🌈 博客个人主页:Chris在Coding
🎥 本文所属专栏:[高并发内存池]
❤️ 前置学习专栏:[Linux学习]
⏰ 我们仍在旅途

目录
8 使用定长内存池脱离new
9. 释放对象时不传大小
10.性能优化
10.1 与malloc在多线程下对比测试
10.2 性能瓶颈分析
10.3 基于基数树的性能优化
8 使用定长内存池脱离new
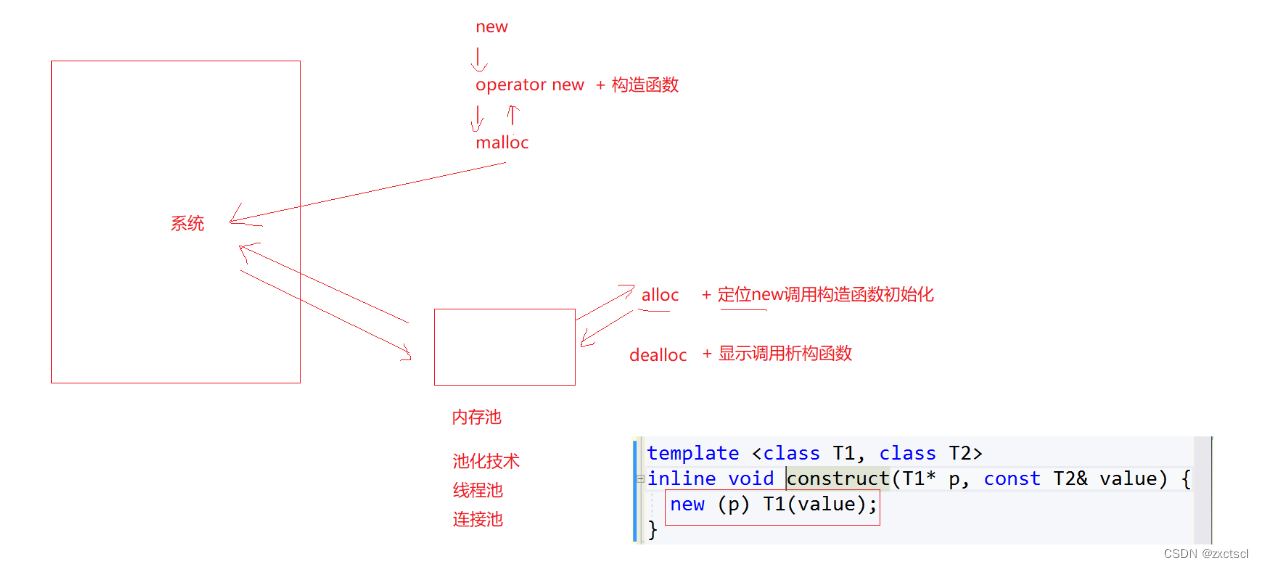
在我们这个项目中,我们是为了在高并发场景下替代 malloc 函数的使用,决定使用 tcmalloc,但由于 tcmalloc 内部不能调用 malloc 函数,因此需要避免直接使用 new 来申请内存。而我们之前使用的new 实际上是封装了 malloc 函数。 为了彻底摆脱对 malloc 函数的依赖,我们这里就要利用之前实现的定长内存池。
class PageCache
{
public:// ...
private:// ...ObjMemoryPool<Span, 18000> _Spanpool;
};这个定长内存池主要用于管理 Span 结构的对象申请和释放,而 Span 对象在系统中主要是在 层创建的。 因此,在 PageCache 类中定义了一个_Spanpool,用于 Span 对象的申请和释放。这样一来,系统在申请 Span 对象的空间时,可以直接从_Spanpool 中获取,而不需要通过调用 malloc 函数。这样做可以彻底避免对 malloc 函数的调用,使得系统更加适合在高并发场景下运行,并且能够充分利用 tcmalloc 提供的内存管理功能。这里为了应对大量的内存申请释放我们将每一次申请的Span个数设置为了18000,具体数字可以自行斟酌。
Span* span = _Spanpool.New();
_Spanpool.Delete(span);现在我们就可以将之前的new,delete分别改写成我们新的接口
之后我们也记得将申请ThreadCache的部分也替换,但是要注意的是此处从该定长内存池中申请内存时需要加锁,防止多个线程同时申请自己的ThreadCache对象而导致线程安全问题。
static void* ConcurrentAlloc(size_t size)
{// ...if (pTLSThreadCache == nullptr){static ObjMemoryPool<ThreadCache, 50> TdPool;static std::mutex tdMtx;tdMtx.lock();pTLSThreadCache = TdPool.New();tdMtx.unlock();}// ...
