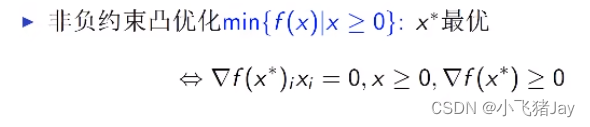🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
情绪分析依赖于组合性原则。如果我们不能理解句子的一部分,我们怎么能理解整个句子?NLP 转换器模型是否可以完成这项艰巨的任务?我们将在本章中尝试几种变压器模型来找出答案。
我们将从斯坦福情绪树库(SST)开始。SST 提供包含复杂句子的数据集进行分析。很容易分析诸如The movie was great. 但是,如果任务变得非常复杂,例如Although the movie was a bit too long, I really enjoyed it.?This sentence is segmented,会发生什么情况。它迫使变压器模型理解序列的结构及其逻辑形式。
然后我们将测试几个带有复杂句子和简单句子的 Transformer 模型。我们会发现,无论我们尝试哪种模型,如果没有得到足够的训练,它都将无法工作。变压器模型就像我们一样。他们是需要努力学习并尝试达到现实生活中人类基线的学生。
运行 DistilBERT、RoBERTa-large、BERT-base、MiniLM-L12-H84-uncased 和 BERT-base 多语言模型很有趣!然而,我们会发现其中一些学生需要更多的培训,就像我们一样。
在此过程中,我们将看到如何使用情绪任务的输出来改善客户关系,并看到一个可以在您的网站上实现的漂亮的五星级界面。
最后,我们将使用 GPT-3 的在线界面通过 OpenAI 帐户进行情绪分析。无需 AI 开发或 API!
本章涵盖以下主题:
- 用于情绪分析的 SST
- 定义长序列的组合性
- 使用 AllenNLP (RoBERTa) 进行情绪分析
- 跑复杂句探索Transformers新领域
- 使用 Hugging Face 情绪分析模型
- DistilBERT 用于情绪分析
- 试验 MiniLM-L12-H384-Uncased
- 探索 RoBERTa-large-mnli
- 研究基于 BERT 的多语言模型
- 使用 GPT-3 进行情绪分析
让我们从 SST 开始。
入门:情绪分析转换器
然后,我们将使用 AllenNLP 运行 RoBERTa 大型变压器。
斯坦福情绪树库 (SST)
索切尔等人。(2013)设计了长短语的语义词空间。他们定义了适用于长序列的组合性原则。组合性原理意味着 NLP 模型必须检查复杂句子的组成表达式以及将它们组合起来的规则以理解序列的含义。
让我们从 SST 中抽取一个样本来掌握组合性原则的含义。
本节和章节是独立的,因此您可以选择执行描述的操作或阅读章节并查看提供的屏幕截图。
转到交互式情绪树库:https ://nlp.stanford.edu/sentiment/treebank.html?na=3&nb=33 。
您可以根据需要进行选择。情感树图将出现在页面上。点击图片获取情感树:
 图 12.1:情感树图
图 12.1:情感树图
为了这例如,我点击了 6 号图,其中包含一个句子提到Jacques Derrida, a pioneer in deconstruction theories in linguistics. 出现了一个长而复杂的句子:
Whether or not you're enlightened by any of Derrida's lectures on the other and the self, Derrida is an undeniably fascinating and playful fellow.
索切尔等人。(2013) 研究向量空间和逻辑形式的组合性。
例如,定义支配 Jacques Derrida 样本的逻辑规则意味着理解以下内容:
- 如何解释将短语与句子的其余部分分开的单词
Whether,or和not和逗号Whether - 怎么理解句子后半句的逗号后面又多了一个
and!
