本篇为第二篇,剩余请移步主页查看
第二步:采集日志数据
准备工作:
(1)开启3台虚拟机
(2)3台虚拟机用xshell启动zookeeper


 (3)3台启动Hadoop
(3)3台启动Hadoop
在master群起后jps查看节点
 在slave1查看节点:
在slave1查看节点:
 在slave2查看节点:
在slave2查看节点:
 1.创建/home/hadoop/web_log目录,使用以下命令:
1.创建/home/hadoop/web_log目录,使用以下命令:
mkdir /home/hadoop/web_log
2.进入/home/hadoop/web_log目录,使用以下命令:
cd /home/hadoop/web_log/

3.创建nginx_memory_hdfs.properties文件,编辑文件使用以下命令:
vim nginx_memory_hdfs.properties

填写以下内容:
# agent 起个名字叫做 a1
# 设置 a1 的 sources 叫做 r1
a1.sources = r1# 设置 a1 的 sinks 叫做 k1
a1.sinks = k1# 设置 a1 的 channels 叫做 c1
a1.channels = c1# 设置 r1 的类型是 exec,用于采集命令产生的数据
a1.sources.r1.type = exec# 设置 r1 采集 tail -F 命令产生的数据
a1.sources.r1.command= sudo tail -F /var/log/nginx/access.log# 设置 c1 的类型是 memory
a1.channels.c1.type = memory# 设置 c1 的缓冲区容量
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100# 设置 k1 的类型是 hdfs
a1.sinks.k1.type = hdfs# 设置 k1 输出路径,按照时间在 hdfs 上创建相应的目录
a1.sinks.k1.hdfs.path = /web/log/%y-%m-%d/%H
a1.sinks.k1.hdfs.filePrefix = events-# 设置 k1 输出的数据保存为文本
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text# 把时间戳放入数据的头中
a1.sinks.k1.hdfs.useLocalTimeStamp = true# 设置 r1 连接 c1
a1.sources.r1.channels = c1# 设置 k1 连接 c1
a1.sinks.k1.channel = c1
4.使用nginx_memory_hdfs.properties文件启动flume,使用以下命令:
flume-ng agent -n a1 -c conf -f /home/hadoop/web_log/nginx_memory_hdfs.properties
 在浏览器进去http://ip/shop.html后在master使用以下命令监控访问日志:
在浏览器进去http://ip/shop.html后在master使用以下命令监控访问日志:
sudo tail -F /var/log/nginx/access.log

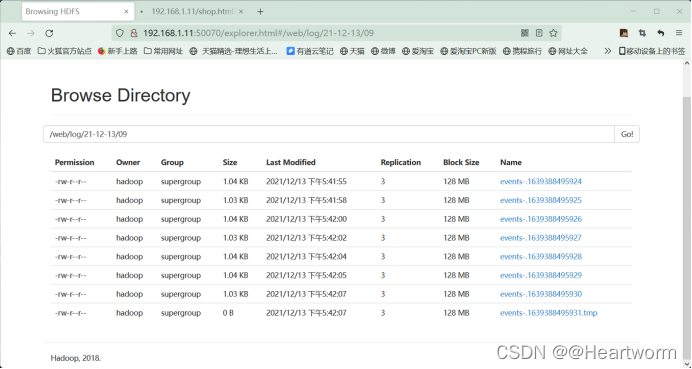
5.在hdfs检查日志数据是否采集到/web/log目录