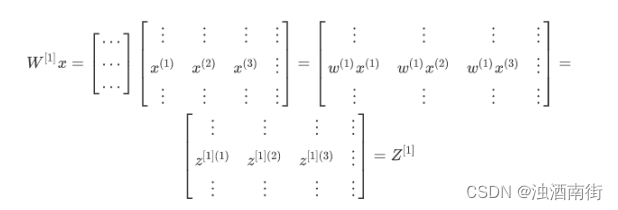直接上代码
import torch
import matplotlib.pyplot as plt
from torch import nn# 创建data
print("**** Create Data ****")
weight = 0.3
bias = 0.9
X = torch.arange(0,1,0.01).unsqueeze(dim = 1)
y = weight * X + bias
print(f"Number of X samples: {len(X)}")
print(f"Number of y samples: {len(y)}")
print(f"First 10 X & y sample: \n X: {X[:10]}\n y: {y[:10]}")
print("\n")# 将data拆分成training 和 testing
print("**** Splitting data ****")
train_split = int(len(X) * 0.8)
X_train = X[:train_split]
y_train = y[:train_split]
X_test = X[train_split:]
y_test = y[train_split:]
print(f"The length of X train: {len(X_train)}")
print(f"The length of y train: {len(y_train)}")
print(f"The length of X test: {len(X_test)}")
print(f"The length of y test: {len(y_test)}\n")# 显示 training 和 testing 数据
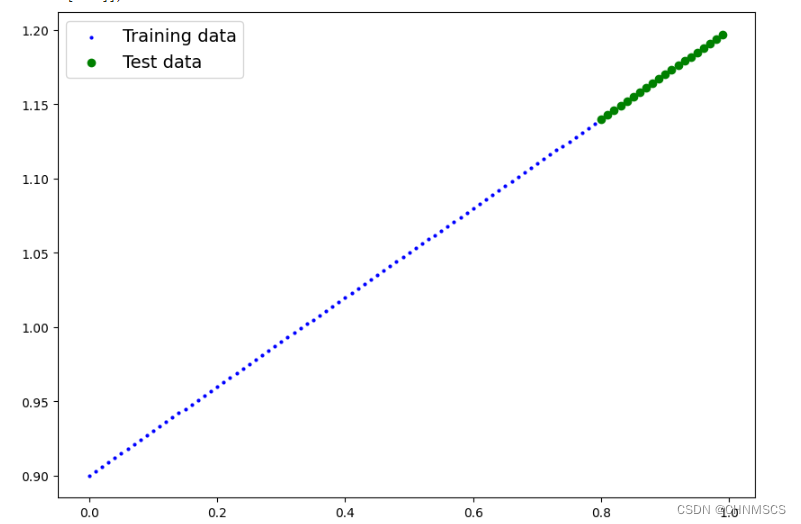
def plot_predictions(train_data = X_train,train_labels = y_train,test_data = X_test,test_labels = y_test,predictions = None):plt.figure(figsize = (10,7))plt.scatter(train_data, train_labels, c = 'b', s = 4, label = "Training data")plt.scatter(test_data, test_labels, c = 'g', label="Test data")if predictions is not None:plt.scatter(test_data, predictions, c = 'r', s = 4, label = "Predictions")plt.legend(prop = {"size": 14})
plot_predictions()# 创建线性回归
print("**** Create PyTorch linear regression model by subclassing nn.Module ****")
class LinearRegressionModel(nn.Module):def __init__(self):super().__init__()self.weight = nn.Parameter(data = torch.randn(1,requires_grad = True,dtype = torch.float))self.bias = nn.Parameter(data = torch.randn(1,requires_grad = True,dtype = torch.float))def forward(self, x):return self.weight * x + self.biastorch.manual_seed(42)
model_1 = LinearRegressionModel()
print(model_1)
print(model_1.state_dict())
print("\n")# 初始化模型并放到目标机里
print("*** Instantiate the model ***")
print(list(model_1.parameters()))
print("\\n")# 创建一个loss函数并优化
print("*** Create and Loss function and optimizer ***")
loss_fn = nn.L1Loss()
optimizer = torch.optim.SGD(params = model_1.parameters(),lr = 0.01)
print(f"loss_fn: {loss_fn}")
print(f"optimizer: {optimizer}\n")# 训练
print("*** Training Loop ***")
torch.manual_seed(42)
epochs = 300
for epoch in range(epochs):# 将模型加载到训练模型里model_1.train()# 做 Forwardy_pred = model_1(X_train)# 计算 Lossloss = loss_fn(y_pred, y_train)# 零梯度optimizer.zero_grad()# 反向传播loss.backward()# 步骤优化optimizer.step()### 做测试if epoch % 20 == 0:# 将模型放到评估模型并设置上下文model_1.eval()with torch.inference_mode():# 做 Forwardy_preds = model_1(X_test)# 计算测试 losstest_loss = loss_fn(y_preds, y_test)# 输出测试结果print(f"Epoch: {epoch} | Train loss: {loss:.3f} | Test loss: {test_loss:.3f}")# 在测试集上对训练模型做预测
print("\n")
print("*** Make predictions with the trained model on the test data. ***")
model_1.eval()
with torch.inference_mode():y_preds = model_1(X_test)
print(f"y_preds:\n {y_preds}")
