一、Spark3.0 简介
Spark3.0版本包含了3400多个补丁程序,是开源社区做出巨大贡献的最高峰,带来了Python和SQL功能的重大进步,并着眼于探索和生产的易用性。
1、Spark3.0新功能
(1)通过自适应查询执行,动态分区修剪和其他优化,与Spark2.4相比,TPC-DS的性能提高了2倍
(2)符合ANSI SQL
(3)pandas API有重大改进,包括Python类型提示和其他pandas UDF
(4)更好的Python错误处理,简化了PySpark异常
(5)用于structured streaming新的UI界面
(6)使用R语言UDF函数,速度提高40倍
二、 Spark Sql 引擎改进
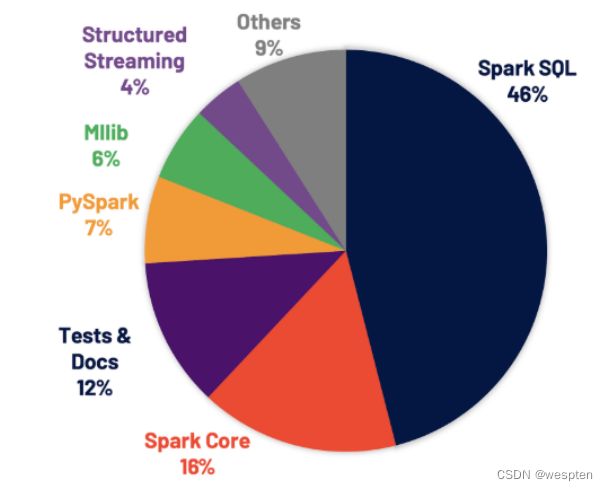
Spark Sql是支持大多数Spark应用的程序引擎。例如,根据Databricks(Spark的商业化公司)统计,发现超过90%的Spark API调用和使用DataFrame,DataSet和SQL API以及SQL优化器优化其他库。这意味着,即使Pyhton和Scala开发人员也将大部分工作通过Spark Sql引擎进行。在Spark3.0版本中,贡献的所有修补程序中有46%用于SQL,从而提高性能和ANSI兼容性。
如下图所示,Spark3.0在总运行时间的性能大约要比Spark2.4快上2倍。

新的自适应查询执行(AQE)框架通过在运行时生成更好的执行计划来提高性能并简化调优。此版本引入了三个主要的自适应优化
(1)Dynamic coalescing shuffle partitions:动态合并shuffle分区,简化甚至避免调整shuffle分区个数,用户可以在开始时设置相对大量的洗牌分区,然后AQE可以在运行时将相邻的小分区合并成为更大分区
(2)Dynamic switching join strategies:动态选择join策略,这种自适应优化可以在运行时将sort-merge join转换为broadcast-hash join,从而进一步简化调整并提高性能。
(3)Dynamic optimzing skew joins:动态优化数据倾斜join,是另一个关键的性能优化,因为倾斜join会导致工作极度失衡并严重降低性能,在AQE中它可以将倾斜的分区拆分为较小的分区,并将它们与另一端的相应分区合并。
基于3TB TPC-DS基准,与不使用AQE的Spark相比:

1、Hydrogen,Streaming 扩展
在Spark3.0中,完成了Project Hydrogen关键组件,并引入新的功能来改善流传输和扩展性。
(1)加速器感知调度:Project Hydrogen 是Spark的一项重大计划,为了更好的统一Spark上的深度学习和数据处理,GPU和其他加速器已被广泛用于加速处理。为了使Spark能够利用目标平台上的硬件加速器,此版本增强了现有调度程序,使群集管理器可以感知加速器。用户可以通过脚本指定加速器,也可以使用新的RDD API来利用加速器。
(2)新的Structured Streaming UI界面:Structured Streaming最初是在Spark2.0引入的。此版本添加了新的专用Spark UI,这个新的UI提供了两组统计信息。
1. 已完成的流查询作业的聚合信息。
2. 关于流的详细统计信息。
并且根据Databricks公司的统计,每天都有超过5万亿条数据在结构化流上处理。

(3)可观察指标:连续监视数据质量的变化是管理数据管道的非常理想化的功能,此版本引入了对批处理和流应用程序的监视。
可观察的指标是可以在查询(DataFrame)上定义的任意聚合函数。一旦DataFrame的执行达到完成点(例如,完成批查询或到达流时期),就会发出一个命名事件,其中包含一个完成点来处理数据的度量。
2、Adaptive Query Execution
在Spark3.0中AQE框架具有以下三个功能:
(1)Dynamically coalescing shuffle partitions
(2)Dynamically switching join strategies
(3)Dynamically optimizing skew joins
① Dynamically coalescing shuffle partitions
在Spark中运行查询处理非常大的数据时,shuffle通常会对查询性能产生非常重要的影响。
shuffle是非常昂贵的操作,因为它需要进行网络传输移动数据,以便下游进行计算。
最好的分区取决于数据,但是每个查询的阶段之间的数据大小可能相差很大,这使得该数字难以调整:
(1)如果分区太少,则每个分区的数据量可能会很大,处理这些数据量非常大的分区,可能需要将数据溢写到磁盘(例如,排序和聚合),降低了查询。
(2)如果分区太多,则每个分区的数据量大小可能很小,读取大量小的网络数据块,这也会导致I/O效率低而降低了查询速度。拥有大量的task(一个分区一个task)也会给Spark任务计划程序带来更多负担。
为了解决这个问题,我们可以在任务开始时先设置较多的shuffle分区个数,然后在运行时通过查看shuffle文件统计信息将相邻的小分区合并成更大的分区。
例如,假设正在运行select max(i) from tbl groupby j。输入tbl很小,在分组前只有2个分区。那么任务刚初始化时,我们将分区数设置为5,如果没有AQE,Spark将启动五个任务来进行最终聚合,但是其中会有三个非常小的分区,为每个分区启动单独的任务这样就很浪费。

取而代之的是,AQE将这三个小分区合并为一个,因此最终聚只需三个task而不是五个。

② Dynamically switching join strategies
Spark支持多种join策略,其中如果join的一张表可以很好的插入内存,那么broadcast shah join通常性能最高。因此,spark join中,如果小表小于广播大小阀值(默认10mb),Spark将计划进行broadcast hash join。但是,很多事情都会使这种大小估计出错(例如,存在选择性很高的过滤器),或者join关系是一系列的运算符而不是简单的扫描表操作。
为了解决此问题,AQE现在根据最准确的join大小运行时重新计划join策略。从下图实例中可以看出,发现连接的右侧表比左侧表小的多,并且足够小可以进行广播,那么AQE会重新优化,将sort merge join转换成为broadcast hash join。

对于运行是的broadcast hash join,可以将shuffle优化成本地shuffle,优化掉stage 减少网络传输。Broadcast hash join可以规避shuffle阶段,相当于本地join。
③ Dynamically optimizing skew joins
当数据在群集中的分区之间分布不均匀时,就会发生数据倾斜。严重的倾斜会大大降低查询性能,尤其对于join。AQE skew join优化会从随机shuffle文件统计信息自动检测到这种倾斜。然后它将倾斜分区拆分成较小的子分区。
例如,下图 A join B,A表中分区A0明细大于其他分区:

因此,skew join 会将A0分区拆分成两个子分区,并且对应连接B0分区:

没有这种优化,会导致其中一个分区特别耗时拖慢整个stage,有了这个优化之后每个task耗时都会大致相同,从而总体上获得更好的性能。
④ 开启AQE
可以通过设置参数spark.sql.adaptive.enabled设置为true,(Spark 3.0中默认为false),并且满足以下条件
- 它不是流查询
- 它包含至少一个exchange操作(通常是join,aggregate或window运算符时)或一个子查询
3、New Structured Streaming UI

统计信息页面显示一些有用的指标,可用于深入了解流式查询的状态:
- Input Rate:数据到底的速率
- Process Rate:Spark处理数据的速率
- Input Rows:触发器中处理的记录行数
- Batch Duration:每批的处理持续时间
- Operation Duration:执行各种操作锁花费的时间
- (1)addBatch:将当前批次的结果数据添加到接收器
- (2)getBatch:获取要处理的新一批数据
- (3)latestOffset:获取源的最新偏移量
- (4)queryPlaning:生成执行计划
- (5)walCommit:将偏移量写入元数据
4、Dynamic Partition Pruning
Spark3.0支持动态分区裁剪,简称DPP,核心思路就是先将join一侧作为子查询计算出来,再将其所有分区用到join另一侧作为表过滤条件,从而实现对分区的动态修剪。
如图所示:

将:
select t1.id,t2.pkey from t1 join t2 on t1.pkey =t2.pkey and t2.id<2优化成了:
select t1.id,t2.pkey from t1 join t2 on t1.pkey=t2.pkey and t1.pkey in(select t2.pkey from t2 where t2.id<2)触发条件:
- 待裁剪的表join的时候,join条件里必须有分区字段
- 如果是需要修剪左表,那么join必须是inner join ,left semi join或right join,反之亦然。但如果是left out join,无论右边有没有这个分区,左边的值都存在,就不需要被裁剪
- 另一张表需要存在至少一个过滤条件,比如a join b on a.key=b.key and a.id<2
开启DDP后性能对比 参数spark.sql.optimizer.dynamicPartitionPruning.enabled 默认开启。

5、支持ANSI SQL
从spark3.0开始,Spark SQL引入了两个实验性选项来符合SQL标准,spark.sql.ansi.enabled和spark.sql.storeAssignmentPolicy。
当spark.sql.ansi.enabled设置为true时(默认是false),Spark Sql基本行为(例如算术运算,类型转换SQL函数和SQL解析)都遵循ANSI标准。
当spark.sql.storeAssignmentPolicy设置为ANSI时,Spark Sql符合ANSI存储分配规则。
算术运算对比,默认情况下Spark Sql不会检查对数字类型的执行算术运算是否溢出,这意味着在某个操作导致溢出的情况下,结果与JAVA/SCALA程序中的相应结果一致(例如,相加总和大于可表示的最大值,则结果会成为负数)。另一方面Spark Sql对于十进制溢出返回null。当spark.sql.ansi.enabled设置为ture并在算术运算时发生溢出,它将在运行时引发算术异常。

类型转换、部分SQL函数、关键字都会有不一样,参考官网
ANSI Compliance - Spark 3.0.0 Documentation
6、支持JDK11
保留jdk8的支持,直接跳过jdk9和jdk10直接支持jdk11。
7、Hadoop支持
移除了hadoop2.6 的支持,新增了Hadoop3的支持。
8、Scala支持
移除了scala2.11的支持,新增scala2.12支持。
9、Hive支持
默认情况下使用Apahe Hive 2.3依赖。
10、Hint功能增强
在spark2.4的时候就有了hint功能,不过那个时候还是只有broadcasthash join的hint,这次3.0又增加了sort merge join,shuffle_hash join,shuffle_replicate nested loop join
具体用法如下:
- broadcasthast join
三种方式都支持:
sparkSession.sql("select /*+ BROADCAST(school) */ * from student left join school on student.schoolid=school.id").show
sparkSession.sql("select /*+ BROADCASTJOIN(school) */ * from student left join school on student.schoolid=school.id").show
sparkSession.sql("select /*+ MAPJOIN(school) */ * from student left join school on student.schoolid=school.id").show
- sort merge join
sparkSession.sql("select /*+ SHUFFLE_MERGE(school) */ * from student left join school on student.schoolid=school.id").show
sparkSession.sql("select /*+ MERGEJOIN(school) */ * from student left join school on student.schoolid=school.id").show
sparkSession.sql("select /*+ MERGE(school) */ * from student left join school on student.schoolid=school.id").show
- shuffle_hash join
sparkSession.sql("select /*+ SHUFFLE_HASH(school) */ * from student left join school on student.schoolid=school.id").show
- shuffle_replicate_nl join
使用条件非常苛刻,驱动表(school表)必须小,且很容易被spark执行成sort merge join:
sparkSession.sql("select /*+ SHUFFLE_REPLICATE_NL(school) */ * from student inner join school on student.schoolid=school.id").show()

11、使用堆外内存
这里使用下堆外内存来结合查看界面,当在yarn群集上去提交任务时,需要取指定driver和executor端的堆外内存。driver端对应spark.driver.memoryOverhead参数默认值driverMemory*0.1,当然最小值是384MB不能比它小,此参数是spark2.3时才有。executor端对应spark.executor.memoryOverhead参数,默认值executorMemory*0.1,最小值384mb,spark2.3时才有。
前面两个参数主要用于解决JVM开销,内部字符串,NIO BUFFER等开销,如果实际程序中需要用到堆外内存那么得再开启spark.memory.offHeap.enabled参数,并且通过spark.memory.offHeap.size参数指定大小,一个容器的可以申请多少内存资源由spark.executor.memoryOverhead,spark.executor.memory, spark.memory.offHeap.size 3个参数决定。
接下来就使用下堆外内存进行缓存,并用spark ui界面进行查看内存使用情况:
object OFFHeapMemroyTest {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setAppName("test")sparkConf.set("spark.memory.offHeap.enabled", "true")sparkConf.set("spark.memory.offHeap.size", "1G")val sparkSession = SparkSession.builder().enableHiveSupport().config(sparkConf).getOrCreate()val df = sparkSession.sql("select *from default.student")df.persist(StorageLevel.OFF_HEAP)df.foreach(item=>println(""))while (true) {}}
}提交yarn指定参数:
spark-submit --master yarn --deploy-mode client --driver-memory 1g --conf spark.driver.memoryOverhead=1g --num-executors 2 --conf spark.executor.memoryOverhead=1g --executor-cores 2 --executor-memory 1g --queue spark --class com.yyds.test.OFFHeapMemroyTest spark3test-1.0-SNAPSHOT-jar-with-dependencies.jar


三、Spark从2.4升级3.0迁移
1、Spark Core
- org.apahce.spark.ExecutorPlugin接口和相关配置已替换为org.apache.spark.api.plugin.SparkPlugin,该功能增加了新功能
- 不推荐使用TaskContext.isRunningLocally方法。本地执行已被移出,并返回false
- ShuffleWriteMetrics中不推荐使用的方法shuffleBytesWritten,shuffleBytesTime和shuffleRecordWriten已被删除
- 已弃用AccumulabeInfo.apply,因为不再允许创建AccumulabelInfo
- 不再推荐使用Accumlator V1 APi已被删除,请使用Accumlator V2 API
- 日志文件将以UTF-8编写,Spark History Server将以UTF-8编码读取
2、Structred Streaming
- 在Spark3.0中当通过Spark.readStream(...),使用基于文件的数据源(例如文本,json,csv,parquet,orc)时,结构化流会强制将模式设置为可为空
- 在Spark3.0中,已弃用类org.apache.spark.sql.streaming.ProcessingTime,请改用org.apache.spark.sql.streaming.Trigger.ProcessingTime。同样已删除org.apache.spark.sql.execution.streaming.continuous.ContinuousTrigger,请改用Trigger.Continuous。
同样不推荐使用ora.apache.spark.sql.execution.streaming.OneTimeTirgger,请改用Trigger.Once。
3、Spark Sql
详见官网:
https://spark.apache.org/docs/3.0.0/sql-migration-guide.html#upgrading-from-spark-sql-24-to-30
四、Spark3.0 集群部署
环境规划:
| Hadoo101 | Hadoo102 | Hadoop103 |
| Zk | Zk | Zk |
| ResourceManager | ResourceManager | |
| DataNode | DataNode | DataNode |
| NodeManager | NodeManager | NodeManager |
| JournalNode | JournalNode | JournalNode |
| NameNode | NameNode | NameNode |
| JobHistoryServer | ||
| Spark2.4.5 | Spark3.0.0 | |
| HistoryServer |
1、编译Spark(有问题,编译能成功)
hadoop版本3.13,上传Spark3.0.0源码,进行编译:
[root@hadoop103 software]# tar -zxvf spark-3.0.0.tgz -C /opt/module/
[root@hadoop103 software]# cd /opt/module/spark-3.0.0/
[root@hadoop103 spark-3.0.0]# export MAVEN_OPTS="-Xmx2g -XX:ReservedCodeCacheSize=1g"将pom.xml进行替换,将准备好的pom.xml覆盖上去。
上传zinc-0.3.15.tgz 解压到spark3.0.0 build下:

打包:
[root@hadoop103 spark-3.0.0]# ./dev/make-distribution.sh --name custom-spark --tgz -Pyarn -Dhadoop.version=3.1.3 -Phive -Phive-thriftserver 
2、解压安装
(1)解压
[root@hadoop103 module]# tar -zxvf spark-3.0.0/spark-3.0.0-bin-custom-spark.tgz -C /opt/module/(2)将hive-site.xml复制过来
[root@hadoop101 conf]# scp hive-site.xml hadoop103:/opt/module/spark-3.0.0-bin-custom-spark/conf(3)配置环境变量
[root@hadoop103 module]# vim /etc/profile
#SPARK_HOME
export SPARK_HOME=/opt/module/spark-3.0.0-bin-custom-spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
[root@hadoop103 module]# source /etc/profile(4)配置spark-default.conf
[root@hadoop103 module]# cd spark-3.0.0-bin-custom-spark/conf
[root@hadoop103 conf]# mv spark-defaults.conf.template spark-defaults.conf
spark.yarn.historyServer.address=hadoop102:18080
spark.yarn.historyServer.allowTracking=true
spark.eventLog.dir=hdfs://mycluster/spark_historylog
spark.eventLog.enabled=true
spark.history.fs.logDirectory=hdfs://mycluster/spark_historylog
spark.executor.extraLibraryPath=/opt/module/hadoop-3.1.3/lib/native/(5)配置spark-env.sh
[root@hadoop103 conf]# mv spark-env.sh.template spark-env.sh
[root@hadoop103 conf]# vim spark-env.sh
YARN_CONF_DIR=/opt/module/hadoop-3.1.3/etc/hadoop
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native(6)解决guava包冲突
[root@hadoop103 ~]# cd /opt/module/hadoop-3.1.3/share/hadoop/common/lib/
[root@hadoop103 lib]# cp guava-27.0-jre.jar /opt/module/spark-3.0.0-bin-custom-spark/jars/
[root@hadoop103 lib]# cd /opt/module/spark-3.0.0-bin-custom-spark/jars/
[root@hadoop103 jars]# rm -rf guava-14.0.1.jar(7)启动历史服务器
[root@hadoop103 module]# scp -r spark-3.0.0-bin-hadoop2.7/ hadoop102:/opt/module/
[root@hadoop103 module]# hadoop dfs -mkdir hdfs://mycluster/spark_historylog
[root@hadoop102 module]# start-history-server.sh五、Spark3.0 新特性
1、Dynamically coalescing shuffle partitions 使用
开启aqe参数spark.sql.adaptive.enabled,设置为ture。开启aqe中动态合并分区功能spark.sql.adaptive.coalescePartitions.enabled,此参数默认开启。设置初始分区个数spark.sql.adaptive.coalescePartitions.initialPartitionNum,该参数默认值与spark.sql.shuffle.partitions一致,默认200。
此参数可以设置了大点,后续会进行动态合并。测试该功能对join和groupby的效果。
val sparkConf = new SparkConf().setAppName("dws_member_import").setMaster("local[*]").set("spark.sql.adaptive.enabled", "true").set("spark.sql.adaptive.coalescePartitions.enabled", "true").set("spark.sql.adaptive.coalescePartitions.initialPartitionNum","1000")//设置初始分区为1000个.set("spark.sql.autoBroadcastJoinThreshold", "-1")//先关闭广播join功能
val sparkSession = SparkSession.builder().config(sparkConf).enableHiveSupport().getOrCreate()
val ssc = sparkSession.sparkContext
ssc.hadoopConfiguration.set("fs.defaultFS", "hdfs://mycluster")
ssc.hadoopConfiguration.set("dfs.nameservices", "mycluster")
sparkSession.sql(s"select appregurl,count(uid),dn,dt from dws.dws_member where dt='${dt}' group by appregurl,dn,dt").show //根据dt日期查询dws_member表,测试group by
sparkSession.sql("select a.uid,a.fullname,b.appkey,b.createtime from dwd.dwd_member a inner join dwd.dwd_member_regtype b on a.uid =b.uid and a.dt=b.dt").show() //测试两表join
val df1=sparkSession.sql("select uid,dt,fullname from dwd.dwd_member")
val df2=sparkSession.sql("select uid,dt,appkey,createtime from dwd.dwd_member_regtype")
df1.join(df2,Seq("uid","dt"),"left").show() //测试对api join是否有效运行结果查看Spark UI:

可以看到开启aqe动态合并分区后,每个stage会根据分区的数据量自动进行缩小分区操作,从而避免过多的小任务或者空转的情况。
将任务放到spark2.4.5上运行,或者将spark.sql.adaptive.enabled设置为false关闭aqe,查看运行效果。

每个stage的task个数并不会动态缩减,保持默认值200,那么就有可能造成分区数据不均衡或者空数据的分区。
2、Dynamically switching join strategies 使用
准备两张表:
CREATE TABLE `student`(`id` int, `name` string, `age` int, `schoolid` int)
PARTITIONED BY ( `dt` string)CREATE TABLE `school`(`id` int, `name` string)
PARTITIONED BY ( `dt` string)往student表灌入5000万条数据,school表灌入1500万条数据。


保证表大小不小于默认广播join小表大小10mb。


灌入数据后,两表进行join,并且join时对school表进行filter操作,过滤id小于1000的数据:
val sparkConf = new SparkConf().setAppName("test").setMaster("local[*]")
val sparkSession = SparkSession.builder().config(sparkConf).enableHiveSupport().getOrCreate()
val ssc = sparkSession.sparkContext
ssc.hadoopConfiguration.set("fs.defaultFS", "hdfs://mycluster")
ssc.hadoopConfiguration.set("dfs.nameservices", "mycluster")
val df1 = sparkSession.sql("select id,name,age,schoolid from default.student")
val df2 = sparkSession.sql("select id,name from default.school").filter("id<1000")
df1.join(df2, df1("schoolid") === df2("id"), "left").show(20)先不打开aqe,查看stage和执行计划图:

两张表数据量均大于广播join默认值(10mb) 。

可以看到,school表经过filter过滤数据量已非常小,但还是走了sortmerge join。开启aqe测试spark3.0自动选择join策略功能,打开本地shuffle读取器(用于转换广播join,默认是打开的) 。
val sparkConf = new SparkConf().setAppName("test").setMaster("local[*]").set("spark.sql.adaptive.enabled", "true")
.set("spark.sql.adaptive.localShuffleReader.enabled","true")
val sparkSession = SparkSession.builder().config(sparkConf).enableHiveSupport().getOrCreate()
val ssc = sparkSession.sparkContext
ssc.hadoopConfiguration.set("fs.defaultFS", "hdfs://mycluster")
ssc.hadoopConfiguration.set("dfs.nameservices", "mycluster")
val df1 = sparkSession.sql("select id,name,age,schoolid from default.student")
val df2 = sparkSession.sql("select id,name from default.school").filter("id<1000")
df1.join(df2, df1("schoolid") === df2("id"), "left").show(20)开启后,再次运行代码,查看stage和sql执行计划图:

多了一个转换操作,将原先sortmerge join转换为了广播join:

3、Dynamically optimizing skew joins 使用
Spark3.0 aqe自动优化倾斜join,首先来模拟数据倾斜场景,首先建两张表,一张course课程表,一张shopping购物车表:
CREATE EXTERNAL TABLE `dwd_sale_course`(`courseid` int, `coursename` string, `status` string, `pointlistid` int, `majorid` int, `chapterid` int, `chaptername` string, `edusubjectid` int, `edusubjectname` string, `teacherid` int, `teachername` string, `coursemanager` string, `money` decimal(10,4))
PARTITIONED BY ( `dt` string, `dn` string)CREATE EXTERNAL TABLE `dwd.dwd_course_shopping_cart`(`courseid` int, `orderid` string, `coursename` string, `discount` decimal(2,1), `sellmoney` decimal(10,4), `createtime` timestamp)
PARTITIONED BY ( `dt` string, `dn` string)建完之后,往两张表里灌数据,并且购物车表数据让courseid为101和103的数据倾斜,分别生成500万条数据,生成数据后进行join操作。

先在spark2.4.5上运行查看数据倾斜效果:

点解stage,查看task详情,对时间进行排序:


Task 19和task 123出现了数据倾斜,切到Spark3.0.0使用aqe进行优化。
分别要开启一下参数:
- 1. spark.sql.adaptive.enabled 开启aqe功能,默认关闭
- 2. spark.sql.adaptive.skewJoin.enabled 开启aqe倾斜join
- 3. spark.sql.adaptive.skewJoin.skewedPartitionFactor 倾斜因子,如果分区的数据量大于 此因子乘以分区的中位数,并且也大于spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes,那么认为是数据倾斜的
- 4. spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes,每个分区的阀值,默认256mb,理想情况此参数应该大于spark.sql.adaptive.advisoryPartitionSizeInBytes
spark.sql.adaptive.skewJoin.skewedPartitionFactor 参数官网有两处:


所以官网有误,查看源码,默认值为5。

运行加完参数后的代码:
val sparkConf = new SparkConf().setAppName("dws_sellcourse_import")
.set("spark.sql.autoBroadcastJoinThreshold", "-1") //把广播join先禁止了
.set("spark.sql.adaptive.enabled", "true") //开启aqe
.set("spark.sql.adaptive.skewJoin.enabled", "true") //开启aqe倾斜join 默认开启
.set("spark.sql.adaptive.skewJoin.skewedPartitionFactor", "2") //设置中文数默认值5 官网有误
.set("spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes", "10m") //默认值256m
.set("spark.sql.adaptive.advisoryPartitionSizeInBytes", "8m") //推荐每个分区的数据量
.set("spark.sql.adaptive.coalescePartitions.enabled", "false") //先关闭动态合并分区val sparkSession = SparkSession.builder().config(sparkConf).enableHiveSupport().getOrCreate()val ssc = sparkSession.sparkContextssc.hadoopConfiguration.set("fs.defaultFS", "hdfs://mycluster")ssc.hadoopConfiguration.set("dfs.nameservices", "mycluster")HiveUtil.openDynamicPartition(sparkSession)HiveUtil.openCompression(sparkSession)val course = sparkSession.sql("select courseid,coursename,status,pointlistid,majorid,chapterid,chaptername,edusubjectid," +"edusubjectname,teacherid,teachername,coursemanager,money,dt,dn from dwd.dwd_sale_course")val shoppingCart = sparkSession.sql("select courseid,orderid,coursename,discount,sellmoney,createtime,dt,dn from dwd.dwd_course_shopping_cart").drop("coursename").withColumnRenamed("discount", "cart_discount").withColumnRenamed("createtime", "cart_createtime")val result = course.join(shoppingCart, Seq("courseid", "dt", "dn"), "right")result.foreachPartition(partition=>{partition.foreach(item=>{println(item.getAs[String]("coursename"))})})
}
点击stage查看task详情:

已将数据倾斜情况优化,再将动态分别分区开启结合倾斜join使用:
.set("spark.sql.adaptive.coalescePartitions.enabled", "true") //开启动态合并分区


耗时1.9分钟到达最优效果。
4、Dynamic Partition Pruning 使用
此功能默认是打开,参数spark.sql.optimizer.dynamicPartitionPruning.enabled,该功能会进行执行计划下推处理,先将此功能关闭,正常走个join并且带过滤条件。
先生成数据,并且两张表都有100个分区。
val sparkConf = new SparkConf().setAppName("test").setMaster("local[*]").set("spark.sql.optimizer.dynamicPartitionPruning.enabled", "false") //关闭dpp
val sparkSession = SparkSession.builder().config(sparkConf).enableHiveSupport().getOrCreate()
val ssc = sparkSession.sparkContext
ssc.hadoopConfiguration.set("fs.defaultFS", "hdfs://mycluster")
ssc.hadoopConfiguration.set("dfs.nameservices", "mycluster")
import sparkSession.implicits._
sparkSession.range(1000000).mapPartitions(partitions => {val random = new Random()partitions.map(item => Student(item, "name" + item, random.nextInt(100), random.nextInt(100)))
}).write.partitionBy("partition").mode(SaveMode.Append).saveAsTable("test_student")sparkSession.range(1000000).mapPartitions(partitions => {val random = new Random()partitions.map(item => School(item, "school" + item, random.nextInt(100)))
}).write.partitionBy("partition").mode(SaveMode.Append).saveAsTable("test_school")生成数据后两边进行join。先关闭dpp测试:
val result=sparkSession.sql("select a.id,a.name,a.age,b.name from default.test_student a inner join default.test_school b " +" on a.partition=b.partition and b.id<1000 ")
result.foreach(item=>println(item.get(1)))

开启dpp后,spark.sql.optimizer.dynamicPartitionPruning.enabled设置为true,再次运行代码。



test_student表会多出一个filte过滤,这就是dpp的过滤算子下推的结果。经过测试发现修改join条件和更改过滤条件都有可能导致失效,感觉此功能还不是很完善。
5、Structred Streaming 使用
Structred Streaming是基于Spark Sql引擎构建的可伸缩且容错的流式处理引擎。可以使用DataSet/DataFrame API表示流聚合,事件时间窗口。计算在同一优化的Spark Sql引擎上执行。最后,系统通过检查点和预写日志来确保端的一次性容错保证。简而言之,结构化流提供了快速,可扩展,容错,端到端的一次精确流处理,而用户不必自己处理。
从Spark2.3开始,引入了一种“连续处理”的新延迟的处理模式,该模式下实现最低延迟的低至1毫秒的端到端延迟。
1)程序设计模型
结构化流处理中关键思想是将实时的数据流视为被连续追加的表。这就产生了一个新的流处理模型,该模型与批处理模型非常相似。
将输入的数据流视为“输入表”,流上到达每个数据都像是将新行附加到输入表中。

