要弄懂这个问题,需要先来看关于webpack打包的3个问题。
三个问题
第一个问题
项目中的json文件,如何使用webpack进行处理?
如果我们希望把json文件当做静态配置,例如有如下json文件
{"version": "1.0.0","name": "config"
}在其他模块中引用:
// index.js
import config from './config';console.log(config); // {version: '1.0.0', name: 'config'}要实现上面的效果,应该如何配置?
如果我们希望把json文件当做静态资源加载,例如
// index.js
import axios from 'axios';
import config from './config';axios(config)
.then(res => {console.log(res.data); // {version: '1.0.0', name: 'config'}
});这种效果又怎么实现?
第二个问题
我们知道webpack可以分包打包,而且html-webpack-plugin会帮助我们管理分包文件的加载顺序,通常打包出来的html中script会是这样的
<script src="static/js/275.ffbe1.chunk.js"></script>
<script src="static/js/main.d9933.chunk.js"></script>因为main中模块依赖275.ffbe1 chunk中的模块,因此先加载275.ffbe1.chunk.js。
那么如果我们加载chunk的顺序有问题(先加载main),会不会报错呢?如果不会报错,webpack是怎么保证这种容错的呢?
第三个问题
对于动态加载的模块,路径是动态生成的,比如
const Component = React.lazy(() => import(`~/page/${component}`));或者
const loadingImgSrc = require(`~/img/${skin}.loading.png`);动态的路径只有在执行时候才能确定,webpack在打包时候并不能知道具体路径,那么webpack是如何处理的呢?
概述
上面问题虽然在平时工作的大部分项目中不会遇到,但是对于我们深入理解webpack模块化原理、应对可能遇到的疑难杂症和特殊需求以及应付有些深度的面试都大有帮助。
阅读本文可以获知上面3个问题的答案,并了解:
- webpack模块的解析过程(如何处理不同类型模块,用户如何根据配置控制模块解析行为)。
- 模块打包的原理(对于正常打包、动态依赖的打包和分片打包,webpack运行时是如何工作的)。
- 模块路径解析规则。
模块解析
模块解析过程
模块解析,就是分析模块的导入(依赖)和导出的过程。模块解析在webpack打包过程中有非常重要的地位。
我们先来看下webpack打包过程,大致过程可以描述为:webpack从入口开始构建依赖图,然后把不同类型的模块交给对应的loader处理,处理完成后打包到一起。
这个过程的描述有些不清晰:webpack负责构建依赖图,那么实际项目中那么多种不同类型的模块,它们的依赖如何解析?loader负责处理不同类型的模块,处理时候也要解析依赖吗,到底是webpack解析依赖,还是loader解析依赖?loader它到底做了哪些事情?最终webpack是如何将不同模块打包到一起的呢?
其实,webpack本身可以支持几种常见的模块:https://webpack.docschina.org/concepts/modules/#supported-module-types
对于这些类型的模块,webpack会对其根据后缀匹配,然后进行默认方式的解析,不需要配置loader,例如JavaScript/auto,支持ESM、CommonJS、AMD,对于asset类型的模块会输出静态资源然后导出引用地址。
对于其他类型的模块,需要对应的loader处理。
loader主要做了两件事:
- 转译代码。
- 将模块化代码转为webpack可以识别的格式。例如对于css,@import等引用其他css的语法webpack并不能识别,
css-loader会将这些模块引用语法转换为require,这样就能够被webpack识别了。所以,最终负责依赖解析的还是webpack,loader只是将模块转为webpack能识别的模块。loader还有一种方式可以让webpack知道某个模块的依赖,就是使用this.resolve/this.getResolve。(https://webpack.docschina.org/contribute/writing-a-loader/#module-dependencies)
webpack打包过程可以图示如下
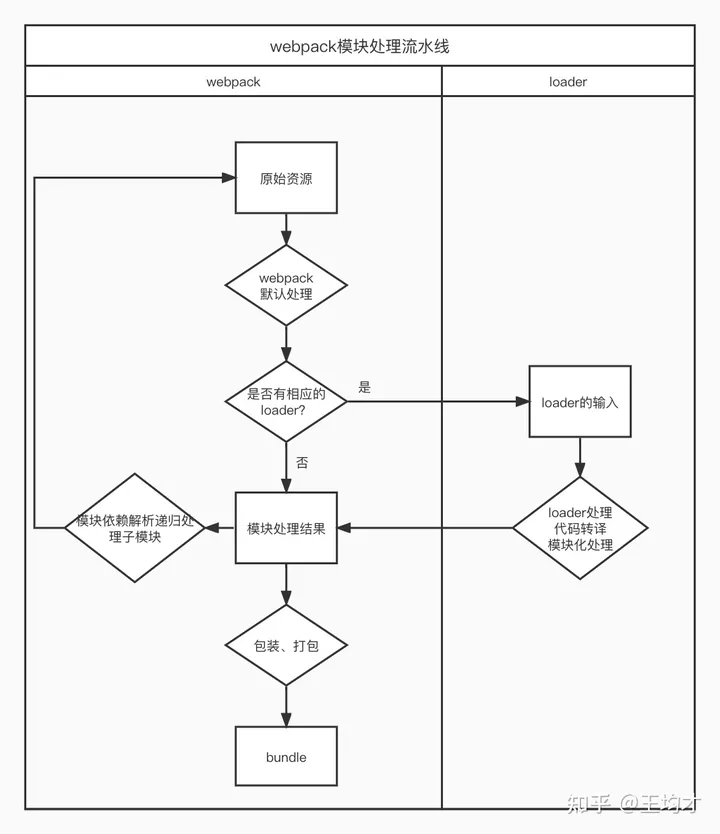
- webpack对原始资源做默认处理。
- 交给loader处理,将依赖的语句改成
require或者通过this.resolve解析依赖。也就是说loader得负责把模块转成webpack能够识别的模块化语法(包括导入和导出语法),这样webpack才能根据导入语句分析依赖,才能根据导出语句进行包装然后打包。 - loader处理完交给webpack,webpack解析依赖,然后递归处理依赖模块。
- 添加运行时代码,打包。
模块解析相关配置
1. Rule.type
webpack支持通过设置Rule.type控制模块的默认解析方式:https://webpack.docschina.org/configuration/module/#ruletype。
