- 一、方差与标准差
- 二、协方差
- 三、皮尔逊系数
- 四、斯皮尔曼系数
一、方差与标准差
总体方差
V a r ( x ) = σ 2 = ∑ i = 1 n ( x i − x ˉ ) 2 n = ∑ i = 1 n x i 2 − n x ˉ 2 n = E ( x 2 ) − [ E ( x ) ] 2 Var(x)=\sigma^2=\frac {\sum\limits_{i=1}^{n} (x_i - \bar{x})^2} {n} =\frac{\sum\limits_{i=1}^nx_i^2-n\bar{x}^2} {n} =E(x^2)-[E(x)]^2 Var(x)=σ2=ni=1∑n(xi−xˉ)2=ni=1∑nxi2−nxˉ2=E(x2)−[E(x)]2
样本方差
V a r ( x ) = s 2 = ∑ i = 1 n ( x i − x ˉ ) 2 n − 1 = ∑ i = 1 n x i 2 − n x ˉ 2 n − 1 Var(x)=s^2=\frac {\sum\limits_{i=1}^{n} (x_i - \bar{x})^2} {n-1} =\frac{\sum\limits_{i=1}^nx_i^2-n\bar{x}^2} {n-1} Var(x)=s2=n−1i=1∑n(xi−xˉ)2=n−1i=1∑nxi2−nxˉ2
标准差
S D ( x ) = σ ∣ s = V a r ( x ) SD(x)=\sigma|s=\sqrt{Var(x)} SD(x)=σ∣s=Var(x)
方差用来衡量随机变量离其期望值的分散程度,标准差在方差的基础上消除了量纲的影响。
二、协方差
总体协方差
C o v ( x , y ) = ∑ i = 1 n ( x i − x ˉ ) ( y i − y ˉ ) n = ∑ i = 1 n x i y i − n x ˉ y ˉ n {Cov}(x, y) = \frac {\sum\limits_{i=1}^{n} (x_i - \bar{x})(y_i - \bar{y})} {n} =\frac{\sum\limits_{i=1}^nx_iy_i-n\bar{x}\bar{y}} {n} Cov(x,y)=ni=1∑n(xi−xˉ)(yi−yˉ)=ni=1∑nxiyi−nxˉyˉ
样本协方差
C o v ( x , y ) = ∑ i = 1 n ( x i − x ˉ ) ( y i − y ˉ ) n − 1 = ∑ i = 1 n x i y i − n x ˉ y ˉ n − 1 {Cov}(x, y) = \frac {\sum\limits_{i=1}^{n} (x_i - \bar{x})(y_i - \bar{y})} {n-1} =\frac{\sum\limits_{i=1}^nx_iy_i-n\bar{x}\bar{y}} {n-1} Cov(x,y)=n−1i=1∑n(xi−xˉ)(yi−yˉ)=n−1i=1∑nxiyi−nxˉyˉ
对协方差公式的直观理解:以 ( x ˉ , y ˉ ) (\bar{x}, \bar{y}) (xˉ,yˉ)为坐标原点,计算各个点到原点构成的矩形面积之和,然后除以n-1。其中一三象限面积为正,二四象限面积为负。
协方差的含义可以从以下几个方面理解:
- 正值和负值: 协方差为正表示两个变量呈正相关关系,即一个变量增大,另一个变量也倾向于增大;协方差为负表示两个变量呈负相关关系,即一个变量增大,另一个变量倾向于减小。
- 绝对值的大小: 协方差的绝对值大小表示变量之间的线性关系的强度。绝对值越大,说明两个变量之间的线性关系越强;绝对值越小,说明关系越弱。
- 零值: 协方差为零表示两个变量之间没有线性关系。但需要注意,协方差为零并不意味着两个变量之间没有其他类型的关系,只是没有线性关系。
- 单位: 协方差的单位是两个变量单位的乘积,即结果受量纲的影响。
直观理解可以参考https://www.youtube.com/watch?v=J9pXAfd_Kmc
三、皮尔逊系数
公式1
r = ∑ ( x i − x ˉ ) ( y i − y ˉ ) ∑ ( x i − x ˉ ) 2 ∑ ( y i − y ˉ ) 2 = C o v ( x , y ) σ x σ y r=\frac {\sum (x_i - \bar{x}) (y_i - \bar{y})} {\sqrt{\sum(x_i - \bar{x})^2 \sum(y_i - \bar{y})^2}} =\frac{Cov(x,y)} {\sigma_x\sigma_y} r=∑(xi−xˉ)2∑(yi−yˉ)2∑(xi−xˉ)(yi−yˉ)=σxσyCov(x,y)
