文章目录
- Hive集成Iceberg
- 环境准备
- Hive与Iceberg的版本对应关系如下
- 上传jar包,拷贝到Hive的auxlib目录中
- 修改hive-site.xml,添加配置项
- 启动 HMS 服务
- 启动 Hadoop
- 创建和管理 Catalog
- 默认使用 HiveCatalog
- 指定 Catalog 类型
- 使用 HiveCatalog
- 使用 HadoopCatalog
- 指定路径加载
- 基本操作
- 创建表
- 创建外部表
- 创建内部表
- 创建分区表
- 修改表
- 插入表
- 删除表
- Hive集成Iceberg-Ambari2.7.5(该版本无法集成Iceberg,记录了集成失败过程)
- 版本
- 上传jar包,拷贝到Hive MeataStore服务所在机器的/opt/hive/iceberglib目录中
- 修改hive-site.xml,添加配置项
- 可能遇到的问题
- 创建表提示 Error: Error while compiling statement: FAILED: SemanticException Cannot find class 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler' (state=42000,code=40000)
- 不兼容-insert数据后查询不到,在HDFS中也看不到快照等文件
数据湖Iceberg-简介(1)
数据湖Iceberg-存储结构(2)
数据湖Iceberg-Hive集成Iceberg(3)
数据湖Iceberg-SparkSQL集成(4)
数据湖Iceberg-FlinkSQL集成(5)
数据湖Iceberg-FlinkSQL-kafka类型表数据无法成功写入(6)
数据湖Iceberg-Flink DataFrame集成(7)
Hive集成Iceberg
环境准备
Hive与Iceberg的版本对应关系如下
| Hive版本 | 官方推荐Hive版本 | Iceberg版本 |
|---|---|---|
| 2.x | 2.3.8 | 0.8.0-incubating~1.1.0 |
| 3.x | 3.1.2 | 0.10.0~1.1.0 |
Iceberg与Hive 2和Hive 3的集成,支持以下特性:
- 创建表
- 删除表
- 读取表
- 插入表(INSERT into)
更多功能需要Hive 4.x(目前alpha版本)才能支持。
