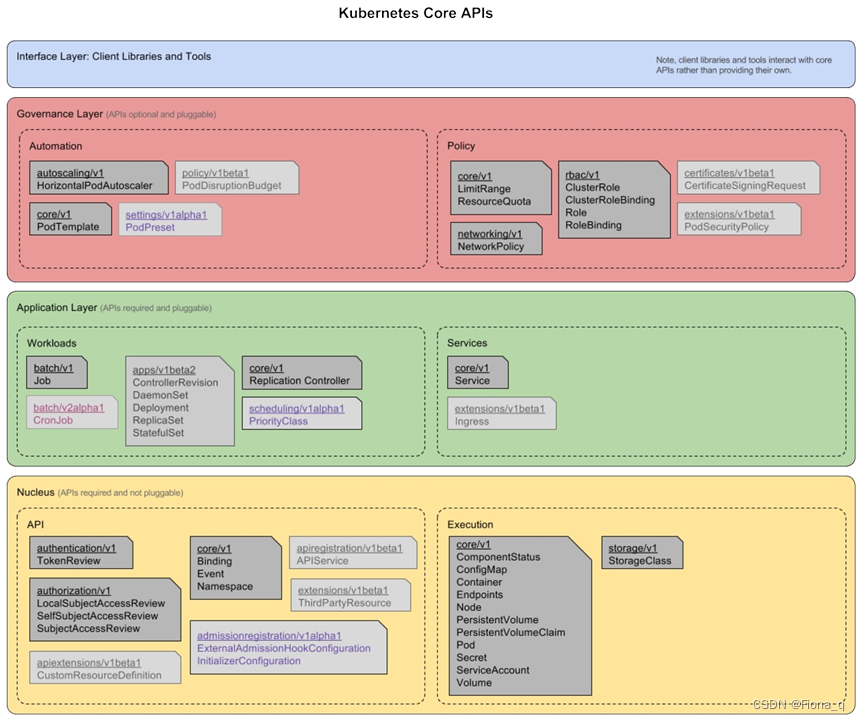
策略模式
- 一、介绍
- 二、不同的支付方式采用不同的策略
- 三、 电商定价策略
- 四、日志记录策略
- 五、 压缩算法
- 六、Java 中的 `Arrays.sort()` 方法,不同的排序策略进行排序
- 七、Spring 中的 `ResourceLoader` 类,不同的资源位置采用不同的加载策略
一、介绍
策略模式是一种行为型设计模式,它定义了一系列算法,并将每个算法封装起来,使它们可以相互替换。策略模式让算法的变化独立于使用算法的客户端。
策略模式的主要角色有
-
Context(上下文): 负责维护一个具体的策略类实例,并根据它来协调算法的执行。
-
Strategy(抽象策略): 定义了一个算法族,声明了一个算法的操作,它有一个或多个具体的策略类实现。
-
ConcreteStrategy(具体策略): 具体实现了 Strategy 接口定义的算法。
策略模式的优点
- 算法可以在运行时进行切换,避免了使用复杂的条件语句。
- 扩展性良好,增加一个策略只需增加一个具体的策略类即可。
- 避免使用多重条件转移语句,利于代码的维护。
策略模式的缺点
- 客户端必须知道所有的策略类,并且需要理解具体的策略类,违反了最少知识原则。
- 增加了对象的数目。
二、不同的支付方式采用不同的策略
// 支付策略接口
interface PaymentStrategy {boolean pay(double amount);
}// 具体的支付策略实现
class CashPaymentStrategy implements PaymentStrategy {@Overridepublic boolean pay(double amount) {System.out.println("现金支付了 " + amount + " 元");return true;}
}class CreditCardPaymentStrategy implements PaymentStrategy {@Overridepublic boolean pay(double amount) {System.out.println("信用卡支付了 " + amount + " 元");return true;}
}// 上下文类
class PaymentContext {private PaymentStrategy strategy;public void setStrategy(PaymentStrategy strategy) {this.strategy = strategy;}public boolean executePayment(double amount) {return strategy.pay(amount);}
}// 客户端代码
public class Client {public static void main(String[] args) {PaymentContext context = new PaymentContext();context.setStrategy(new CashPaymentStrategy());context.executePayment(100.0); // 现金支付了 100.0 元context.setStrategy(new CreditCardPaymentStrategy());context.executePayment(200.0); // 信用卡支付了 200.0 元}
}
PaymentStrategy接口定义了支付操作的抽象策略。CashPaymentStrategy和CreditCardPaymentStrategy分别实现了现金支付和信用卡支付的具体策略。PaymentContext类是上下文,它维护了一个策略实例,并提供了执行支付操作的方法。- 在客户端代码中,我们可以根据需要动态地设置不同的支付策略,并执行相应的支付操作。
Java项目中有很多地方都可以使用策略模式,下面我给出一些典型的例子:
三、 电商定价策略
在一个电商项目中,我们可以根据不同的营销策略对商品进行不同的定价。比如,对于普通用户可以按照原价定价,而对于VIP用户则可以打折。我们可以使用策略模式来实现这个需求。
// 定价策略接口
interface PricingStrategy {double calculatePrice(double originalPrice);
}// 原价定价策略
class OriginalPricingStrategy implements PricingStrategy {@Overridepublic double calculatePrice(double originalPrice) {return originalPrice;}
}// VIP折扣策略
class VipDiscountPricingStrategy implements PricingStrategy {private final double discountRate;public VipDiscountPricingStrategy(double discountRate) {this.discountRate = discountRate;}@Overridepublic double calculatePrice(double originalPrice) {return originalPrice * (1 - discountRate);}
}// 定价上下文
class PricingContext {private PricingStrategy strategy;public void setStrategy(PricingStrategy strategy) {this.strategy = strategy;}public double calculatePrice(double originalPrice) {return strategy.calculatePrice(originalPrice);}
}
四、日志记录策略
在一个需要记录日志的系统中,我们可能需要根据不同的日志级别采用不同的日志记录策略。比如,对于DEBUG级别的日志,我们可以将其记录到控制台,而对于ERROR级别的日志,我们则需要将其记录到文件中。这种情况下,就可以使用策略模式。
// 日志记录策略接口
interface LoggingStrategy {void log(String message, LogLevel level);
}// 控制台日志记录策略
class ConsoleLoggingStrategy implements LoggingStrategy {@Overridepublic void log(String message, LogLevel level) {System.out.println("[" + level + "] " + message);}
