目录标题
- 压缩和解压缩
- zip和unzip命令
- gzip和gunzip命令
- bzip2、bunzip2命令
- xz、unxz命令
- tar归档命令
- 创建非压缩的包文件
- 创建带压缩的包文件
- 列出包文件中的文件列表
- 提取包文件到指定目录
- 文件上传
- sftp是一个交互文件传输程序
- scp具有和ssh一样的验证机制,从而可以实现2台机器安全的远程拷贝文件
- shell相关知识
- 设置环境变量
- 设置环境变量(永久生效)
- 通过echo或printf打印环境变量
- 用env或set显示默认的环境变量
- 用unset消除本地变量和环境变量
- 普通变量
压缩和解压缩
zip和unzip命令
zip既归档又压缩的文件,可以压缩目录
格式:
zip file
unzip file
实例: 使用zip压缩文件test1.txt
[root@localhost test]# zip test1.zip test1.txt
adding: test1.txt (stored 0%)
[root@localhost test]# ls test1*
test1.txt test1.zip
gzip和gunzip命令
gzip(gunzip=gzip -d)命令
实例: 使用gzip压缩文件
[root@localhost test]# gzip test1.txt unzip test1.zip test1.txt
[root@localhost test]# ls test1*
test1.txt.gz test1.zip
实例: 使用gzip压缩目录下文件
[root@localhost test]# gzip -r dir1/
[root@localhost test]# ls dir1
fstab.gz test3.txt.gz test4.txt.gz test5.txt.gz
注意:以上压缩之后原始文件就没有了
bzip2、bunzip2命令
bunzip2=bzip2 -d
bzip2、bunzip2示例如下:
# bzip2 -z man.config //将man.config以bzip2压缩,此时man.config变成
man.config.bz2
# bzip2 -9 -c man.config > man.config.bz2 //将man.config用最佳的压缩比压缩,并
保留原本的档案
# bzip2 -d man.config.bz2 //将man.config.bz2解压缩,可用bunzip2取代bzip2 -d
# bunzip2 man.config.bz2 //将man.config.bz2解压缩
注:查看压缩过的文件内容
bzcat 文件.bz2
xz、unxz命令
实例1:压缩文件
[root@localhost test]# xz test1.txt
[root@localhost test]# ls test1.txt.xz
test1.txt.xz
实例2:压缩dir1目录下文件
[root@localhost test]# xz dir1/*
[root@localhost test]# ls dir1
fstab.xz test3.txt.xz test4.txt.xz test5.txt.xz
实例3:解压缩(xz -d等价于unxz)
[root@localhost test]# unxz test1.txt.xz
实例5:解压缩目录dir1下文件
[root@localhost test]# xz -d dir1/*
[root@localhost test]# ls dir1
fstab test3.txt test4.txt test5.txt
tar归档命令
格式:
tar [选择] 打包文件名 被打包的源文件或目录列表
常用选项:
| 选项 | 功能 |
|---|---|
| c | 创建.tar格式的包文件 |
| x | 释放.tar格式的文件 |
| t | 查看包中的文件列表 |
| v | 表示在命令执行时显示详细的提示信息 |
| f 包文件名 | 用于指定包文件名。当与-c选项一起使用时,创建的tar包文件使用该选项指定的文件名;当与-x选项一起使用时,则释放该选项指定的tar包文件。 |
| p | 打包是保留文件及目录的权限 |
| z | 调用gzip程序,以gzip格式压缩或解压缩文件。 |
| j | 调用bzip2程序,以bzip2格式压缩或解压缩文件。 |
| J | 使用xz压缩(.tar.xz)。xz的压缩率通常比bzip2更高。 |
| C目录路径名 | 释放包时指定释放的目录的位置。 |
tar打包时排错:
--exclude=PATTERN 排除以PATTERN指定的文件
-X,--exclude-from=FILE 排除FILE中列出的模式串
创建非压缩的包文件
命令:
tar cvf 包文件名 要打包的目录或文件名列表
功能:将指定的一个或多个文件或目录备份生成一个指定的包文件。
创建带压缩的包文件
为节省存储空间,通常需要生成压缩格式的tar包文件,tar命令支持三种不同的压缩方式;
命令:
tar c[z j | J] f 压缩包文件名 要备份的目录或文件名
列出包文件中的文件列表
命令:tar t[v]f 包文件名
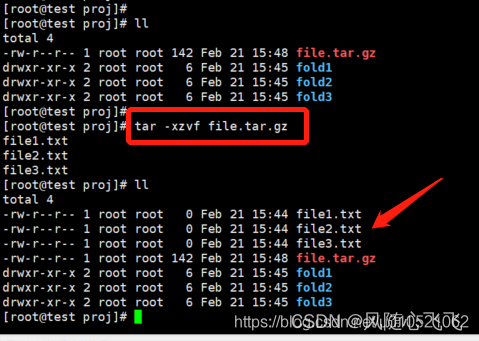
提取包文件到指定目录
格式:
tar x[z j | J] [v]f 包文件名 [-C 目标位置]
文件上传
sftp是一个交互文件传输程序
类似于ftp传输协议,属于ssh,但它进行加密传输,相对FTP来讲有更高的安全性。
sftp用法:
如果有服务器的端口不是默认的22,请在sftp后面加-P端口号即可。
sftp root@223.6.6.6
The authenticity of host ‘223.6.6.6 (223.6.6.6)’ can’t be established.