上传jar包,拷贝到Hive的auxlib目录中
mkdir auxlib
cp iceberg-hive-runtime-1.1.0.jar /opt/module/hive/auxlib
cp libfb303-0.9.3.jar /opt/module/hive/auxlib
修改hive-site.xml,添加配置项
<property><name>iceberg.engine.hive.enabled</name><value>true</value>
</property><property><name>hive.aux.jars.path</name><value>/opt/module/hive/auxlib</value>
</property>
使用TEZ引擎注意事项:
-
使用Hive版本>=3.1.2,需要TEZ版本>=0.10.1
-
指定tez更新配置:
<property><name>tez.mrreader.config.update.properties</name><value>hive.io.file.readcolumn.names,hive.io.file.readcolumn.ids</value> </property> -
从Iceberg 0.11.0开始,如果Hive使用Tez引擎,需要关闭向量化执行:
<property><name>hive.vectorized.execution.enabled</name><value>false</value> </property>
启动 HMS 服务
启动 Hadoop
创建和管理 Catalog
Iceberg支持多种不同的Catalog类型,例如:Hive、Hadoop、亚马逊的AWS Glue和自定义Catalog。
根据不同配置,分为三种情况:
-
没有设置iceberg.catalog,默认使用HiveCatalog
-
设置了 iceberg.catalog的类型,使用指定的Catalog类型,如下表格
| 配置项 | 说明 |
|---|---|
| iceberg.catalog.<catalog_name>.type | Catalog的类型: hive, hadoop, 如果使用自定义Catalog,则不设置 |
| iceberg.catalog.<catalog_name>.catalog-impl | Catalog的实现类, 如果上面的type没有设置,则此参数必须设置 |
| iceberg.catalog.<catalog_name>. | Catalog的其他配置项 |