公式2
r = 1 n ∑ i = 1 n x i y i − x ˉ y ˉ σ x σ y r=\frac{\frac1n\sum\limits_{i=1}^nx_iy_i-\bar{x}\bar{y}} {\sigma_x\sigma_y} r=σxσyn1i=1∑nxiyi−xˉyˉ
公式1表明皮尔逊系数其实就是x, y的协方差与x, y各自标准差的乘积之比。皮尔逊系数的值域范围为[-1, 1],不受量纲的影响。
下面分别给出值域的证明和公式1–>公式2的推导。
(1)值域证明:
- 令 x i − x ˉ = a i , y i − y ˉ = b i x_i-\bar{x}=a_i,y_i-\bar{y}=b_i xi−xˉ=ai,yi−yˉ=bi,则公式1= ∑ a i b i ∑ a i 2 ∑ b i 2 \frac{\sum{a_ib_i}} {\sqrt{\sum{a_i}^2\sum{b_i}^2}} ∑ai2∑bi2∑aibi
- 根据柯西不等式的一般形式有: ∑ i = 1 n a i 2 ∑ i = 1 n b i 2 ≥ ( ∑ i = 1 n a i b i ) 2 \sum\limits_{i=1}^{n}a_i^2 \sum\limits_{i=1}^{n}b_i^2\ge(\sum\limits_{i=1}^{n}a_ib_i)^2 i=1∑nai2i=1∑nbi2≥(i=1∑naibi)2
- 由1、2知道原式中的分子 ∑ a i b i \sum{a_ib_i} ∑aibi的绝对值必小于等于分母 ∑ a i 2 ∑ b i 2 \sqrt{\sum{a_i}^2 \sum{b_i}^2} ∑ai2∑bi2,所以对应值域[-1,1]
看到一个关于柯西不等式的证明很有意思,分享下。原地址https://zhuanlan.zhihu.com/p/397034475

(2)公式1–>公式2推导:
r = ∑ ( x i − x ˉ ) ( y i − y ˉ ) ∑ ( x i − x ˉ ) 2 ∑ ( y i − y ˉ ) 2 = ∑ ( x i y i − x ˉ y i − x i y ˉ + x ˉ y ˉ ) ∑ ( x i 2 − 2 x i x ˉ + x ˉ 2 ) ∑ ( y i 2 − 2 y i y ˉ + y ˉ 2 ) = ∑ x i y i − n x ˉ y ˉ − n x ˉ y ˉ + n x ˉ y ˉ ( ∑ x i 2 − 2 n x ˉ 2 + n x ˉ 2 ) ( ∑ y i 2 − 2 n y ˉ 2 + n y ˉ 2 ) = ∑ x i y i − n x ˉ y ˉ ( ∑ x i 2 − n x ˉ 2 ) ( ∑ y i 2 − n y ˉ 2 ) \begin{aligned} r&=\frac {\sum(x_i - \bar{x}) (y_i - \bar{y})} {\sqrt{\sum(x_i - \bar{x})^2 \sum(y_i - \bar{y})^2}}\\ &=\frac{\sum(x_iy_i-\bar{x}y_i-x_i\bar{y}+\bar{x}\bar{y})} {\sqrt{\sum(x_i^2-2x_i\bar{x}+\bar{x}^2) \sum(y_i^2-2y_i\bar{y}+\bar{y}^2)}}\\ &=\frac{\sum{x_iy_i}-n\bar{x}\bar{y}-n\bar{x}\bar{y}+n\bar{x}\bar{y}} {\sqrt{(\sum{x_i^2}-2n\bar{x}^2+n\bar{x}^2) (\sum{y_i^2}-2n\bar{y}^2+n\bar{y}^2)}}\\ &=\frac{\sum{x_iy_i}-n\bar{x}\bar{y}} {\sqrt{(\sum{x_i^2}-n\bar{x}^2) (\sum{y_i^2}-n\bar{y}^2)}} \end{aligned} r=∑(xi−xˉ)2∑(yi−yˉ)2∑(xi−xˉ)(yi−yˉ)=∑(xi2−2xixˉ+xˉ2)∑(yi2−2yiyˉ+yˉ2)∑(xiyi−xˉyi−xiyˉ+xˉyˉ)=(∑xi2−2nxˉ2+nxˉ2)(∑yi2−2nyˉ2+nyˉ2)∑xiyi−nxˉyˉ−nxˉyˉ+nxˉyˉ=(∑xi2−nxˉ2)(∑yi2−nyˉ2)∑xiyi−nxˉyˉ
