Spark RDD 基本操作
在前面已经介绍过Spark RDD的两种操作分别是:
Transformation(转换操作)
Action(行动操作)
下面以例子的方式详细介绍Spark RDD的这两种操作涉及的函数。
Transformation(转换操作)
Transformation用于对RDD的创建,同时还提供大量操作方法,包括map,filter,groupBy,join等,RDD利用这些操作生成新的RDD,但是需要注意,无论多少次Transformation,在RDD中真正数据计算Action之前都不会真正运行。
map()函数
RDD.map(func),map接受一个函数作为参数,作用于RDD中的每个对象,并将返回结果作为结果RDD中对应的元素的值。
Scala
scala> val nums = sc.parallelize(List(1,2,3,4))
nums: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[4] at parallelize at <console>:27
scala>nums.take(4).foreach(println)
1
2
3
4
Python
>>> nums = sc.parallelize([1,2,3,4])
>>> for num in nums.take(4):
... print num
...
1
2
3
4
>>> new_nums = nums.map(lambda x: x*2)
>>> for new_num in new_nums.take(4):
... print new_num
...
2
4
6
8
flatMap()函数
RDD.flatMap(func),和map类似,只不过map返回的是一个个元素,而flatMap返回的则是一个返回值序列的迭代器。
Scala
scala> val string = sc.parallelize(List("i love you"))
string: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[5] at parallelize at <console>:27
scala> val new_str = string.flatMap(line=>line.split(" "))
new_str: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[6] at flatMap at <console>:29
scala> new_str.take(3).foreach(println)
i
love
youPython
>>> string = sc.parallelize(["i love you"])
>>> new_str = string.flatMap(lambda str:str.split(" "))</span>
>>> for str in new_str.take(3):
... print str
...
i
love
you
filter()函数
RDD.filter(func),接受一个函数作为参数,并将RDD中满足该函数的元素放入新的RDD中返回。
Scala
scala> val string = sc.parallelize(List("i love you"))
string: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[7] at parallelize at <console>:27
scala> string.first()
res3: String = i love you
scala>
<pre name="code" class="java">scala> val string = sc.parallelize(List("I love you"))
scala> val new_str = string.filter(line =>line.contains("love"))
new_str: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[6] at filter at <console>:23
scala> new_str.foreach(println)
I love you
Python
>>> string = sc.parallelize(["i love you"])
>>> new_str = string.filter(lambda line : "you" in line)
>>> new_str.first()
'i love you'
union()函数
RDD1.union(RDD2),操作对象为两个RDD,返回一个新的RDD,转化操作可以操作任意数量的输入RDD。
Scala
scala> val num1 = sc.parallelize(List(1,2,3))
num1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:27
scala> val num2 = sc.parallelize(List(4,5,6))
num2: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[1] at parallelize at <console>:27
scala> val num3 = num1.union(num2)
mum3: org.apache.spark.rdd.RDD[Int] = UnionRDD[2] at union at <console>:31
scala> num3.count()
res1: Long = 6
scala> num3.foreach(println)
3
1
2
4
5
6
Python
>>> num1 = sc.parallelize([1,2,3])
>>> num2 = sc.parallelize([4,5,6])
>>> num3 = num1.union(num2)
>>> for num in num3.take(6):
... print num
...
1
2
3
4
5
6
filter()函数
RDD.filter(func),接受一个函数作为参数,并将RDD中满足该函数的元素放入新的RDD中返回。
Python
>>> string = sc.parallelize(["i love you"])
>>> new_str = string.filter(lambda line : "you" in line)
>>> new_str.first()
'i love you'
Scala
scala> val string = sc.parallelize(List("i love you"))
string: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[7] at parallelize at <console>:27
scala> string.first()
res3: String = i love you
scala>
<pre name="code" class="java">scala> val string = sc.parallelize(List("I love you"))
scala> val new_str = string.filter(line =>line.contains("love"))
new_str: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[6] at filter at <console>:23
scala> new_str.foreach(println)
I love you
union()函数
RDD1.union(RDD2),操作对象为两个RDD,返回一个新的RDD,转化操作可以操作任意数量的输入RDD。
Scala
scala> val num1 = sc.parallelize(List(1,2,3))
num1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:27
scala> val num2 = sc.parallelize(List(4,5,6))
num2: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[1] at parallelize at <console>:27
scala> val num3 = num1.union(num2)
mum3: org.apache.spark.rdd.RDD[Int] = UnionRDD[2] at union at <console>:31
scala> num3.count()
res1: Long = 6
scala> num3.foreach(println)
3
1
2
4
5
6
Python
>>> num1 = sc.parallelize([1,2,3])
>>> num2 = sc.parallelize([4,5,6])
>>> num3 = num1.union(num2)
>>> for num in num3.take(6):
... print num
...