- 设置 iceberg.catalog=location_based_table,直接通过指定的根路径来加载Iceberg表
默认使用 HiveCatalog
CREATE TABLE iceberg_test1 (i int)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler';INSERT INTO iceberg_test1 values(1);
查看HDFS可以发现,表目录在默认的hive仓库路径下。
指定 Catalog 类型
使用 HiveCatalog
set iceberg.catalog.iceberg_hive.type=hive;
set iceberg.catalog.iceberg_hive.uri=thrift://hadoop1:9083;
set iceberg.catalog.iceberg_hive.clients=10;
set iceberg.catalog.iceberg_hive.warehouse=hdfs://hadoop1:8020/warehouse/iceberg-hive;CREATE TABLE iceberg_test2 (i int)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
TBLPROPERTIES('iceberg.catalog'='iceberg_hive');INSERT INTO iceberg_test2 values(1);
使用 HadoopCatalog
set iceberg.catalog.iceberg_hadoop.type=hadoop;
set iceberg.catalog.iceberg_hadoop.warehouse=hdfs://hadoop1:8020/warehouse/iceberg-hadoop;CREATE TABLE iceberg_test3 (i int)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
LOCATION 'hdfs://hadoop1:8020/warehouse/iceberg-hadoop/default/iceberg_test3'
TBLPROPERTIES('iceberg.catalog'='iceberg_hadoop');INSERT INTO iceberg_test3 values(1);