}9. 释放对象时不传大小
实际上在使用free去释放内存时,我们是不会去传入申请的内存块的大小,所以这里实现的接口也应该能做到不传入对象的大小也能正常释放内存
为了实现在释放对象时不再需要显式传入对象的大小,我们可以通过在 Span 结构中增加一个 _size 成员来实现。每个 Span 管理的内存块被切分成多个对象,而这些对象的大小可能不同。因此,为每个 Span 增加一个_size 成员,用于表示这个 Span 管理的内存块被切分的对象的大小。这样一来,在释放对象时,系统可以通过对象的地址找到其对应的 Span,并从中获取对象的大小,而无需显式传入对象的大小。
struct Span
{PAGEID _pageId = 0;size_t _n = 0;Span* _next = nullptr;Span* _prv = nullptr;size_t _used = 0;void* _freeList = nullptr;bool _isused = false;size_t _size = 0;
};而所有的Span都是从PageCache中拿出来的,因此每当我们调用NewSpan获取到一个k页的Span时,就应该将这个Span的_size确定下来。
Span* CentralCache::GetOneSpan(SpanList& list, size_t align_size)
{// ...PageCache::GetInstance()._pagemtx.lock();Span* span = PageCache::GetInstance().NewSpan(SizeTable::PageSizeLimit(align_size));span->_size = align_size;span->_isused = true;PageCache::GetInstance()._pagemtx.unlock();// ...
}这里我们还要记得给申请大于256KB内存时获得的kspan写上size大小
static void* ConcurrentAlloc(size_t size)
{if (size > MAXSIZE){// ...PageCache::GetInstance()._pagemtx.lock();Span* span = PageCache::GetInstance().NewSpan(kpage);span->_size = size;PageCache::GetInstance()._pagemtx.unlock();// ...}// ...
}现在当我们释放对象时,就不用再传入大小了。
static void ConcurrentFree(void* ptr)