一旦定义了向量空间,Socher等人。(2013)可以生成表示组合性原理的复杂图表。
我们可以现在逐节查看图表。第一部分是Whether句子的片段:
 图 12.2:复杂句子的“Whether”部分
图 12.2:复杂句子的“Whether”部分
该句子已正确分为两个主要部分。第二段也是正确的:
 图 12.3:复句的主要部分
图 12.3:复句的主要部分
我们可以从Socher等人的方法中得出几个结论。(2013)设计:
- 情感分析不能简化为计算句子中的正面和负面词
- Transformer 模型或任何 NLP 模型必须能够学习组合性原理,以了解复杂句子的成分如何与逻辑形式规则相匹配
- Transformer 模型必须能够建立一个向量空间来解释复杂句子的微妙之处
我们现在将使用 RoBERTa-large 模型将该理论付诸实践。
使用 RoBERTa-large 进行情绪分析
在本节中,我们将使用 AllenNLP运行 RoBERTa 大型变压器的资源。刘等人。(2019) 分析了现有的 BERT 模型,发现它们的训练不如预期。考虑到模型的生产速度,这并不奇怪。他们致力于改进 BERT 模型的预训练,以产生稳健优化的 BERT 预训练方法( RoBERTa )。
让我们首先在SentimentAnalysis.ipynb.
运行要安装的第一个单元allennlp-models:
!pip install allennlp==1.0.0 allennlp-models==1.0.0现在让我们尝试运行我们的 Jacques Derrida 示例:
!echo '{"sentence": "Whether or not you're enlightened by any of Derrida's lectures on the other and the self, Derrida is an undeniably fascinating and playful fellow."}' | \
allennlp predict https://storage.googleapis.com/allennlp-public-models/sst-roberta-large-2020.06.08.tar.gz -输出首先展示架构RoBERTa-large 模型,它有24层和16注意力头:
"architectures": ["RobertaForMaskedLM"],"attention_probs_dropout_prob": 0.1,"bos_token_id": 0,"eos_token_id": 2,"hidden_act": "gelu","hidden_dropout_prob": 0.1,"hidden_size": 1024,"initializer_range": 0.02,"intermediate_size": 4096,"layer_norm_eps": 1e-05,"max_position_embeddings": 514,"model_type": "roberta","num_attention_heads": 16,"num_hidden_layers": 24,"pad_token_id": 1,"type_vocab_size": 1,"vocab_size": 50265
}如有必要,您可以花几分钟时间阅读第 3 章微调BERT 模型中的BERT 模型配置部分中对 BERT 架构的描述,以充分利用该模型。
情绪分析产生介于0(负)和1 (正)之间的值。
然后输出产生情绪分析任务的结果,显示输出 logits 和最终的肯定结果:
prediction: {"logits": [3.646597385406494, -2.9539334774017334], "probs": [0.9986421465873718, 0.001357800210826099]注意:该算法是随机的,因此输出可能因一次运行而异。
"token_ids": [0, 5994, 50, 45, 47, 769, 38853, 30, 143, 9, 6113, 10505, 281, 25798, 15, 5, 97, 8, 5, 1403, 2156, 211, 14385, 4347, 16, 41, 35559, 12509, 8, 23317, 2598, 479, 2], "label": "1","tokens": ["<s>", "\u0120Whether", "\u0120or", "\u0120not", "\u0120you", "\u0120re", "\u0120enlightened", "\u0120by", "\u0120any", "\u0120of", "\u0120Der", "rid", "as", "\u0120lectures", "\u0120on", "\u0120the", "\u0120other", "\u0120and", "\u0120the", "\u0120self", "\u0120,", "\u0120D", "err", "ida", "\u0120is", "\u0120an", "\u0120undeniably", "\u0120fascinating", "\u0120and", "\u0120playful", "\u0120fellow", "\u0120.", "</s>"]}花一些时间输入一些样本来探索精心设计和预训练的 RoBERTa 模型。
现在让我们看看我们如何使用情绪分析来预测客户与其他 Transformer 模型的行为。
通过情绪分析预测客户行为
本节会产生情绪对几个 Hugging Face 转换器模型进行分析任务,以查看哪些产生最好的结果,哪些是我们最喜欢的。
我们将从使用 Hugging Face DistilBERT 模型开始。
使用 DistilBERT 进行情绪分析
让我们跑DistilBERT 的情感分析任务和看看我们如何使用结果来预测客户行为。
打开SentimentAnalysis.ipynb和变压器安装和进口电池:
!pip install -q transformers
from transformers import pipeline我们现在将创建一个名为 的函数classify,它将使用我们发送给它的序列运行模型:
def classify(sequence,M):#DistilBertForSequenceClassification(default model)nlp_cls = pipeline('sentiment-analysis')if M==1:print(nlp_cls.model.config)return nlp_cls(sequence)请注意,如果您发送M=1到该函数,它将显示我们正在使用的 DistilBERT 6 层 12 头模型的配置:
DistilBertConfig {"activation": "gelu","architectures": ["DistilBertForSequenceClassification"],"attention_dropout": 0.1,"dim": 768,"dropout": 0.1,"finetuning_task": "sst-2","hidden_dim": 3072,"id2label": {"0": "NEGATIVE","1": "POSITIVE"},"initializer_range": 0.02,"label2id": {"NEGATIVE": 0,"POSITIVE": 1},"max_position_embeddings": 512,"model_type": "distilbert","n_heads": 12,"n_layers": 6,"output_past": true,"pad_token_id": 0,"qa_dropout": 0.1,"seq_classif_dropout": 0.2,"sinusoidal_pos_embds": false,"tie_weights_": true,"vocab_size": 30522
}这个 DistilBERT 模型的具体参数是标签定义。
我们现在创建一个序列列表(您可以添加更多)我们可以发送到classify函数:
seq=3
if seq==1:sequence="The battery on my Model9X phone doesn't last more than 6 hours and I'm unhappy about that."
if seq==2:sequence="The battery on my Model9X phone doesn't last more than 6 hours and I'm unhappy about that. I was really mad! I bought a Moel10x and things seem to be better. I'm super satisfied now."
if seq==3:sequence="The customer was very unhappy"
if seq==4:sequence="The customer was very satisfied"
print(sequence)
M=0 #display model cofiguration=1, default=0
CS=classify(sequence,M)
print(CS) 在这种情况下,seq=3被激活以模拟我们需要考虑的客户问题。输出是否定的,这就是我们要找的例子:
[{'label': 'NEGATIVE', 'score': 0.9997098445892334}]我们可以从这个结果中得出几个结论,通过编写一个函数来预测客户行为:
- 将预测存储在客户管理数据库中。
- 计算客户在一段时间(周、月、年)内抱怨服务或产品的次数。经常抱怨的客户可能会转向竞争对手以获得更好的产品或服务。
- 检测在负面反馈消息中不断出现的产品和服务。产品或服务可能有缺陷,需要质量控制和改进。
你可以花几分钟运行其他序列或创建一些序列来探索 DistilBERT 模型。
我们现在将探索其他 Hugging Face 变形金刚。
使用 Hugging Face 的模特名单进行情绪分析
本节将探索 Hugging Face 的变压器模型列表并输入一些示例以评估他们的结果。这想法是测试多个模型,而不仅仅是一个模型,然后查看哪个模型最适合给定项目的需求。
我们将运行 Hugging Face 模型:https ://huggingface.co/models 。
对于我们使用的每个模型,您可以在 Hugging Face 提供的文档中找到模型的描述:https ://huggingface.co/transformers/ 。
我们将测试几个模型。如果您实施它们,您可能会发现它们需要对您希望执行的 NLP 任务进行微调甚至预训练。在这种情况下,对于 Hugging Face 转换器,您可以执行以下操作:
- 微调可以参考第 3 章,微调 BERT 模型
- 对于预训练,可以参考第 4 章,从头开始预训练 RoBERTa 模型
我们先来看看 Hugging Face 模型列表:https ://huggingface.co/models 。
 图 12.4:选择文本分类模型
图 12.4:选择文本分类模型
 图 12.5:Hugging Face 预训练的文本分类模型
图 12.5:Hugging Face 预训练的文本分类模型
我们将从 DistilBERT 开始。
用于 SST 的 DistilBERT
该distilbert-base-uncased-finetuned-sst-2-english模型在 SST 上进行了微调。
我们试试看一个需要很好理解原理的例子组合性:
"Though the customer seemed unhappy, she was, in fact satisfied but thinking of something else at the time, which gave a false impression."