}// 文件日志记录策略
class FileLoggingStrategy implements LoggingStrategy {@Overridepublic void log(String message, LogLevel level) {// 将日志记录到文件中}
}// 日志记录上下文
class LoggingContext {private LoggingStrategy strategy;public void setStrategy(LoggingStrategy strategy) {this.strategy = strategy;}public void log(String message, LogLevel level) {strategy.log(message, level);}
}
五、 压缩算法
在一个需要进行数据压缩的系统中,我们可能需要根据不同的场景采用不同的压缩算法。比如,对于一般的文本数据,我们可以使用Gzip算法进行压缩,而对于多媒体数据,我们则需要使用更高效的算法。这种情况下,我们可以使用策略模式来实现不同的压缩算法。
// 压缩策略接口
interface CompressionStrategy {byte[] compress(byte[] data);byte[] decompress(byte[] compressedData);
}// Gzip压缩策略
class GzipCompressionStrategy implements CompressionStrategy {@Overridepublic byte[] compress(byte[] data) {// 使用Gzip算法进行压缩}@Overridepublic byte[] decompress(byte[] compressedData) {// 使用Gzip算法进行解压缩}
}// ZLIB压缩策略
class ZlibCompressionStrategy implements CompressionStrategy {@Overridepublic byte[] compress(byte[] data) {// 使用ZLIB算法进行压缩}@Overridepublic byte[] decompress(byte[] compressedData) {// 使用ZLIB算法进行解压缩}
}// 压缩上下文
class CompressionContext {private CompressionStrategy strategy;public void setStrategy(CompressionStrategy strategy) {this.strategy = strategy;}public byte[] compress(byte[] data) {return strategy.compress(data);}public byte[] decompress(byte[] compressedData) {return strategy.decompress(compressedData);}
}
六、Java 中的 Arrays.sort() 方法,不同的排序策略进行排序
Java 的 Arrays.sort() 方法在内部确实使用了策略模式来实现不同的排序算法。下面我们来详细分析一下它的底层实现源码。
Arrays.sort() 方法的实现位于 java.util.Arrays 类中,它根据待排序数组的类型和大小,选择合适的排序算法进行排序。在这个过程中,它使用了策略模式来封装不同的排序算法。
首先,让我们看看 Arrays.sort() 方法的签名:
public static void sort(Object[] a) {// 判断数组类型和长度if (LegacyMergeSort.userRequested)legacyMergeSort(a);elseComputeMaxs.parallelSort(a, null);
}
可以看到,对于对象数组,sort() 方法会根据一个名为 LegacyMergeSort.userRequested 的标志位,选择使用旧的归并排序算法(legacyMergeSort)或者新的并行排序算法(ComputeMaxs.parallelSort)。这里就体现了策略模式的思想,不同的排序算法被封装在不同的策略类中。
接下来,我们看看新的并行排序算法 ComputeMaxs.parallelSort() 的实现:
static <T extends Comparable<? super T>> void parallelSort(T[] a, Comparator<? super T> cmp) {// 根据数组长度选择合适的排序算法int len = a.length;if (len > MIN_ARRAY_SORT_GRAN) {rangeSort(a, 0, len - 1, cmp);} else if (len != 0) {Binarysort.sort(a, 0, len, null, cmp);}
}private static <T extends Comparable<? super T>>
void rangeSort(T[] a, int from, int to, Comparator<? super T> cmp) {// 使用TimSort或归并排序算法进行排序if (from == 0 && to == a.length - 1) {// 使用TimSort算法new TimSort(a, cmp).sort(a, from, to);} else {// 使用归并排序算法new MergeSort(a, cmp, from, to).sort();}
}
在上面的代码中,我们可以看到
parallelSort()方法根据数组长度选择使用rangeSort()或Binarysort.sort()。rangeSort()用于较大的数组,而Binarysort.sort()用于较小的数组。rangeSort()方法根据数组的范围,选择使用TimSort算法或归并排序(MergeSort)算法。
这里,TimSort、MergeSort 和 Binarysort 就是不同的排序策略类。它们都实现了相应的排序算法,而 parallelSort() 和 rangeSort() 充当了策略模式中的上下文(Context)角色,根据具体情况选择合适的策略类。
让我们继续看看 TimSort 的实现
static final class TimSort<T extends Comparable<? super T>> extends MergeSort<T> {// TimSort算法的实现代码...
