的更改可以进一步触发对其他实体的集群的更改。为了解决这个问题,可以天真地将KG中的所有实体聚类,然而,对于大型KG来说,这可能是浪费和耗时的。相反,我们使用在线分层聚类算法GRINCH (Monath等人,2019年),该算法在在线设置中表现与聚合聚类一样好。GRINCH每次观察一个实体,将其放置在最近的邻居旁边,并以树节点旋转的形式执行局部重排,并以将树的一部分子树嫁接到另一部分子树的形式执行全局重排。只需删除相应的叶节点,就可以从层次结构中删除实体。我们首先使用GRINCH删除表示形式因添加新节点而发生更改的实体,然后将这些实体与KG中新添加的实体一起增量地添加回来。我们使用与§2.2.2相同的方法,从GRINCH构建的层次聚类中提取一个平面聚类。
(c)重新估计新参数
重新分配集群后,最后一步是估计每个集群的参数。这种计算是有效的,因为从方程2和3可以清楚地看出,集群中每个实体的贡献可以独立计算(因此可以很容易地并行化)。然而,即使对于每个实体,这种计算也需要在KG中进行路径遍历,这是非常昂贵的。我们展示了不必为集群中的所有实体重新计算。
设n为模型考虑的推理路径的最大长度。对于向KG中添加的每个新实体ei,我们需要重新计算从ei开始的长度不超过(n + 1)的周期内的实体的统计信息。有关上述结果的理由,请参阅附录(a .4)。
3.Experiments
在本节中,我们将根据一系列知识库补全(KBC)基准(§3.3)来评估我们提出的方法。为了评估我们方法的非参数性质,我们还在一个“开放世界”设置(§2.3)上进行评估,在这个“开放世界”设置中,KG添加了新的实体。我们证明了我们提出的方法在标准设置的基准测试中与几种最先进的方法相比具有竞争力,但它在在线设置中的性能大大优于其他方法(§3.4)。所有实验的最佳超参数,包括尝试的超参数范围和验证集上的结果,见§A.6
3.1 Data and Evaluation Protocol数据和评估方案
Data
我们对以下KBC数据集进行评估:NELL-995, FB122 (Guo等人,2016),WN18RR (Dettmers等人,2018)。FB122是来自Freebase的数据集的一个子集,FB15K (Bordes et al., 2013),包含关于人、地点和体育的122个关系。NELL-995 (Xiong et al., 2017)是由系统的第995次迭代派生的NELL的子集。由Dettmers等人(2018)通过去除测试泄漏的逆关系,从WN18中生成WN18RR。
评价指标
根据之前的工作,我们使用HITS@N和平均倒数秩(MRR)来评估我们的方法,这是评估排名列表的标准指标。
3.2 Experimental Setting

开放世界知识库补全
在这种设置中,我们从最受欢迎的前10%的节点(其中有几条边)开始,并添加更多随机选择的节点,以便初始种子KB包含V中所有实体的50%。这是为了确保种子知识库不是太稀疏,并且在种子知识库上训练的初始模型是有意义的。接下来,所选节点之间的任何边都被添加到种子KB中。我们将其余的实体随机分成10批。每批实体以及其中包含的边都被增量地添加到知识库中。验证集和测试集也以同样的方式划分,即,如果一个三元组的头和尾实体都出现在知识库中,那么只有三元组才被放入相应的分段中。
KBC的参数化模型学习固定实体集的表示,不能处理开箱即用的“开放世界”设置。为了完成这项任务,我们扩展了最具竞争力的基于嵌入的模型——RotatE (Sun等人,2019)。对于批处理中到达的每个新实体,我们为其初始化一个嵌入的新实体。我们探索了两种初始化新实体嵌入的方法——(a)随机初始化和(b)实体嵌入的按元素排序的平均排序(w.r.t新实体所连接的关系)。具体地说,设t表示新的实体,设S = {(h,r,t)}为与实体t相关的事实。

