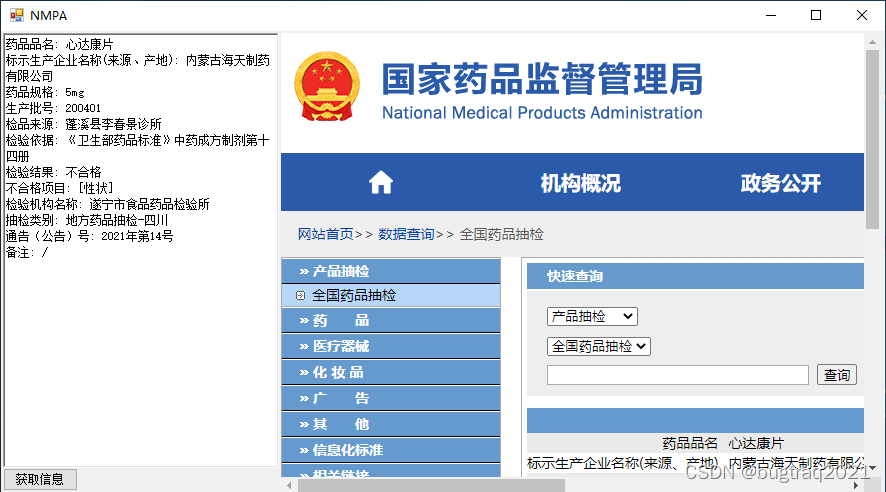
(原文地址:http://lmc.worldhm.net/webpage_blog/showlogs.jsp?lid=1576)
千万人同时访问的网站,一般是有很多个数据库同时工作,说明白一点就是数据库集群和并发控制,这样的网站实时性也是相对的。这些网站都有一些共同的特点: 数据量大,在线人数多,并发请求多,pageview高,响应速度快。总结了一下各个大网站的架构,主要提高效率及稳定性的几个地方包括:
1、程序
程序开发是一方面,系统架构设计(硬件+网络+软件)是另一方面。
软件架构方面,做网站首先需要很多web服务器存储静态资源,比如图片、视频、静态页等,千万不要把静态资源和应用服务器放在一起。
一个好的程序员写出来的程序会非常简洁、性能很好,一个初级程序员可能会犯很多低级错误,这也是影响网站性能的原因之一。
网 站要做到效率高,不光是程序员的事情,数据库优化、程序优化这是必须的,在性能优化上要数据库和程序齐头并进!缓存也是两方面同时入手。第一,数据库缓存 和数据库优化,这个由dba完成(而且这个有非常大的潜力可挖,只是由于我们都是程序员而忽略了他而已)。第二,程序上的优化,这个非常的有讲究,比如说 重要一点就是要规范SQL语句,少用in 多用or,多用preparestatement,另外避免程序冗余如查找数据少用双重循环等。另外选用优秀的开源框架加以支持,我个人认为中后台的支持 是最最重要的,可以选取spring+ibatis。因为ibatis直接操作SQL并有缓存机制。spring的好处就不用我多说了,IOC的机制可以 避免new对象,这样也节省开销。据我分析,绝大部分的开销就是在NEW的时候和连接数据库时候产生的,请尽量避免。另外可以用一些内存测试工具来做一个 demo说明hibernate和ibatis谁更快!前台你想用什么就用什么,struts,webwork都成,如果觉得自己挺牛X可以试试用 tapestry。
用数据库也未必不能解决访问量巨大所带来的问题,作成静态文件硬盘的寻址时间也未必少于数据库的搜索时间,当然对资料的索引要下一翻工夫。我自己觉得门户往往也就是当天、热门的资料点击率较高,将其做缓存最多也不过1~2G的数据量吧,举个例子:
◎ 拿网易新闻来说http://news.163.com/07/0606/09/3GA0D10N00011229.html
格式化一下,方便理解:http://域名/年/月日/新闻所属分类/新闻ID.html
可以把当天发布的、热门的、流揽量大的作个缓寸,用hashtable(key:年-月-日-分类-ID,value:新闻对象),静态将其放到内存(速度绝对快过硬盘寻址静态页面)。
通 常是采用oracle存储过程+2个weblogic,更新机制也几乎一样每签发一条新闻,就会生成静态页面,然后发往前端的web服务器,前端的web 都是做负载均衡的。另外还有定时的程序,每5-15分钟自动生成一次。在发布新闻的同时将数据缓存。当然缓存也不会越来越大,在个特定的时间段(如凌晨) 剔除过期的数据。做一个大的网站远没有想象中那么简单,服务器基本就要百十个的。
这样可以大大增加一台计算机的处理速度,如果一台机器处理不了,可以用httpserver集群来解决问题了。
2、网络
中国的网络分南北电信和网通,访问的ip就要区分南北进入不同的网络。
3、集群
通常会使用CDN与GSBL与DNS负载均衡技术,每个地区一组前台服务器群,例如:网易,百度使用了DNS负载均衡技术,每个频道一组前台服务器,一搜使用了DNS负载技术,所有频道共用一组前台服务器集群。
网站使用基于Linux集群的负载均衡,失败恢复,包括应用服务器和数据库服务器,基于linux-ha的服务状态检测及高可用化。
