本篇为第三篇,剩余请移步主页查看
本篇需要eclipse
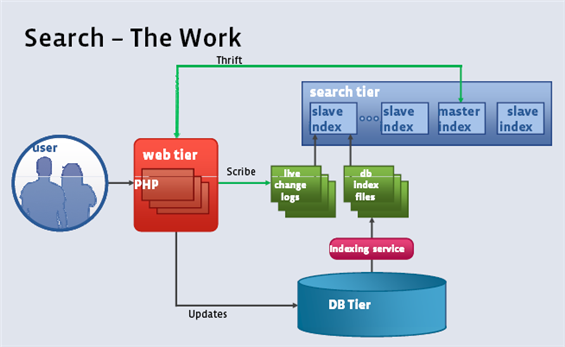
三.Etl数据清洗
(1)在eclipse连接Hadoop,通过xshell进行连接,并进行Hadoop可视化

(2)在eclipse创建Etl mapreduce项目
(3)在eclipse进行编写NginxEtlMapper 和NginxETLDiver这两个类


NginxEtlMapper类代码:
package ETL;import java.io.IOException;import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;public class nginxetlmapper extends Mapper<LongWritable,Text,Text,NullWritable>{private Text outputKey = new Text();
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException{String[] words = value.toString().split("");String path = words[6];outputKey.set(path);context.write(outputKey,NullWritable.get());}
}
NginxETLDiver类的代码:
import java.io.IOException;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class NginxEtlDriver {public static void main(String[] args) {if(args.length<2) {System.out.println("请输入正确的参数");return;}String day = args[0];String hour = args[1];Configuration conf = new Configuration();try {Job job = Job .getInstance(conf);job.setJobName("nginx-etl");job.setJarByClass(NginxEtlDriver.class);job.setMapperClass(NginxEtlMapper.class);job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(NullWritable.class);job.setNumReduceTasks(0);Path inputPath = new Path("/web/log/" + day + "/" + hour);FileInputFormat.addInputPath(job, inputPath);Path outputPath = new Path("/web/log/etl/" + day + "/" + hour);FileSystem.get(conf).delete(outputPath,true);FileOutputFormat.setOutputPath(job, outputPath);job.waitForCompletion(true);}catch(IOException e) {e.printStackTrace();}catch(InterruptedException e) {e.printStackTrace();}catch (ClassNotFoundException e) {e.printStackTrace();}}
}
(4)打包(jar)上传到/home/hadoop(Linux)下
打包步骤:
右键点击包含写的这两个类的包
 选择图标为奶瓶的jar file,点击next
选择图标为奶瓶的jar file,点击next


 最后点击browse 点击finish结束
最后点击browse 点击finish结束

找到打包后的文件保存位置拖拽到xshell上传,上传成功如图:


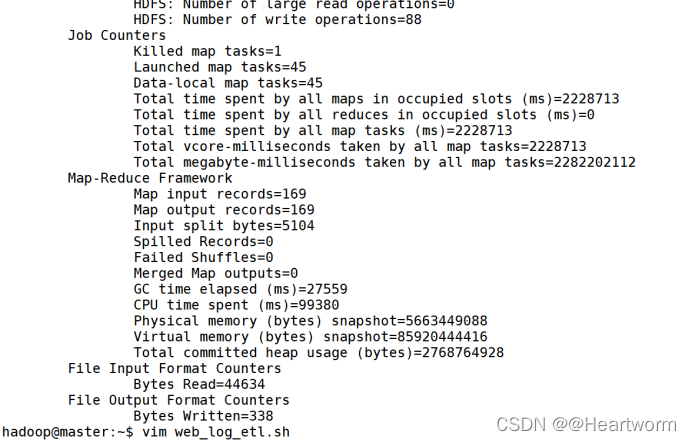
(5)执行jar包 hadoop jar /home/hadoop/web_log/NginxETL.jar 21-12–13 09年月日)

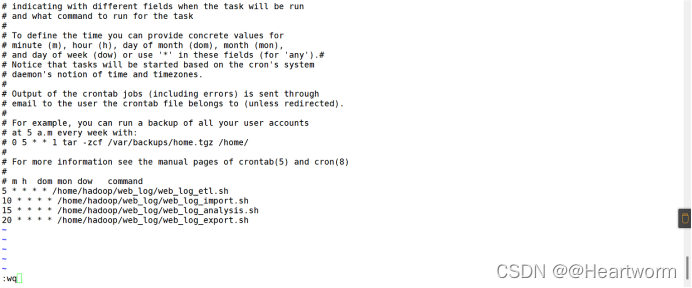
(6)直接编写web_log_etl.sh脚本,内容如图
命令:
vim web_log_etl.sh
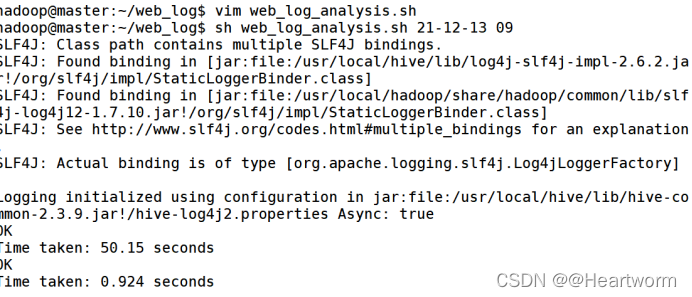
 (7)运行脚本使用以下命令:
(7)运行脚本使用以下命令:
sh web_log_etl.sh 21-12-13 09