这句话对于transformer来说很难分析,需要逻辑规则训练。
输出为假阴性:

图 12.6:复杂序列分类任务的输出
假阴性并不意味着模型不能正常工作。我们可以选择其他模型。但是,这可能意味着我们必须下载并训练它更长更好!
在撰写本书时,类 BERT 模型在 GLUE 和 SuperGLUE 排行榜上都有很好的排名。排名会不断变化,但不会改变变压器的基本概念。
我们现在将尝试一个困难但不太复杂的例子。
这个例子是现实生活项目的重要一课。当我们试图估计客户投诉了多少次时,我们会同时得到假阴性和假阳性。因此,在未来几年内,定期的人为干预仍将是强制性的。
让我们尝试一个 MiniLM 模型。
MiniLM-L12-H384-无壳
Microsoft/MiniLM-L12-H384-uncased 优化规模除了对 BERT 模型进行其他调整外,还对教师的最后一个自我注意层进行了优化,以获得更好的性能。它有 12 层、12 个头和 3300 万个参数,比 BERT-base 快 2.7 倍。
让我们测试一下它理解组合性原则的能力:
Though the customer seemed unhappy, she was, in fact satisfied but thinking of something else at the time, which gave a false impression.
输出很有趣,因为它产生了一个仔细的拆分(未决定)分数:
 图 12.7:复杂句子情感分析
图 12.7:复杂句子情感分析
我们可以看到这个输出不是决定性的,因为它是周围0.5。它应该是积极的。
让我们尝试一个涉及蕴涵的模型。
RoBERTa-large-mnli
多类型自然语言推理( MultiNLI ) 任务MultiNLI可以帮助解决这解释当我们试图确定客户的意思时,使用复杂的句子。推理任务必须确定一个序列是否包含以下序列。
我们需要格式化输入并使用序列分割标记分割序列:
Though the customer seemed unhappy</s></s> she was, in fact satisfied but thinking of something else at the time, which gave a false impression
结果很有趣,尽管它保持中立:

图 12.8:稍微肯定的句子获得的中性结果
然而,有这个结果没有错。第二序列不是从第一个序列推断出来的。结果是仔细正确的。
让我们在“积极情绪”多语言 BERT 基础模型上完成我们的实验。
基于 BERT 的多语言模型
让我们跑我们在超酷的 BERT 基础上进行的最终实验型号:nlptown/bert-base-multilingual-uncased-sentiment.
它设计得非常好。
让我们用一个友好而积极的英语句子来运行它:
 图 12.9:英语情感分析
图 12.9:英语情感分析
让我们试试看用法语用"Ce modèle est super bien!"("this model is super good,"意思"cool"):
 图 12.10:法语情绪分析
图 12.10:法语情绪分析
路径这个模型的拥抱脸是nlptown/bert-base-multilingual-uncased-sentiment。您可以在搜索表单中找到它在拥抱脸网站上。它目前的链接是nlptown/bert-base-multilingual-uncased-sentiment · Hugging Face。
您可以使用以下初始化代码在您的网站上实现它:
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("nlptown/bert-base-multilingual-uncased-sentiment")
model = AutoModelForSequenceClassification.from_pretrained("nlptown/bert-base-multilingual-uncased-sentiment")这需要一些时间和耐心,但结果可能非常酷!