1
2
3
4
5
6
distinct()函数
RDD.distinct(),该函数作用就是去重,但其操作的开销大,因为它需要所有数据通过网络进行混洗。
Scala
scala> val num1 = sc.parallelize(List(1,2,3,3))
num1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[4] at parallelize at <console>:27
scala> val num2 = num1.distinct()
num2: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[7] at distinct at <console>:29
scala> num2.foreach(println)
2
3
1
Python
>>> nums1 = sc.parallelize([1,2,3,3])
>>> nums1.count()
4
>>> nums2=nums1.distinct()
>>> nums2.count()
3
>>>
intersection()函数
RDD1.intersection(RDD2),返回两个RDD中都有的元素,类似于集合中的交集。
Scala
scala> val num1 = sc.parallelize(List(1,2,3,4))
num1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[9] at parallelize at <console>:27
scala> val num2 = sc.parallelize(List(3,4,5,6))
num2: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[10] at parallelize at <console>:27
scala> val num3 = num1.intersection(num2)
num3: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[16] at intersection at <console>:31
scala> num3.foreach(println)
4
3
Python
>>> nums_1=sc.parallelize([1,2,3,4,5])
>>> nums_2=sc.parallelize([3,4,5,6,7])
>>> nums_3=nums_1.intersection(nums_2)
>>> nums_3.count()
[Stage 7:> (0 + 3
>>> for num in nums_3.take(3):
... print num
...
3
4
5
>>>
subtract()函数
RDD1.subtract(RDD2),接受一个RDD作为参数,返回一个由只存在第一个RDD1而不存在与第二个RDD2中的所有元素组成的RDD。
Scala
scala> val num1 = sc.parallelize(List(1,2,3,4))
num1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[17] at parallelize at <console>:27
scala> val num2 = sc.parallelize(List(3,4,5,6))
num2: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[18] at parallelize at <console>:27
scala> val num3 = num1.subtract(num2)
num3: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[22] at subtract at <console>:31
scala> num3.foreach(println)
2
1
Python
>>> nums_4 = nums_1.subtract(nums_2)
>>> nums_4.count()
2
>>> for num in nums_4.take(2):
... print num
...