分子分母除以n,结合上面方差的公式即可证明。
四、斯皮尔曼系数
斯皮尔曼系数的计算和皮尔逊系数相同,唯一区别只是将皮尔逊系数中的原始值替换为了原始值所对应的秩(序号)。
假设有两个 ( x , y ) (x,y) (x,y)的变量,对应的顺序编号为 ( R ( x ) , R ( y ) ) (R(x),R(y)) (R(x),R(y)),将 ( R ( x ) , R ( y ) ) (R(x),R(y)) (R(x),R(y))当做 ( x , y ) (x,y) (x,y)代入到皮尔逊系数公式则得到斯皮尔曼系数的一般计算公式:
ρ = ∑ ( R ( x i ) − R ( x i ) ˉ ) ( R ( y i ) − R ( y i ) ˉ ) ∑ ( R ( x i ) − R ( x i ) ˉ ) 2 ∑ ( R ( y i ) − R ( y i ) ˉ ) 2 = C o v ( R ( x ) , R ( y ) ) σ R ( x ) σ R ( y ) \rho=\frac {\sum (R(x_i) - \bar{R(x_i)}) (R(y_i) - \bar{R(y_i)})} {\sqrt{\sum(R(x_i) - \bar{R(x_i) })^2 \sum(R(y_i) - \bar{R(y_i)})^2}} =\frac{Cov(R(x),R(y))} {\sigma_{R(x)} \sigma_{R(y)}} ρ=∑(R(xi)−R(xi)ˉ)2∑(R(yi)−R(yi)ˉ)2∑(R(xi)−R(xi)ˉ)(R(yi)−R(yi)ˉ)=σR(x)σR(y)Cov(R(x),R(y))
当 x , y x,y x,y中均不包含重复值时,可以使用下面的简单公式计算:
r = 1 − 6 ∑ d i 2 n ( n 2 − 1 ) r=1-\frac{6\sum{d_i^2}} {n(n^2-1)} r=1−n(n2−1)6∑di2
其中 d i = R ( x i ) − R ( y i ) d_i=R(x_i)-R(y_i) di=R(xi)−R(yi),表示 x , y x,y x,y之间的序号差。下面先举个例子了解实际如何计算,再给出一般公式到简单公式的证明。
(1)实际计算
这里直接拿维基百科上的截图,下面的数据中, X , Y X,Y X,Y分别表示智商和每周看电视的时间。
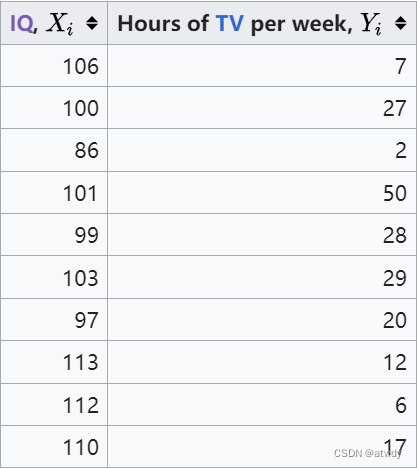
接下来先根据 X i X_i Xi进行排序,得到rank x i x_i xi,再在 X i X_i Xi排完序的基础上,对 Y i Y_i Yi进行排序,得到rank y i y_i yi,然后分别计算它们之间的序号差 d i d_i di和 d i 2 d_i^2 di2。
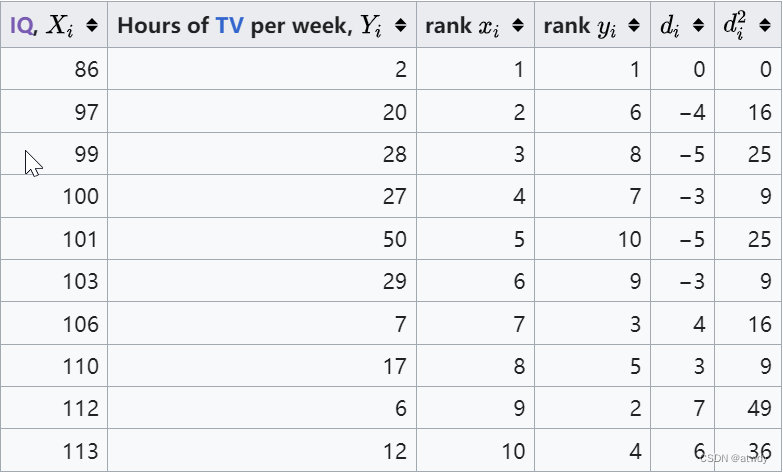
最后代入到公式 1 − 6 ∑ d i 2 n ( n 2 − 1 ) 1-\frac{6\sum{d_i^2}}{n(n^2-1)} 1−n(n2−1)6∑di2得到 r = 1 − 6 ∗ 194 10 ( 1 0 2 − 1 ) ≈ − 0.1758 r=1-\frac{6*194}{10(10^2-1)}\approx-0.1758 r=1−10(102−1)6∗194≈−0.1758。
简单公式只适用于 X i , Y i X_i,Y_i Xi,Yi中均无重复值的情况,任一列有重复值使用简单公式计算的结果就会有偏差。至于为什么有偏差,可以从下面(2)中的公式推导看出。
当有重复值时,一般采用平均顺序作为所有重复值的序号,例如对于序列[1, 1, 1, 2, 3],1的序号为(1+2+3)/3,均为2。原序列对应的序号为[2, 2, 2, 4, 5],经过验证在pandas的corr方法中采用的就是平均顺序计算。
(2)一般公式到简单公式的推导
推导可以从皮尔逊系数的计算公式2开始,只不过这里的 x i , y i x_i,y_i xi,yi代表的不是原值,而是原值对应的秩。下面推导过程中的前置条件为: x i , y i x_i,y_i xi,yi均服从类似1, 2, 3, 4, …这样的分布,均为正整数且不含重复值,因为这里的 x i , y i x_i,y_i xi,yi表示的是序号。这就要求原值中不能包含重复值。
