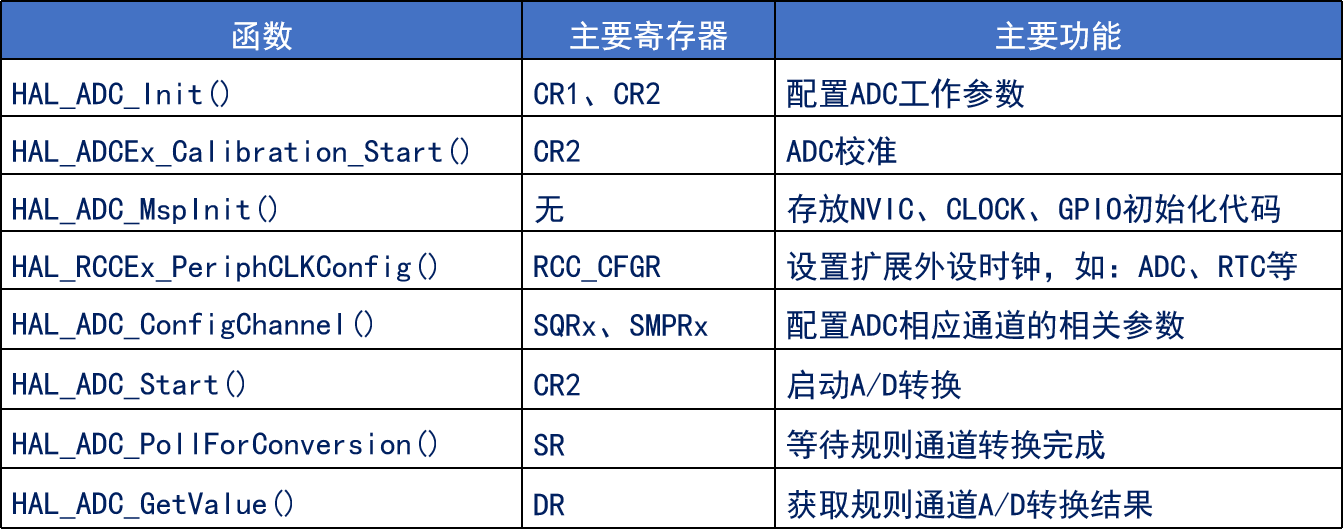
./spider/movie.py文件
import scrapy
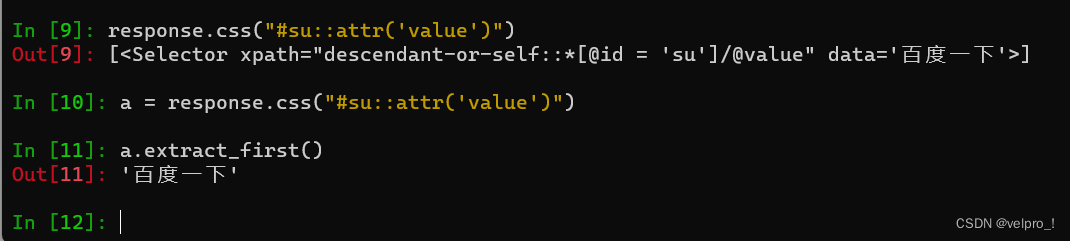
from scrapy_movie_20240116.items import ScrapyMovie20240116Itemclass MovieSpider(scrapy.Spider):name = "movie"# 如果是多页下载的话, 那么必须要调整的是allowed_domains的范围 一般情况下只写城名allowed_domains = ["dy2018.com"]start_urls = ["https://dy2018.com/html/tv/hytv/index.html"]def parse(self, response):# 获取第一页名字和第二页图片a_list = response.xpath("//div[@class='co_content8']//td[2]//a") # xpath语法for a in a_list:# extract_first() 从某个数据结构中提取第一个元素# 获取第一页的name 和 要点击的链接name = a.xpath("./text()").extract_first()href = a.xpath("./@href").extract_first()# 第2页的地址是:url = "https://dy2018.com" + href# 对第二页的链接发起访问# scrapy.Request就是scrpay的get请求 url就是请求地址# callback是你要执行的那个函数注意不需要加()# meta 把这个方法的name传到parse_second方法中yield scrapy.Request(url=url, callback=self.parse_second, meta={'name': name})def parse_second(self, response):# 获取第2页的图片src = response.xpath("//div[@id='Zoom']/img/@src").extract_first() # xpath语法# 接受到请求的那个meta参数的值name = response.meta["name"]# 将爬取的数据放在对象里movie = ScrapyMovie20240116Item(src=src, name=name)# 获取一个movie 将movie交给pipelines,将对象放在管道里yield movie
items.py文件
import scrapyclass ScrapyMovie20240116Item(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()# 通俗的说就是你要下载的数据都有什么name = scrapy.Field()src = scrapy.Field()pipelines.py文件
class ScrapyMovie20240116Pipeline:# 在爬虫文件开始之前就执行的方法def open_spider(self, spider):self.fp = open("movie.json", "w", encoding="utf-8")def process_item(self, item, spider):self.fp.write(str(item))return item# 在爬虫文件开始之后就执行的方法def close_spider(self,spider):self.fp.close()settings.py文件:
# 开启管道
ITEM_PIPELINES = {"scrapy_movie_20240116.pipelines.ScrapyMovie20240116Pipeline": 300,
}