1
2
>>>
cartesian()函数
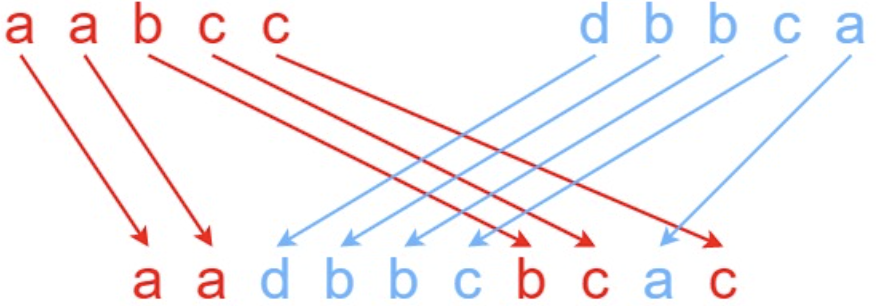
RDD1.cartesian(RDD2),求笛卡尔积,求出所有可能的(a,b)对。
Scala
scala> val num1 = sc.parallelize(List(1,2,3,4))
num1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[23] at parallelize at <console>:27
scala> val num2 = sc.parallelize(List(3,4,5,6))
num2: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[24] at parallelize at <console>:27
scala> val num3 = num1.cartesian(num2)
num3: org.apache.spark.rdd.RDD[(Int, Int)] = CartesianRDD[25] at cartesian at <console>:31
scala> num3.foreach(println)
(1,3)
(1,5)
(1,6)
(1,4)
(2,3)
(2,4)
(3,3)
(2,5)
(2,6)
(3,4)
(3,6)
(4,3)
(3,5)
(4,5)
(4,4)
(4,6)
Python
>>> nums_5 = nums_1.cartesian(nums_2)
>>> nums_5
org.apache.spark.api.java.JavaPairRDD@5617ade8
>>> nums_5.first()
(1, 3)
>>>
sample()函数
sample(withReplacement,traction,[send])对RDD采样以及是否转换。
Scala
scala> val num1 = sc.parallelize(List(1,2,3,4))
num1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[37] at parallelize at <console>:27
scala> val num2 = num1.sample(false,0.5)
num2: org.apache.spark.rdd.RDD[Int] = PartitionwiseSampledRDD[38] at sample at <console>:29
scala> num2.foreach(println)
2
3
Python
>>> nums = sc.parallelize([1,2,3,4,5,6,7])
>>> new_nums = nums.sample(False,0.5)
>>> new_nums
PythonRDD[106] at RDD at PythonRDD.scala:43
>>> new_nums.count()
5
>>> for n in new_nums.take(5):
... print n
...
1
3
5
6
7
Action(行动操作)
Action是数据执行部分,其通过执行count,reduce,collect等方法真正执行数据的计算部分。实际上,RDD中所有的操作都是Lazy模式进行,运行在编译中不会立即计算最终结果,而是记住所有操作步骤和方法,只有显示的遇到启动命令才执行。这样做的好处在于大部分前期工作在Transformation时已经完成,当Action工作时,只需要利用全部自由完成业务的核心工作。
count()函数
RDD.count(),是统计RDD中元素的个数,返回的是一个整数。
Scala
scala> val num1 = sc.parallelize(List(1,2,3))
num1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[3] at parallelize at <console>:27
scala> num1.count()
res3: Long = 3
Python
>>> nums = sc.parallelize([1,2,3,4])
>>> nums.count()
[Stage 0:> (0 +[Stage 0:> (0 +[Stage 0:==============>(1 +4
>>>
collect()函数
RDD.collect(),用来收集数据,保存在一个新的数据结构中,用来持久化,需要注意的是collect不能用在大规模数据集上。
Scala
scala> val num2=num1.collect()
num2: Array[Int] = Array(1, 2, 3)
scala> num2
res4: Array[Int] = Array(1, 2, 3)
scala>
Python
>>> new_nums = nums.collect()
>>> new_nums
[1, 2, 3, 4]
>>>take()函数
RDD.take(num),用于取回num个value,在这里结合map使用,方便查看值。
Scala
scala> val nums = sc.parallelize(List(1,2,3,4))
nums: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[4] at parallelize at <console>:27
scala>nums.take(4).foreach(println)
1
2
3
4
Python
>>> nums = sc.parallelize([1,2,3,4])
>>> for num in nums.take(4):
... print num
...
1
2
3
4
>>> new_nums = nums.map(lambda x: x*2)
>>> for new_num in new_nums.take(4):
... print new_num
...