ρ = 1 n ∑ i = 1 n x i y i − x ˉ y ˉ σ x σ y = 1 n ∑ i = 1 n 1 2 ( x i 2 + y i 2 − d i 2 ) − x ˉ 2 σ x σ y = 1 2 n ∑ i = 1 n x i 2 + 1 2 n ∑ i = 1 n y i 2 − 1 2 n ∑ i = 1 n d i 2 − x ˉ 2 σ x σ y = ( 1 n ∑ i = 1 n x i 2 − x ˉ 2 ) − 1 2 n ∑ i = 1 n d i 2 σ x σ y = σ x 2 − 1 2 n ∑ i = 1 n d i 2 σ x σ y = σ x σ y − 1 2 n ∑ i = 1 n d i 2 σ x σ y = 1 − 1 2 n ∑ i = 1 n d i 2 σ x σ y = 1 − 1 2 n ∑ i = 1 n d i 2 1 n ∑ i = 1 n x i 2 − x ˉ 2 \begin{aligned} \rho&=\frac{\frac1n\sum\limits_{i=1}^nx_iy_i-\bar{x}\bar{y}} {\sigma_x\sigma_y}\\ &=\frac{\frac1n\sum\limits_{i=1}^n\frac12(x_i^2+y_i^2-d_i^2)-\bar{x}^2} {\sigma_x\sigma_y}\\ &=\frac{\frac1{2n}\sum\limits_{i=1}^nx_i^2+\frac1{2n}\sum\limits_{i=1}^ny_i^2-\frac1{2n}\sum\limits_{i=1}^nd_i^2-\bar{x}^2} {\sigma_x\sigma_y}\\ &=\frac{(\frac1n\sum\limits_{i=1}^nx_i^2-\bar{x}^2)-\frac1{2n}\sum\limits_{i=1}^nd_i^2} {\sigma_x\sigma_y}\\ &=\frac{\sigma_x^2-\frac1{2n}\sum\limits_{i=1}^nd_i^2} {\sigma_x\sigma_y}\\ &=\frac{\sigma_x\sigma_y-\frac1{2n}\sum\limits_{i=1}^nd_i^2} {\sigma_x\sigma_y}\\ &=1-\frac{\frac1{2n}\sum\limits_{i=1}^nd_i^2} {\sigma_x\sigma_y}\\ &=1-\frac{\frac1{2n}\sum\limits_{i=1}^nd_i^2} {\frac1n\sum\limits_{i=1}^nx_i^2-\bar{x}^2} \end{aligned} ρ=σxσyn1i=1∑nxiyi−xˉyˉ=σxσyn1i=1∑n21(xi2+yi2−di2)−xˉ2=σxσy2n1i=1∑nxi2+2n1i=1∑nyi2−2n1i=1∑ndi2−xˉ2=σxσy(n1i=1∑nxi2−xˉ2)−2n1i=1∑ndi2=σxσyσx2−2n1i=1∑ndi2=σxσyσxσy−2n1i=1∑ndi2=1−σxσy2n1i=1∑ndi2=1−n1i=1∑nxi2−xˉ22n1i=1∑ndi2
其中 ∑ i = 1 n x i 2 = 1 2 + 2 2 + 3 2 + . . . + n 2 = n ( n + 1 ) ( 2 n + 1 ) 6 \sum\limits_{i=1}^nx_i^2=1^2+2^2+3^2+...+n^2=\frac{n(n+1)(2n+1)}{6} i=1∑nxi2=12+22+32+...+n2=6n(n+1)(2n+1)(金字塔数), x ˉ 2 = ( 1 + n 2 ) 2 \bar{x}^2=(\frac{1+n}{2})^2 xˉ2=(21+n)2,代入上面得到 ρ = 1 − 6 ∑ d i 2 n ( n 2 − 1 ) \rho=1-\frac{6\sum{d_i^2}}{n(n^2-1)} ρ=1−n(n2−1)6∑di2。
斯皮尔曼系数值域同样为[-1, 1],因为本身的计算还是基于皮尔逊系数公式。
参考https://en.wikipedia.org/wiki/Spearman%27s_rank_correlation_coefficient