{Span* span = PageCache::GetInstance().MapObjToSpan(ptr);size_t size = span->_size;if (size > MAXSIZE){Span* span = PageCache::GetInstance().MapObjToSpan(ptr);//超过256KB的内存,ThreadCache中无法维护,都是以Span类型储存并维护PageCache::GetInstance()._pagemtx.lock();PageCache::GetInstance().ReleaseSpanToPageCache(span);PageCache::GetInstance()._pagemtx.unlock();}else{assert(pTLSThreadCache);pTLSThreadCache->deallocate(ptr, size);}
}10.性能优化
10.1 与malloc在多线程下对比测试
#include"ConcurrentAlloc.h"// ntimes 一轮申请和释放内存的次数
// rounds 轮次
void BenchmarkMalloc(size_t ntimes, size_t nworks, size_t rounds)
{std::vector<std::thread> vthread(nworks);std::atomic<size_t> malloc_costtime = 0;std::atomic<size_t> free_costtime = 0;for (size_t k = 0; k < nworks; ++k){vthread[k] = std::thread([&, k]() {std::vector<void*> v;v.reserve(ntimes);for (size_t j = 0; j < rounds; ++j){size_t begin1 = clock();for (size_t i = 0; i < ntimes; i++){//v.push_back(malloc(16));v.push_back(malloc((16 + i) % 8192 + 1));}size_t end1 = clock();size_t begin2 = clock();for (size_t i = 0; i < ntimes; i++){free(v[i]);}size_t end2 = clock();v.clear();malloc_costtime += (end1 - begin1);free_costtime += (end2 - begin2);}});}for (auto& t : vthread){t.join();}printf("%u个线程并发执行%u轮次,每轮次malloc %u次: 花费:%u ms\n",nworks, rounds, ntimes, (size_t)malloc_costtime);printf("%u个线程并发执行%u轮次,每轮次free %u次: 花费:%u ms\n",nworks, rounds, ntimes, (size_t)free_costtime);printf("%u个线程并发malloc&free %u次,总计花费:%u ms\n",nworks, nworks * rounds * ntimes, (size_t)malloc_costtime + free_costtime);
}// 单轮次申请释放次数 线程数 轮次
void BenchmarkConcurrentMalloc(size_t ntimes, size_t nworks, size_t rounds)
{std::vector<std::thread> vthread(nworks);std::atomic<size_t> malloc_costtime = 0;std::atomic<size_t> free_costtime = 0;for (size_t k = 0; k < nworks; ++k){vthread[k] = std::thread([&]() {std::vector<void*> v;v.reserve(ntimes);for (size_t j = 0; j < rounds; ++j){size_t begin1 = clock();for (size_t i = 0; i < ntimes; i++){//v.push_back(ConcurrentAlloc(16));v.push_back(ConcurrentAlloc((16 + i) % 8192 + 1));}size_t end1 = clock();size_t begin2 = clock();for (size_t i = 0; i < ntimes; i++){ConcurrentFree(v[i]);}size_t end2 = clock();v.clear();malloc_costtime += (end1 - begin1);free_costtime += (end2 - begin2);}});}for (auto& t : vthread){t.join();}printf("%u个线程并发执行%u轮次,每轮次concurrent alloc %u次: 花费:%u ms\n",nworks, rounds, ntimes, (size_t)malloc_costtime);printf("%u个线程并发执行%u轮次,每轮次concurrent