在这里,◦代表了Hadamard(或元素)产品。这个初始化最小化新嵌入的RotatE目标,确保它根据前一个时间步骤中的模型“位置很好”。新关系的嵌入是随机初始化的。接下来,在新批三元组上进一步训练模型,以便训练新的实体嵌入。注意,对于大量的kg,由于新批次的数据频繁到达,对整个数据进行重新训练可能是不切实际的,然而,为了仍然防止模型忘记之前学习的内容,我们也对已经训练过的三元组的m%进行抽样,并对它们进行重新训练。我们确保在新添加的实体附近的三元组比其他三元组有十倍的可能性被采样。我们还尝试了一种设置,我们尝试冻结最初训练的实体嵌入,只训练新的实体和关系嵌入。
3.3 KBC基准测试结果
表2和表3给出了KBC任务的结果。我们的方法明显优于参数规则学习方法,如MINERVA、gntp和Das等人(2020)最近提出的基于案例的方法。我们想强调我们的模型与Das等人(2020)在FB122测试- ii评估中的性能差异,在测试- ii评估中,三元组可以通过学习逻辑规则来回答。这一结果强调了路径概率加权的重要性。在FB122和NELL-995的整体测试集上,我们也可以与大多数基于嵌入的模型进行比较,并取得了最先进的结果。我们报告模型运行3次的平均值。
我们在没有聚类实体(即每个实体都有自己的聚类)且有每个实体参数的情况下执行消融。表4指出了由于稀疏性导致的路径先验估计和精度参数的噪声导致的性能下降。表6显示了一个例子,在这个例子中,我们的模型学会根据集群中存在的实体类型为不同的路径打分。

路径长度对WN18RR的影响
在WN18RR的开发集上,在我们的方法没有将答案排在前10位的2985个查询中,有2030个查询要求最小路径长度大于3。基于路径的推理模型没有能力回答这些查询。为了纠正这个问题,我们进行了一个路径长度n = 5的实验(在2030个答案中有950个是可达的)。表5中的结果表明,当允许使用较长的推理路径时,我们的方法恢复了很大一部分性能。