输入流生成“结果表”,在每个trigger触发器间隔时间将新行数据附加到结果表,并在最后更新结果表。更新完结果表之后希望写入到外部接收器Sink。

2)对外输出模式
- Complete Mode:完整模式,整个更新后的结果表被写入外部sink。由连接器决定如何处理整个表
- Append Mode:追加模式,仅将结果表中附加的新行写入到外部sink,这种模式适用于历史数据不会有更改的情况
- Update Mode:更新模式,仅将在结果表中发生变化的,发生更新的行写入外部sink,如果此模式历史数据没有发生变化,相当于Append追加模式。
结构化流不会实现整个表,也就是说不会保存整个表的明细数据,从流数据源读取最新的可用数据并进行增量处理得到最新结果,结构化流会仅保留最新结果而丢弃源数据。此模型与许多其他流处理引擎明细不同。许多流系统要求用户自己维护运行中的聚合,因此必须考虑容错和数据一致性。
3)处理延迟数据
事件时间是嵌入数据本身的时间,对于许多应用程序来说,都希望按此时间进行处理,而不是Spark本身受到数据的时间。在结构化流中,可以基于事件时间来进行窗口聚合操作。
此模型自然会根据事件时间处理比预期晚到达的数据,从Spark2.1开始,支持水印功能,该功能允许用户指定最新数据可延迟的阀值,并允许引擎相应地清楚旧状态。
4)容错定义
精准一次消费是结构化流设计的主要目标之一,为此结构化有接收器和执行引擎,可以可靠地跟踪处理确切的进度,以便结构化流可以通过重新启动或/重新处理来处理任何类型的故障。例如流数据源Kafka,结构化流可以跟踪对应偏移量读取位置,引擎使用checkpoint和wal预写日志记录每个trigger触发器的偏移量。结构化流可以重播源数据和幂等的接收器,确保精准一次消费。
5)输入源
- File source:文件源,支持CSV,JSON,ORC,Parquet。支持容错。支持全局路径,但不支持逗号分割的全局路径。
- Socket Source:从套接字读取UTF-8文本数据,一般用于测试,不支持端到端的容错。
- Kafka Source:从Kafka读取数据,版本0.10.0或更高,支持容错。
- Rate Source:以每秒指定的行数生成数据,带有时间戳,用于测试环境。
6)本地测试水位线
case class Student(uid: Int, timestamp: Timestamp, time: Timestamp, `type`: String)object StructredStreamingTest {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setAppName("test").setMaster("local[*]").set("spark.sql.shuffle.partitions", "12")val sparkSession = SparkSession.builder().config(sparkConf).getOrCreate()val line = sparkSession.readStream.format("socket").option("host", "hadoop101").option("port", "7777").option("includeTimestamp", true).load()import sparkSession.implicits._val result = line.as[(String, Timestamp)].filter(item => item._1.split(",").length == 3).mapPartitions(partitions => {partitions.map(item => {val datas = item._1.split(",")val uid = datas(0).toIntval timestamp = Timestamp.valueOf(datas(1)) //事件时间val `type` = datas(2)val time = item._2 //处理时间Student(uid, timestamp, time, `type`)})})import org.apache.spark.sql.functions._val rs = result.withWatermark("timestamp", "5 minutes") //指定timestamp为事件时间.groupBy(window($"timestamp", "5 second"),$"`type`").count()val query = rs.writeStream.outputMode("update").format("console").option("truncate", "false").start()query.awaitTermination()}
}编写代码之后,在hadoop101上启动端口并发送数据,发送一下4条数据,并且最后一条作为延迟数据,最后一条数据延迟发送但不能超过水位线5分钟。
1001,2020-08-06 16:08:54,A
1002,2020-08-06 16:08:57,B
1003,2020-08-06 16:08:58,B
1004,2020-08-06 16:08:52,A 延迟数据
查看ide 控制台打印效果:


对类型为A的数据进行了累加。
注意事项:
- output mode输出模式必须是Append或者Update。Complete完整模式要求保留所有聚合数据,因此不能使用水位线;
- 聚合操作必须有事件时间的列或者基于事件时间的窗口;
- 聚合操作中使用的时间列必须和事件时间列相同;
- withWatemark必须写在聚合操作前,如果写在groupby,count算子后面则无效;
7)Join
从Spark2.3开始,Structed Streaming支持流跟流join, Structed Streaming支持任何字段的inner join,进行join时必须指定以下条件:
- 在两条流上定义水位线延迟,一边引擎知道输入流可以延迟多久
- 定义两个输入流的join条件 1.join时加上时间范围 2.join时加上窗口事件时间
本地代码测试:
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession//1001,imporession1,2020-08-07 10:00:00
//1002,imporession1,2020-08-07 10:05:00
//1003,imporession1,2020-08-07 10:08:00//1001,clieck1,2020-08-07 11:00:00
//1002,clieck1,2020-08-07 11:00:00
//1003,clieck1,2020-08-07 13:00:00 超出时间范围case class ImpressionData(impressionAdId: Int, data: String, impressionTime: Timestamp)case class ClickData(clickId: Int, data: String, clickTime: Timestamp)object JoinTest {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setAppName("test").setMaster("local[*]").set("spark.sql.shuffle.partitions", "12")val sparkSessioin = SparkSession.builder().config(sparkConf).getOrCreate()val line1 = sparkSessioin.readStream.format("socket").option("host", "hadoop101").option("port", "7777").load()val line2 = sparkSessioin.readStream.format("socket").option("host", "hadoop101").option("port", "7778").load()import sparkSessioin.implicits._val impressionStream = line1.as[String].filter(item => item.split(",").length == 3).mapPartitions(partitions => {partitions.map(item => {val datas = item.split(",")val impressionAdId = datas(0).toIntval data = datas(1)val timestamp = Timestamp.valueOf(datas(2))ImpressionData(impressionAdId, data, timestamp)})}).withWatermark("impressionTime", "2 hours")val clickStream = line2.as[String].filter(item => item.split(",").length == 3).mapPartitions(partitions => {partitions.map(item => {val datas = item.split(",")val clikecId = datas(0).toIntval data = datas(1)val timestamp = Timestamp.valueOf(datas(2))ClickData(clikecId, data, timestamp)})}).withWatermark("clickTime", "3 hours")import org.apache.spark.sql.functions._val result = impressionStream.join(clickStream, expr("impressionAdId=clickId and clickTime>=impressionTime " +" and clickTime<=impressionTime+ interval 1 hour"))val query = result.writeStream.outputMode("Append").format("console").option("truncate", "false").start()query.awaitTermination()}
}编写完之后进行测试:

其中第三组数据,1003,click数组事件时间超出了join条件事件时间范围,查看ide控制台join结果。


1003延迟数据并没有join上。对于inner join 内部水位线的时间约束是可选的,但是对于left join和right join水位线约束就必须加上了,这是因为当存在外连接的时候会有null值,引擎必须知道输入行什么时候不匹配。
修改代码,如下,join时加指定第三个参数join类型:
val result = impressionStream.join(clickStream, expr("impressionAdId=clickId and clickTime>=impressionTime " +" and clickTime<=impressionTime+ interval 1 hour"), "left")注意事项:
- 采用外连join结果是否为null取决于水位线延迟和时间范围条件;
- 在微批处理引擎中,水位线在微批次末尾进行处理,下一个微批处理来更新水位线并更新状态并输出外部结果,因此如果流中没有接收到新数据,则外部结果的生产可能会有延迟(flink也是这样,因此需要重写trigger)。简而言之,如果连接的两个输入流中任何一个流在一段时间内为接收到数据,则外部输出可能会有延迟;
Structed Streaming也支持流跟静态数据的join(可以实现维度表关联事实表),一下是支持类型。

其他信息:
- join操作级联,df1.join(df2,...).join(df3,...).join(df4,...)
- 从spark2.4开始 join操作只能用Append模式,尚不支持其他两种模式
- 从spark2.4开始,有一些操作无法用于join:
- 在join前无法对流式数据进行聚合操作;
- 在join前无法使用mapGroupsWithState和flatMapGroupsWithState算子;
8)流式重复数据删除
Structred Streaming,可以根据唯一标示,删除重复数据:
package com.yyds.testimport java.sql.Timestampimport org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession//1001,name1,2020-08-07 11:00:00
//1001,name2,2020-08-07 11:30:00
case class Student2(uid: Int, name: String, time: Timestamp)object DuplicationTest {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setAppName("test").setMaster("local[*]").set("spark.sql.shuffle.partitions", "12")val sparkSession = SparkSession.builder().config(sparkConf).getOrCreate()val line = sparkSession.readStream.format("socket").option("host", "hadoop101").option("port", "7777").load()import sparkSession.implicits._val result = line.as[String].map(item => {val datas = item.split(",")val uid = datas(0).toIntval name = datas(1)val time = Timestamp.valueOf(datas(2))Student2(uid, name, time)})val data = result.dropDuplicates("uid")val query = data.writeStream.outputMode("update").format("console").option("truncate", "false").start()query.awaitTermination()}
}

带水位线的去重,会根据水位线时间去判断重复数据,不带水位线则是全局判断:
val data=result.withWatermark("time","10 seconds").dropDuplicates("uid",time)9)处理多个水位线
流跟流进行join,合并在一起,每个流都会有各自的水位线阀值,结构化流在执行操作时,会分别跟踪每个输入流中出现的最大事件时间,根据相应延迟计算水位线,并选择其中一个水位线作为全局水位线用于状态操作。
默认情况下,选择最小值作为全局水位线。换句话说,全局水位线将以最慢的流的速度安全地移动,并且结果将因此而延迟。
从spark2.4开始,可以配置spark.sql.streaming.multipleWatermarkPolicy此参数来控制全局水位线,默认值是min,延迟最高的流的水位线。可以将此值设置为max,以延迟最低流的水位线作为全局水位线,这使全局最快的速度移动,但是副作用就是速度较慢的流中,数据会被丢弃。
10)不支持的操作
- 不支持多个流的聚合操作(即DataFrame上的聚合链)
- 不支持使用limit和take
- 不支持使用distinct
- 仅在聚合操作之后,并且输出模式是Complete,才能使用Sort排序操作
- 无法直接使用count()函数获取流的个数,只能通过ds.groupby().count()获取分组后的个数
- 无法直接使用foreach()函数,只能使用ds.writeStream.foreach()
- Show()用的是console sink
当前版本如果使用这些操作时会遇到一个AnalysisException错误。
11)使用foreach和foreachBatch
foreach和foreachBatch方法都可以定义输出逻辑,区别在于foreach是对于每行数据,foreachBatch是对于每个微批数据。
data.writeStream.foreach(new ForeachWriter[Student2] {override def open(partitionId: Long, epochId: Long): Boolean = ???override def process(value: Student2): Unit = ???override def close(errorOrNull: Throwable): Unit = ???
})
data.writeStream.foreachBatch(new VoidFunction2[Dataset[Student2], java.lang.Long] {override def call(v1: Dataset[Student2], v2: lang.Long): Unit = {}
})
data.writeStream.foreachBatch { (batchDF: Dataset[Student2], batchId: Long) =>batchDF.persist()batchDF.write.format("").save() //locationbatchDF.write.format("").save() //location2batchDF.unpersist()
}Foreach写法跟flink类似,open打开资源连接,process处理数据,close关闭相应资源。
12)Trigger
流查询的触发设置定义了流数据处理的时间,无论该查询是具有固定批处理间隔的微批查询还是作为连续处理的查询。
以下是受支持的各种触发器:
- 未指定,默认触发器,该模式下,上一个微批处理完后才会生成微批次处理。
- 固定间隔微批,查询以微批次模式执行,该模式下,微批次将按用户指定的时间间隔启动。如果前一个微批处理完了,并且是在间隔时间内的,那么会进行等待,间隔时间结束后再执行下一微批,如果前一批数据处理时间大于间隔时间,则结束后立马就执行下一批微批,没有等待时间。如果没有新数据,则不会启动。
- 一次性微批,该查询仅执行一个微批处理来处理所有数据,然后停止。如果是跑定时任务这会很有用。
- 连续固定的检查点间隔模式,查询将以新的低延迟,连续处理模式执行,连续处理是spark2.3中引入的一种新的执行模式,可实现几乎1ms的端到端延迟,并保证容错。与默认触发器相比,该模式可以实现精准以下消费,但是延迟最多只能实现100ms。这种模式不支持水位线操作。

13)对接Kafka
导入所需jar包:
<dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql-kafka-0-10_2.12</artifactId><version>3.0.0</version>
</dependency>kafka版本必须是0.11.0.0或更高。
必选配置:
| Option | Value | Meaning |
| assign | {“topicA:”[0,1],”topicB”:[0,1]} | json串的形式监控topic。assign,subscribe,subscribeParttern三种只能选择其中一种 |
| subscribe | topicA,topicB | 以逗号分割的形式填写 |
| subscribePattern | JAVA regex string | 正则表达式来匹配对应topic |
| kafka.bootstrap.servers | Hadoop101:9092,hadoop102:9092 ,hadoop103:9092 | kafka集群地址 |
可选配置:
| Option | Value | Defaule | Query type | Meaning |
| startingOffsetByTimestamp | {"topicA":{"0": 1000, "1": 1000}, "topicB": {"0": 2000, "1": 2000}} | none | streaming and batch | 查询开始时每个分区对 应的时间戳标记,如果 时间戳标记不存在偏 移量则查询会失败。 此参数相当于KafkaConsumer.offsets ForTimes |
| startingOffsets | "earliest", "latest" (streaming only), or json string """ {"topicA":{"0":23,"1":-1},"topicB":{"0":-2}} """ | "latest" for streaming, "earliest" for batch | streaming and batch | 查询开始的起点,每个分区对应开始查询的最早的偏移量,在json串中-2代表最早的偏移量,-1代表最新的片偏移量。 |
| endingOffsetsByTimestamp | json string """ {"topicA":{"0": 1000, "1": 1000}, "topicB": {"0": 2000, "1": 2000}} """ | latest | batch query | 批处理查询的结束时 的终点,json串中指定 每个分区指定结束时间 戳标记。 |
| endingOffsets | latest or json string {"topicA":{"0":23,"1":-1},"topicB":{"0":-1}} | latest | batch query | 批处理查询结束时的终点,json串为每个分区指定结束时的偏移量。-1代表最新,-2不可用使用。 |
| failOnDataLoss | true or false | true | streaming and batch | 在topic已删除或者偏移量不存在的情况下,是否查询失败。当你认为是错误的警告时,可以禁用了。 |
| kafkaConsumer.pollTimeoutMs | Long | 512 | streaming and batch | 执行程序时,从kafka消费数据进行对接的超时时长,单位毫秒 |
| fetchOffset.numRetries | Int | 3 | streaming and batch | 程序对接kafka重试次数 |
| fetchOffset.retryIntervalMs | Long | 10 | streaming and batch | 失败后重试中间等待的时长,单位毫秒 |
| maxOffsetsPerTrigger | Long | none | streaming and batch | 每个触发间隔处理的最大偏移量速率限制,指定的偏移总数将按比例分给对应的topic 分区 |
| minPartitions | Int | none | streaming and batch | 程序从kafka读取的最小分区数,Spark分区对接kafka分区默认映射关系是1:1,如果此参数设置了比topic分区数还大,那么spark会将topic分区切成多个小分区 |
| groupIdPrefix | String | spark-kafka-source | streaming and batch | 结构化流查询时生成的使用者标识符的前缀(group.id),如果设置了kafka.group.id则可以忽略 |
| kafka.group.id | String | none | streaming and batch | 消费者组设置 |
| includeHeaders | boolean | false | streaming and batch | 是否在数据行中包含kafka header信息 |
消费者缓存:
初始化Kafka消费者很耗时,尤其是在流处理场景当中,因此Spark利用Apache Commons Pool进行了将kafka信息缓存在executor上,缓存信息包括Topic name,Topic Partition,Group Id。
以下是对池的配置:
| Property Name | Default | Meaning | Since Version |
| spark.kafka.consumer.cache.capacity | 64 | 缓存使用的最大数量,这是一个软限制,不会影响程序正常运行 | 3.0 |
| spark.kafka.consumer.cache.timeout | 5 minutes | 消费者信息可以在池中闲置的最大时间 | 3.0 |
| spark.kafka.consumer.cache.evictorThreadRunInterval | 1 minutes | 池中定时驱逐空闲状态线程的间隔时间 | 3.0 |
| spark.kafka.consumer.cache.jmx.enable | False | 创建池的时候是否启用JMX,默认不启用 | 3.0 |
数据写出到Kafka:
向外写出,结构化流支持批处理和流处理下图是两个例子,读的时候也一样read和readStream。


当模式指定为writeStream时为流式处理,当模式指定为write时为批处理 。
6、统计count案例
创建topic:
[root@hadoop102 module]# kafka_2.11-2.4.0/bin/kafka-topics.sh --zookeeper hadoop102:2181/kafka_2.4 --create --replication-factor 2 --partitions 10 --topic register_topic编写生产者代码发送数据:
import java.util.Propertiesimport org.apache.kafka.clients.producer.{KafkaProducer, ProducerRecord}
import org.apache.spark.{SparkConf, SparkContext}object RegisterProducer {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setAppName("registerProducer").setMaster("local[*]")val ssc = new SparkContext(sparkConf)ssc.textFile("file://"+this.getClass.getResource("/register.log").getPath, 10).foreachPartition(partition => {val props = new Properties()props.put("bootstrap.servers", "hadoop101:9092,hadoop102:9092,hadoop103:9092")props.put("acks", "1")props.put("batch.size", "16384")props.put("linger.ms", "10")props.put("buffer.memory", "33554432")props.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer")props.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer")val producer = new KafkaProducer[String, String](props)partition.foreach(item => {val msg = new ProducerRecord[String, String]("register_topic",item)producer.send(msg)})producer.flush()producer.close()})}
}数据格式,根据第二个类型字段统计count个数:

编写结构化流代码:
import org.apache.spark.SparkConf
import org.apache.spark.sql.{Row, SparkSession}case class Data(appName: String, value: Int)object WortCount {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setAppName("word count").setMaster("local[*]").set("spark.sql.shuffle.partitions", "10") //和topic 分区数一致val sparkSession = SparkSession.builder().config(sparkConf).getOrCreate()val df = sparkSession.readStream.format("kafka").option("kafka.bootstrap.servers", "hadoop101:9092,hadoop102:9092,hadoop103:9092").option("subscribe", "register_topic").option("startingOffsets", "earliest").option("enable.auto.commit", "false") //测试不提交偏移量.option("maxOffsetsPerTrigger", "3000").load()import sparkSession.implicits._val result = df.selectExpr("cast(value as string)").as[String].filter(item => item.split("\t").length == 3).mapPartitions((partition: Iterator[String]) => partition.map(item => {val datas = item.split("\t")val app_name = datas(1) match {case "1" => "PC"case "2" => "APP"case _ => "Other"}Data(app_name, 1)})).groupBy("appName").count()val query = result.writeStream.outputMode("update").format("console").option("truncate", "false").start()query.awaitTermination()}
}

经过测试,aqe特性对结构化流不起作用,只适用于批处理。
将结果写入mysql:
建表语句:
create table wordcount(
id int PRIMARY KEY AUTO_INCREMENT,
appname varchar(20),
`value` int,
UNIQUE INDEX index_appname(appname)
)ENGINE=INNODB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8;准备相关jar包和工具类:
<dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><version>1.1.16</version>
</dependency>
<dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.29</version>
</dependency>import java.io.InputStream;
import java.util.Properties;/**** 读取配置文件工具类*/
public class ConfigurationManager {private static Properties prop = new Properties();static {try {InputStream inputStream = ConfigurationManager.class.getClassLoader().getResourceAsStream("comerce.properties");prop.load(inputStream);} catch (Exception e) {e.printStackTrace();}}//获取配置项public static String getProperty(String key) {return prop.getProperty(key);}//获取布尔类型的配置项public static boolean getBoolean(String key) {String value = prop.getProperty(key);try {return Boolean.valueOf(value);} catch (Exception e) {e.printStackTrace();}return false;}}import com.alibaba.druid.pool.DruidDataSourceFactory;import javax.sql.DataSource;
import java.io.Serializable;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.Properties;/*** 德鲁伊连接池*/
public class DataSourceUtil implements Serializable {public static DataSource dataSource = null;static {try {Properties props = new Properties();props.setProperty("url", ConfigurationManager.getProperty("jdbc.url"));props.setProperty("username", ConfigurationManager.getProperty("jdbc.user"));props.setProperty("password", ConfigurationManager.getProperty("jdbc.password"));props.setProperty("initialSize", "5"); //初始化大小props.setProperty("maxActive", "20"); //最大连接props.setProperty("minIdle", "5"); //最小连接props.setProperty("maxWait", "60000"); //等待时长props.setProperty("timeBetweenEvictionRunsMillis", "2000");//配置多久进行一次检测,检测需要关闭的连接 单位毫秒props.setProperty("minEvictableIdleTimeMillis", "600000");//配置连接在连接池中最小生存时间 单位毫秒props.setProperty("maxEvictableIdleTimeMillis", "900000"); //配置连接在连接池中最大生存时间 单位毫秒props.setProperty("validationQuery", "select 1");props.setProperty("testWhileIdle", "true");props.setProperty("testOnBorrow", "false");props.setProperty("testOnReturn", "false");props.setProperty("keepAlive", "true");props.setProperty("phyMaxUseCount", "100000");dataSource = DruidDataSourceFactory.createDataSource(props);} catch (Exception e) {e.printStackTrace();}}//提供获取连接的方法public static Connection getConnection() throws SQLException {return dataSource.getConnection();}// 提供关闭资源的方法【connection是归还到连接池】// 提供关闭资源的方法 【方法重载】3 dqlpublic static void closeResource(ResultSet resultSet, PreparedStatement preparedStatement,Connection connection) {// 关闭结果集// ctrl+alt+m 将java语句抽取成方法closeResultSet(resultSet);// 关闭语句执行者closePrepareStatement(preparedStatement);// 关闭连接closeConnection(connection);}private static void closeConnection(Connection connection) {if (connection != null) {try {connection.close();} catch (SQLException e) {e.printStackTrace();}}}private static void closePrepareStatement(PreparedStatement preparedStatement) {if (preparedStatement != null) {try {preparedStatement.close();} catch (SQLException e) {e.printStackTrace();}}}private static void closeResultSet(ResultSet resultSet) {if (resultSet != null) {try {resultSet.close();} catch (SQLException e) {e.printStackTrace();}}}
}import java.sql.{Connection, PreparedStatement, ResultSet}trait QueryCallback {def process(rs: ResultSet)
}class SqlProxy {private var rs: ResultSet = _private var psmt: PreparedStatement = _/*** 执行修改语句** @param conn* @param sql* @param params* @return*/def executeUpdate(conn: Connection, sql: String, params: Array[Any]): Int = {var rtn = 0try {psmt = conn.prepareStatement(sql)if (params != null && params.length > 0) {for (i <- 0 until params.length) {psmt.setObject(i + 1, params(i))}}rtn = psmt.executeUpdate()} catch {case e: Exception => e.printStackTrace()}rtn}/*** 执行查询语句* 执行查询语句** @param conn* @param sql* @param params* @return*/def executeQuery(conn: Connection, sql: String, params: Array[Any], queryCallback: QueryCallback) = {rs = nulltry {psmt = conn.prepareStatement(sql)if (params != null && params.length > 0) {for (i <- 0 until params.length) {psmt.setObject(i + 1, params(i))}}rs = psmt.executeQuery()queryCallback.process(rs)} catch {case e: Exception => e.printStackTrace()}}def shutdown(conn: Connection): Unit = DataSourceUtil.closeResource(rs, psmt, conn)
}准备连接数据库配置文件放到resource下:
jdbc.url=jdbc:mysql://hadoop101:3306/qz_course?useUnicode=true&characterEncoding=utf8&serverTimezone=Asia/Shanghai&useSSL=false
jdbc.user=root
jdbc.password=123456修改结构化流代码:
import java.sql.Connectionimport com.yyds.test.util.{DataSourceUtil, SqlProxy}
import org.apache.spark.SparkConf
import org.apache.spark.sql.{ForeachWriter, Row, SparkSession}case class Data(appName: String, value: Int)object WortCount {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setAppName("word count").setMaster("local[*]").set("spark.sql.shuffle.partitions", "10") //和topic 分区数一致val sparkSession = SparkSession.builder().config(sparkConf).getOrCreate()val df = sparkSession.readStream.format("kafka").option("kafka.bootstrap.servers", "hadoop101:9092,hadoop102:9092,hadoop103:9092").option("subscribe", "register_topic").option("startingOffsets", "earliest").option("enable.auto.commit", "false") //测试不提交偏移量.option("maxOffsetsPerTrigger", "3000").load()import sparkSession.implicits._val result = df.selectExpr("cast(value as string)").as[String].filter(item => item.split("\t").length == 3).mapPartitions((partition: Iterator[String]) => partition.map(item => {val datas = item.split("\t")val app_name = datas(1) match {case "1" => "PC"case "2" => "APP"case _ => "Other"}Data(app_name, 1)})).groupBy("appName").count()val query = result.writeStream.outputMode("update").foreach(new ForeachWriter[Row] {var client: Connection = _var sqlProxy: SqlProxy = _override def open(partitionId: Long, epochId: Long): Boolean = {client = DataSourceUtil.getConnectionsqlProxy = new SqlProxytrue}override def process(value: Row): Unit = {val appName = value.getString(0)val count = value.getLong(1)sqlProxy.executeUpdate(client, "insert into wordcount(appname,`value`) values(?,?) on duplicate key update appname=?,`value`=?", Array(appName, count, appName, count))}override def close(errorOrNull: Throwable): Unit = {client.close()}}).option("truncate", "false").start()query.awaitTermination()}
}查看效果:


yarn提交使用checkpoint:
代码去掉localhost[*]。输出端加上checkpoint选项:


修改pom.xml文件,将spark相关的包加上provided:
<dependencies><!-- Spark的依赖引入 --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.12</artifactId><scope>provided</scope><version>3.0.0</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.12</artifactId><scope>provided</scope><version>3.0.0</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-hive_2.12</artifactId><scope>provided</scope><version>3.0.0</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql-kafka-0-10_2.12</artifactId><scope>provided</scope><version>3.0.0</version></dependency><dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><version>1.1.16</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.29</version></dependency>
</dependencies><build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.6.1</version><!-- 所有的编译都依照JDK1.8来搞 --><configuration><source>1.8</source><target>1.8</target></configuration></plugin><plugin><groupId>org.scala-tools</groupId><artifactId>maven-scala-plugin</artifactId><version>2.15.1</version><executions><execution><id>compile-scala</id><goals><goal>add-source</goal><goal>compile</goal></goals></execution><execution><id>test-compile-scala</id><goals><goal>add-source</goal><goal>testCompile</goal></goals></execution></executions></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-assembly-plugin</artifactId><configuration><archive><manifest></manifest></archive><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration></plugin><plugin><groupId>net.alchim31.maven</groupId><artifactId>scala-maven-plugin</artifactId><version>3.2.2</version><executions><execution><!-- 声明绑定到maven的compile阶段 --><goals><goal>compile</goal><goal>testCompile</goal></goals></execution></executions></plugin><!-- 用于项目的打包插件 --><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-assembly-plugin</artifactId><version>3.0.0</version><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin></plugins>
</build>然后打包,将jar包上传到集群上:
[root@hadoop103 ~]# spark-submit --master yarn --deploy-mode cluster --packages org.apache.spark:spark-sql-kafka-0-10_2.12:3.0.0 --driver-memory 1g --num-executors 5 --executor-cores 2 --executor-memory 2g --queue spark --class com.yyds.test.WortCount spark3test-1.0-SNAPSHOT-jar-with-dependencies.jar


checkpoint存储信息,可用于第二次启动恢复数据:

7、topN例子
经过测试发现Spark3.0结构化流支持limit操作了(官网仍然没有修改),那么可以排序后再limit去求topN,输出模式必须是Complete
case class Data(appName: String, value: Int)object WortCount {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setAppName("word count").setMaster("local[*]").set("spark.sql.shuffle.partitions", "10") //和topic 分区数一致val sparkSession = SparkSession.builder().config(sparkConf).getOrCreate()val df = sparkSession.readStream.format("kafka").option("kafka.bootstrap.servers", "hadoop101:9092,hadoop102:9092,hadoop103:9092").option("subscribe", "register_topic").option("startingOffsets", "earliest").option("enable.auto.commit", "false") //测试不提交偏移量.option("maxOffsetsPerTrigger", "3000").load()import sparkSession.implicits._import org.apache.spark.sql.functions._val result = df.selectExpr("cast(value as string)").as[String].filter(item => item.split("\t").length == 3).mapPartitions((partition: Iterator[String]) => partition.map(item => {val datas = item.split("\t")val app_name = datas(1) match {case "1" => "PC"case "2" => "APP"case _ => "Other"}Data(app_name, 1)})).groupBy("appName").count().orderBy(desc("count")).limit(1)val query = result.writeStream.outputMode("Complete").format("console").start()query.awaitTermination()}
}六、Spark 内存管理
1、下载源码
下载地址:Index of /dist/spark
2、Spark1.5.2源码解读
当代码开始运行比如Spark Streaming,首先声明StreamingContext对象:

点击StreamingContext方法查看源码,用IDE代码下好的源码 Spark1.5.2。
跳转到 org.apache.spark.streaming包下的StreamingContext。
源码中可以看出调用了StreamingContext.createNewSparkContext方法,继续点击查看源码:
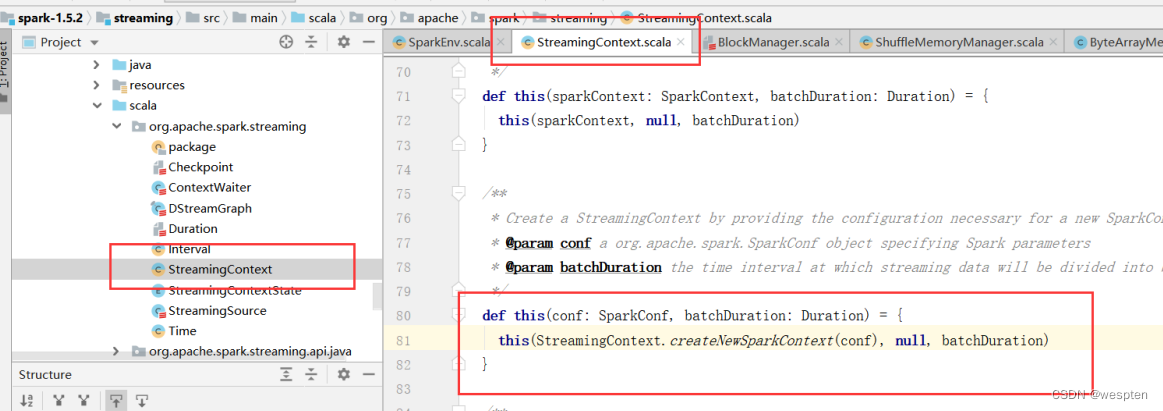
在该类877行方法中,实例化了SparkContext,继续点击查看源码:

该类为org.apache.spark包下的SparkContext对象:

代码217行处声明了SparkEnv对象,并用“_”符合占坑,该对象用于后续设置各Spark默认参数:

在SparkContext对象的389行处,在SparkConf开始设置各相关系统参数:

在代码450行处创建了SparkEnv对象,点击createSparkEnv方法查看源码:

该方法中调用了SparkEnv.createDriveEnv方法,继续点击查看源码:

跳转到了org.apache.spark下的SparkEnv对象,查看createDriverEnv方法:

可以看到该方法中对driver的地址和端口号都进行了判断和获取。继续点击create方法查看源码:

在该类的234行声明了create方法:

在该方法中可以看到,声明了Spark默认的序列化,并且通过反射的方式获取构造器实例化:


继续往下看可以看到,在325行设置了新类型的shuffle,为SortShuffle,在代码329行创建了ShuffleMemoryManager,查看该方法:

跳转到了org.apache.spark.shuffle包下的ShuffleMemoryManager,该类对应的伴生对象create方法中声明了shuffle所需的内存占比:


查看ShuffleMemoryManager下的create方法中的maxMemory值,可以看出方法getMxMemory方法中,指定shuffle默认可用内存为: 系统可用最大内存*0.2*0.8。
所以可以在Spark1.5.2版本中可以通过在SparkConf对象设置spark.shuffle.memoryFraction参数来调整shuffle所需内存占比:

知道了shuffle默认内存后再看getPageSize方法,查看pageSize大小,查看注释可以看出,开发者如果没用设置spark.buffer.pageSize系统会默认设置,该pagesize的计算方式为:
shuffle所需内存/cpu core的个数/安全系数(16)。

通过源码可以知道shuffle内存是由shuffleMemoryManager类管理,继续往下看。
可以看到在Spark1.5.2中可以设置Spark.shuffle.blockTransferService参数来设置程序之间传输shuffle和缓存块的实现,有netty和nio两种实现。根据官网描述该选项是Spark1.2开始默认,并且在Spark1.5.0中不推荐使用nio块传输,并且在Spark1.6.0中删除。

继续往下,查看blockManager:

调用了org.apache.spark.storage包下的BlockManager的构造方法:

可以看出第5个参数是设置最大内存的:

在返回上一层的方法,查看第5个参数对应的方法:

可以得知在Spark1.5.2中Storage默认所占的内存比为 系统可运行最大内存*0.6*0.9。
可以通过在SparkConf设置spark.storage.memoryFraction参数来改变Storage所需内存比。

继续看BlockManager中的代码,可以看出Spark针对块的读写,最大会开启128个线程:

继续查看MemoryStor方法:

在MemoryStore类中可以看到,在Storage内存中会有0.2占比的展开空间内存,此空间不是事先保留的,而是通过删除现有块动态分配的。

可以看出代码中默认关闭外部随机服务,运行外部shuffle的端口号为7337,默认关闭合并随机播放期间创建的中间文件。

通过源码得知在Spark1.5.2中Storage所需内存占比由BlockManager控制,后续还有控制广播实现的和缓存的Manager。


3、Spark1.6.0源码解读
当代码开始运行比如Spark Streaming,首先声明StreamingContext对象:

点击StreamingContext方法查看源码 用IDE代码下好的源码 Spark1.6.0。
跳转到 org.apache.spark.streaming包下的StreamingContext,点击构造方法:

点击StreamingContext.createNewSparkContext方法,源码中创建了SparkContext对象:

再点击对应方法查看org.apache.spark下的SparkContext类代码:

在源码223行中,声明了SparkEnv对象,并用“_”占坑:

在源码396行声明Spark对应配置:

找到源码457行创建SparkEnv对象:


继续点击SparkEnv.createDriverEnv方法查看源码,跳转到org.apache.spark包下的SparkEnv类。可以看出该方法会对driver的地址和端口进行判断和获取再点击方法create查看具体代码:
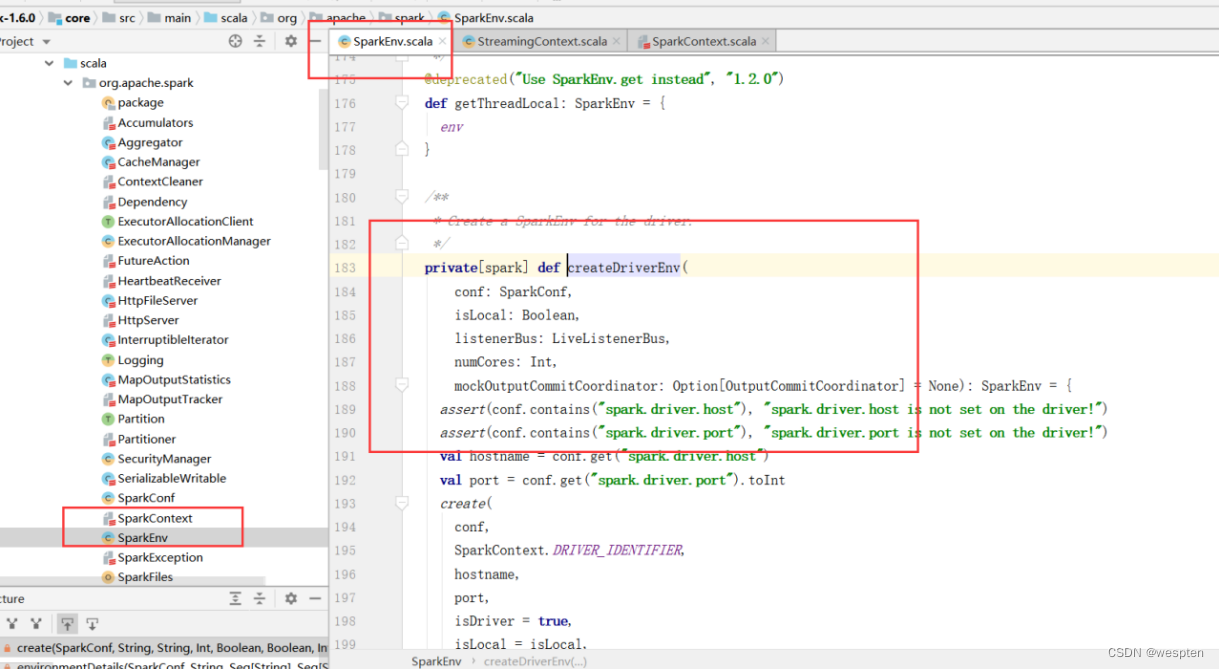

在create方法中指定了spark序列化方式,默认为java序列化并且是有反射得到构造器实例化:


在源码345行声明了spark 1.6.0 spark shuffl 默认为sort shuffle:

代码349行处通过spark.memory.useLegacyMode参数来判断内存管理使用静态管理还是动态管理,默认此参数是false,在Spark1.6.0当中内存管理进行了修改参数为false所以默认采用动态管理。如果要使用老版本静态管理则可以在SparkConf对象里将参数spark.memory.useLegacyMode为true。

先查看静态内存管理类StaticMemoryManager类,可以看出老版本静态管理内存的代码都被移动到了getMaxExecutionMemory和getMaxStorageMemory。

从源码可以看出:
StorageMemory内存占比为 系统最大内存*0.6*0.9。
ShuffleMemory 内存占比为 系统最大内存*0.2*0.8。

再看动态内存管理类,org.apache.spark.memory包下的UnifiedMemoryManager:

从源码中可以看出保留内存为300MB,代码注释也写明了假如有1G的JVM,实际用于执行计算和存储的内存为(1024-300)*0.75=543MB:

再看该类下apply方法,获取最大内存的方法,先会通过spark.testing.memory参数去获取,如果没有设置默认为系统可运行最大内存,对保留内存spark.testing.reservedMemory参数进行判断如果存在sparkConf里存在该配置则给0,如果没有此参数则给默认系统参数300MB。
然后会对保留内存乘以1.5的倍数计算出最小系统内存,对当前系统可运行的内存进行判断如果当前系统可运行内存小于最小系统内存则抛出异常提示增大内存大小。
最后计算可用内存,计算方式为系统可运行内存减去预留内存(默认300MB),再乘以spark.memory.fraction参数里的值(默认0.75)得出可用内存。

继续看该方法中实例化了伴生类。


从代码注释出可以看出,执行计算和存储共享区域为总堆空间-300MB,通过spark.memory.fraction配置共享区域内存的比值,执行计算和存储的边界由spark.memory.storageFraction决定默认0.5,也就是说子共享内存中执行计算和存储所需内存各占一半。
存储内存可以借用执行内存,执行内存也可以借用存储内存,直到各区域恢复空间。

源码中会进行判断,始终保持onHealExecutionMemoryPool.poolSize+StorageMemoryPool.poolSize=最大内存(执行计算和存储的共享内存)。

再看父类,父类为org.apache.spark.memory包下的MemoryManager。



根据上述源码中得出执行内存和存储内存的共享区域等于StorageMemoryPool所占内存+onHeapExecutionMemoryPool所占内存,下面方法中进行赋值操作。
并且堆外内存由参数spark.memory.offheap.size控制默认为0。




七、Spark3.0 内存优化
用以下三张表,做性能测试:

1、RDD
cache:
import org.apache.spark.SparkConf
import org.apache.spark.sql.{Row, SparkSession}object MemoryTuning {def main(args: Array[String]): Unit = {System.setProperty("HADOOP_USER_NAME", "root")val sparkConf = new SparkConf().setAppName("test")val sparkSession = SparkSession.builder().config(sparkConf).enableHiveSupport().getOrCreate()val ssc = sparkSession.sparkContextssc.hadoopConfiguration.set("fs.defaultFS", "hdfs://mycluster")ssc.hadoopConfiguration.set("dfs.nameservices", "mycluster")useRddCache(sparkSession)}def useRddCache(sparkSession: SparkSession): Unit = {val result = sparkSession.sql("select * from dwd.dwd_course_pay ").rddresult.cache()result.foreachPartition((p: Iterator[Row]) => p.foreach(item => println(item.get(0))))while (true) {//因为历史服务器上看不到,storage内存占用,所以这里加个死循环 不让sparkcontext立马结束}}
}打成jar,上传到集群并去跑yarn任务,并在yarn界面查看spark ui:
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 3 --executor-cores 2 --executor-memory 6g --queue spark --class com.yyds.sparksqltuning.MemoryTuning spark-sql-tuning-1.0-SNAPSHOT-jar-with-dependencies.jar
通过spark ui看到,rdd使用默认cache缓存级别,占用内存4.3GB,并且storage内存还不够,只缓存了75%。
kryo+序列化缓存:
停止任务,使用kryo序列化并且使用rdd序列化缓存级别。使用kryo序列化需要修改spark的序列化模式,并且需要进程注册类操作。
import java.sql.Timestampimport org.apache.spark.SparkConf
import org.apache.spark.sql.{Row, SparkSession}
import org.apache.spark.storage.StorageLevelobject MemoryTuning {def main(args: Array[String]): Unit = {System.setProperty("HADOOP_USER_NAME", "root")val sparkConf = new SparkConf().setAppName("test").set("spark.serializer", "org.apache.spark.serializer.KryoSerializer").registerKryoClasses(Array(classOf[CoursePay]))val sparkSession = SparkSession.builder().config(sparkConf).enableHiveSupport().getOrCreate()val ssc = sparkSession.sparkContextssc.hadoopConfiguration.set("fs.defaultFS", "hdfs://mycluster")ssc.hadoopConfiguration.set("dfs.nameservices", "mycluster")// useRddCache(sparkSession)useRddKryo(sparkSession)}case class CoursePay(orderid: String, discount: BigDecimal, paymoney: BigDecimal, createtime: Timestamp, dt: String, dn: String)def useRddKryo(sparkSession: SparkSession): Unit = {import sparkSession.implicits._val result = sparkSession.sql("select * from dwd.dwd_course_pay ").as[CoursePay].rddresult.persist(StorageLevel.MEMORY_ONLY_SER)result.foreachPartition((p: Iterator[CoursePay]) => p.foreach(item => println(item.orderid)))while (true) {//因为历史服务器上看不到,storage内存占用,所以这里加个死循环 不让sparkcontext立马结束}}
}打成jar包在yarn上运行,查看storage所占内存,内存占用减少了1445.8mb并且缓存了100%。使用序列化缓存配合kryo序列化,可以优化存储内存占用。

选择:


根据官网的描述,那么可以推断出,如果yarn内存资源充足情况下,使用默认级别MEMORY_ONLY是对CPU的支持最好的。但是序列化缓存可以让体积更小,那么当yarn内存资源不充足情况下可以考虑使用MEMORY_ONLY_SER配合kryo使用序列化缓存。
2、DataFrame、DataSet

根据官网描述,DataSet类似RDD,但是并不使用JAVA序列化也不使用Kryo序列化,而是使用一种特有的编码器进行序列化对象。那么来使用DataSet进行缓存。
cache:
package com.yyds.sparksqltuningimport java.sql.Timestampimport org.apache.spark.SparkConf
import org.apache.spark.sql.{Row, SparkSession}
import org.apache.spark.storage.StorageLevelobject MemoryTuning {def main(args: Array[String]): Unit = {System.setProperty("HADOOP_USER_NAME", "root")val sparkConf = new SparkConf().setAppName("test")val sparkSession = SparkSession.builder().config(sparkConf).enableHiveSupport().getOrCreate()val ssc = sparkSession.sparkContextssc.hadoopConfiguration.set("fs.defaultFS", "hdfs://mycluster")ssc.hadoopConfiguration.set("dfs.nameservices", "mycluster")// useRddCache(sparkSession)// useRddKryo(sparkSession)userDataSet(sparkSession)}
case class CoursePay(orderid: String, discount: BigDecimal, paymoney: BigDecimal, createtime: Timestamp, dt: String, dn: String)def userDataSet(sparkSession: SparkSession): Unit = {import sparkSession.implicits._val result = sparkSession.sql("select * from dwd.dwd_course_pay ").as[CoursePay]result.cache()result.foreachPartition((p: Iterator[CoursePay]) => p.foreach(item => println(item.orderid)))while (true) {}}
}提交任务,在yarn上查看spark ui,查看storage内存占用。内存使用612.3mb。




序列化缓存:
import java.sql.Timestampimport org.apache.spark.SparkConf
import org.apache.spark.sql.{Row, SparkSession}
import org.apache.spark.storage.StorageLevelobject MemoryTuning {def main(args: Array[String]): Unit = {System.setProperty("HADOOP_USER_NAME", "root")val sparkConf = new SparkConf().setAppName("test")val sparkSession = SparkSession.builder().config(sparkConf).enableHiveSupport().getOrCreate()val ssc = sparkSession.sparkContextssc.hadoopConfiguration.set("fs.defaultFS", "hdfs://mycluster")ssc.hadoopConfiguration.set("dfs.nameservices", "mycluster")// useRddCache(sparkSession)// useRddKryo(sparkSession)userDataSet(sparkSession)}
case class CoursePay(orderid: String, discount: BigDecimal, paymoney: BigDecimal, createtime: Timestamp, dt: String, dn: String)def userDataSet(sparkSession: SparkSession): Unit = {import sparkSession.implicits._val result = sparkSession.sql("select * from dwd.dwd_course_pay ").as[CoursePay]result.persist(StorageLevel.MEMORY_AND_DISK_SER)result.foreachPartition((p: Iterator[CoursePay]) => p.foreach(item => println(item.orderid)))while (true) {}}
}打成jar包,提交yarn。查看spark ui,storage占用内存646.2mb。和默认cache缓存级别差别不大。所以Dataframe可以直接使用cache。

所以从性能上来讲,DataSet,DataFrame是大于RDD的建议开发中使用DataSet、DataFrame。
八、Spark3.0 分区和参数控制
Spark sql默认shuffle分区个数为200,参数由spark.sql.shuffle.partitions控制,此参数只能控制Spark sql、DataFrame、DataSet分区个数。不能控制RDD分区个数。

所以如果两表进行join形成一张新表,如果新表的分区不进行缩小分区操作,那么就会有200份文件插入到hdfs上,这样就有可能导致小文件过多的问题。那么一般在插入表数据前都会进行缩小分区操作来解决小文件过多问题。
1、小文件过多场景
还是由上面视图三张表为例,进行join,先不进行缩小分区操作。查看效果。为了演示效果,先禁用了广播join。广播join下面会进行说明。
import org.apache.spark.SparkConf
import org.apache.spark.sql.{SaveMode, SparkSession}object PartitionTuning {def main(args: Array[String]): Unit = {System.setProperty("HADOOP_USER_NAME", "root")val sparkConf = new SparkConf().setAppName("test")
.set("spark.sql.autoBroadcastJoinThreshold","-1")val sparkSession = SparkSession.builder().config(sparkConf).enableHiveSupport().getOrCreate()val ssc = sparkSession.sparkContextssc.hadoopConfiguration.set("fs.defaultFS", "hdfs://mycluster")ssc.hadoopConfiguration.set("dfs.nameservices", "mycluster")testJoin(sparkSession)}def testJoin(sparkSession: SparkSession) = {//查询出三张表 并进行join 插入到最终表中val saleCourse = sparkSession.sql("select *from dwd.dwd_sale_course")val coursePay = sparkSession.sql("select * from dwd.dwd_course_pay").withColumnRenamed("discount", "pay_discount").withColumnRenamed("createtime", "pay_createtime")val courseShoppingCart = sparkSession.sql("select *from dwd.dwd_course_shopping_cart").drop("coursename").withColumnRenamed("discount", "cart_discount").withColumnRenamed("createtime", "cart_createtime")saleCourse.join(courseShoppingCart, Seq("courseid", "dt", "dn"), "right").join(coursePay, Seq("orderid", "dt", "dn"), "left").select("courseid", "coursename", "status", "pointlistid", "majorid", "chapterid", "chaptername", "edusubjectid", "edusubjectname", "teacherid", "teachername", "coursemanager", "money", "orderid", "cart_discount", "sellmoney","cart_createtime", "pay_discount", "paymoney", "pay_createtime", "dt", "dn").write.mode(SaveMode.Overwrite).insertInto("dws.dws_salecourse_detail")}
}提交yarn任务查看spark ui:

可以看到有2个stage的分区个数是200,这两个stage分别对应代码两处join。再往里面点击查看task的运行情况。

可以看到cpu申请到的task任务数也不平均,那么就会造成cpu空转的情况,就像当前hadoop102,hadoop103的运行情况一样。那么这也是需要解决的问题。先来看小文件过多问题,通过浏览器访问NameNode查看对应路径产生的文件个数。


一共产生了200份小文件,那么先解决小文件过多的问题。
2、解决小文件过多问题
解决小文件过多问题也非常简单,在spark当中一个分区最终落盘形成一个文件,那么解决小文件过多问题只需将分区缩小即可。在插入表前,添加coalesce算子指定缩小后的分区个数。那么使用此算子需要注意,coalesce算子缩小分区后那么实际处理插入数据的任务只有一个,可能会导致oom,所以需要适当控制,并且coalesce算子里的参数只能填写比原有数据分区小的值,比如当前表的分区是200,那么填写参数必须小于200,否则无效。当然缩小分区后任务的耗时肯定会变久。

修改参数后,打成jar包重新在yarn上运行此任务。最后write阶段分区个数是20,再来看对应hdfs路径下产生的文件个数。
![]()


最终产生的文件个数为20个。
3、合理利用CPU资源
根据提交命令:
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 3 --executor-cores 4 --executor-memory 2g --queue spark --class com.yyds.sparksqltuning.PartitionTuning spark-sql-tuning-1.0-SNAPSHOT-jar-with-dependencies.jar去向yarn申请的executor vcore资源个数为12个(num-executors*executor-cores),如果不修改spark sql分区个数,那么就会像上图所展示存在cpu空转的情况。这个时候需要合理控制shuffle分区个数。如果想要让任务运行的最快当然是一个task对应一个vcore,但是数仓一般不会这样设置,为了合理利用资源,一般会将分区(也就是task)设置成vcore的2倍到3倍。
修改参数spark.sql.shuffle.partitions,此参数默认值为200。

那么根据我们当前任务的提交参数,将此参数设置为24或36为最优效果。

设置完参数,yarn上提交任务,再次运行。
查看spark ui,点击相应stage,查看task详情:

这张图就很明显了,分别hadoop101,hadop102,hadoop103各自申请到4个vcore,然后每个vcore都分配到了3个任务,也都是差不多时间点结束。充分利用了cpu的资源。
那么spark sql当中修改分区的方式就有3种了,分别是算子coalesce、repartition和参数spark.sql.shuffle.partitions。
九、Spark3.0 广播join

Spark join策略中,如果当一张小表足够小并且可以先缓存到内存中,那么可以使用Broadcast Hash Join,其原理就是先将小表聚合到driver端,再广播到各个大表分区中,那么再次进行join的时候,就相当于大表的各自分区的数据与小表进行本地join,从而规避了shuffle。
广播join默认值为10MB,由spark.sql.autoBroadcastJoinThreshold参数控制:

那么观察历史任务,代码中我以将广播join禁用了。



有两处stage,shuffle分区为36.分别对应两个join。
再来看物理执行计划图:





两张表都走了SortMerge Join。那么根据表大小可以看出哪些是小表,哪些是大表。

可以针对小表join大表进行优化。
1、通过参数进行优化
.set("spark.sql.autoBroadcastJoinThreshold", "10485760 ")
修改完参数后,再次打成jar包,在yarn上运行此任务查看stage,和执行计划图。当然默认值为10mb,当表小于10mb也可以不设置。

可以看到多出了一个broadcast exchange的stage,此操作就是广播小表的操作。这个stage在spark3.0中会显示,2.x系列版本中不会显示。join产生shffle task的个数为36的stage只剩下一个了,说明一个join的stage已经被优化掉了。再来查看执行计划图。

第一个小表join大表的stage从sortmerge join转换为了broadcast hashjoin。


整个任务的耗时也从2.5分钟优化到了2.2分钟。
2、通过api进行优化
通过api进行广播join的优化,为了避免参数自动生效,先将参数禁用。

再通过api对小表进行广播,广播join方法来自org.apache.spark.sql.functions类下,所以使用api时需要先导包,然后对小表进行广播,再去做join。

再次打成jar包,在yarn上运行查看效果:


同样生效,相比来说api更加灵活,因为参数总有临界值,使用api可以自己来控制。此处优化效果1.9分钟。sql任务每次跑耗时都会有差异,但针对小表join大表,广播join一定是起到了优化的效果。

十、Spark3.0 数据倾斜
1、查看数据倾斜场景
根据此业务,为三表join,即课程表join购物车表再join支付表,造数据时,故意将购物车表数据的courseid(课程id)101和103数据各造了500万条,使两边join时产生数据倾斜。通过spark ui查看数据倾斜场景,先将广播join关闭,因为如果是小表join大表产生数据倾斜了广播join是可以优化掉数据倾斜的。

打成jar包,提交yarn运行任务。数据倾斜是在第一个join,小表join大表,所以我们查看stage对应的第一个产生shuffle并且分区是36的stage。

点击stage,查看task详情,点击duration,让task根据耗时排序:


可以看到有两个task发生了数据倾斜,再查看vcore的情况。

可以看到有2个task非常耗时,那么当spark sql如果产生数据倾斜了,就会导致某个task非常耗时从而影响整个stage的耗时,这个时候就需要解决数据倾斜。
2、提高并行度(没有用)
网上有很多帖子,说提高并行度可以解决数据倾斜,这种说法是错误的,数据倾斜的本质是某个key的数据量过大,经过shuffle都聚到同一个task了,所以这个时候只是把分区增大也是没用的。下面来测试下,修改spark.sql.shuffle.partitions分区数,将此参数设置为1000。
再来提交任务,查看spark ui图。


仍然存在数据倾斜情况:

所以仅仅是提高并行度,是不能解决数据倾斜问题的。
3、join
在小表join大表时如果产生数据倾斜,那么广播join可以直接规避掉此shuffle阶段。直接优化掉stage。并且广播join也是Spark Sql中最常用的优化方案。
4、打散大表 扩容小表
此方案是先将大表打散比如,现在业务中courseid是101和103两个值过多产生了数据倾斜,那么这个时候可以将大表的数据针对courseid进行打散操作,加上随机值,比如在courseid前加上0-9的随机值打散10分形成0_101,1_101,...,9_101。
打散之后为了让大表和小表join上,那么小表需进行扩容操作和大表对应的随机key能匹配上,那么小表就需要进行扩容操作。小表当中比如存在1条101数据,那么这个时候小表数据量得扩大10倍,并且加上前缀让key变成0_101,1_101,...,9_101。这样能与大表数据join上。
以下为代码处理,这里的实现思路:
- 打散大表:实际就是数据一进一出进行处理,对courseid前拼上随机前缀实现打散。
- 扩容小表:实际就是将DataFrame中每一条数据,转成一个集合,并往这个集合里循环添加10条数据,最后使用flatmap压平此集合,达到扩容的效果。
import org.apache.spark.SparkConf
import org.apache.spark.sql.{Row, SaveMode, SparkSession}import scala.collection.mutable.ArrayBuffer
import scala.util.Randomobject PartitionTuning {def main(args: Array[String]): Unit = {System.setProperty("HADOOP_USER_NAME", "root")val sparkConf = new SparkConf().setAppName("test").set("spark.sql.shuffle.partitions", "36").set("spark.sql.autoBroadcastJoinThreshold", "-1")val sparkSession = SparkSession.builder().config(sparkConf).enableHiveSupport().getOrCreate()val ssc = sparkSession.sparkContextssc.hadoopConfiguration.set("fs.defaultFS", "hdfs://mycluster")ssc.hadoopConfiguration.set("dfs.nameservices", "mycluster")testJoin2(sparkSession)}
/*** 打散大表 扩容小表 解决数据倾斜** @param sparkSession*/def testJoin2(sparkSession: SparkSession): Unit = {import sparkSession.implicits._val saleCourse = sparkSession.sql("select *from dwd.dwd_sale_course")val coursePay = sparkSession.sql("select * from dwd.dwd_course_pay").withColumnRenamed("discount", "pay_discount").withColumnRenamed("createtime", "pay_createtime")val courseShoppingCart = sparkSession.sql("select *from dwd.dwd_course_shopping_cart").withColumnRenamed("discount", "cart_discount").withColumnRenamed("createtime", "cart_createtime")//将大表打散 打散10份val newCourseShoppingCart = courseShoppingCart.mapPartitions((partitions: Iterator[Row]) => {partitions.map(item => {val courseid = item.getAs[Int]("courseid")val randInt = Random.nextInt(10)DwdCourseShoppingCart(courseid, item.getAs[String]("orderid"),item.getAs[String]("coursename"), item.getAs[java.math.BigDecimal]("cart_discount"),item.getAs[java.math.BigDecimal]("sellmoney"), item.getAs[java.sql.Timestamp]("cart_createtime"),item.getAs[String]("dt"), item.getAs[String]("dn"), randInt + "_" + courseid)})})//小表进行扩容 扩大10倍val newSaleCourse = saleCourse.flatMap(item => {val list = new ArrayBuffer[DwdSaleCourse]()val courseid = item.getAs[Int]("courseid")val coursename = item.getAs[String]("coursename")val status = item.getAs[String]("status")val pointlistid = item.getAs[Int]("pointlistid")val majorid = item.getAs[Int]("majorid")val chapterid = item.getAs[Int]("chapterid")val chaptername = item.getAs[String]("chaptername")val edusubjectid = item.getAs[Int]("edusubjectid")val edusubjectname = item.getAs[String]("edusubjectname")val teacherid = item.getAs[Int]("teacherid")val teachername = item.getAs[String]("teachername")val coursemanager = item.getAs[String]("coursemanager")val money = item.getAs[java.math.BigDecimal]("money")val dt = item.getAs[String]("dt")val dn = item.getAs[String]("dn")for (i <- 0 until 10) {list.append(DwdSaleCourse(courseid, coursename, status, pointlistid, majorid, chapterid, chaptername, edusubjectid,edusubjectname, teacherid, teachername, coursemanager, money, dt, dn, courseid + "_" + i))}list})
newSaleCourse.join(newCourseShoppingCart.drop("courseid").drop("coursename"),Seq("rand_courseid", "dt", "dn"), "right").join(coursePay, Seq("orderid", "dt", "dn"), "left").select("courseid", "coursename", "status", "pointlistid", "majorid", "chapterid", "chaptername", "edusubjectid", "edusubjectname", "teacherid", "teachername", "coursemanager", "money", "orderid", "cart_discount", "sellmoney","cart_createtime", "pay_discount", "paymoney", "pay_createtime", "dt", "dn").write.mode(SaveMode.Overwrite).insertInto("dws.dws_salecourse_detail")}case class DwdCourseShoppingCart(courseid: Int,orderid: String,coursename: String,cart_discount: java.math.BigDecimal,sellmoney: java.math.BigDecimal,cart_createtime: java.sql.Timestamp,dt: String,dn: String,rand_courseid: String)case class DwdSaleCourse(courseid: Int,coursename: String,status: String,pointlistid: Int,majorid: Int,chapterid: Int,chaptername: String,edusubjectid: Int,edusubjectname: String,teacherid: Int,teachername: String,coursemanager: String,money: java.math.BigDecimal,dt: String,dn: String,rand_courseid: String)}打成jar包,提交yarn任务,查看spark ui图。
观察task详情:

已经解决数据倾斜问题。
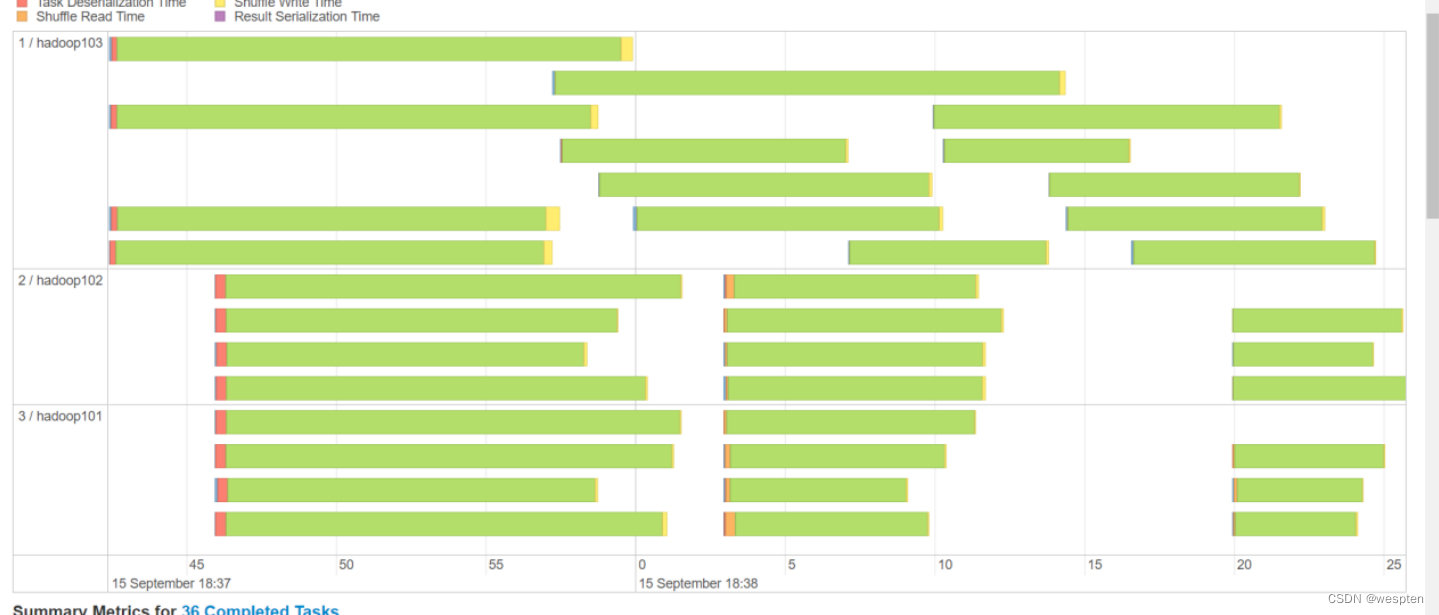
但是这个方案,虽然解决了数据倾斜但是更加耗时了,原来33秒变成43秒。

所以此方案虽然能解决数据倾斜,但是由于小表需要扩容,可能会更加耗时。建议产生严重数据倾斜时,结果出不来了那么可以采用此方案解决。
十一、Spark3.0 SMB JOIN
SMB JOIN用于大表join大表的优化。
SMB JOIN是sort merge bucket操作,需要进行分桶,首先会进行排序,然后根据key值合并,把相同key的数据放到同一个bucket中(按照key进行hash)。分桶的目的其实就是把大表化成小表。相同key的数据都在同一个桶中之后,再进行join操作,那么在联合的时候就会大幅度的减小无关项的扫描。
使用条件:
- 两表进行分桶,桶的个数必须相等;
- 两边进行join时,join列==排序列==分桶列;
还是以上面三张表为例,首先第一个join是课程表join购物车表,那么是小表join大表。得个join是购物车表join支付表,那么属于大表join大表,那么针对购物车表join支付表这个stage,来进行优化。
先看下原始不做优化的耗时1.3分钟:

两张表join前的排序时长总耗时为36.2秒和23.5秒,那么SMB Join的优化主要就是优化这两个排序时间的。

那么做SMB Join之前首先要对表进行分桶,下面为代码 。
1、Spark对表进行分桶
重新生成dwd表,生成分桶表。解析源数据,将数据导入到分桶表中。
import org.apache.spark.SparkConf
import org.apache.spark.sql.{SaveMode, SparkSession}object SMBJoinTuning {def main(args: Array[String]): Unit = {System.setProperty("HADOOP_USER_NAME", "root")val sparkConf = new SparkConf().setAppName("test").setMaster("local[*]")val sparkSession = SparkSession.builder().config(sparkConf).enableHiveSupport().getOrCreate()val ssc = sparkSession.sparkContextssc.hadoopConfiguration.set("fs.defaultFS", "hdfs://mycluster")ssc.hadoopConfiguration.set("dfs.nameservices", "mycluster")useBucket(sparkSession)}def useBucket(sparkSession: SparkSession) = {sparkSession.read.json("/user/yyds/ods/coursepay.log").write.partitionBy("dt", "dn").format("parquet").bucketBy(5, "orderid").sortBy("orderid").mode(SaveMode.Overwrite).saveAsTable("dwd.dwd_course_pay_cluster")sparkSession.read.json("/user/yyds/ods/courseshoppingcart.log").write.partitionBy("dt", "dn").bucketBy(5, "orderid").format("parquet").sortBy("orderid").mode(SaveMode.Overwrite).saveAsTable("dwd.dwd_course_shopping_cart_cluster")}
}提交jar包,运行yarn任务。
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 3 --executor-cores 4 --executor-memory 2g --queue spark --class com.yyds.sparksqltuning.SMBJoinTuning spark-sql-tuning-1.0-SNAPSHOT-jar-with-dependencies.jar读数据时,任务task个数不可控制,由切片决定:



两张分桶表导入成功。
2、Join
前置工作准备好后,join就正常执行即可。
import org.apache.spark.SparkConf
import org.apache.spark.sql.{SaveMode, SparkSession}object SMBJoinTuning {def main(args: Array[String]): Unit = {System.setProperty("HADOOP_USER_NAME", "root")val sparkConf = new SparkConf().setAppName("test")
.set("spark.sql.shuffle.partitions", "36")val sparkSession = SparkSession.builder().config(sparkConf).enableHiveSupport().getOrCreate()val ssc = sparkSession.sparkContextssc.hadoopConfiguration.set("fs.defaultFS", "hdfs://mycluster")ssc.hadoopConfiguration.set("dfs.nameservices", "mycluster")useSMBJoin(sparkSession)
}
def useSMBJoin(sparkSession: SparkSession) = {//查询出三张表 并进行join 插入到最终表中
val saleCourse = sparkSession.sql("select *from dwd.dwd_sale_course")
val coursePay = sparkSession.sql("select * from dwd.dwd_course_pay_cluster").withColumnRenamed("discount", "pay_discount").withColumnRenamed("createtime", "pay_createtime")
val courseShoppingCart = sparkSession.sql("select *from dwd.dwd_course_shopping_cart_cluster").drop("coursename").withColumnRenamed("discount", "cart_discount").withColumnRenamed("createtime", "cart_createtime")
val tmpdata = courseShoppingCart.join(coursePay, Seq("orderid"), "left")
val result = broadcast(saleCourse).join(tmpdata, Seq("courseid"), "right")
result.select("courseid", "coursename", "status", "pointlistid", "majorid", "chapterid", "chaptername", "edusubjectid", "edusubjectname", "teacherid", "teachername", "coursemanager", "money", "orderid", "cart_discount", "sellmoney","cart_createtime", "pay_discount", "paymoney", "pay_createtime", "dwd.dwd_sale_course.dt", "dwd.dwd_sale_course.dn").write.mode(SaveMode.Overwrite).saveAsTable("dws.dws_salecourse_detail_2")
}打成jar包,提交yarn任务:

看到sort排序时间得到了优化。注意此优化join顺序不能变。两大表得先join,否则分桶无优化效果。
十二、Spark3.0 堆外内存使用
讲到堆外内存,就必须去提一个东西,那就是去yarn申请资源的单位,容器。Spark on yarn模式,一个容器到底申请多少内存资源。
一个容器最多可以申请多大资源,是由yarn参yarn.scheduler.maximum-allocation-mb决定,而spark中又是有由spark.executor.memoryOverhead,spark.executor.memory, spark.memory.offHeap.size 三个参数决定。
即spark.executor.memoryOverhead+spark.executor.memory+spark.memory.offHeap.size的值必须小于等于yarn.scheduler.maximum-allocation-mb。

三个参数:
- spark.executor.memory: spark提交任务时指定的堆内内存。
- spark.executor.memoryOverhead:spark堆外内存参数,内存额外开销,默认开启,默认值为spark.executor.memory*0.1并且会与最小值384mb做对比,取最大值。这就是为什么spark on yarn任务堆内内存填写申请1个g,而实际去yarn申请的内存不是1个g的原因。
- spark.memory.offHeap.size:堆外内存参数,spark中默认关闭,需要将spark.memory.enable.offheap.enable参数设置为true
注意:网上有很多帖子说spark.executor.memoryOverhead包含spark.memory.offHeap.size,这并没有错,但仅限于spark3.0之前的版本,3.0之后就发生改变了,实际去yarn申请的内存资源又三个参数相加。
以下源码:


1、测试申请容器上限
修改对应yarn参数配置,yarn.scheduler.maximum-allocation-mb修改为4G。

提交spark on yarn任务并指定参数,故意将:
spark.driver.memoryOverhead+ size+executor-memoryspark.memory.offHeap. 申请的资源大于4G。
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 3 --executor-cores 4 --conf spark.driver.memoryOverhead=1g --conf spark.memory.offHeap.enabled=true --conf spark.memory.offHeap.size=2g --executor-memory 2g --queue spark --class com.yyds.sparksqltuning.SMBJoinTuning spark-sql-tuning-1.0-SNAPSHOT-jar-with-dependencies.jar报错,提示:

将spark.memory.offHeap.size修改为1g后再次提交:
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 3 --executor-cores 4 --conf spark.driver.memoryOverhead=1g --conf spark.memory.offHeap.enabled=true --conf spark.memory.offHeap.size=1g --executor-memory 2g --queue spark --class com.yyds.sparksqltuning.SMBJoinTuning spark-sql-tuning-1.0-SNAPSHOT-jar-with-dependencies.jar
3个executor,每个executor申请4G内存资源,加上driver端1G内存资源一共申请13g内存。
2、使用堆外缓存级别
使用堆外内存可以垃圾回收的工作,也加快了复制的速度。
什么情况使用堆外内存:
当需要缓存非常大的数据量时,虚拟机将承受非常大的GC压力,因为虚拟机必须检查每个对象是否可以收集并必须访问所有内存页。本地缓存是最快的,但会给虚拟机带来GC压力,所以,当你需要处理非常多GB的数据量时可以考虑使用堆外内存来进行优化,因为这不会给Java垃圾收集器带来任何压力。让JAVA GC为应用程序完成工作,缓存操作交给堆外。
import com.yyds.sparksqltuning.MemoryTuning.CoursePay
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
import org.apache.spark.storage.StorageLevelobject OFFHeapCache {def main(args: Array[String]): Unit = {System.setProperty("HADOOP_USER_NAME", "root")val sparkConf = new SparkConf().setAppName("test")val sparkSession = SparkSession.builder().config(sparkConf).enableHiveSupport().getOrCreate()val ssc = sparkSession.sparkContextssc.hadoopConfiguration.set("fs.defaultFS", "hdfs://mycluster")ssc.hadoopConfiguration.set("dfs.nameservices", "mycluster")useOFFHeapMemory(sparkSession)}def useOFFHeapMemory(sparkSession: SparkSession): Unit = {import sparkSession.implicits._val result = sparkSession.sql("select * from dwd.dwd_course_pay ").as[CoursePay]result.persist(StorageLevel.OFF_HEAP)result.foreachPartition((p: Iterator[CoursePay]) => p.foreach(item => println(item.orderid)))while (true) {}}
}再次提交任务:
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 3 --executor-cores 4 --conf spark.driver.memoryOverhead=1g --conf spark.memory.offHeap.enabled=true --conf spark.memory.offHeap.size=1g --executor-memory 2g --queue spark --class com.yyds.sparksqltuning.OFFHeapCache spark-sql-tuning-1.0-SNAPSHOT-jar-with-dependencies.jar


十三、Spark3.0 AQE
1、Dynamically coalescing shuffle partitions
在Spark中运行查询处理非常大的数据时,shuffle通常会对查询性能产生非常重要的影响。
shuffle是非常昂贵的操作,因为它需要进行网络传输移动数据,以便下游进行计算。
最好的分区取决于数据,但是每个查询的阶段之间的数据大小可能相差很大,这使得该数字难以调整:
(1)如果分区太少,则每个分区的数据量可能会很大,处理这些数据量非常大的分区,可能需要将数据溢写到磁盘(例如,排序和聚合),降低了查询。
(2)如果分区太多,则每个分区的数据量大小可能很小,读取大量小的网络数据块,这也会导致I/O效率低而降低了查询速度。拥有大量的task(一个分区一个task)也会给Spark任务计划程序带来更多负担。
为了解决这个问题,我们可以在任务开始时先设置较多的shuffle分区个数,然后在运行时通过查看shuffle文件统计信息将相邻的小分区合并成更大的分区。
例如,假设正在运行select max(i) from tbl group by j。输入tbl很小,在分组钱只有2个分区。那么任务刚初始化时,我们将分区数设置为5,如果没有AQE,Spark将启动五个任务来进行最终聚合,但是其中会有三个非常小的分区,为每个分区启动单独的任务这样就很浪费。

取而代之的是,AQE将这三个小分区合并为一个,因此最终聚只需三个task而不是五个:

import org.apache.spark.SparkConf
import org.apache.spark.sql.{SaveMode, SparkSession}object AqeTest {def main(args: Array[String]): Unit = {System.setProperty("HADOOP_USER_NAME", "root")val sparkConf = new SparkConf().setAppName("test").set("spark.sql.autoBroadcastJoinThreshold", "-1")//为了测试动态缩小分区,关闭广播join.set("spark.sql.adaptive.enabled", "true") //开启aqe功能.set("spark.sql.adaptive.coalescePartitions.enabled","true") //开启动态缩小分区.set("spark.sql.adaptive.coalescePartitions.initialPartitionNum","500")//此参数默认和spark.sql.shuffle.partitions相等,初始值可以设置了大点val sparkSession = SparkSession.builder().config(sparkConf).enableHiveSupport().getOrCreate()val ssc = sparkSession.sparkContextssc.hadoopConfiguration.set("fs.defaultFS", "hdfs://mycluster")ssc.hadoopConfiguration.set("dfs.nameservices", "mycluster")useJoin(sparkSession)}def useJoin(sparkSession: SparkSession) = {val saleCourse = sparkSession.sql("select *from dwd.dwd_sale_course")val coursePay = sparkSession.sql("select * from dwd.dwd_course_pay").withColumnRenamed("discount", "pay_discount").withColumnRenamed("createtime", "pay_createtime")val courseShoppingCart = sparkSession.sql("select *from dwd.dwd_course_shopping_cart").drop("coursename").withColumnRenamed("discount", "cart_discount").withColumnRenamed("createtime", "cart_createtime")saleCourse.join(courseShoppingCart, Seq("courseid", "dt", "dn"), "right").join(coursePay, Seq("orderid", "dt", "dn"), "left").select("courseid", "coursename", "status", "pointlistid", "majorid", "chapterid", "chaptername", "edusubjectid", "edusubjectname", "teacherid", "teachername", "coursemanager", "money", "orderid", "cart_discount", "sellmoney","cart_createtime", "pay_discount", "paymoney", "pay_createtime", "dt", "dn").write.mode(SaveMode.Overwrite).insertInto("dws.dws_salecourse_detail_1")}
}提交任务观察spark ui对应stage产生task:
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 3 --executor-cores 4 --executor-memory 2g --queue spark --class com.yyds.sparksqltuning.AqeTest spark-sql-tuning-1.0-SNAPSHOT-jar-with-dependencies.jar
发现没有了200分区的stage,分区自动被优化缩小了。点击stage查看详情,发现虽然分区得到了优化,可以自动调节缩小了,但是资源的使用没有得到最优的调整。

再次添加参数,将spark.dynamicAllocation.enabled设置为true和spark.dynamicAllocation.shuffleTracking.enabled设置为true,开启动态资源分配,此参数CDH中是默认开启的。

再次提交任务,查看spark ui:


这样就会充分利用集群资源,但是可能会申请内存资源过大造成浪费,所以当集群资源充足时可以将3.0动态缩小分区特性和动态申请资源结合使用。
2、Dynamically switching join strategies
Spark支持多种join策略,其中如果join的一张表可以很好的插入内存,那么broadcast shah join通常性能最高。因此,spark join中,如果小表小于广播大小阀值(默认10mb),Spark将计划进行broadcast hash join。但是,很多事情都会使这种大小估计出错(例如,存在选择性很高的过滤器),或者join关系是一系列的运算符而不是简单的扫描表操作。
为了解决此问题,AQE现在根据最准确的join大小运行时重新计划join策略。从下图实例中可以看出,发现连接的右侧表比左侧表小的多,并且足够小可以进行广播,那么AQE会重新优化,将sort merge join转换成为broadcast hash join。

对于运行是的broadcast hash join,可以将shuffle优化成本地shuffle,优化掉stage 减少网络传输。Broadcast hash join可以规避shuffle阶段,相当于本地join。
package com.yyds.sparksqltuningimport org.apache.spark.SparkConf
import org.apache.spark.sql.{SaveMode, SparkSession}object AqeTest {def main(args: Array[String]): Unit = {System.setProperty("HADOOP_USER_NAME", "root")val sparkConf = new SparkConf().setAppName("test").set("spark.sql.adaptive.enabled", "false") //开启aqe功能.set("spark.sql.adaptive.localShuffleReader.enabled", "false") // spark会在不需要进行shuffle时尝试使用本地shuffle读取器。将sort-meger join 转换为广播joinval sparkSession = SparkSession.builder().config(sparkConf).enableHiveSupport().getOrCreate()val ssc = sparkSession.sparkContextssc.hadoopConfiguration.set("fs.defaultFS", "hdfs://mycluster")ssc.hadoopConfiguration.set("dfs.nameservices", "mycluster")switchJoinStartegies(sparkSession)}
def switchJoinStartegies(sparkSession: SparkSession) = {// val saleCourse = sparkSession.sql("select *from dwd.dwd_sale_course")val coursePay = sparkSession.sql("select * from dwd.dwd_course_pay").withColumnRenamed("discount", "pay_discount").withColumnRenamed("createtime", "pay_createtime").where("orderid between 'odid-9999000' and 'odid-9999999'")val courseShoppingCart = sparkSession.sql("select *from dwd.dwd_course_shopping_cart").drop("coursename").withColumnRenamed("discount", "cart_discount").withColumnRenamed("createtime", "cart_createtime")val tmpdata = coursePay.join(courseShoppingCart, Seq("orderid"), "right")tmpdata.show()
}先不开启动态选择join策略,并且对corsepay 表filter操作过滤只剩1000条数据,进行join。打包提交任务:
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 3 --executor-cores 4 --executor-memory 2g --queue spark --class com.yyds.sparksqltuning.AqeTest spark-sql-tuning-1.0-SNAPSHOT-jar-with-dependencies.jar查看执行计划图:


虽然对coursepay进行了where过滤操作,使这张表最终数据小于了10mb但是却没有走广播join。接下来开启3.0自动选择join策略参数,进行优化。
将参数spark.sql.adaptive.enabled设置为true开启aqe。
spark.sql.adaptive.localShuffleReader.enabled设置为true,此参数默认为true,开启后spark后会尝试使用本地shuffle读取器进行读取数据,即将sort-merge-join转换为广播join。

再次打包提交任务,查看spark 执行计划图。




3、Dynamically optimizing skew joins
当数据在群集中的分区之间分布不均匀时,就会发生数据倾斜。严重的倾斜会大大降低查询性能,尤其对于join。AQE skew join优化会从随机shuffle文件统计信息自动检测到这种倾斜。然后它将倾斜分区拆分成较小的子分区。
例如,下图 A join B,A表中分区A0明细大于其他分区:

因此,skew join 会将A0分区拆分成两个子分区,并且对应连接B0分区。

没有这种优化,会导致其中一个分区特别耗时拖慢整个stage,有了这个优化之后每个task耗时都会大致相同,从而总体上获得更好的性能。
那么还是拿上面例子来讲,如果不做优化,当课程表和购物车表进行join,产生了数据倾斜。如下图:

文档上面已列举了两种方式解决,那么到了3.0之后就可以交个spark来自定解决了。Spark3.0增加了以下参数。
1. spark.sql.adaptive.skewJoin.enabled :是否开启倾斜join检测,如果开启了,那么会将倾斜的分区数据拆成多个分区,默认是开启的,但是得打开ape;
2. spark.sql.adaptive.skewJoin.skewedPartitionFactor :默认值5,此参数用来判断分区数据量是否数据倾斜,当任务中最大数据量分区对应的数据量大于的分区中位数乘以此参数(5),并且也大于spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes参数,那么任务此任务数据倾斜;
3. spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes :默认值256mb,用于判断是否数据倾斜;
4. spark.sql.adaptive.advisoryPartitionSizeInBytes :此参数用来告诉spark进行拆分后推荐分区大小是多少;
先来看此任务中的中位分区的数据量,点解task详情页面shuffle read size进行排序,然后查看第100个任务,可以看到当前任务中,中位分区数据量为1.2MB。


中位分区数1.2MB,现在最大分区的数据量是27.5MB,满足中位分区数乘以spark.sql.adaptive.skewJoin.skewedPartitionFactor的判定,但是小于spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes参数。这个时候我们可以修改spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes参数来让spark认为此任务发生数据倾斜了,自动进行优化。测试的时候关闭aqe中的动态缩小分区操作,影响测试。
import org.apache.spark.SparkConf
import org.apache.spark.sql.{SaveMode, SparkSession}object AqeTest {def main(args: Array[String]): Unit = {System.setProperty("HADOOP_USER_NAME", "root")val sparkConf = new SparkConf().setAppName("test").set("spark.sql.autoBroadcastJoinThreshold", "-1").set("spark.sql.adaptive.enabled","true").set("spark.sql.adaptive.coalescePartitions.enabled","false").set("spark.sql.adaptive.skewJoin.skewedPartitionFactor","5").set("spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes","10mb").set("spark.sql.adaptive.advisoryPartitionSizeInBytes","8mb")
val sparkSession = SparkSession.builder().config(sparkConf).enableHiveSupport().getOrCreate()
val ssc = sparkSession.sparkContext
ssc.hadoopConfiguration.set("fs.defaultFS", "hdfs://mycluster")
ssc.hadoopConfiguration.set("dfs.nameservices", "mycluster")
useJoin(sparkSession)
}
def useJoin(sparkSession: SparkSession) = {val saleCourse = sparkSession.sql("select *from dwd.dwd_sale_course")val coursePay = sparkSession.sql("select * from dwd.dwd_course_pay").withColumnRenamed("discount", "pay_discount").withColumnRenamed("createtime", "pay_createtime")val courseShoppingCart = sparkSession.sql("select *from dwd.dwd_course_shopping_cart").drop("coursename").withColumnRenamed("discount", "cart_discount").withColumnRenamed("createtime", "cart_createtime")saleCourse.join(courseShoppingCart, Seq("courseid", "dt", "dn"), "right").join(coursePay, Seq("orderid", "dt", "dn"), "left").select("courseid", "coursename", "status", "pointlistid", "majorid", "chapterid", "chaptername", "edusubjectid", "edusubjectname", "teacherid", "teachername", "coursemanager", "money", "orderid", "cart_discount", "sellmoney","cart_createtime", "pay_discount", "paymoney", "pay_createtime", "dt", "dn").write.mode(SaveMode.Overwrite).insertInto("dws.dws_salecourse_detail_1")
}
}再次打包提交,查看spark on yarn任务。

看到这个stage由200变成了206说明进行过了拆分,点击查看详情:

已自动优化倾斜task。
十四、Spark3.0 DPP
Spark3.0支持动态分区裁剪Dynamic Partition Pruning,简称DPP,核心思路就是先将join一侧作为子查询计算出来,再将其所有分区用到join另一侧作为表过滤条件,从而实现对分区的动态修剪。
如下图所示:

将:
select t1.id,t2.pkey from t1 join t2 on t1.pkey =t2.pkey and t2.id<2优化成了:
select t1.id,t2.pkey from t1 join t2 on t1.pkey=t2.pkey and t1.pkey in(select t2.pkey from t2 where t2.id<2)触发条件:
- 待裁剪的表join的时候,join条件里必须有分区字段
- 如果是需要修剪左表,那么join必须是inner join ,left semi join或right join,反之亦然。但如果是left out join,无论右边有没有这个分区,左边的值都存在,就不需要被裁剪
- 另一张表需要存在至少一个过滤条件,比如a join b on a.key=b.key and a.id<2
参数spark.sql.optimizer.dynamicPartitionPruning.enabled 默认开启。
先创建两张表包含多个分区,并插入测试数据:
import java.util.Randomimport org.apache.spark.SparkConf
import org.apache.spark.sql.{SaveMode, SparkSession}object DPPTest {case class Student(id: Long, name: String, age: Int, partition: Int)case class School(id: Long, name: String, partitions: Int)def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setAppName("test").set("spark.sql.optimizer.dynamicPartitionPruning.enabled", "false") //关闭dppval sparkSession = SparkSession.builder().config(sparkConf).enableHiveSupport().getOrCreate()val ssc = sparkSession.sparkContextssc.hadoopConfiguration.set("fs.defaultFS", "hdfs://mycluster")ssc.hadoopConfiguration.set("dfs.nameservices", "mycluster")saveData(sparkSession)}def saveData(sparkSession: SparkSession) = {import sparkSession.implicits._sparkSession.range(1000000).mapPartitions(partitions => {val random = new Random()partitions.map(item => Student(item, "name" + item, random.nextInt(100), random.nextInt(100)))}).write.partitionBy("partition").mode(SaveMode.Overwrite).saveAsTable("test_student")sparkSession.range(1000000).mapPartitions(partitions => {val random = new Random()partitions.map(item => School(item, "school" + item, random.nextInt(100)))}).write.partitionBy("partition").mode(SaveMode.Overwrite).saveAsTable("test_school")}
}插入数据后两表进行join,先关闭dpp功能:
def getResult(sparkSession: SparkSession)={val result=sparkSession.sql("select a.id,a.name,a.age,b.name from default.test_student a inner join default.test_school b " +" on a.partition=b.partition and b.id<1000 ")result.foreach(item=>println(item.get(1)))
}
提交任务观察spark ui:



没有任何优化,开启DPP:

再次提交任务 观察spark ui:



多出了一个子查询,对另一张分区表进行裁剪过滤。
十五、Spark3.0 Hint增强
在spark2.4的时候就有了hint功能,不过那个时候还是只有broadcasthash join的hint,这次3.0又增加了sort merge join,shuffle_hash join,shuffle_replicate nested loop join。
具体用法如下:
(1)broadcasthast join
三种方式都支持:
sparkSession.sql("select /*+ BROADCAST(school) */ * from student left join school on student.schoolid=school.id").show
sparkSession.sql("select /*+ BROADCASTJOIN(school) */ * from student left join school on student.schoolid=school.id").show
sparkSession.sql("select /*+ MAPJOIN(school) */ * from student left join school on student.schoolid=school.id").show
(2)sort merge join
sparkSession.sql("select /*+ SHUFFLE_MERGE(school) */ * from student left join school on student.schoolid=school.id").show
sparkSession.sql("select /*+ MERGEJOIN(school) */ * from student left join school on student.schoolid=school.id").show
sparkSession.sql("select /*+ MERGE(school) */ * from student left join school on student.schoolid=school.id").show
(3)shuffle_hash join
sparkSession.sql("select /*+ SHUFFLE_HASH(school) */ * from student left join school on student.schoolid=school.id").show
(4)shuffle_replicate_nl join
使用条件非常苛刻,驱动表(school表)必须小,且很容易被spark执行成sort merge join。
sparkSession.sql("select /*+ SHUFFLE_REPLICATE_NL(school) */ * from student inner join school on student.schoolid=school.id").show()
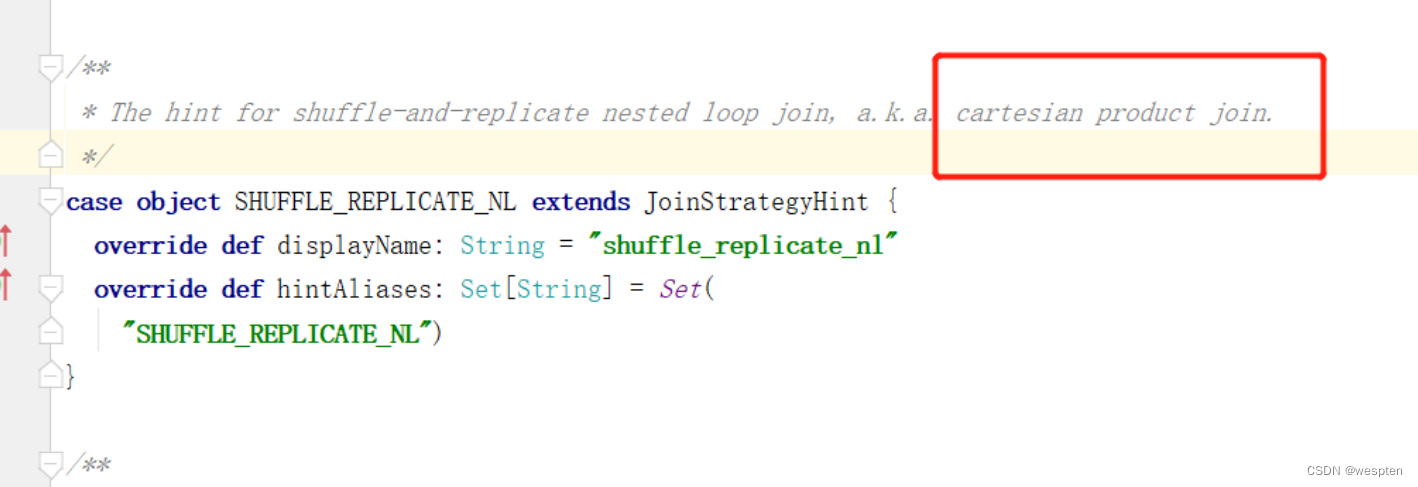
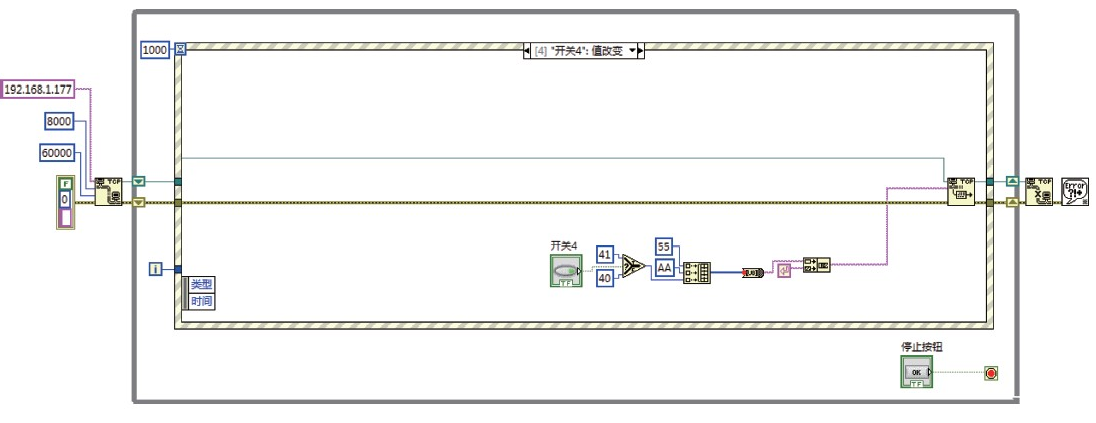

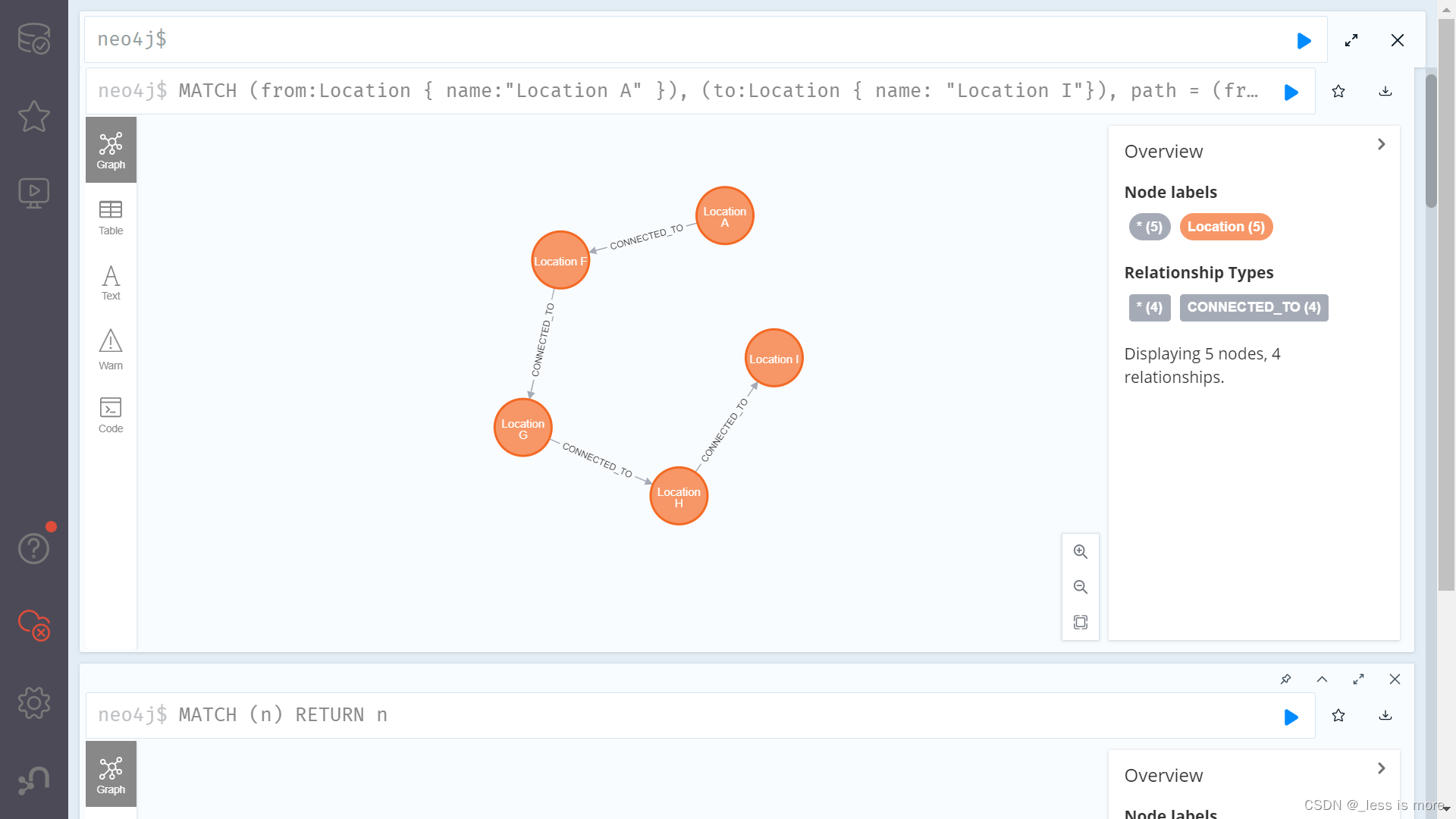


![沉睡者IT - [短视频运营] 抖音短视频成SEO新风口](https://img-blog.csdnimg.cn/img_convert/4d0e6ae8161cd07f0979800849e84509.jpeg)