指定路径加载
如果HDFS中已经存在iceberg格式表,我们可以通过在Hive中创建Icerberg格式表指定对应的location路径映射数据。
CREATE EXTERNAL TABLE iceberg_test4 (i int)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
LOCATION 'hdfs://hadoop1:8020/warehouse/iceberg-hadoop/default/iceberg_test3'
TBLPROPERTIES ('iceberg.catalog'='location_based_table');
基本操作
创建表
创建外部表
CREATE EXTERNAL TABLE iceberg_create1 (i int)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler';describe formatted iceberg_create1;
创建内部表
CREATE TABLE iceberg_create2 (i int)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler';describe formatted iceberg_create2;
创建分区表
CREATE EXTERNAL TABLE iceberg_create3 (id int,name string)
PARTITIONED BY (age int)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler';describe formatted iceberg_create3;
Hive语法创建分区表,不会在HMS中创建分区,而是将分区数据转换为Iceberg标识分区。这种情况下不能使用Iceberg的分区转换,例如:days(timestamp),如果想要使用Iceberg格式表的分区转换标识分区,需要使用Spark或者Flink引擎创建表
修改表
只支持HiveCatalog表修改表属性,Iceberg表属性和Hive表属性存储在HMS中是同步的。
ALTER TABLE iceberg_create1 SET TBLPROPERTIES('external.table.purge'='FALSE');
插入表
支持标准单表INSERT INTO操作