dealloc %u次: 花费:%u ms\n",nworks, rounds, ntimes, (size_t)free_costtime);printf("%u个线程并发concurrent alloc&dealloc %u次,总计花费:%u ms\n",nworks, nworks * rounds * ntimes, (size_t)malloc_costtime + free_costtime);
}int main()
{size_t n = 10000;cout << "==========================================================" << endl;BenchmarkConcurrentMalloc(n, 4, 10);cout << endl << endl;BenchmarkMalloc(n, 4, 10);cout << "==========================================================" << endl;return 0;
}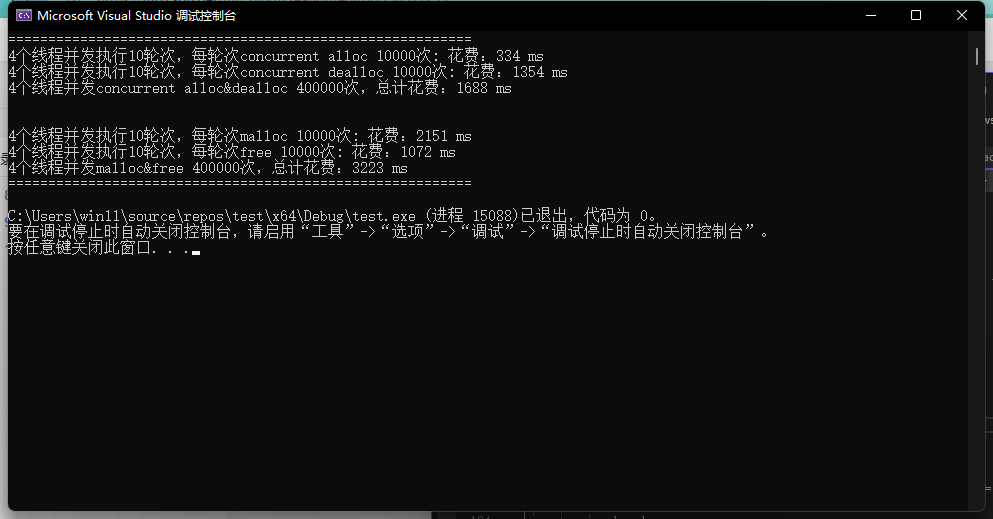
经过测试我们会发现我们现在实现的TcMalloc跟malloc在多线程情况下相比仍显得捉襟见肘, 这里我们进一步分析再次优化我们得代码
10.2 性能瓶颈分析
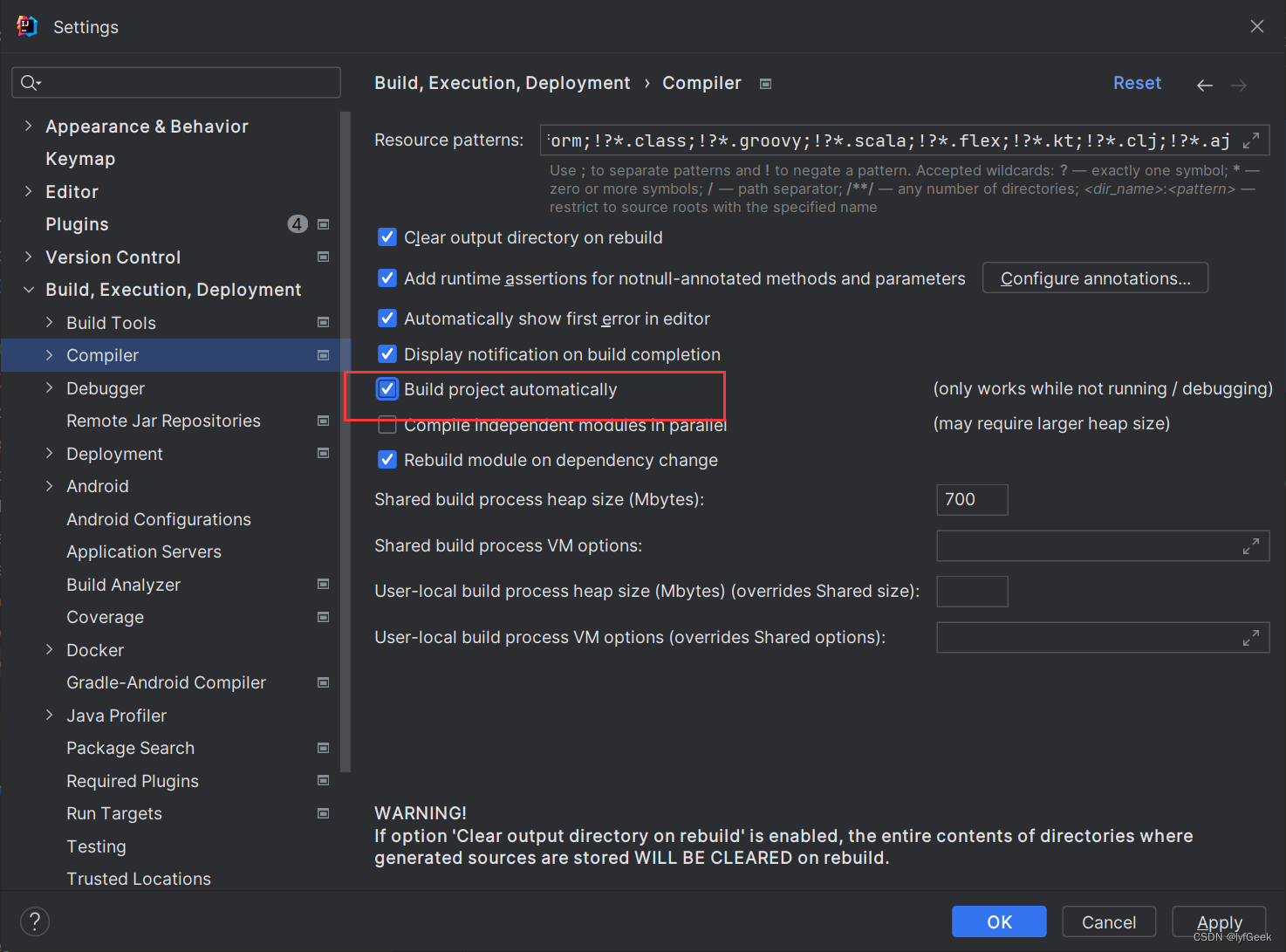
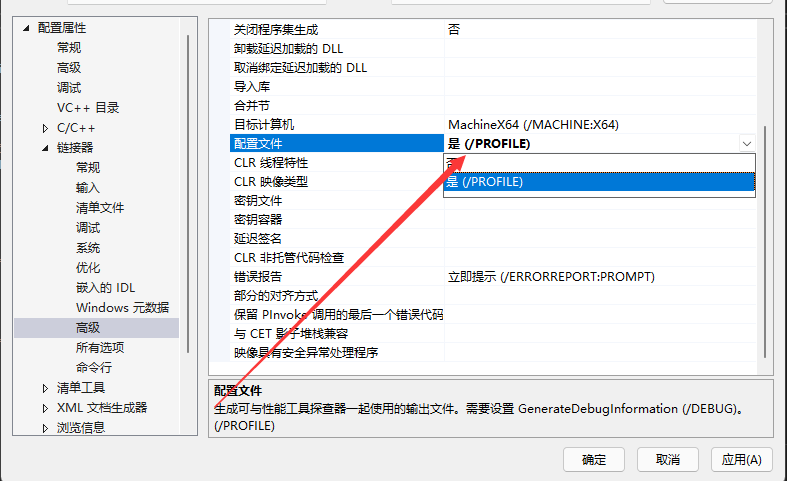
这里我使用的是VS2022自带的性能探查器,这里我们先进入项目属性页面,把链接器下面高级这一栏中的配置文件改成/PROFILE
再进入调试栏打开性能探查器

等待系统分析结束后,我们可以得到这样的分析结果
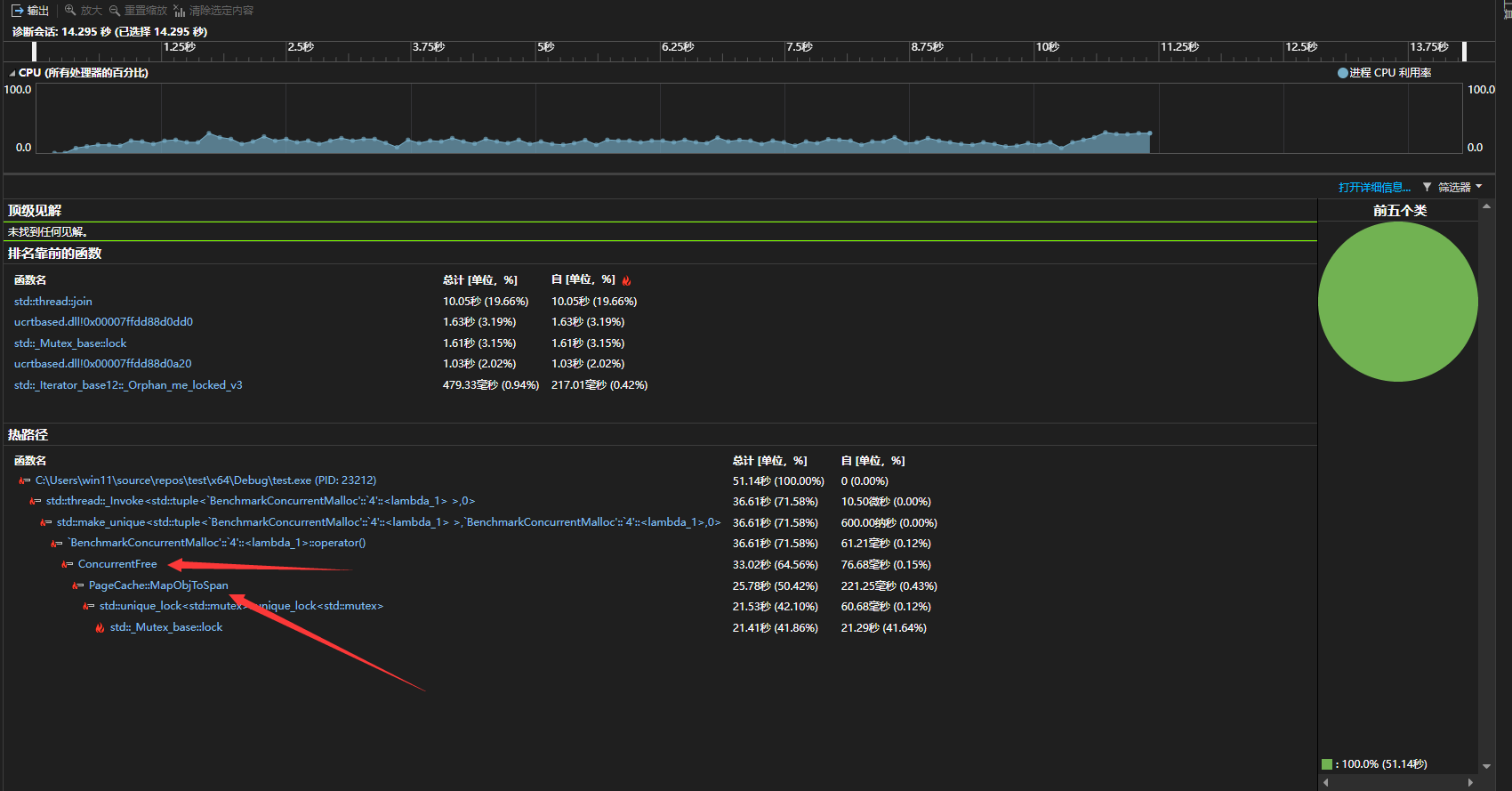
这里我们不难发现,内存块的释放其实占用了大部分的运行时间,而其中花费时间最多的就是MapObjToSpan
通过分析我们不难得出,之所以调用MapObjToSpan会花费如此多的时间,其主要原因是因为在锁的竞争上,因此本项目的性能优化点就在于解决映射时,锁的竞争问题
10.3 基于基数树的性能优化
基数树(Radix Trie)是一种多叉树,也称为基数特里树或压缩前缀树。相比于普通的Trie(前缀树),基数树具有更高的空间利用率。在基数树中,具有唯一子节点的每个节点都与其父节点合并,这样可以大大减少内部节点的数量,提高了空间利用率。
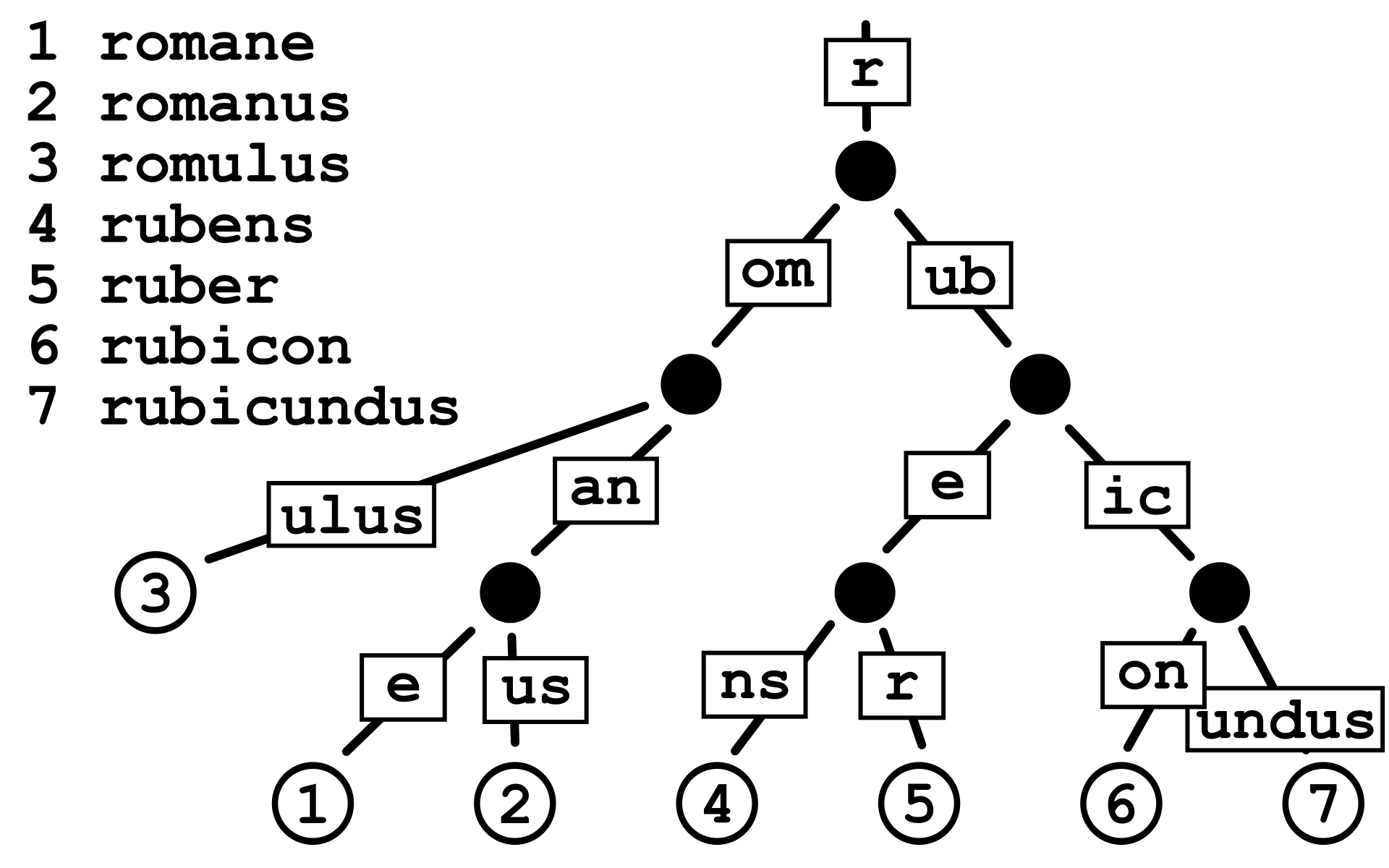
为什么使用基数树不需要加锁?