}
TimSort 类继承自 MergeSort 类,它是一种改进的归并排序算法,对于部分有序的数组有更好的性能表现。
而 MergeSort 类则实现了传统的归并排序算法
static final class MergeSort<T extends Comparable<? super T>> extends Sorter<T> {// 归并排序算法的实现代码...
}
MergeSort 继承自 Sorter 抽象类,Sorter 定义了一些公共的排序方法和字段,同时也包含了 Binarysort 的实现。
abstract static class Sorter<T extends Comparable<? super T>> {// 一些公共方法和字段...// Binarysort算法的实现static <T extends Comparable<? super T>> void sort(T[] a, int from, int to, ...) {// Binarysort算法实现代码...}
}
通过上面的源码分析,我们可以看到 Java Arrays.sort() 方法是如何使用策略模式来选择合适的排序算法的。不同的排序算法被封装在不同的策略类中,如 TimSort、MergeSort 和 Binarysort。而 parallelSort() 和 rangeSort() 方法则根据具体情况选择合适的策略类进行排序。
这种设计使得 Arrays.sort() 方法可以灵活地切换不同的排序算法,也便于后续添加新的排序算法。同时,由于每种算法都被封装在单独的类中,代码的可读性和维护性也得到了提高。
总的来说,Java 的 Arrays.sort() 方法是一个很好的策略模式的应用实例,它展示了如何使用策略模式来封装和选择不同的算法,提高代码的灵活性和可扩展性。
七、Spring 中的 ResourceLoader 类,不同的资源位置采用不同的加载策略
在 Spring 5 中,ResourceLoader 接口使用了策略模式来加载不同类型的资源。它定义了一个统一的接口,而具体的资源加载策略则由不同的实现类来处理。下面我们来分析一下它的底层源码:
ResourceLoader 接口的定义如下:
public interface ResourceLoader {Resource getResource(String location);ClassLoader getClassLoader();
}
它定义了两个方法:
getResource(String location)用于根据给定的资源位置返回对应的Resource对象。getClassLoader()返回相关的ClassLoader。
Spring 提供了一个默认的 ResourceLoader 实现类 DefaultResourceLoader。它实现了多种资源加载策略,包括从类路径、文件系统、URL 等不同位置加载资源。
public class DefaultResourceLoader implements ResourceLoader {// ...@Overridepublic Resource getResource(String location) {Assert.notNull(location, "Location must not be null");// 通过 ClassPathContextResource 策略加载类路径资源if (location.startsWith(CLASSPATH_URL_PREFIX)) {return new ClassPathContextResource(location.substring(CLASSPATH_URL_PREFIX.length()), getClassLoader());}// ... 其他策略}
}
在 getResource 方法中,根据资源位置的不同前缀,采用不同的资源加载策略。比如,对于以 classpath: 开头的资源位置,它会使用 ClassPathContextResource 策略进行加载。
ClassPathContextResource 是 ClassPathResource 的子类,它实现了从类路径中加载资源的具体策略:
public class ClassPathResource extends AbstractFileResolvingResource {// 获取资源的具体实现...
}
Spring 还提供了其他一些 ResourceLoader 的实现,如:
FileSystemResourceLoader: 从文件系统中加载资源ServletContextResourceLoader: 从 Servlet 上下文中加载资源...
通过组合不同的资源加载策略,Spring 可以非常灵活地从各种不同的位置加载资源。
总的来说,ResourceLoader 接口充当了策略模式中的抽象策略角色,而具体的资源加载策略则由其不同的实现类(如 ClassPathResource、FileSystemResource 等)扮演了具体策略的角色。当需要加载资源时,Spring 会根据资源位置信息选择合适的策略实现,从而完成资源的加载过程。