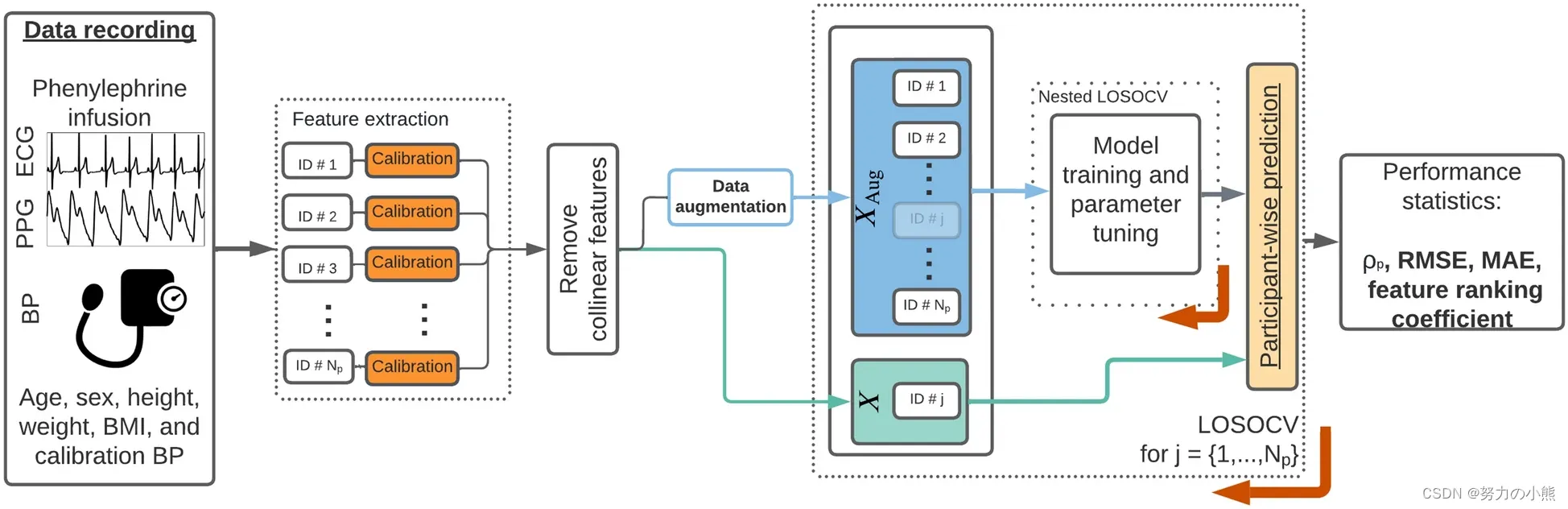
作为一个企业,我们都希望拥有高效率和优异的竞争力。但是,如何才能在竞争激烈的市场中脱颖而出?这时,精益管理理念的出现可以帮助我们。
精益管理的基本概念是什么?
精益管理的核心理念是通过消除浪费来实现生产效率的最大化。这包括减少不必要的等待时间,提高工作效率,以及避免生产中的缺陷和错误。它是一种全面的、基于团队的方法,旨在优化整个生产过程。

七大浪费
精益管理认为,制造过程中有七种浪费是会导致生产效率降低的。这七种浪费包括:
- 运输浪费
- 库存浪费
- 过程中的等待
- 生产过程中的过度加工
- 生产缺陷和错误
- 不必要的动作
- 未能充分利用员工的智力和创造力
通过对这些浪费进行消除或最小化,企业可以实现更高效率的生产,并提高整个企业的竞争力。

精益管理的优点是什么?
精益管理的优点不仅仅在于提高生产效率和降低成本。它还可以带来其他的益处,包括:
改善员工工作条件
通过减少浪费,员工的工作负担可以得到缓解。此外,精益管理也重视员工的参与和反馈,这有助于建立更良好的工作环境和工作关系。
提高客户满意度
通过减少生产中的缺陷和错误,产品质量可以得到提高。这不仅可以增加客户的信任度,还可以提高客户的满意度,从而增加企业的市场份额。
增强企业的灵活性
精益管理的重点是在于通过减少浪费来实现生产效率的最大化。这样,企业可以更快地适应市场的变化,并能够更快地满足客户的需求。
精益管理如何实施?
要成功地实施精益管理,需要以下的步骤:
设定目标和指标
首先,需要明确企业的目标和指标。这些目标和指标应该是具体、可测、可达到的,并能够反映企业的经营状况。只有这样,才能有效地实施精益管理。
改进生产流程
接下来,需要分析生产流程,找出存在的浪费,并进行改进。这需要有一支具有高度技能和经验的团队,以便能够识别并解决问题。
提高员工参与度
精益管理的另一个重要方面是员工参与度的提高。这可以通过鼓励员工提出意见、建议和改进建议,以及提供适当的培训和支持来实现。
实施持续改进
精益管理不是一次性的任务,而是一项持续的过程。因此,需要制定一个持续改进的计划,并确保团队对该计划的理解和支持。
精益管理的例子
精益管理在世界各地都有着成功的例子。例如,日本的丰田汽车就是以精益管理为基础的企业之一。丰田汽车通过消除浪费,改进生产流程,提高员工参与度和实施持续改进,以成为全球最大的汽车制造商之一。
此外,像亚马逊和波音这样的企业也采用了精益管理的理念。这些企业通过减少浪费,提高生产效率,实现了更高的竞争力。
总结
精益管理是一种非常有效的管理理念,它可以帮助企业提高生产效率和竞争力。通过消除浪费,改进生产流程,提高员工参与度和实施持续改进,企业可以更好地满足客户需求,并在激烈的市场竞争中脱颖而出。