ECDSA key fingerprint is SHA256:Hl/dKTFzL4lOlF8DIG5itaV4OAsZunC2AWlFGLjLfsg.
Are you sure you want to continue connecting (yes/no)? yes【输入yes回车】
Warning: Permanently added ‘223.6.6.6’ (ECDSA) to the list of known hosts.
root@223.6.6.6’s password:【输入223.6.6.6的root密码并回车】
Connected to 223.6.6
sftp>
将223.6.6.6服务器文件下载到223.5.5.5的home目录;
sftp> get /var/www/renwole.txt /home/
将223.5.5.5服务器文件上传到223.6.6.6服务器的mnt目录;
sftp> put /home/renwole.txt /mnt/
如果不知道远程主机的目录是什么,ls命令可以列出223.6.6.6服务器的当前目录列表,例如:
sftp> ls //和查看本地操作命令一样
sftp> pwd //查询223.6.6.6的当前工作目录
改变路径可以用cd,改变本机路径可以用cd…例如:
sftp> cd
如果想退出,例如:
exit //退出机器,返回你原始机器界面。
scp具有和ssh一样的验证机制,从而可以实现2台机器安全的远程拷贝文件
scp可以概括为:scp -P端口 文件路径 用户名@主机地址:远程目录 -r
如果想拷贝本地文件到另一台ssh终端,可以使用以下命令;
scp /renwole/mariadb.tar.gz root@223.6.6.6:/renwole123/
root@223.6.6.6’s password:【输入密码回车】
mariadb.tar.gz 8% 37MB 1.3MB/s 05:29 ETA
scp test.tar.bz2 root@172.24.8.134:/ 发送文件
scp root@172.24.8.134:/134 . 接收文件
如果你反过来操作,把远程主机的文件拷贝到当前系统,操作命令为:
scp root@223.6.6.6:/renwole123/mariadb.tar.gz /renwole
如果你想拷贝文件夹以及文件夹内的所有文件,就加参数-r如果你的端口号不是22,那么需要在scp后加个-P(区分大小写)端口号。建议加-C选项,因为这样可以启用SSH的压缩功能;传输速度更快,例如:
scp -P 6632 -C /renwole/mariadb root@223.6.6.6:/renwole123/
shell相关知识
设置环境变量
如果想要设置环境变量,就要在给变量复制之后或在设置变量时使用export命令,另外,除了export命令。带-x选项的declera内置命令也可以完成同样的功能(此处不要在前面加$)