您可以在您的网站上实施此转换器,以平均您客户的全球满意度!您还可以将其用作持续反馈,以改善您的客户服务并预测客户反应。
在我们离开之前,我们将了解 GPT-3 如何进行情绪分析。
使用 GPT-3 进行情绪分析
你会需要一个 OpenAI 帐户来运行示例在这个部分。教育界面不需要 API、开发或培训。例如,您可以简单地输入一些推文,并要求进行情绪分析:
鸣叫:I didn't find the movie exciting, but somehow I really enjoyed watching it!
情绪:Positive
鸣叫:I never ate spicy food like this before but find it super good!
情绪:Positive
输出令人满意。
我们现在将向 GPT-3 引擎提交一个困难的序列:
鸣叫:It's difficult to find what we really enjoy in life because of all of the parameters we have to take into account.
情绪:Positive
输出是假的!情绪一点也不积极。这句话说明了生活的艰辛。然而,这个词enjoy为 GPT-3 引入了偏见。
如果我们从序列中取出享受并用动词替换它are,则输出是否定的:
鸣叫:It's difficult to find what we really are in life because of all of the parameters we have to take into account.
情绪:Negative
输出也是假的!不是因为人生难解,我们才能断定这句话是否定的。正确的输出应该是中性的。然后我们可以要求 GPT-3 执行另一项任务,以解释为什么它在管道中很困难,例如。
以无事可做的用户身份运行 NLP 任务显示了工业 4.0 (I4.0) 的发展方向:更少的人工干预和更多的自动化功能。但是,我们知道有些情况需要我们的新技能,例如当转换器没有产生预期结果时设计预处理函数。人还是有用的!
一个例子使用现成的代码进行推文分类在第 7 章“使用 GPT-3 引擎的超人变形金刚崛起”的运行 OpenAI GPT-3 任务部分进行了描述。如果您愿意,您可以在该代码中实现本节的示例。
现在让我们看看我们如何仍然能够证明自己的宝贵资产。
临走前的一些务实的I4.0思考
Hugging Face 转换器的情绪分析包含一个“中性”的句子。
但这是真的吗?
标签这句话“中性”困扰着我。我很好奇 OpenAI GPT-3 是否可以做得更好。毕竟,GPT-3 是一个基础模型,理论上可以做很多它没有经过训练的事情。
我再次检查了这句话:
Though the customer seemed unhappy, she was, in fact, satisfied but thinking of something else at the time, which gave a false impression.
当我仔细阅读这句话时,我可以看到客户是she。当我深入观察时,我明白那she是in fact satisfied。我决定在找到可行的模型之前不要盲目尝试模型。一个接一个地尝试一个模型是没有效率的。
我需要使用逻辑和实验来找到问题的根源。我不想依赖能够自动找到原因的算法。有时我们需要使用我们的神经元!
问题可能是很难识别she为customer机器吗?正如我们在第 10 章中所做的那样,使用基于 BERT 的 Transformers 进行语义角色标签,让我们问 SRL BERT。
使用 SRL 进行调查
第 10 章以我的建议将 SRL 与我们现在正在做的其他工具一起使用。
我首先She was satisfied使用AllenNLP - Demo上的语义角色标签界面运行。
结果是正确的:

图 12.11:简单句子的 SRL
在这个谓词的框架中分析很清楚:was是动词,She是ARG1,satisfied是ARG2。
我们应该在一个复杂的句子中找到相同的分析,我们这样做:
 图 12.12:动词“satisfied”与其他词合并,造成混淆
图 12.12:动词“satisfied”与其他词合并,造成混淆
Satisfied仍然是ARG2,所以问题可能不存在。
现在,重点是ARGM-ADV,它也进行了修改was。这个词false很有误导性,因为ARGM-ADV与ARG2相关,其中包含thinking.
thinking谓词给出了 a ,但在这个复杂的句子中,false impressionthinking 没有被识别为谓词。正如我们在第 10 章的质疑 SRL 的范围部分中she was看到的,这可能是一个未识别的省略号吗?