-
对于使用 C++ 中的
map或unordered_map进行映射关系的读取,需要加锁的原因在于它们的底层数据结构(红黑树和哈希表)在插入数据时可能会引起结构变化,为了避免数据不一致性问题,需要在读取操作时加锁。 -
相比之下,基数树的特性不同。基数树在空间开辟后不会发生结构变化,因此不需要在读取操作时加锁。此外,基数树的读取和建立映射操作不会同时对同一个页进行操作,因为读取映射时是针对
_useCount不为 0 的页,而建立映射时是针对_useCount等于 0 的页,所以不存在同时对同一页面进行读取和建立映射操作的情况。
二层基数树
在32位的环境下,一页的大小为8K为例,此时存储页号最多需要19个比特位。而二层基数树实际上就是把这19个比特位分为两次进行映射。
比如用前5个比特位在基数树的第一层进行映射,映射后得到对应的第二层,然后用剩下的比特位在基数树的第二层进行映射,映射后最终得到该页号对应的span指针。
在二层基数树中,第一层的数组占用的空间为 X 4 =
字节(即 128 字节),而第二层的数组最多占用的空间为
X
X 4 =
字节(即 2 MB)。这意味整个二层基数树加起来对系统的花销并不大。
二层基数树只需要在一开始分配第一层的数组空间,当需要对某个页面号进行映射时,再分配相应的第二层数组空间即可。这种延迟分配的策略可以节省内存,并在实际需要时才分配所需的内存空间,提高了内存的利用率。
template<int bits>
class PageMap_Two
{
private:static const int _rootbits = 5;static const int _leafbits = bits - _rootbits;static const int _rootlen = 1 << _rootbits;static const int _leaflen = 1 << _leafbits;struct Leaf{void* _points[_leaflen];};Leaf* _root[_rootlen];
public:PageMap_Two(){//先把root层清理干净memset(_root, 0, sizeof _root);_PreMemoryAlloc();}inline void _Ensure(size_t start, size_t n){for (uintptr_t key = start; key <= start + n - 1;){const uintptr_t i1 = key >> _leafbits;if (_root[i1] == NULL) //第一层i1下标指向的空间未开辟{//开辟对应空间static ObjMemoryPool<Leaf, 100>leafPool;Leaf* leaf = (Leaf*)leafPool.New();memset(leaf, 0, sizeof(*leaf));_root[i1] = leaf;}key = ((key >> _leafbits) + 1) << _leafbits; //继续后续检查}}void _PreMemoryAlloc(){_Ensure(0, 1 << bits);}void* get(uintptr_t k) const{const uintptr_t i1 = k >> _leafbits;const uintptr_t i2 = k & (_leaflen - 1);if ((k >> bits) > 0 || _root[i1] == nullptr) {return nullptr;}return _root[i1]->_points[i2];}void set(uintptr_t k, void* v) {const uintptr_t i1 = k >> _leafbits;const uintptr_t i2 = k & (_leaflen - 1);assert(i1 < _rootlen);_root[i1]->_points[i2] = v;}
};- 类模板 PageMap_Two 接受一个整数模板参数 bits,用于确定页面编号的位数。
- 类内部定义了一个名为 Leaf 的结构体,用于表示基数树的叶子节点,每个叶子节点包含一个指针数组 _points,用于存储页面的指针。
- 类内部使用 _root 数组来表示基数树的根节点数组,数组长度为 _rootlen,每个元素存储一个指向叶子节点的指针。