export命令和declare命令的格式如下:
export 变量名=value 变量名=value ;
export 变量名 ;多条命令依次执行
declare -x 变量名=value
设置环境变量(永久生效)
用户的环境变量配置:
[root@www ~]$ ls /root/.bashrc # 推荐再此文件中优先设置
/root/.bashrc
[root@www ~]$ ls /root/.bash_profile
/root/.bash_profile
全局的环境变量配置
[root@www ~]$ /etc/profile
[root@www ~]$ /etc/bashrc
[root@www ~]$ /etc/profile.d/
若要在登录后初始化或显示加载内容,则把脚本文件放在/etc/profile.d/下即可(无需加载执行权限)
生产场景下(Java环境中),自定义环境变量的实例。
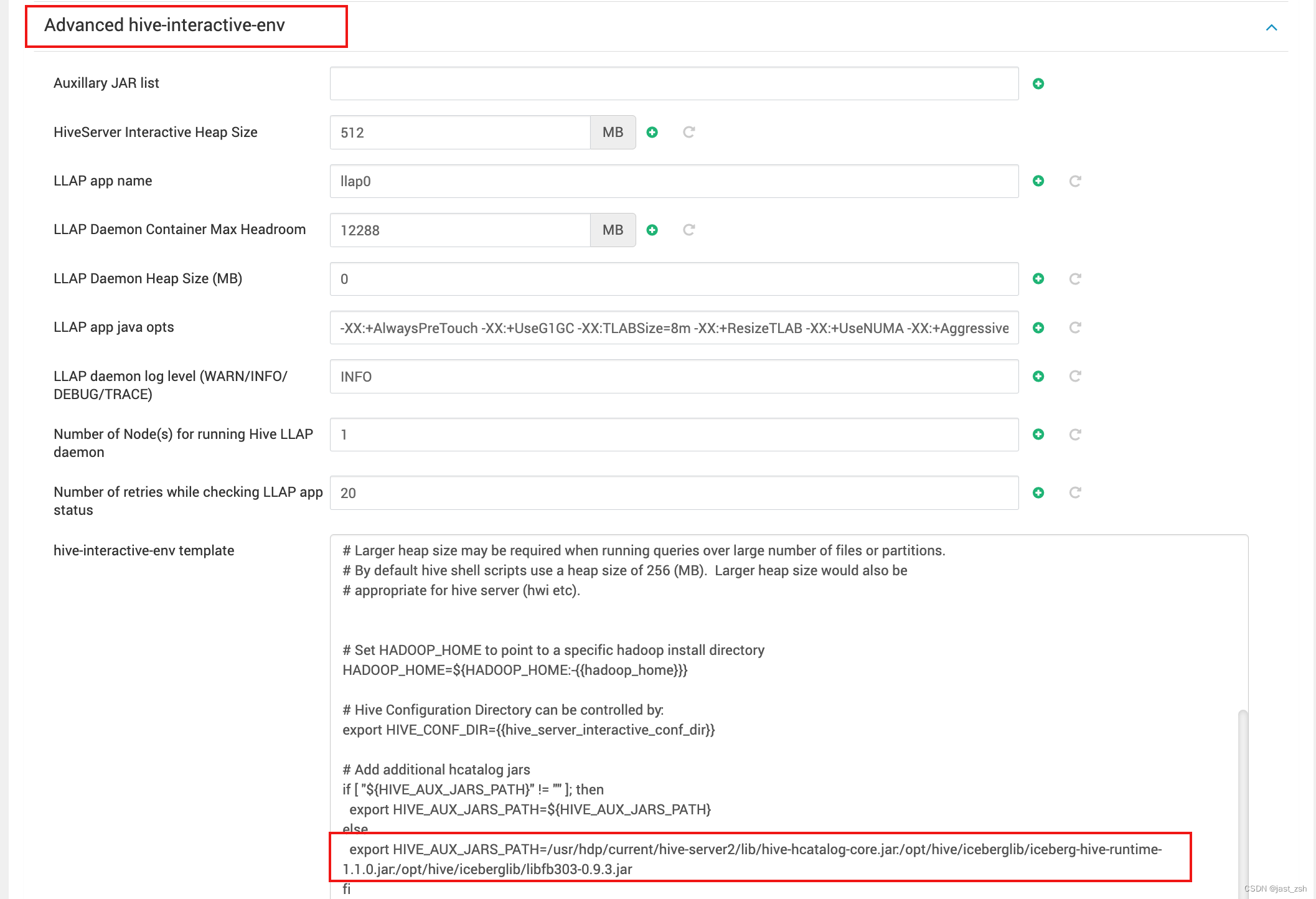
export JAVA_HOME=/application/jdk
export CLASSPATH=$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH:$HOME/bin
export RESIN=/applaction/resin
显示与取消环境变量
通过echo或printf打印环境变量
[root@www ~]$ echo $HOME
/root
[root@www ~]$ echo $UID
0
[root@www ~]$ echo $PWD
/root
[root@www ~]$ echo $SHELL
/bin/bash
[root@www ~]$ echo $USER
root
[root@www ~]$ printf "$HOME\n"
/root
用env或set显示默认的环境变量
[root@www ~]$ env
XDG_SESSION_ID=17
HOSTNAME=www.oliven.com
TERM=xterm
...
[root@www ~]$ set
BASH=/bin/bash
...
[root@www ~]$ declare | head
BASH=/bin/bash
...
用unset消除本地变量和环境变量
[root@www ~]$ echo $USER
root
[root@www ~]$ unset USER
[root@www ~]$ echo $USER
[root@www ~]$
普通变量
定义本地变量
变量的赋值,一般有五种写法:
name=value
name1='value'
name_2="value"
_name_3=`cmd`
_na_me_4=$(cmd)
变量名一般有字母、数字、下划线组成的,可以以字母或下划线开头。