例如前言中提到的第一个问题,我们可以什么都不配置,webpack就会按照默认方式,把json解析成js对象。相当于
export default {"version": "1.0.0","name": "config"
};如果希望把json作为静态资源解析,则要配置Rule.type
// webpack.config.js
module.exports = {// other config...module: {rules: [{test: /.json$/,type: 'asset/resource'}]}
};如果模块类型(后缀)和配置的type不匹配,webpack会不进行默认处理,而是交给相应的loader处理。
2. module.noParse
顾名思义,用于模块没有依赖的场景,模块不会被webpack进行解析,直接被打包到bundle。
对于那些模块中确定没有其他依赖的js模块,可以不继续进行模块解析。例如大型的、已经打包好的、以global方式引入的第三方库,设置该配置可以避免模块解析工作从而提升构建性能。
module.exports = {//...module: {noParse: /jquery|lodash/,},
};3. Rule.exclude
该配置用于模块本身已经经过处理,不需要loader再次处理,可以直接让webpack处理。这个选项也可以用来缩小构建目标。
模块打包
依赖解析完成之后,代码也转译完成后,剩下的就是打包了。
普通模块打包
webpack解析好模块后,会将代码都包装成commonjs格式的模块,本质就是闭包。通过webpack运行时代码完成模块导出导入。
例如有这样的代码
// index.js
import lib from './lib';
console.log(lib);// lib.js
export default 'lib';webpack配置
// webpack.config.js
module.exports = {entry: './src/index.js',mode: 'development',
};在development模式下打包结果如下(经过简化)
(() => {"use strict";var __webpack_modules__ = ({"./src/index.js":((__unused_webpack_module, __webpack_exports__, __webpack_require__) => {__webpack_require__.r(__webpack_exports__);var _lib__WEBPACK_IMPORTED_MODULE_0__ = __webpack_require__("./src/lib.js");console.log(_lib__WEBPACK_IMPORTED_MODULE_0__["default"]);}),"./src/lib.js":((__unused_webpack_module, __webpack_exports__, __webpack_require__) => {__webpack_require__.r(__webpack_exports__);__webpack_require__.d(__webpack_exports__, {"default": () => (__WEBPACK_DEFAULT_EXPORT__)});const __WEBPACK_DEFAULT_EXPORT__ = ('lib'); })});var __webpack_module_cache__ = {};function __webpack_require__(moduleId) {var cachedModule = __webpack_module_cache__[moduleId];if (cachedModule !== undefined) {return cachedModule.exports;}var module = __webpack_module_cache__[moduleId] = {exports: {}};__webpack_modules__[moduleId](module, module.exports, __webpack_require__);return module.exports;}(() => {__webpack_require__.d = (exports, definition) => {for(var key in definition) {if(__webpack_require__.o(definition, key) && !__webpack_require__.o(exports, key)) {Object.defineProperty(exports, key, { enumerable: true, get: definition[key] });}}};})();(() => {__webpack_require__.o = (obj, prop) => (Object.prototype.hasOwnProperty.call(obj, prop))})();(() => {__webpack_require__.r = (exports) => {if(typeof Symbol !== 'undefined' && Symbol.toStringTag) {Object.defineProperty(exports, Symbol.toStringTag, { value: 'Module' });}Object.defineProperty(exports, '__esModule', { value: true });};})();var __webpack_exports__ = __webpack_require__("./src/index.js");