2
4
6
8
reduce()函数
RDD.reduce(func),接受一个函数作为参数,操作两个RDD的元素类型的数据并返回一个同样类型的新元素。
Scala
scala> val num1 = sc.parallelize(List(1,2,3,4))
num1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[27] at parallelize at <console>:27
scala> val num2 = num1.reduce((x,y)=>x+y)
num2: Int = 10
Python
>>> nums=sc.parallelize([1,2,3,4,5,6])
>>> nums.reduce(lambda x,y:x+y)
21
>>>
aggregate()函数
aggregate()函数需要我们提供期待返回的类型的初始值,然后通过一个函数把RDD中的元素合并起来放入累加器,考虑到每个节点是在本地累加的,最终,还需要通过第二个函数把累加器两两合并。
Scala
scala> val num1 = sc.parallelize(List(1,2,3,4))
num1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[30] at parallelize at <console>:27
scala> val result = num1.aggregate((0,0))(| (acc,value) => (acc._1 + value,acc._2+1),| (acc1,acc2) =>(acc1._1+acc2._1,acc1._2+acc2._2)| )
result: (Int, Int) = (10,4)
scala> val avg = result._1/result._2.toDouble
avg: Double = 2.5
scala>
Python
>>> nums = sc.parallelize([1,2,3,4])
>>> sumCount = nums.aggregate( (0,0),
... (lambda acc,value:(acc[0]+value,acc[1]+1)),
... (lambda acc1,acc2:(acc1[0]+acc2[0],acc1[1]+acc2[1])))
>>> sumCount[0]/float(sumCount[1])
2.5
>>>
foreach()函数
RDD.foreach(func),对RDD中的每个元素使用给定的函数。
Scala
scala> def add(x:Int)={| println (x+2)| }
add: (x: Int)Unit
scala> val num1 = sc.parallelize(List(1,2,3,4))
num1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[36] at parallelize at <console>:27
scala> num1.foreach(add)
6
5
3
4
Python
>>> nums = sc.parallelize([1,2,3])
>>> def add(x):
... print "\n","x+2:",x+2
...
>>> nums.foreach(add)
x+2: 5
x+2: 3
x+2: 4
top()函数
RDD.top(num),从RDD中返回前边的num个元素。
Scala
scala> val num1 = sc.parallelize(List(1,2,3,4))
num1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[31] at parallelize at <console>:27
scala> num1.top(2)
res10: Array[Int] = Array(4, 3)
scala>
Python
>>> nums = sc.parallelize([1,2,3])
>>> def add(x):
... print "\n","x+2:",x+2
...
>>> nums.foreach(add)
x+2: 5
x+2: 3
x+2: 4
takeSample()函数
RDD.takeSample(withReplacement,num,[send]),从RDD中返回任意一些元素。
Scala
scala> val num1 = sc.parallelize(List(1,2,3,4))
num1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[39] at parallelize at <console>:27
scala> val num2 = num1.takeSample(false,2)
num2: Array[Int] = Array(3, 4)
Python
>>> nums = sc.parallelize([1,2,3,4,5,6,7])
>>> new_nums= nums.takeSample(False,5)
>>> new_nums
[5, 3, 4, 6, 7]
Spark 转换操作和行动操作函数汇总
Spark 转换操作
| 函数名 | 作用 |
|---|---|
| map() | 参数是函数,函数应用于RDD每一个元素,返回值是新的RDD |
| flatMap() | 参数是函数,函数应用于RDD每一个元素,将元素数据进行拆分,变成迭代器,返回值是新的RDD |
| filter() | 参数是函数,函数会过滤掉不符合条件的元素,返回值是新的RDD |
| distinct() | 没有参数,将RDD里的元素进行去重操作 |
| union() | 参数是RDD,生成包含两个RDD所有元素的新RDD |
| intersection() | 参数是RDD,求出两个RDD的共同元素 |
| subtract() | 参数是RDD,将原RDD里和参数RDD里相同的元素去掉 |
| cartesian() | 参数是RDD,求两个RDD的笛卡儿积 |
Spark action操作
| 函数名 | 作用 |
|---|---|
| collect() | 返回RDD所有元素 |
| count() | RDD里元素个数 |
| countByValue() | 各元素在RDD中出现次数 |
| reduce() | 并行整合所有RDD数据,例如求和操作 |
| fold(0)(func) | 和reduce功能一样,不过fold带有初始值 |
| aggregate(0)(seqOp,combop) | 和reduce功能一样,但是返回的RDD数据类型和原RDD不一样 |
| foreach(func) | 对RDD每个元素都是使用特定函数 |


![数据库被.[Goodmorningfriends@onionmail.org].faust勒索病毒加密,能恢复吗?](https://img-blog.csdnimg.cn/direct/6547328ef6bc4864be7c5a7d89505198.jpeg)