- 构造函数 PageMap_Two() 初始化 _root 数组,并调用 _PreMemoryAlloc() 函数预先分配内存。
- _PreMemoryAlloc() 函数用于预先分配内存空间,确保根据页面编号的位数 bits 来确定需要的节点数量,并对应创建相应的叶子节点。
- get(uintptr_t k) 函数用于根据页面编号 k 获取对应页面的指针。它首先计算页面编号所在的根节点索引 i1 和叶子节点索引 i2,然后根据索引访问对应的叶子节点 _root[i1] 并返回指针数组 _points[i2] 中的值。
- set(uintptr_t k, void* v) 函数用于设置页面编号为 k 的页面指针为 v。它首先计算页面编号所在的根节点索引 i1 和叶子节点索引 i2,然后直接将指针 v 赋值给 _root[i1] 的指针数组 _points[i2]。
三层基数树
在64位系统下,页面编号需要更多的位数来表示,因此使用三层基数树可以更有效地管理页面的映射关系。下面是为什么需要在64位系统下使用三层基数树的几个原因:
-
更大的地址空间: 在64位系统下,地址空间更大,通常为
,因此需要更多的位来表示页面编号。单层基数树可能不足以覆盖整个地址空间,因此需要更多的层级来管理更多的页面编号。
-
减少内存消耗: 在64位系统下,单层基数树需要分配更大的数组来存储映射关系,这可能会导致较大的内存消耗。使用多层基数树可以将地址空间分成更小的部分,每一层的数组大小相对较小,从而减少了每层的内存消耗。
-
更快的查找速度: 在多层基数树中,每一层的数组相对较小,因此可以更快地进行查找操作。单层基数树可能会出现较深的树结构,导致查找速度较慢,而多层基数树可以将查找路径分解成多个较短的路径,提高了查找效率。
template <int bits>
class PageMap_Three
{
private:static const int _interiorbits = (bits + 2) / 3; //第一、二层对应页号的比特位个数static const int _interiorlen = 1 << _interiorbits; //第一、二层存储元素的个数static const int _leafbits = bits - 2 * _interiorbits; //第三层对应页号的比特位个数static const int _leaflen = 1 << _leafbits; //第三层存储元素的个数struct Node{Node* nodes[_interiorlen];};struct Leaf{void* points[_leaflen];};Node* NewNode(){static ObjMemoryPool<Node, 1000> nodePool;Node* result = nodePool.New();if (result != NULL){memset(result, 0, sizeof(*result));}return result;}Node* _root;
public:PageMap_Three(){_root = NewNode();}void* get(uintptr_t k) const{const uintptr_t i1 = k >> (_leafbits + _interiorbits); //第一层对应的下标const uintptr_t i2 = (k >> _leafbits) & (_interiorlen - 1); //第二层对应的下标const uintptr_t i3 = k & (_leaflen - 1); //第三层对应的下标//页号超出范围,或映射该页号的空间未开辟if ((k >> bits) > 0 || _root->nodes[i1] == NULL || _root->nodes[i1]->nodes[i2] == NULL){return NULL;}return reinterpret_cast<Leaf*>(_root->nodes[i1]->nodes[i2])->points[i3]; //返回该页号对应span的指针}void set(uintptr_t k, void* v){assert(k >> bits == 0);const uintptr_t