应用服务器集群可以采用apache+tomcat集群和weblogic集群等;web服务器集群可以用反向代理,也可以用NAT的方式,或者多域名解析都可以;Squid也可以,方法很多,可以根据情况选择。
4、数据库
因 为是千万人同时访问的网站,所以一般是有很多个数据库同时工作的,说明白一点就是数据库集群和并发控制,数据分布到地理位置不同的数据中心,以免发生断电 事故。另外还有一点的是,那些网站的静态化网页并不是真的,而是通过动态网页与静态网页网址交换做出现的假象,这可以用urlrewrite这样的开源网 址映射器实现。这样的网站实时性也是相对的,因为在数据库复制数据的时候有一个过程,一般在技术上可以用到hibernate和ecache,但是如果要 使网站工作地更好,可以使用EJB和websphere,weblogic这样大型的服务器来支持,并且要用oracle这样的大型数据库。
大型 门户网站不建议使用Mysql数据库,除非你对Mysql数据的优化非常熟悉。Mysql数据库服务器的master-slave模式,利用数据库服务器 在主从服务器间进行同步,应用只把数据写到主服务器,而读数据时则根据负载选择一台从服务器或者主服务器来读取,将数据按不同策略划分到不同的服务器 (组)上,分散数据库压力。
大型网站要用oracle,数据方面操作尽量多用存储过程,绝对提升性能;同时要让DBA对数据库进行优化,优化后的数据库与没优化的有天壤之别;同时还可以扩展分布式数据库,以后这方面的研究会越来越多;
5、页面
从开始就考虑使用虚拟存储/簇文件系统。它能让你大量并行IO访问,而且不需要任何重组就能够增加所需要的磁盘。
页面数据调用更要认真设计,一些数据查询可以不通过数据库的方式,实时性要求不高的可以使用lucene来实现,即使有实时性的要求也可以用lucene,lucene+compass还是非常优秀的。
新闻类的网站可以用静态页存储,采用定时更新机制减轻服务器负担;首页每个小模块可以使用oscache缓存,这样不用每次都拉数据。
前端的基于静态页面缓存的web加速器,主要应用有squid等。squid 将大部分静态资源(图片,js,css等)缓存起来,直接返回给访问者,减少应用服务器的负载
网 站的静态化网页并不是真的,而是通过动态网页与静态网页网址交换做出现的假象,这可以用urlrewrite这样的开源网址映射器实现,后缀名为htm或 者html并不能说明程序生成了静态页面,可能是通过url重写来实现的,为的只不过是在搜索引擎中提升自己网站的覆盖面积罢了。
生成静态页面的服务器和www服务器是两组不同的服务器,页面生成后才会到www服务器,一部分数据库并不是关系数据库,这样更适合信息衍生,www、mail服务器、路由器多,主要用负载平衡解决访问瓶颈。
◎ 静态页面的缺点:
1) 增加了程序的复杂度
2) 不利于管理资料
3) 速度不是最快
4) 伤硬盘
6、缓存
从一开始就应该使用缓存,高速缓存是一个更好的地方存储临时数据,比如Web站点上跟踪一个特定用户的会话产生的临时文件,就不再需要记录到数据库里。
不 能用lucene实现的可以用缓存,分布式缓存可以用memcached,如果有钱的话用10来台机器做缓存,> 10G的存储量相信存什么都够了;如果没钱的话可以在页面缓存和数据缓存上下功夫,多用OSCACHE和EHCACHE,SWARMCACHE也可以,不 过据说同步性不是很好;
可以使用Memcache进行缓存,用大内存把这些不变的数据全都缓存起来,而当修改时就通知cache过 期,memcache是LJ开发的一款分布式缓存产品,很多大型网站在应用,我们可以把Cache Server与App Server装在一起。因为Cache Server对CPU消耗不大,而有了Cache Server的支援,App Server对内存要求也不是太高,所以可以和平共处,更有效的利用资源。
以上一些不太成熟的想法,可以从某一个层次开始,逐步细化,把产品的性能指标提高上去。