})();我们对上面打包结果进一步改造,提取关键代码
(() => {"use strict";var modules = ({"./src/index.js":((exports, require) => {var lib = require("./src/lib.js");console.log(lib["default"]);}),"./src/lib.js":((exports, require) => {exports.default = 'lib'; })});var modulesCache = {};function require(moduleId) {var cachedModule = modulesCache[moduleId];if (cachedModule !== undefined) {return cachedModule.exports;}var module = modulesCache[moduleId] = {exports: {}};modules[moduleId](module.exports, require);return module.exports;}require("./src/index.js");
})();可以发现webpack打包其实做了几件事:
- 实现了CommonJS规范的
require方法,导入的模块缓存起来,如果下次再导入直接返回结果。 - 每个模块引用语句都改成了
require引用。 - 模块被包装成闭包,按照CommonJS格式(
module.exports)导出。
关于模块化语法更多细节可以参考这个文章:https://segmentfault.com/a/1190000010349749
动态引入的模块打包
我们看这样的代码
// index.js
import('./lib').then(res => {console.log(res);}
);
// lib.js
export default 'lib';webpack配置
// webpack.config.js
module.exports = {entry: './src/index.js',mode: 'development',
};上面代码index模块动态引入lib模块,这种打包会生成两个chunk,切片之间通过webpack运行时异步加载。
打包生成main.js和src_lib_js.js,这里只给出提取关键代码并简化后的结果
// main.js
(() => {var modules = ({"./src/index.js":((exports, require) => {require.ensureChunk("src_lib_js").then(() => {return require("./src/lib.js");}).then(res => { console.log(res.default); });})});var modulesCache = {};function require(moduleId) {var cachedModule = modulesCache[moduleId];if (cachedModule !== undefined) {return cachedModule.exports;}var module = modulesCache[moduleId] = {exports: {}};modules[moduleId](module.exports, require);return module.exports;}var installedChunks = {"main": 0};require.ensureChunk = (chunkId) => {// 拼接urlfunction getScriptUrl(chunkId) {var scriptUrl;// web workerif (window.importScripts) scriptUrl = window.location + "";var document = window.document;if (!scriptUrl && document) {if (document.currentScript)// 以当前的script为基准加载chunkscriptUrl = document.currentScript.srcif (!scriptUrl) {var scripts = document.getElementsByTagName("script");if(scripts.length) scriptUrl = scripts[scripts.length - 1].src}}if (!scriptUrl) throw new Error("Automatic publicPath is not supported in this browser");// 去掉路由后面的内容(hash、query和多余的斜杠)scriptUrl = scriptUrl.replace(/#.*$/, "").replace(/?.