表2:FB122的链路预测结果。Test-II表示可以通过逻辑规则推断出的三元组的子集。

3.4 Open-World KBC results
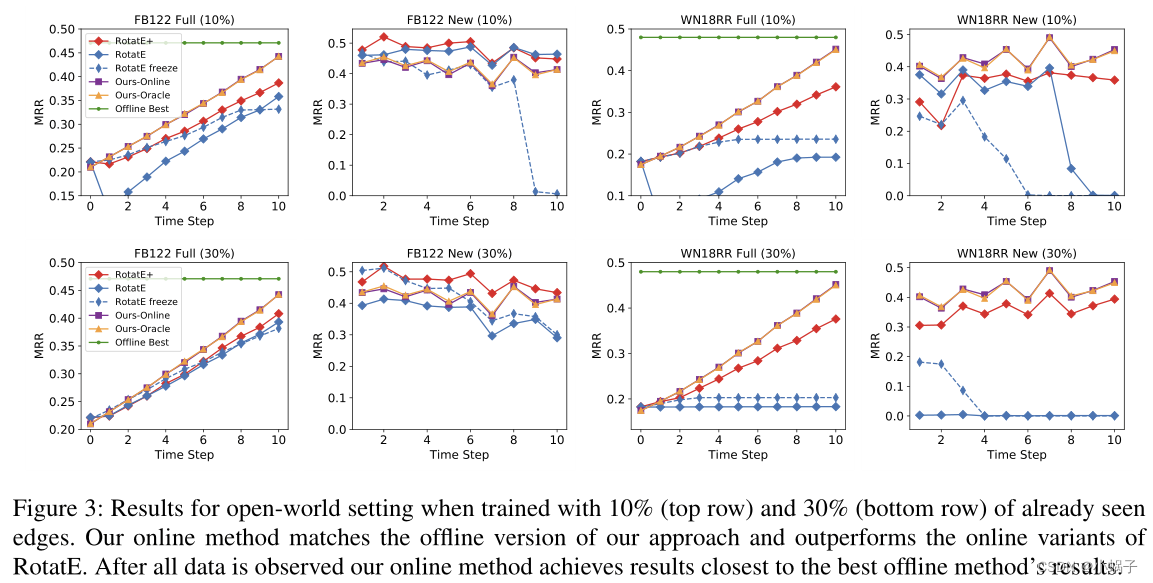
图3报告了该任务的结果。我们报告了对新实体随机初始化嵌入的RotatE模型(RotatE)和对新实体嵌入的系统初始化模型(RotatE+)的结果。我们用m ={10%,30%}之前看到的边进行实验,并对它们进行再训练。我们发现,不包括以前见过的边缘会导致整体性能的严重退化,因为模型忘记了它在过去学到的东西。我们还报告了冻结已经看到的实体表示和只学习新实体表示的结果(RotatE-Freeze)。所有的模型都被训练,直到验证集(包含新的和旧的三元组)性能停止提高。在我们的方法中,我们还报告了oracle设置的结果,当新数据到达时,我们重新聚集所有的实体,并从头重新估计所有的参数(而不是使用GRINCH和只重新计算所需的参数(§2.3)。对于这两个数据集,RotatE得到的离线最佳结果(FB122 test-I为47.1,WN18RR为48)。我们报告整个评估集(完整)的性能,以及包含新添加的边的集合(新)的性能。
结果的主要总结是(i) RotatE模型在在线设置中收敛到较低的性能,在FB122中损失至少8个MRR点,在WN18RR中损失至少11个MRR点。在FB122上,我们观察到模型更倾向于通过牺牲先前学习的事实来学习新信息(图3中的第2子图)(ii)在冻结设置中,模型性能在某一指示饱和点之后迅速恶化,即模型很难通过保持现有实体的参数不变来学习关于到达的实体的新信息。(iii)在全面评估上,RotatE+的表现优于RotatE,表明糟糕的初始化会随着时间的推移而恶化性能,然而,与最佳性能之间仍有很大的差距(iv)我们的方法几乎与我们在oracle设置中的性能相匹配,表明在线聚类和快速参数逼近的有效性。(v)最后,我们的表现最接近离线最佳结果,优于RotatE的所有变体。
图3:使用10%(上行)和30%(下行)已经看到的边缘进行训练时,开放世界设置的结果。我们的在线方法与我们方法的离线版本相匹配,并且优于RotatE的在线变体。在观察了所有数据后,我们的在线方法取得的结果最接近最佳离线方法的结果。
4.相关工作
Open-world KG completion
Shi和Weninger(2018)考虑了开放世界KG补全任务。然而,他们使用文本描述来学习使用卷积神经网络的实体表示。我们的模型不使用额外的文本数据,我们使用非常简单的实体表示,这有助于我们良好地执行。Tang等人(2019)通过阅读新闻,学会了用新的链接更新KG。即使它们处理添加或删除新边,它们也不会观察到新的实体。最后,它们都没有使用CBR方法从类似实体中学习。
Learning to update knowledge graphs by reading news
关于KGs的归纳表示学习
最近的工作(Teru et al., 2020;Wang等人,2020)学习实体独立的关系表示,因此允许它们处理看不见的实体。然而,它们不会通过从相似实体收集推理路径来执行上下文推理。此外,在我们的开放世界设置中,我们考虑了更具挑战性的设置,在那里新的事实和实体以流的方式到达,我们提供了一种使用在线层次聚类更新参数的有效方法。这使得我们的方法适用于初始KG很小且持续增长的情况。
Rule induction in knowledge graphs
归纳逻辑规划(ILP)的经典工作是从有根据的事实中归纳出规则。然而,他们需要明确的反例,这在KBs中是不存在的,他们不能扩展到大型KBs。最近的ILP方法试图通过从规则中猜测反例来弥补这一缺陷,并使其更具可扩展性。统计关系学习方法和概率逻辑方法结合机器学习和逻辑学习规则。然而,这些工作都没有从知识图中的相似实体动态地推导出推理规则。
链接预测的贝叶斯非参数方法
在贝叶斯非参数中有大量的工作可以自动学习实体的潜在维度(Kemp等人,2006;Xu等,2006)。我们的方法不学习实体的潜在维数,而是非参数的,因为它从最近的邻居收集推理路径,通过在线非参数层次聚类有效更新参数,可以无缝地与新实体推理。
基于嵌入的链路预测方法
我们还比较了基于张量分解或神经方法的更流行的基于嵌入的模型(Nickel et al., 2011;Bordes等,2013;Dettmers等,2018;孙等人,2019)。我们的简单方法不需要迭代优化,它的性能优于大多数方法,并且与最新的RotatE模型的性能相当。此外,我们在在线实验中优于RotatE。
CBR for KG completion
很少有人尝试将CBR应用于知识管理(Dubitzky等人,1999;Bartlmae和Riemenschneider, 2000),然而,他们并不进行情境化推理或考虑在线设置。我们的工作与Das等人(2020)最近的工作最为密切相关。然而,由于它没有考虑到每条路径的重要性,它的性能很低,我们的模型在几个基准测试中优于它。
5.结论
我们提出了一种简单而准确的基于概率的知识库推理方法。我们的方法是非参数的,从知识库中的相似实体动态地派生推理规则,并且能够处理新的实体。我们将相似的实体聚类在一起,并使用简单的计数统计估计每个聚类参数,度量路径的先验性和精度。我们的简单方法在几种基准测试中与基于嵌入式的最佳模型相比具有竞争力,并且在开放世界环境中优于所有模型。
![[Linux-文件I/O] 文件函数系统文件接口缓冲区文件描述符dup2inode软硬链接动静态库](https://img-blog.csdnimg.cn/img_convert/db36b2847d2fc777c496b23567e08524.png)