INSERT INTO iceberg_create2 VALUES (1);
INSERT INTO iceberg_create1 select * from iceberg_create2;
在HIVE 3.x中,INSERT OVERWRITE虽然能执行,但其实是追加。
删除表
DROP TABLE iceberg_create1;
Hive集成Iceberg-Ambari2.7.5(该版本无法集成Iceberg,记录了集成失败过程)
版本
Hive:3.1.0
Tez:0.9.1
Iceberg:1.1.0
上传jar包,拷贝到Hive MeataStore服务所在机器的/opt/hive/iceberglib目录中
[root@bigdata-24-199 iceberglib]# pwd
/opt/hive/iceberglib
[root@bigdata-24-199 iceberglib]# ls
iceberg-hive-runtime-1.1.0.jar libfb303-0.9.3.jar
修改hive-site.xml,添加配置项
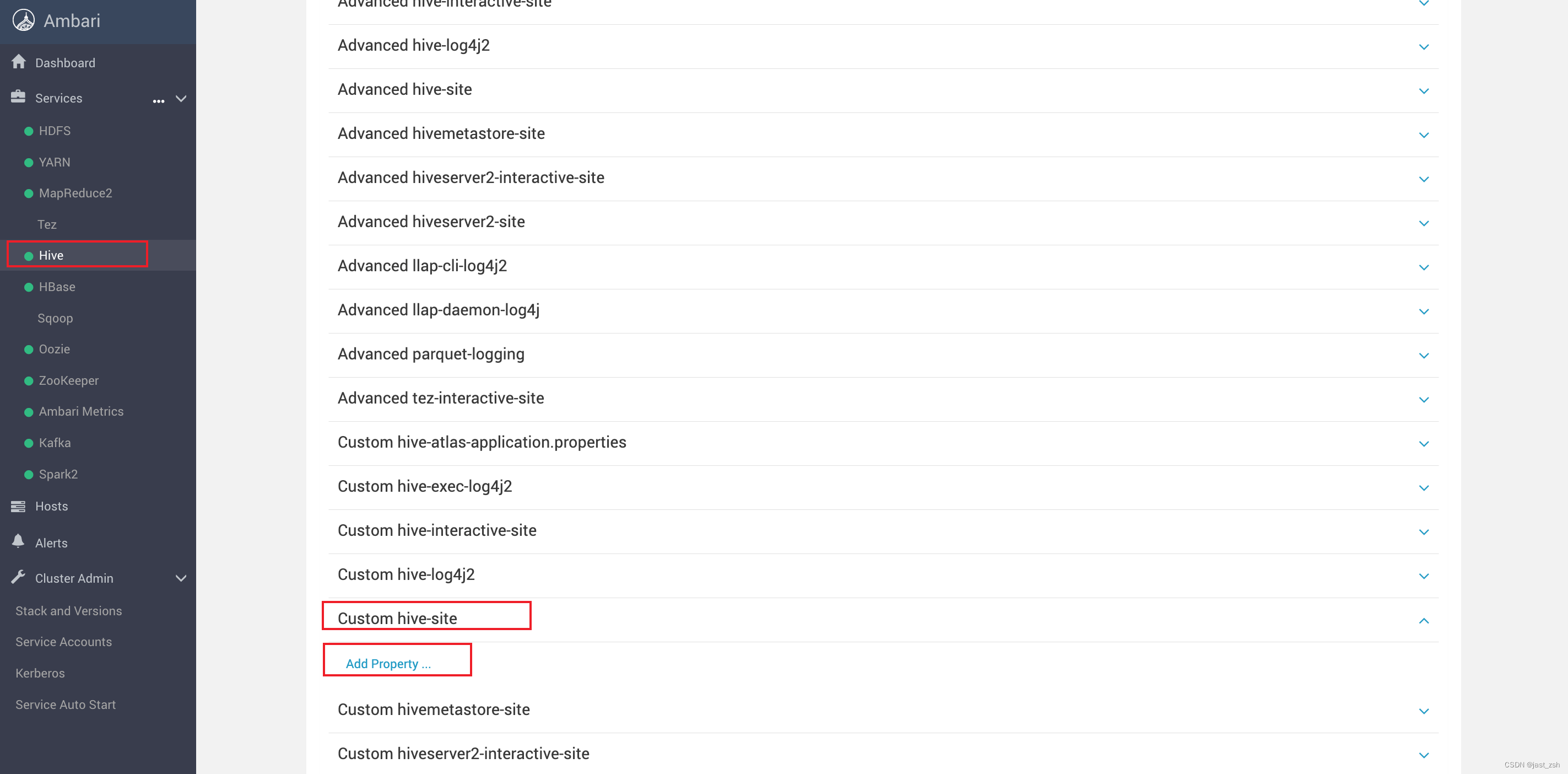
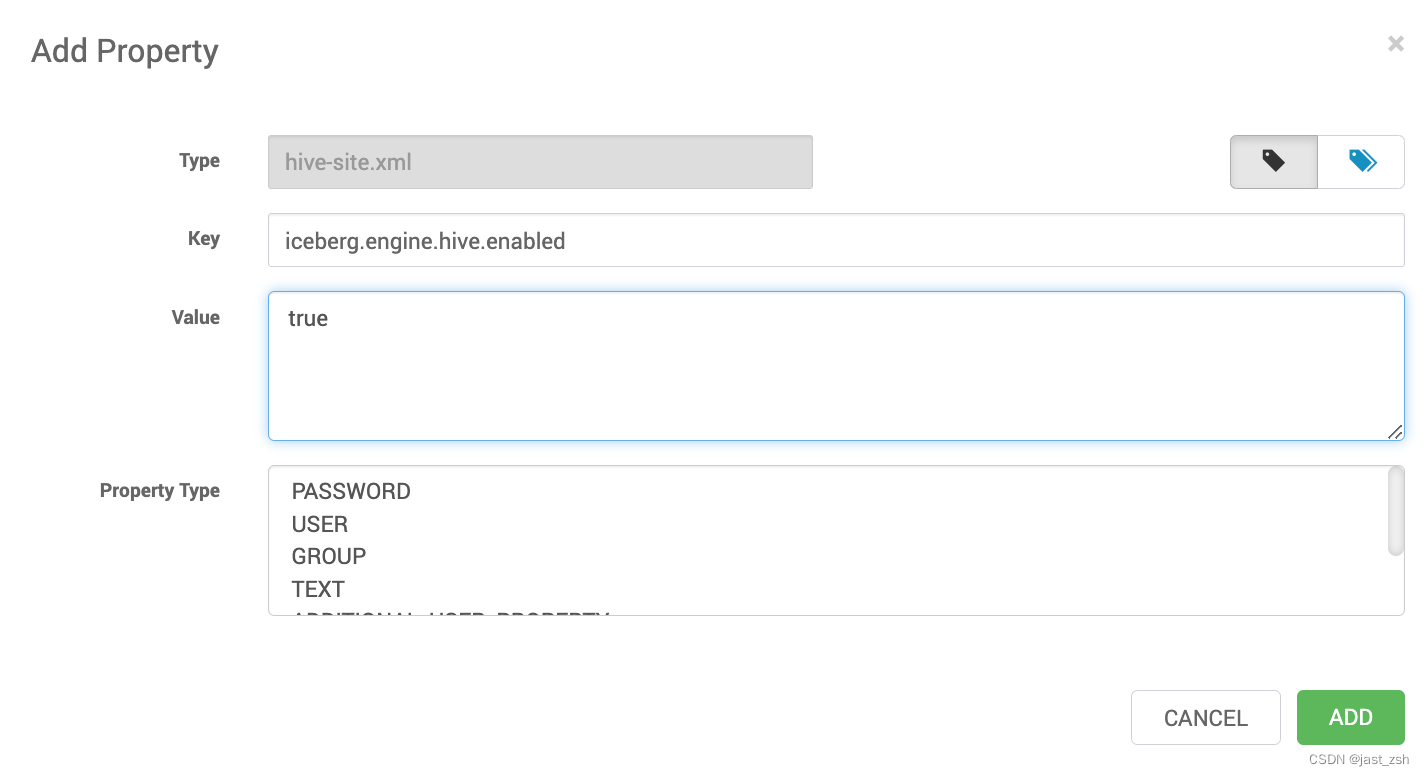

<property><name>iceberg.engine.hive.enabled</name><value>true</value>
</property><property><name>hive.aux.jars.path</name><value>/opt/hive/iceberglib</value>
</property>
在Ambari中配置hive(Ambari版本中必须配置这一步,不然后续创建表提示招不到类)
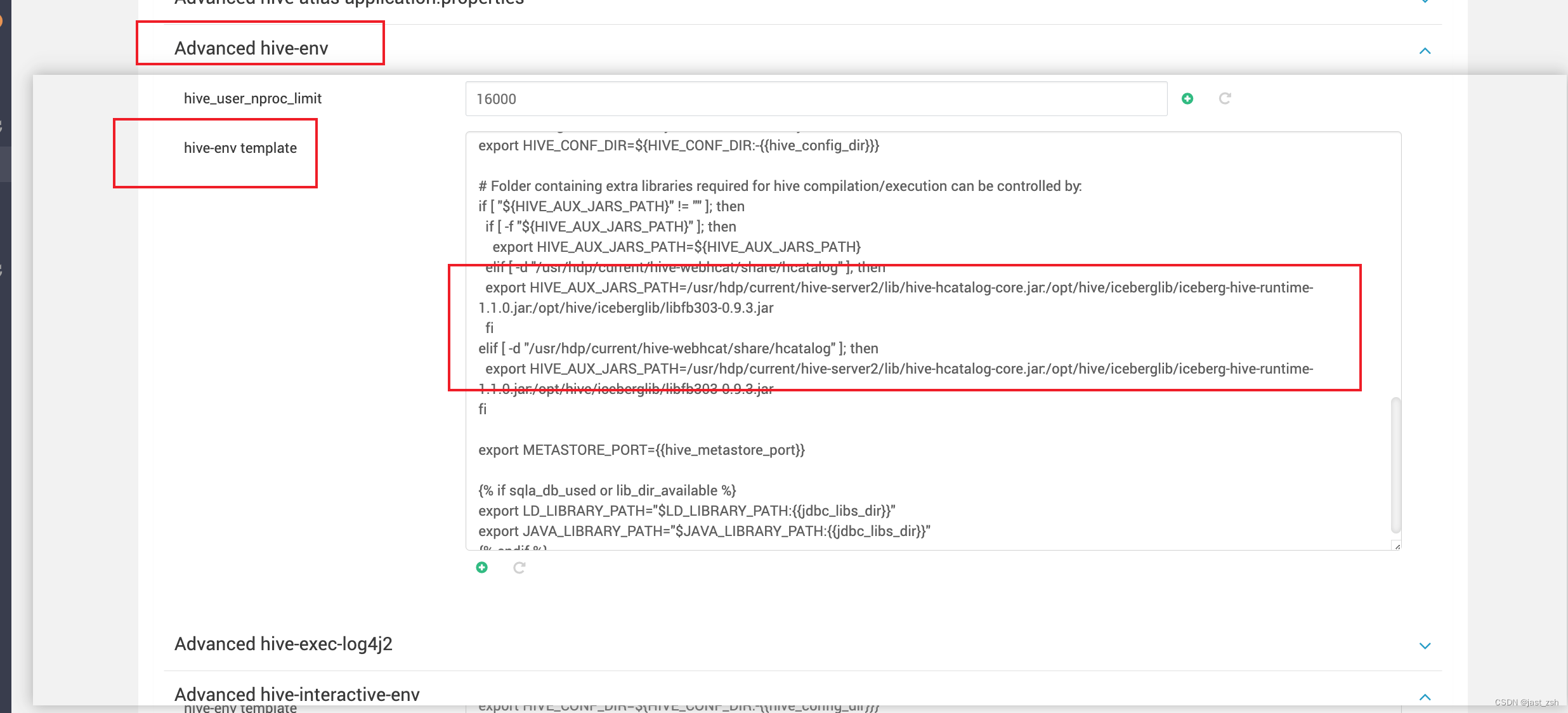
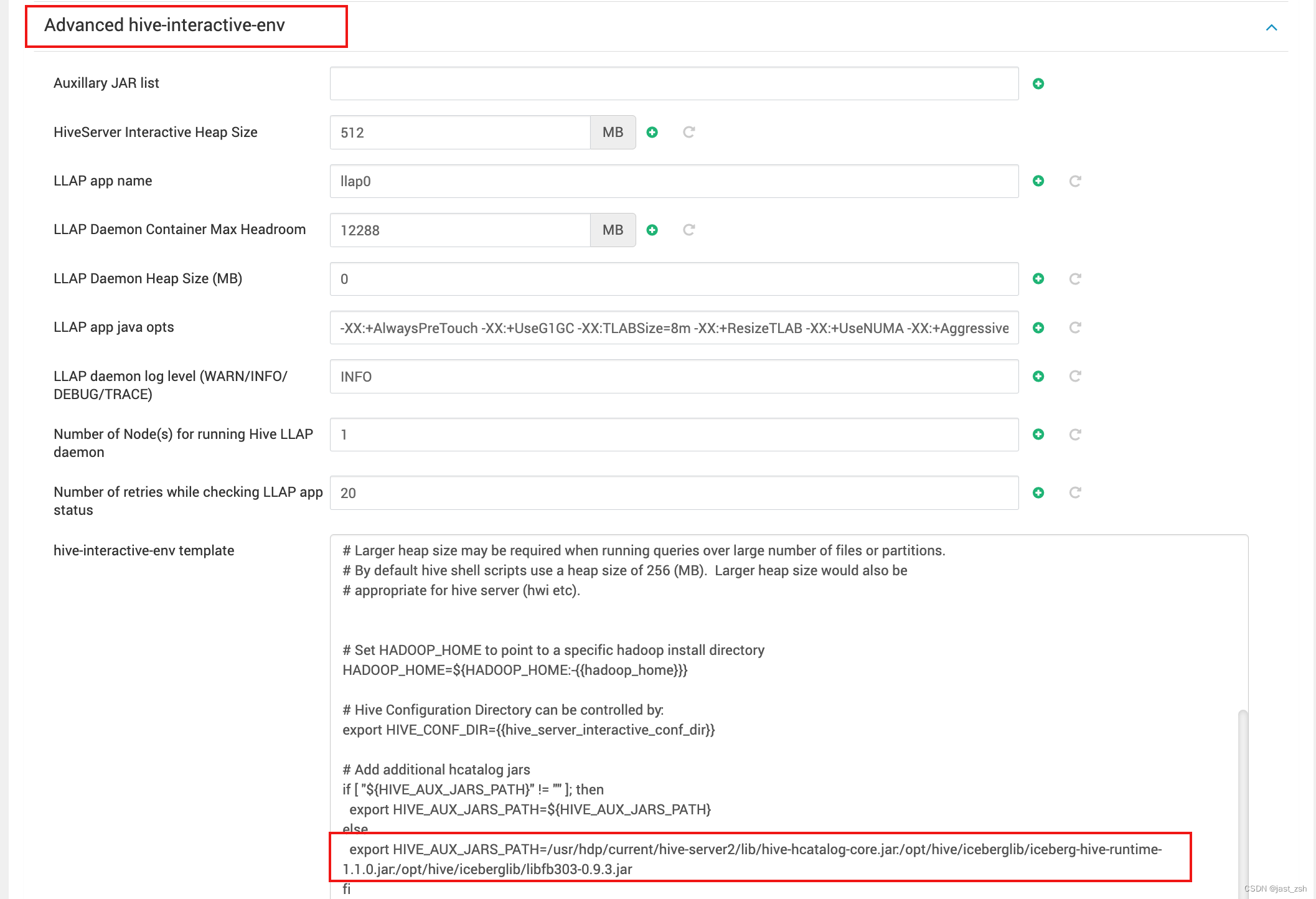
修改hive-interactive-env template和hive-env template中搜索HIVE_AUX_JARS_PATH,被配置我们引用的包
export HIVE_AUX_JARS_PATH=/usr/hdp/current/hive-server2/lib/hive-hcatalog-core.jar:/opt/hive/iceberglib/iceberg-hive-runtime-1.1.0.jar:/opt/hive/iceberglib/libfb303-0.9.3.jar