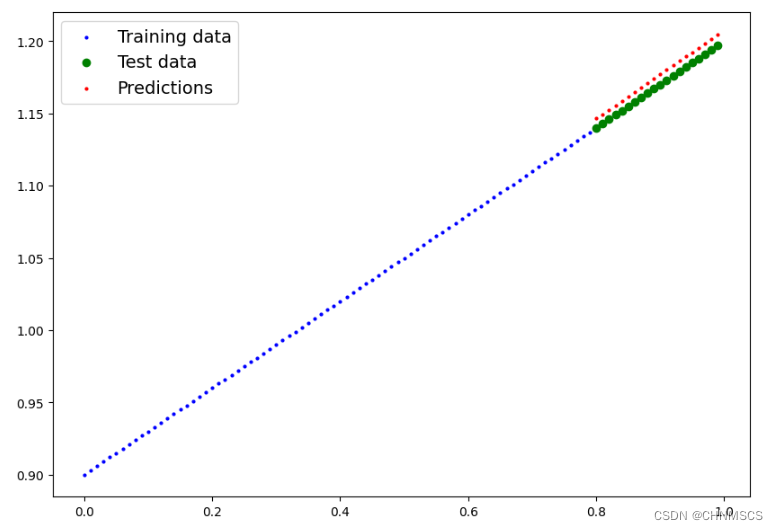
## 画图
plot_predictions(predictions = y_preds) # 保存训练好的模型
print("\n")
print("*** Save the trained model ***")
from pathlib import Path
## 创建模型的文件夹
MODEL_PATH = Path("models")
MODEL_PATH.mkdir(parents = True, exist_ok = True)
## 创建模型的位置
MODEL_NAME = "trained model"
MODEL_SAVE_PATH = MODEL_PATH / MODEL_NAME
## 保存模型到刚创建好的文件夹
print(f"Saving model to {MODEL_SAVE_PATH}")
torch.save(obj = model_1.state_dict(), f = MODEL_SAVE_PATH)
## 创建模型的新类型
loaded_model = LinearRegressionModel()
loaded_model.load_state_dict(torch.load(f = MODEL_SAVE_PATH))
## 做预测,并跟之前的做预测
y_preds_new = loaded_model(X_test)
print(y_preds == y_preds_new)结果如下
**** Create Data ****
Number of X samples: 100
Number of y samples: 100
First 10 X & y sample: X: tensor([[0.0000],[0.0100],[0.0200],[0.0300],[0.0400],[0.0500],[0.0600],[0.0700],[0.0800],[0.0900]])y: tensor([[0.9000],[0.9030],[0.9060],[0.9090],[0.9120],[0.9150],[0.9180],[0.9210],[0.9240],[0.9270]])**** Splitting data ****
The length of X train: 80
The length of y train: 80
The length of X test: 20
The length of y test: 20**** Create PyTorch linear regression model by subclassing nn.Module ****
LinearRegressionModel()
OrderedDict([('weight', tensor([0.3367])), ('bias', tensor([0.1288]))])*** Instantiate the model ***
[Parameter containing:
tensor([0.3367], requires_grad=True), Parameter containing:
tensor([0.1288], requires_grad=True)]*** Create and Loss function and optimizer ***
loss_fn: L1Loss()
optimizer: SGD (
Parameter Group 0dampening: 0differentiable: Falseforeach: Nonelr: 0.01maximize: Falsemomentum: 0nesterov: Falseweight_decay: 0
)*** Training Loop ***
Epoch: 0 | Train loss: 0.757 | Test loss: 0.725
Epoch: 20 | Train loss: 0.525 | Test loss: 0.454
Epoch: 40 | Train loss: 0.294 | Test loss: 0.183
Epoch: 60 | Train loss: 0.077 | Test loss: 0.073
Epoch: 80 | Train loss: 0.053 | Test loss: 0.116
Epoch: 100 | Train loss: 0.046 | Test loss: 0.105
Epoch: 120 | Train loss: 0.039 | Test loss: 0.089
Epoch: 140 | Train loss: 0.032 | Test loss: 0.074
Epoch: 160 | Train loss: 0.025 | Test loss: 0.058
Epoch: 180 | Train loss: 0.018 | Test loss: 0.042
Epoch: 200 | Train loss: 0.011 | Test loss: 0.026
Epoch: 220 | Train loss: 0.004 | Test loss: 0.009
Epoch: 240 | Train loss: 0.004 | Test loss: 0.006
Epoch: 260 | Train loss: 0.004 | Test loss: 0.006
Epoch: 280 | Train loss: 0.004 | Test loss: 0.006*** Make predictions wit the trained model on the test data. ***
y_preds:tensor([[1.1464],[1.1495],[1.1525],[1.1556],[1.1587],[1.1617],[1.1648],[1.1679],[1.1709],[1.1740],[1.1771],[1.1801],[1.1832],[1.1863],[1.1893],[1.1924],[1.1955],[1.1985],[1.2016],[1.2047]])*** Save the trained model ***
Saving model to models/trained model
tensor([[True],[True],[True],[True],[True],[True],[True],[True],[True],[True],[True],[True],[True],[True],[True],[True],[True],[True],[True],[True]])
点个赞支持一下咯~