*$/, "").replace(//[^/]+$/, "/");return scriptUrl + chunkId + '.js';}// 如果未安装过,则通过script标签下载js文件if (installedChunks[chunkId] === undefined) {return new Promise((resolve, reject) => {var script = document.createElement('script');script.src = getScriptUrl(chunkId);document.head.appendChild(script);script.onload = resolve;script.onerror = reject;});}return Promise.resolve();};var webpackJsonpCallback = (data) => {var [chunkId, moreModules] = data;for(moduleId in moreModules) {modules[moduleId] = moreModules[moduleId];}installedChunks[chunkId][0]();}var chunkLoadingGlobal = self["webpackChunkwebpackmodule3"] = self["webpackChunkwebpackmodule3"] || [];chunkLoadingGlobal.forEach(data => {webpackJsonpCallback(data);});var push = chunkLoadingGlobal.push;chunkLoadingGlobal.push = data => {push(data);webpackJsonpCallback(data);};require("./src/index.js");
})();// src_lib_js.js
"use strict";(self["webpackChunkwebpackmodule3"] = self["webpackChunkwebpackmodule3"] || [])
.push(['src_lib_js',{"./src/lib.js":((exports, require) => {exports.default = 'lib';})}
]);下面解释一下webpack对于动态依赖的打包的关键处理。
动态依赖会把依赖的模块单独打包成一个chunk,chunk就是一个文件,一个chunk中包含1个或多个module。
动态依赖语句会被转为一个promise,通过动态创建script标签异步加载chunk。
加载好chunk后,会做几件事情:
- 把自己注册到已安装依赖中(
webpackChunkwebpackmodule3) - 加载chunk中的所有模块
- 把加载chunk的promise resolve
加载好chunk后(即promise resolve后),意味着模块也已经加载好,接下来就会通过require加载模块(第9行)。然后就可以正常地使用模块了。
我们看到webpack通过全局变量webpackChunkwebpackmodule3来管理多chunk的加载过程,那如果多个用webpack打包的项目工作在同一个浏览器中,会不会全局变量冲突呢?webpack考虑到了这个问题,支持用户通过output.jsonpFunction选项配置全局变量的名称,这样就可以避免冲突。
多chunk打包
wepback支持分包加载,可以把项目打包成多个chunk,多个chunk的加载和动态依赖类似,也是要通过一个全局变量管理chunk,所以chunk的加载过程都是一样的。
多chunk需要注意一个问题,因为多个chunk是有依赖关系的,如果我们在html中加载chunk的顺序正确,那么执行的顺序和打成一个bundle一样,如果加载顺序和依赖的关系不一致,就需要通过某种机制保证依赖的chunk加载完,再执行模块。
我们看下面代码打包的示例
// index.js
import lib from './lib';
console.log(lib);
// lib.js
export default 'lib';webpack配置分包
// webpack.config.js
module.exports = {entry: './src/index.js',mode: 'development',optimization: {splitChunks: {chunks: 'all',minSize: 0,cacheGroups: {lib: {test: /lib/,}},},}
};打包产物如下(代码经过简化)
// main.js
(() => {"use strict";var modules = ({"./src/index.js":((exports, require) => {var lib = require("./src/lib.js");console.log(lib["default"]);})});var modulesCache = {};// The require functionfunction require(moduleId) {var cachedModule = modulesCache[moduleId];if (cachedModule !