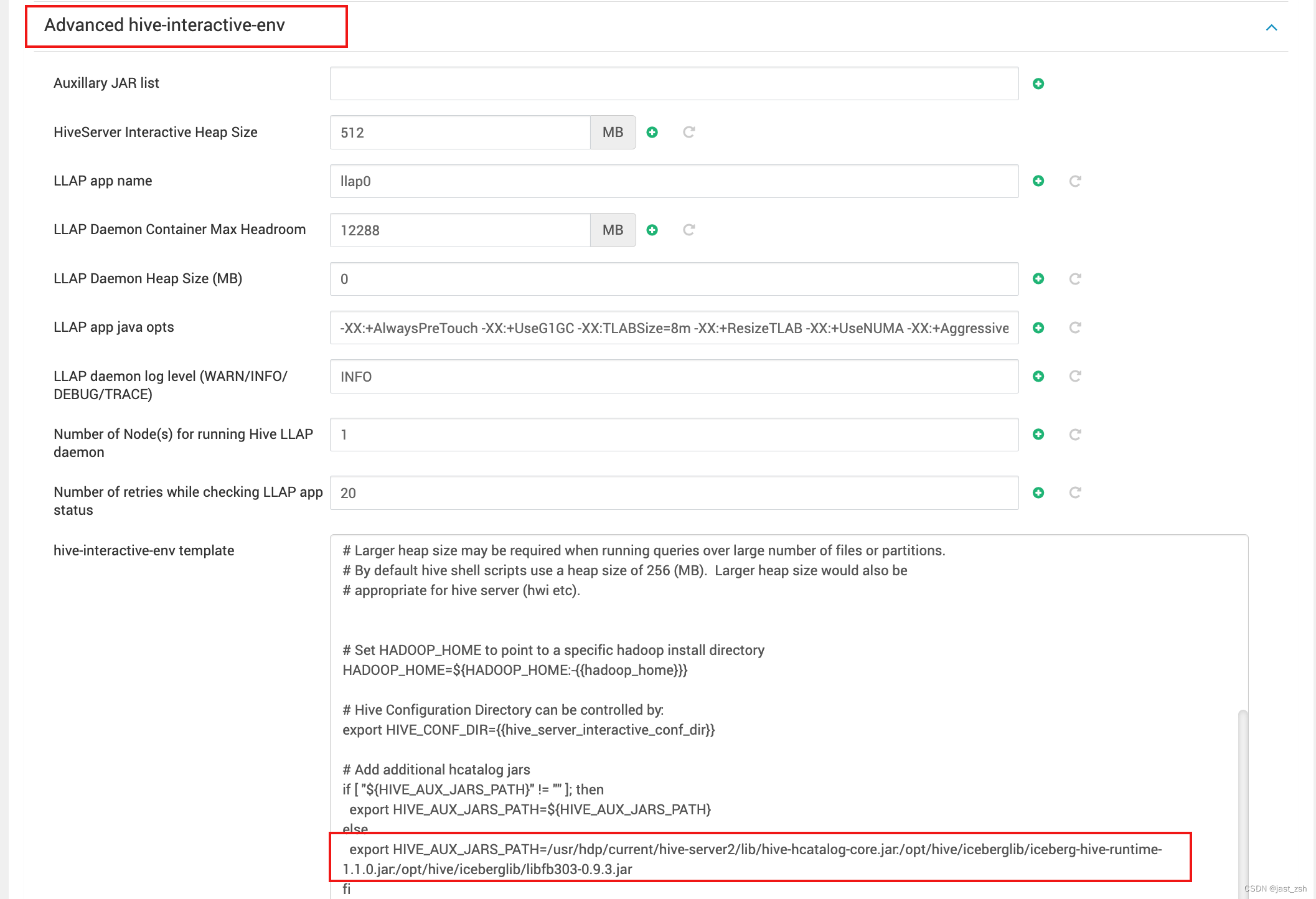
从Iceberg 0.11.0开始,如果Hive使用Tez引擎,需要关闭向量化执行:
<property><name>hive.vectorized.execution.enabled</name><value>false</value>
</property>
保存重启

可能遇到的问题
创建表提示 Error: Error while compiling statement: FAILED: SemanticException Cannot find class ‘org.apache.iceberg.mr.hive.HiveIcebergStorageHandler’ (state=42000,code=40000)
通过set hive.aux.jars.path;命令查看是否配置成功
0: jdbc:hive2://bigdata-24-199:2181,bigdata-2> set hive.aux.jars.path;
+----------------------------------------------------+
| set |
+----------------------------------------------------+
| hive.aux.jars.path=file:///usr/hdp/current/hive-webhcat/share/hcatalog/hive-hcatalog-core.jar |
+----------------------------------------------------+
1 row selected (0.836 seconds)
发现没有我们配置的jar包
说明我们之前配置没有生效,原因为:Ambari配置hive.aux.jars.path方式不同
配置方法:
-
1.hive添加第三方jar包
-
2.上传jar包,添加到hive-server所在服务器
-
3.在Ambari>hive>config中
的hive-interactive-env template和hive-env template中搜索HIVE_AUX_JARS_PATH,被配置我们引用的包HIVE_AUX_JARS_PATH=/usr/hdp/current/hive-server2-hive2/lib/hive-hcatalog-core.jar:/usr/hdp/current/hive-server2-hive2/lib/hive-udf.jar
