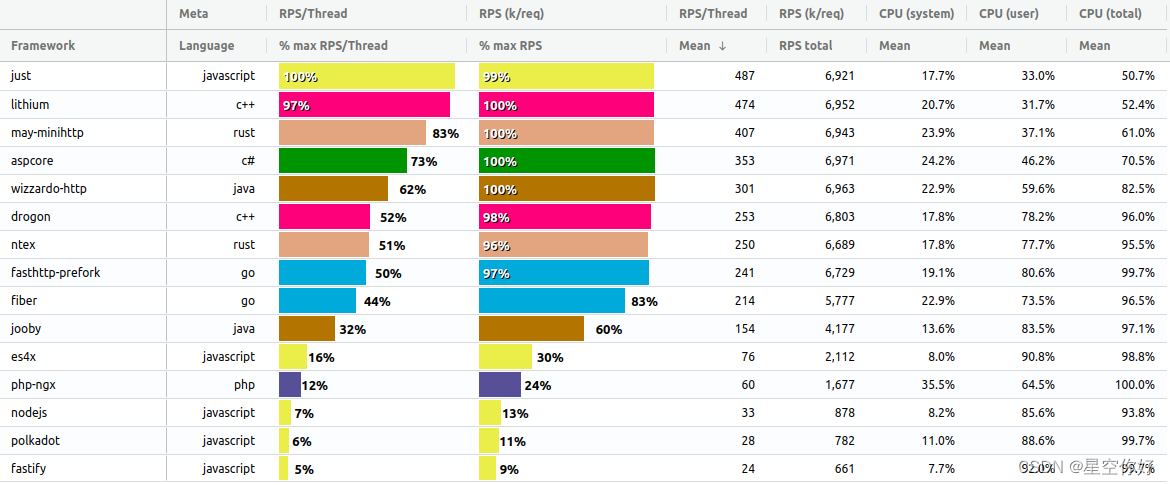
Apache Spark和Apache HBase分别是大数据处理和分布式NoSQL数据库领域的两个重要工具。在本文中,将深入探讨如何在Spark中集成HBase,并演示如何通过Spark访问和操作HBase中的数据。将提供丰富的示例代码,以便更好地理解这一集成过程。
Spark与HBase的基本概念
在开始集成之前,首先了解一下Spark和HBase的基本概念。
-
Apache Spark:Spark是一个快速、通用的分布式计算引擎,具有内存计算能力。它提供了高级API,用于大规模数据处理、机器学习、图形处理等任务。Spark的核心概念包括弹性分布式数据集(RDD)、DataFrame和Dataset等。
-
Apache HBase:HBase是一个分布式、高可伸缩性、列式存储的NoSQL数据库。它设计用于存储大规模数据,并提供快速的随机读/写访问能力。HBase的数据模型是基于行的,每行都有唯一的行键(Row Key)。
集成Spark与HBase
要在Spark中集成HBase,首先需要添加HBase的依赖库,以便在Spark应用程序中使用HBase的API。
以下是一个示例代码片段,演示了如何在Spark中进行集成:
from pyspark.sql import SparkSession
from pyspark.sql import DataFrame# 创建Spark会话
spark = SparkSession.builder.appName("SparkHBaseIntegration").getOrCreate()# 添加HBase依赖库
spark.sparkContext.addPyFile("/path/to/hbase-site.xml")
在上述示例中,首先创建了一个Spark会话,然后通过addPyFile方法添加了HBase的配置文件hbase-site.xml。这个配置文件包含了与HBase集群的连接信息。
使用HBase的API
一旦完成集成,可以在Spark应用程序中使用HBase的API来访问和操作HBase中的数据。
以下是一些示例代码,演示了如何使用HBase的API:
1. 读取数据
import happybase# 连接到HBase
connection = happybase.Connection(host='localhost', port=9090)# 打开表
table = connection.table('mytable')# 读取数据
data = table.row(b'row_key')
print(data)
在这个示例中,首先使用happybase库建立了与HBase的连接,然后打开了名为mytable的表,并通过行键(row key)来读取数据。
2. 写入数据
# 写入数据
table.put(b'new_row_key', {b'cf:column1': b'value1', b'cf:column2': b'value2'})
在这个示例中,使用put方法向HBase表中写入新数据。
3. 扫描数据
# 扫描数据
for key, data in table.scan():print(key, data)
使用scan方法,可以扫描整个HBase表并获取数据。
将HBase数据转换为Spark DataFrame
一种常见的需求是将HBase中的数据转换为Spark DataFrame,以便进一步的数据处理和分析。
以下是一个示例代码片段,演示了如何将HBase数据加载到Spark DataFrame 中:
# 从HBase加载数据到Spark DataFrame
def hbase_to_dataframe(row):# 在这里编写转换逻辑passhbase_data = table.scan()
spark_data = hbase_data.map(hbase_to_dataframe)
df = spark.createDataFrame(spark_data)
在这个示例中,首先定义了一个函数hbase_to_dataframe,用于将HBase中的数据转换为Spark DataFrame 的行。然后,使用scan方法获取HBase数据,将其映射到Spark数据,并最终创建了一个Spark DataFrame。
性能优化
在使用Spark与HBase集成时,性能优化是一个关键考虑因素。
以下是一些性能优化的建议:
-
批量写入:尽量减少对HBase的频繁写入操作,而是采用批量写入的方式来提高性能。
-
使用连接池:考虑使用连接池来管理与HBase的连接,以减少连接的开销。
-
数据转换:在将HBase数据转换为Spark DataFrame时,考虑使用并行化和分区操作来提高性能。
-
分区设计:在HBase中合理设计表的分区,以便查询和扫描操作可以高效执行。
示例代码:将HBase数据加载到Spark DataFrame
以下是一个示例代码片段,演示了如何将HBase中的数据加载到Spark DataFrame 中:
from pyspark.sql import SparkSession# 创建Spark会话
spark = SparkSession.builder.appName("SparkHBaseIntegration").getOrCreate()# 添加HBase依赖库
spark.sparkContext.addPyFile("/path/to/hbase-site.xml")# 导入happybase
import happybase# 连接到HBase
connection = happybase.Connection(host='localhost', port=9090)# 打开表
table = connection.table('mytable')# 从HBase加载数据到Spark DataFrame
def hbase_to_dataframe(row):# 在这里编写转换逻辑passhbase_data = table.scan()
spark_data = hbase_data.map(hbase_to_dataframe)
df = spark.createDataFrame(spark_data)# 显示Spark DataFrame
df.show()
在这个示例中,首先创建了一个Spark会话,并添加了HBase的依赖库。然后,使用happybase库连接到HBase,并打开了名为mytable的表。最后,将HBase数据加载到Spark DataFrame 中,并显示了DataFrame 的内容。
总结
通过集成Spark与HBase,可以充分利用这两个强大的工具来处理和分析大规模数据。本文深入介绍了如何集成Spark与HBase,并提供了示例代码,以帮助大家更好地理解这一过程。同时,也提供了性能优化的建议,以确保在集成过程中获得良好的性能表现。