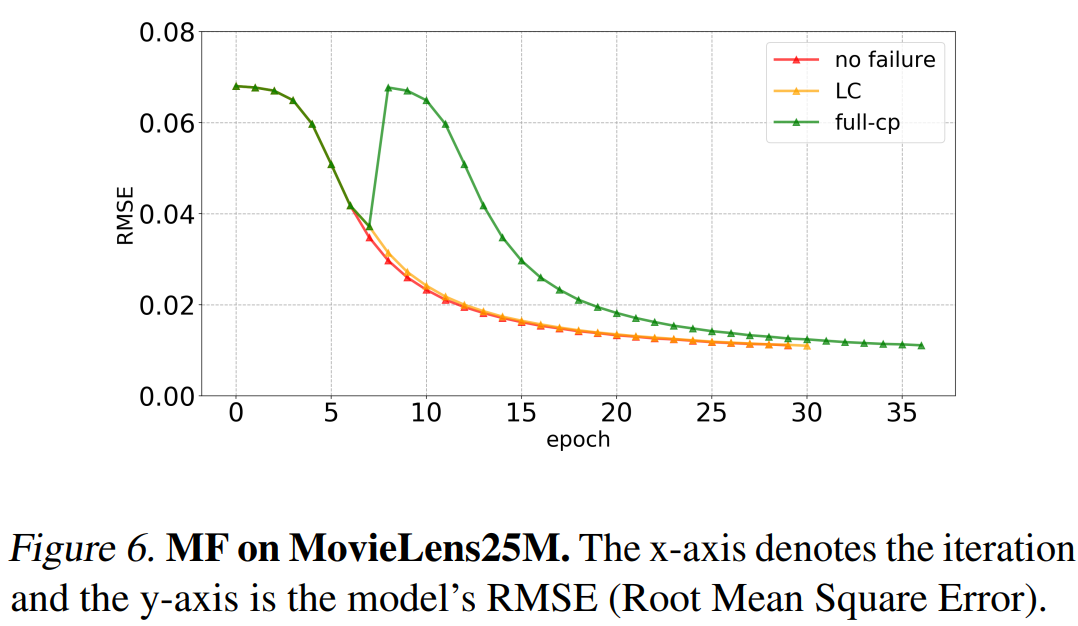
记录两次独立解决问题的过程:
目前来看,问题分为几种:
抄代码的时候抄错了,比如dim=1写成dim=0这种
逻辑错误,如果两份代码没什么差别的话,那么肯定是逻辑错误。
下面的两个问题都是逻辑错误,因为语法错误其实是会报错的,所以第一时间我们应该想的是算法问题,和ICPC一样。
问题一:thresh一直不变。
先检查两份代码,核心代码直接copy过来,做排除法。结果发现就算没改原来的代码,还是不行。
先检查中间变量维度,没问题后检查变量。两种方法:print法,tensorboard法,看分布用tensorboard,看大小可以直接print,print配合if使用,比如当值大于0.01再print,这样能避免太多数据混乱。
thresh作为nn.Parameter不变——>输出梯度,发现梯度是有的,而且设置>0.001输出也是有梯度的——>再继续找跟梯度有关的操作,函数etc.——>optimizer
最后顺着发现是optimizer的放的位置有问题。
问题二:公式推导的equivalent,实验并没有达到0
理论和实践对不上——>一方出了问题——>确定是实验有bug
把问题简化到最简——>多层L1不为0,先单独拎出来第一层来分析L1,对一个数据进行分析,不要有batch_size这一维
第一层要对输入输出分析。
先看input,求input L1,发现L1 = 0 ——> 证明为同一个输入——>排除输入的问题
那么一定是STB-IF layer这一层的问题,那么再一步步排查——>最后发现是reset放的位置有问题导致了第一个数据没有被reset,mem = 0 而不是 0.5 * thresh
对于理论和实验没对上的情况,一定要找到原因,一定不能任其不管,“不行也要给出不行的理由”。
你如果假装看不见那0.2的L1 distance,那么你只是在自欺欺人。如果对待什么事情都是这种态度,不如不干。自欺欺人做出来的成果自己也没有成就感。
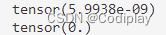
debug 用到的代码:
starttime = time.strftime("%Y-%m-%d_%H:%M:%S")
writer = SummaryWriter(log_dir='logs/'+ starttime[:16], comment=starttime[:16])
ann_outs, snn_outs = [], []
ann_inputs, snn_inputs = [], []
def ann_layer_hook(module, input, output):global ann_outsprint("==ann===")print(input[0].shape)print(output.shape)ann_outs.append(output.cpu())ann_inputs.append(input[0].cpu())writer.add_histogram("ann_1_layer", output.cpu())writer.add_histogram("ann_1_layer_input", input[0].cpu())# exit()
def snn_layer_hook(module, input, output):global snn_outsprint("==snn===")print(input[0].shape)print(output.shape)snn_outs.append(output.sum(0).cpu())snn_inputs.append(input[0].sum(0).cpu())writer.add_histogram("snn_1_layer", output.cpu())writer.add_histogram("snn_1_layer_input", input[0].sum(0).cpu())L1_layer = []
for index, item in enumerate(ann_outs):ann = ann_outs[index]snn = snn_outs[index]# writer.add_histogram("ann", ann)# writer.add_histogram("snn", snn)L1 = torch.sum(torch.abs(ann-snn)) / ann.numel()print(L1)input_loss = torch.sum(torch.abs(ann_inputs[index].squeeze(0)-snn_inputs[index])) / ann.numel()print(input_loss)
这就是差距:
请坚持你认为正确的事情。
tensor(0.1597)
tensor(0.1400)
tensor(0.0989)
tensor(0.2375)
tensor(0.2081)
tensor(1.2237e-08)
tensor(1.9061e-09)
tensor(1.8294e-10)
tensor(3.7203e-08)
tensor(5.8208e-11)