== undefined) {return cachedModule.exports;}var module = modulesCache[moduleId] = {exports: {}};modules[moduleId](module.exports, require);return module.exports;}var installedChunks = {"main": 0};// 如果依赖的chunk未加载完成,保存在deferred中var deferred = [];// 如果依赖的chunk加载完,执行回调// 否则保存该模块,等待依赖的chunk都加载完后再执行回调require.Onload = (chunkIds, fn) => {var result;deferred.push([chunkIds, fn]);// 遍历deferred,将每个依赖chunk加载完成的模块执行for (var i = 0; i < deferred.length; i++) {var [chunkIds, fn] = deferred[i];var fulfilled = true;for (var j = 0; j < chunkIds.length; j++) {if ((installedChunks[chunkIds[i]] === 0) {chunkIds.splice(j--, 1);}else {fulfilled = false;}}if(fulfilled) {deferred.splice(i--, 1)var r = fn();if (r !== undefined) result = r;}}return result;};var webpackJsonpCallback = (data) => {var [chunkId, moreModules] = data;for(moduleId in moreModules) {modules[moduleId] = moreModules[moduleId];}installedChunks[chunkId][0]();return require.Onload();}var chunkLoadingGlobal = self["webpackChunkwebpackmodule3"] = self["webpackChunkwebpackmodule3"] || [];chunkLoadingGlobal.forEach(data => {webpackJsonpCallback(data);});var push = chunkLoadingGlobal.push;chunkLoadingGlobal.push = data => {push(data);webpackJsonpCallback(data);};// startuprequire.Onload(["lib-src_lib_js"], () => (require("./src/index.js")));
})();// lib-src_lib_js.js
(self["webpackChunkwebpackmodule3"] = self["webpackChunkwebpackmodule3"] || []).push([["lib-src_lib_js"],{"./src/lib.js":((exports, require) => {exports.default = 'lib';})
}]);可以看到分片打包之后,不能像只有一个bundle那样直接通过require引用模块,因为依赖的模块所在的chunk可能没有加载完,因此要先通过require.Onload方法确保chunk已经加载完,再去执行当前模块,由于chunk加载完时,chunk内的所有模块都会被加载,因此这时候通过require引用依赖的模块是没有问题的。
require.Onload方法就是把每个模块依赖的chunk和回调都保存起来,并且检查当前所有的模块,如果发现某个模块依赖的chunk都已经加载完,就执行其回调。每当某个chunk加载完,都会调用require.Onload,以便依赖它的模块可以马上执行。
这样,webpack就可以保证分包的chunk在页面加载顺序和依赖顺序不一致时候,也可以正常工作,同步地执行。
模块路径解析
webpack可以解析三种文件路径:绝对路径、相对路径和模块路径,匹配 路径后还会匹配扩展名。
https://www.webpackjs.com/concepts/module-resolution/#webpack-%E4%B8%AD%E7%9A%84%E8%A7%A3%E6%9E%90%E8%A7%84%E5%88%99
下面看如何使用resolve选项控制路径解析。
resolve选项
下面列举几个常用的resolve选项,更多更详细的说明参考官方文档:
https://www.webpackjs.com/configuration/resolve/
resolve.modules
指定webpack模块解析的目录,默认是['node_modules']。webpack会尝试从resolve.module指定的列表中查找模块路径。
resolve.alias
设置路径别名,设置该选项后,让模块引用更简单。
alias: {"@": path.resolve(__dirname, 'src'),"~": path.resolve(__dirname, 'src')
}resolve.extensions
配置扩展名
{extensions: [".js", ".json"]
}webpack会对没有扩展名的路径按照extensions依次匹配,所以通常要把常用的文件扩展名放在前面,以减少尝试匹配的次数。
动态路径的打包
对于动态的路径,如import()/require()。会打包相应目录下所有文件,然后在代码运行的时候动态拼接起来加载。
因此应该注意不要让路径太过模糊,否则会打包出非常多的chunk,最极端情况是整个路径都是一个变量,这意味着webpack会打包所有模块。