i1 = k >> (_leafbits + _interiorbits); //第一层对应的下标const uintptr_t i2 = (k >> _leafbits) & (_interiorlen - 1); //第二层对应的下标const uintptr_t i3 = k & (_leaflen - 1); //第三层对应的下标Ensure(k, 1); //确保映射第k页页号的空间是开辟好了的reinterpret_cast<Leaf*>(_root->nodes[i1]->nodes[i2])->points[i3] = v; //建立该页号与对应span的映射}//确保映射[start,start+n-1]页号的空间是开辟好了的void Ensure(uintptr_t start, size_t n){for (uintptr_t key = start; key <= start + n - 1;){const uintptr_t i1 = key >> (_leafbits + _interiorbits); //第一层对应的下标const uintptr_t i2 = (key >> _leafbits) & (_interiorlen - 1); //第二层对应的下标if (_root->nodes[i1] == NULL) //第一层i1下标指向的空间未开辟{//开辟对应空间Node* n = NewNode();_root->nodes[i1] = n;}if (_root->nodes[i1]->nodes[i2] == NULL) //第二层i2下标指向的空间未开辟{//开辟对应空间static ObjMemoryPool<Leaf, 100> leafPool;Leaf* leaf = leafPool.New();;memset(leaf, 0, sizeof(*leaf));_root->nodes[i1]->nodes[i2] = reinterpret_cast<Node*>(leaf);}key = ((key >> _leafbits) + 1) << _leafbits; //继续后续检查}}
};代码更改
class PageCache
{
public:static PageCache& GetInstance(){return _SingleInstance;}std::mutex _pagemtx;Span* NewSpan(size_t k);Span* MapObjToSpan(void* obj);void ReleaseSpanToPageCache(Span* span);
private:PageCache(){}PageCache(const PageCache&) = delete;static PageCache _SingleInstance;SpanList _Spanlists[NPAGES];/*std::unordered_map<PAGEID,Span*> _IdToSpan;*/
#ifdef _WIN64PageMap_Three <64 - PAGESHIFT> _IdToSpan;
#elif _WIN32PageMap_Two <32 - PAGESHIFT> _IdToSpan;
#endifObjMemoryPool<Span, 18000> _Spanpool;
};同时我们的MapObjSpan也不需要再加锁访问
Span* PageCache::MapObjToSpan(void* obj)
{PAGEID id = ((PAGEID)obj >> PAGESHIFT);Span* ret = (Span*)_IdToSpan.get(id);if (ret != nullptr){return ret;}else{assert(false);return nullptr;}
}此时当我们需要建立页号与span的映射时,就调用基数树当中的set函数。
_IdToSpan.set(span->_pageId, span);而当我们需要读取某一页号对应的span时,就调用基数树当中的get函数。
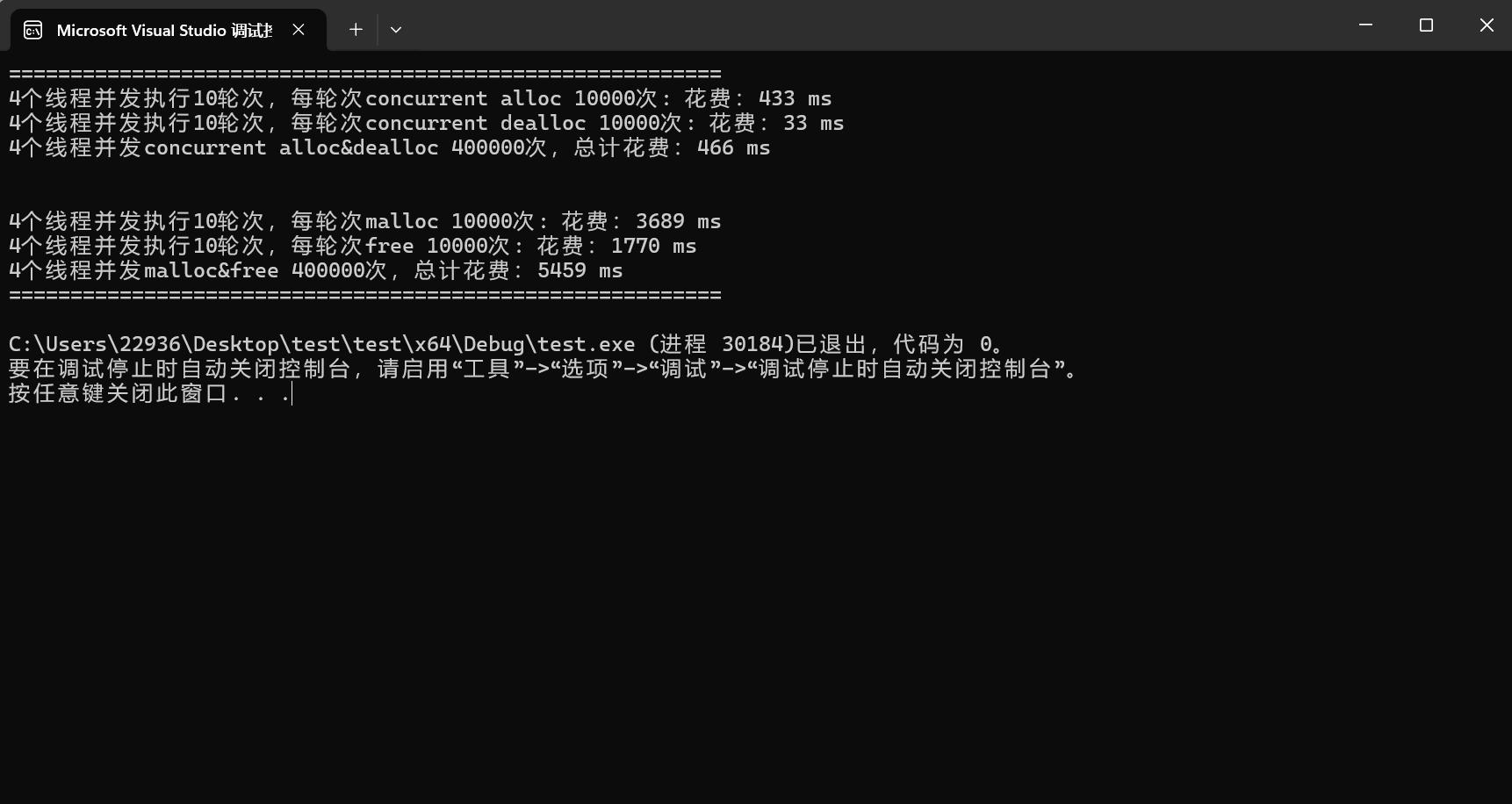
Span* ret = (Span*)_IdToSpan.get(id);更改后再次运行测试程序,我们可以明显看到优化效果
![]()