我们可以通过输入不带省略号的完整句子来快速验证:
Though the customer seemed unhappy, she was, in fact, satisfied but she was thinking of something else at the time, which gave a false impression.
问题SRL 是省略号再次,正如我们在第 10 章中看到的那样。我们现在有五个正确的谓词和五个准确的框架。
第 1 帧显示与unhappy正确相关seemed:

图 12.13:“不开心”与“似乎”正确相关
框架 2显示satisfied现在从句子中分离出来并单独识别为was复杂句子中的参数:

图 12.14:“satisfied”现在在 ARG2 中是一个单独的词
现在,让我们直接进入包含 的谓词thinking,这是我们希望 BERT SRL 正确分析的动词。现在我们抑制省略号并在句子中重复“she was”,输出是正确的:

图 12.15:没有省略号的准确输出
现在我们可以离开我们的 SRL 调查两条线索:
- 这个词
false是一个令人困惑的论点,让算法与复杂句子中的其他词相关联 - 重复的省略号
she was
在我们去 GPT-3 之前,让我们带着我们的线索回到 Hugging Face。
拥抱脸调查
让我们回到 DistilBERT我们在本章的DistilBERT for SST部分中使用的基本未加壳微调 SST-2 模型。
我们将调查我们的两个线索:
- 的省略号
she was我们将首先提交一个没有省略号的完整句子:
Though the customer seemed unhappy, she was, in fact, satisfied but she was thinking of something else at the time, which gave a false impression输出仍然为负:
 图 12.16:假阴性
图 12.16:假阴性
- 这
false在其他积极的句子中的 存在。Though the customer seemed unhappy, she was, in fact, satisfied but thinking of something else at the time, which gave an impression答对了!输出为正:
 图 12.17:真正的肯定
图 12.17:真正的肯定
我们知道这个词false创造如果有省略号,则 SRL 会混淆was thinking。我们也知道这false会给我们使用的情绪分析 Hugging Face 转换器模型造成混乱。
GPT-3 能做得更好吗?让我们来看看。
使用 GPT-3 操场进行调查
让我们使用 OpenAI 的示例一个高级推文分类器,并通过三个步骤对其进行修改以满足我们的调查:
- 第 1 步:向 GPT-3 展示我们的期望:
句子:
"The customer was satisfied"情绪:
Positive句子:
"The customer was not satisfied"情绪:
Negative句子:
"The service was
"情绪:
Positive句子:
"This is the link to the review"情绪:
Neutral
- 第 3 步:输入我们的句子等(第 3 步):
1. "I can't stand this product"2. "The service was bad!