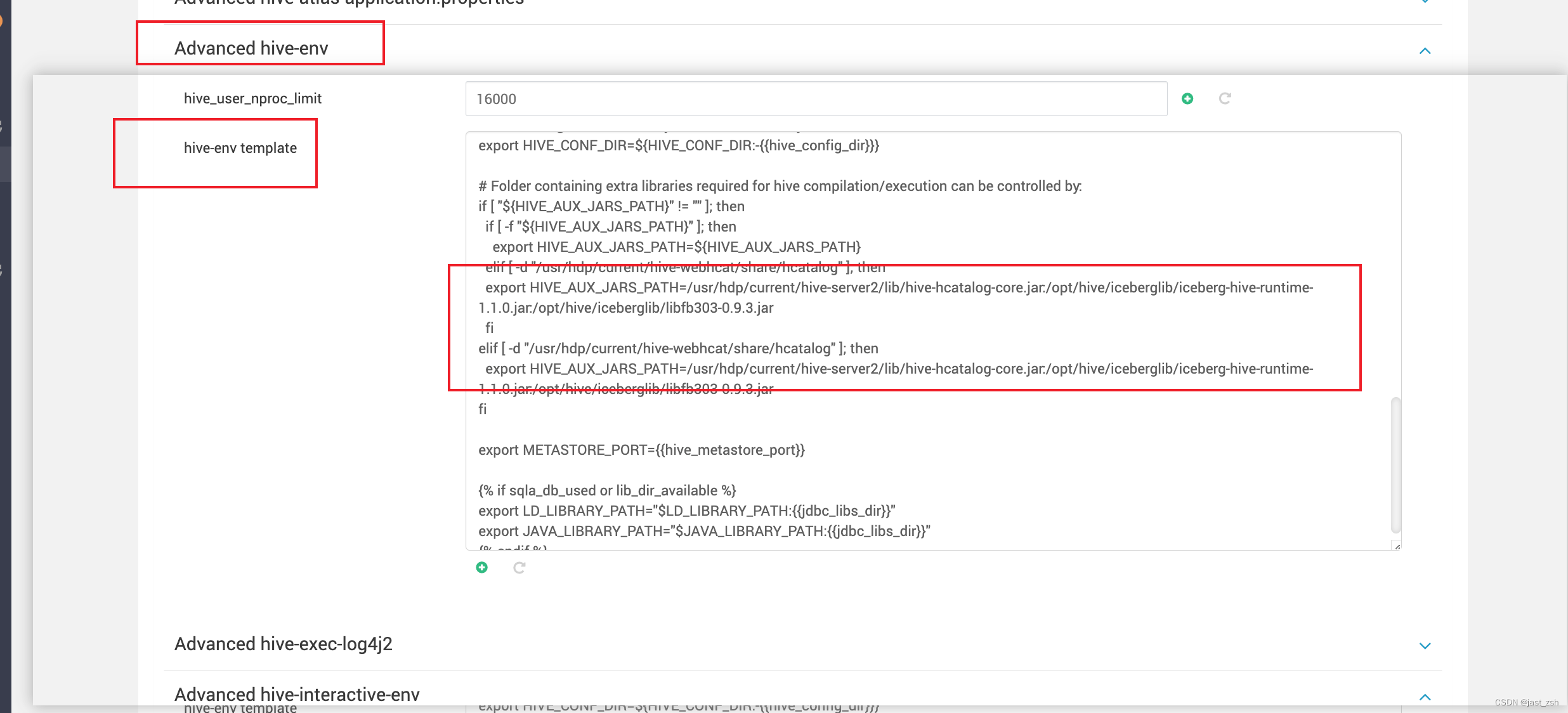
- 4.重启服务,解决问题
不兼容-insert数据后查询不到,在HDFS中也看不到快照等文件
执行 INSERT INTO iceberg_test1 values(1);添加数据后
执行查询看不到数据
0: jdbc:hive2://bigdata-24-199:2181,bigdata-2> select * from iceberg_test1;
INFO : Compiling command(queryId=hive_20230413105058_0937e14c-613a-43ce-ba17-18a6601f044c): select * from iceberg_test1
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:iceberg_test1.i, type:int, comment:null)], properties:null)
INFO : Completed compiling command(queryId=hive_20230413105058_0937e14c-613a-43ce-ba17-18a6601f044c); Time taken: 7.631 seconds
INFO : Executing command(queryId=hive_20230413105058_0937e14c-613a-43ce-ba17-18a6601f044c): select * from iceberg_test1
INFO : Completed executing command(queryId=hive_20230413105058_0937e14c-613a-43ce-ba17-18a6601f044c); Time taken: 0.027 seconds
INFO : OK
+------------------+
| iceberg_test1.i |
+------------------+
+------------------+
No rows selected (7.953 seconds)
查看HDFS存储该表的路径发现,数据文件在里面,metadata.json文件在里面,但是快照文件没有(文件接口可以查看文章:数据湖Iceberg-存储结构(2))暂时无法解决
