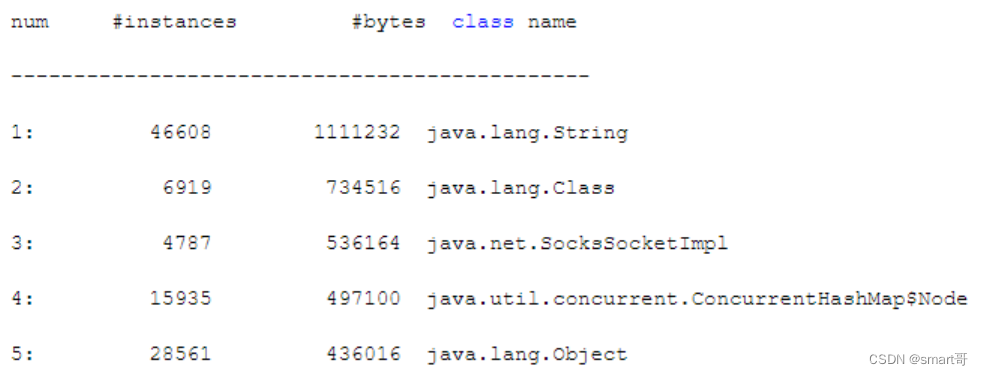
1.数据操作
存储
为了能够完成各种数据操作,我们需要某种方法来存储和操作数据。 通常,我们需要做两件重要的事:
(1)获取数据;
(2)将数据读入计算机后对其进行处理。
如果没有某种方法来存储数据,那么获取数据是没有意义的。
首先,我们介绍n维数组,也称为张量(tensor)。
张量表示一个由数值组成的数组,这个数组可能有多个维度。
存储有很多中方式,比如:
x = np.arange(12)
x = torch.arange(12)
x = tf.range(12)
x = paddle.arange(12)
还有很多其他的方法,比如shape,size,reshape,都是为了把我们的数据存储起来
运算
我们的兴趣不仅限于读取数据和写入数据。 我们想在这些数据上执行数学运算,其中最简单且最有用的操作是按元素(elementwise)运算。 它们将标准标量运算符应用于数组的每个元素。

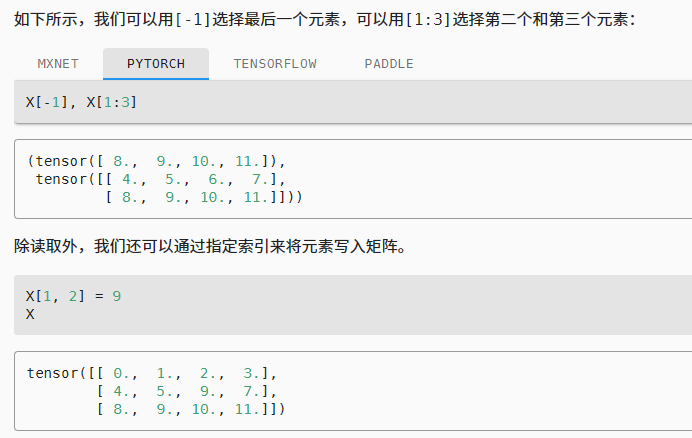
切片和索引
就像在任何其他Python数组中一样,张量中的元素可以通过索引访问。
总结
深度学习存储和操作数据的主要接口是张量(n维数组)。它提供了各种功能,包括基本数学运算、广播、索引、切片、内存节省和转换其他Python对象。
2.数据预处理
为了能用深度学习来解决现实世界的问题,我们经常从预处理原始数据开始, 而不是从那些准备好的张量格式数据开始。 在Python中常用的数据分析工具中,我们通常使用pandas软件包。 像庞大的Python生态系统中的许多其他扩展包一样,pandas可以与张量兼容。
2.1读取数据集
import pandas as pddata = pd.read_csv(data_file)
print(data)NumRooms Alley Price
0 NaN Pave 127500
1 2.0 NaN 106000
2 4.0 NaN 178100
3 NaN NaN 140000
2.2 处理缺失值
注意,“NaN”项代表缺失值。 为了处理缺失的数据,典型的方法包括插值法和删除法, 其中插值法用一个替代值弥补缺失值,而删除法则直接忽略缺失值。
首先,通过位置索引iloc,我们将data分成inputs和outputs, 其中前者为data的前两列,而后者为data的最后一列。
inputs, outputs = data.iloc[:, 0:2], data.iloc[:, 2]
以上述数据为例,对于inputs中缺少的数值,我们用同一列的均值替换“NaN”项。
inputs = inputs.fillna(inputs.mean())
print(inputs)
对于inputs中的类别值或离散值,我们将“NaN”视为一个类别。 由于“巷子类型”(“Alley”)列只接受两种类型的类别值“Pave”和“NaN”, pandas可以自动将此列转换为两列“Alley_Pave”和“Alley_nan”。 巷子类型为“Pave”的行会将“Alley_Pave”的值设置为1,“Alley_nan”的值设置为0。 缺少巷子类型的行会将“Alley_Pave”和“Alley_nan”分别设置为0和1。
inputs = pd.get_dummies(inputs, dummy_na=True)
print(inputs)NumRooms Alley_Pave Alley_nan
0 3.0 1 0
1 2.0 0 1
2 4.0 0 1
3 3.0 0 1
经过上面的操作,我们就把inputs全都转变成了数值
2.3 转换为张量格式
现在inputs和outputs中的所有条目都是数值类型,它们可以转换为张量格式。
import torchX = torch.tensor(inputs.to_numpy(dtype=float))
y = torch.tensor(outputs.to_numpy(dtype=float))
X, y(tensor([[3., 1., 0.],[2., 0., 1.],[4., 0., 1.],[3., 0., 1.]], dtype=torch.float64),tensor([127500., 106000., 178100., 140000.], dtype=torch.float64))
获得张量之后,后续就可以对张量进行运算了
总结
at64),
tensor([127500., 106000., 178100., 140000.], dtype=torch.float64))
获得张量之后,后续就可以对张量进行运算了## 总结处理NaN值的时候,我们通常采用插值法和删除法参考:
B站李沐先生--动手学深度学习