"3. "Though the customer seemed unhappy she was in fact satisfied but thinking of something else at the time, which gave a false impression"4. "The support team was

"5. "Here is the link to the product."句子情感等级:
1: Negative2: Positive3: Positive4: Positive5: Neutral
输出似乎令人满意因为我们的句子是肯定的(数字 3)。这个结果可靠吗?我们可以在此处多次运行该示例。但是,让我们深入到代码级别来找出答案。
GPT-3 代码
我们刚刚单击在Playground 中查看代码,复制它,并将其粘贴到我们的SentimentAnalysis.ipynb章节笔记本中。我们添加一行以仅打印我们想看到的内容:
response = openai.Completion.create(engine="davinci",prompt="This is a Sentence sentiment classifier\nSentence: \"The customer was satisfied\"\nSentiment: Positive\n###\nSentence: \"The customer was not satisfied\"\nSentiment: Negative\n###\nSentence: \"The service was \"\nSentiment: Positive\n###\nSentence: \"This is the link to the review\"\nSentiment: Neutral\n###\nSentence text\n\n\n1. \"I loved the new Batman movie!\"\n2. \"I hate it when my phone battery dies\"\n3. \"My day has been \"\n4. \"This is the link to the article\"\n5. \"This new music video blew my mind\"\n\n\nSentence sentiment ratings:\n1: Positive\n2: Negative\n3: Positive\n4: Neutral\n5: Positive\n\n\n###\nSentence text\n\n\n1. \"I can't stand this product\"\n2. \"The service was bad! \"\n3. \"Though the customer seemed unhappy she was in fact satisfied but thinking of something else at the time, which gave a false impression\"\n4. \"The support team was \"\n5. \"Here is the link to the product.\"\n\n\nSentence sentiment ratings:\n",temperature=0.3,max_tokens=60,top_p=1,frequency_penalty=0,presence_penalty=0,stop=["###"]
)
r = (response["choices"][0])
print(r["text"])- 运行 1:我们的句子(第 3 号)是中性的:
1: Negative2: Negative3: Neutral4: Positive5: Positive
- 运行 2:我们的句子(第 3 号)是肯定的:
1: Negative2: Negative3: Positive4: Positive5: Neutral
- 运行 3:我们的句子(编号 3)是肯定的
- 运行 4:我们的句子(数字 3)是否定的
这使我们得出调查结论:
- SRL 表明,如果一个句子简单而完整(没有省略号,没有漏词),我们将获得可靠的情感分析输出。
- SRL 表明,如果句子难度适中,则输出可能可靠,也可能不可靠。
- SRL 表明,如果句子很复杂(省略号、多个命题、许多模棱两可的短语要解决,等等),结果就不稳定,因此也不可靠。
- Cloud AI 和即用型模块将需要更少的 AI 开发。
- 需要更多的设计技能。
- 为 AI 算法提供输入、控制和分析其输出的管道的经典开发将需要思考和有针对性的开发。
本章展示了作为思想家、设计师和管道开发的开发人员的巨大未来!
现在是时候总结我们的旅程并探索新的变压器视野了。
概括
在本章中,我们介绍了一些高级理论。组合性原则不是一个直观的概念。组合性原则意味着transformer模型必须理解句子的每个部分才能理解整个句子。这涉及将提供句子段之间的链接的逻辑形式规则。
情感分析的理论难度需要大量的 Transformer 模型训练、强大的机器和人力资源。尽管许多 Transformer 模型针对许多任务进行了训练,但它们通常需要针对特定任务进行更多训练。
我们测试了 RoBERTa-large、DistilBERT、MiniLM-L12-H384-uncased 和出色的基于 BERT 的多语言 模型。我们发现有些提供了有趣的答案,但需要更多的训练来解决我们在几个模型上运行的 SST 样本。
情感分析需要对一个句子和非常复杂的序列有深刻的理解。因此,尝试 RoBERTa-large-mnli 看看干扰任务会产生什么是有意义的。这里的教训是不要对像变压器模型这样非常规的东西保持传统!尝试一切。在各种任务上尝试不同的模型。Transformers 的灵活性允许我们在同一个模型上尝试许多不同的任务,或者在许多不同的模型上尝试相同的任务。
我们在此过程中收集了一些想法来改善客户关系。如果我们发现客户过于频繁地不满意,那么该客户可能只会寻找我们的竞争对手。如果有多个客户抱怨某项产品或服务,我们必须预见未来的问题并改进我们的服务。我们还可以通过变压器反馈的在线实时表示来展示我们的服务质量。
最后,我们直接在线使用 GPT-3 进行情感分析,只需要使用界面即可!它出奇地有效,但我们看到仍然需要人类来解决更困难的序列。我们看到了 SRL 如何帮助识别复杂序列中的问题。
我们可以得出结论,开发人员作为思想家、设计师和管道开发具有广阔的未来。
在下一章使用变形金刚分析假新闻中,我们将使用情绪分析来分析对假新闻的情绪反应。