[hdfs@bigdata-24-199 ~]$ hdfs dfs -ls /warehouse/tablespace/managed/hive/iceberg_test1
Found 2 items
drwx------+ - hive hadoop 0 2023-04-13 10:37 /warehouse/tablespace/managed/hive/iceberg_test1/data
drwx------+ - hive hadoop 0 2023-04-13 09:50 /warehouse/tablespace/managed/hive/iceberg_test1/metadata
[hdfs@bigdata-24-199 ~]$ hdfs dfs -ls /warehouse/tablespace/managed/hive/iceberg_test1/data
Found 2 items
-rw-rw----+ 3 hive hadoop 404 2023-04-13 10:36 /warehouse/tablespace/managed/hive/iceberg_test1/data/00000-0-hive_20230413103536_153504ef-df11-4744-adf8-6148912f484d-job_1681281011930_0005-00001.parquet
-rw-rw----+ 3 hive hadoop 404 2023-04-13 10:37 /warehouse/tablespace/managed/hive/iceberg_test1/data/00000-0-hive_20230413103726_6d188296-1ea0-453d-bc00-54f98cd97ee6-job_1681281011930_0005-00001.parquet
[hdfs@bigdata-24-199 ~]$ hdfs dfs -ls /warehouse/tablespace/managed/hive/iceberg_test1/metadata
Found 1 items
-rw-rw----+ 3 hive hadoop 1359 2023-04-13 09:50 /warehouse/tablespace/managed/hive/iceberg_test1/metadata/00000-d21b6e4e-636a-45ec-a3a5-805a8b99ffc2.metadata.json