环境:
鲲鹏920:192核心
内存:756G
python:3.9
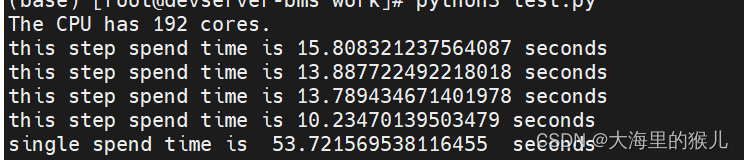
python单进程的耗时
在做单纯的cpu计算的场景,使用单进程核多进程的耗时做如下测试:
单进程情况下cpu的占用了如下,占用一半的核心数:

每一步和总耗时如下:
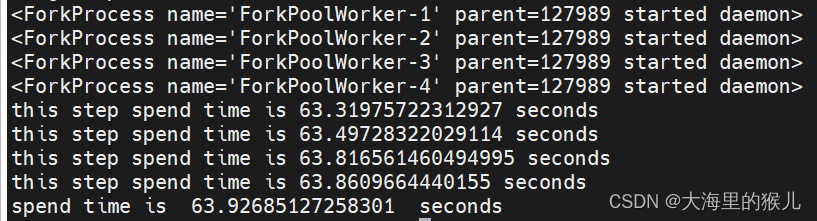
多进程
cpu占用如下,每个进程基本占用48个左右核心数;

多进程的耗时如下:
每一个进程的耗时为63s左右,总的耗时比单进程还多,如果绑定48核心到每个进程,耗时更高。这是为何?
是否可以得出结论,在cpu计算密集的场景,单进程(每个任务都是独立的、排除IO、竞争关系)的效率会比多进程会高呢?
注:同样的代码在x86服务器上测试过,结论依旧是单进程耗时比多进程会少,这是为什么?
样例代码
from sklearn.datasets import load_wine
from sklearn.preprocessing import MinMaxScaler, Normalizer, StandardScaler, RobustScaler
from sklearn.neural_network import MLPClassifier
from sklearn.model_selection import train_test_split
import time
from multiprocessing import Process, Pool, current_process
import multiprocessing
import numpy as np
import os
import psutilimport oscore_count = os.cpu_count()
print(f"The CPU has {core_count} cores.")cpu_cores = [index for index in range(0, core_count)]def task1(data):start = time.time()X = np.random.rand(178, 13)y = np.random.randint(low=0, high=3, size=(178))X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=60)mm_scaler = MinMaxScaler()X_train = mm_scaler.fit_transform(X_train)X_test = mm_scaler.fit_transform(X_test)mlp = MLPClassifier(solver='lbfgs', hidden_layer_sizes=[500, 500], max_iter=300, random_state=60)mlp.fit(X_train, y_train)# print("***" * 10, "current data value:{}".format(data))# print("******************************************current processid:{} end id is {}".format(multiprocessing.current_process().name, data))print("this step spend time is {} seconds".format(time.time() - start))# time.sleep(5)def task(data):process = current_process()print(process)pid = os.getpid()index = process._identity[0]cores = cpu_cores[(index-1) * 48 : index * 48]# print("process:{}, pid:{}, index:{}, core:{}".format(process, pid, index, cores))p = psutil.Process(pid) # 通过进程 ID 获取进程对象# p.cpu_affinity(cores) # 绑定核心start = time.time()X = np.random.rand(178, 13)y = np.random.randint(low=0, high=3, size=(178))X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=60)mm_scaler = MinMaxScaler()X_train = mm_scaler.fit_transform(X_train)X_test = mm_scaler.fit_transform(X_test)mlp = MLPClassifier(solver='lbfgs', hidden_layer_sizes=[500, 500], max_iter=300, random_state=60)mlp.fit(X_train, y_train)print("this step spend time is {} seconds".format(time.time() - start))def main():data = [i for i in range(4)]start = time.time()for item in data:task1(item)print("single spend time is ", time.time() - start, " seconds")start = time.time()with Pool(4) as pool:pool.map_async(task, data)pool.close()pool.join()print("spend time is ", time.time() - start, " seconds")if __name__ == '__main__':main()