本篇为项目第4步,详情请移步主页
四.搭建数据仓库
数仓搭建分为
Ods(数据运营层)数据原始层,最接近数据源中数据的一层
Dwd(数据仓库层)从ODS获得数据建立数据模型
DWB:data warehouse base 数据基础层,存储的是客观数据,一般用作中间层,可以认为是大量指标的数据层。
Dws(服务数据层)整合汇总成分析某一个主题域的服务数据,一般是宽表
Ads(数据服务层)该层主要是提供数据产品和数据分析使用的数据,宽表一般就放在这里
写两个脚本和一个udf函数
(1)创建编辑web_log_import.sh 脚本
 文件内容:
文件内容:
#!/bin/ bash
HQL ="
CREATE DATABASE IF NOТ EXISTS web _ log;
USE web _ log;
CREATE DATABASE IF NOТ EXISTS web _ log(
path string
)
PARТITIONED BY ( day string,hour string )
ROW FORMAT DELIМITED
FIELDS TERMINATED BY '\t';
LOAD DATA INPATH '/ web /log /etl/$1/$2' INТO TABLE ads_web_log PARТITIONED ( day =$1',hour='$2');
"
hive -e "$НQL”
 (2)创建编辑web_log analysis.sh 脚本
(2)创建编辑web_log analysis.sh 脚本

 文件内容如下:
文件内容如下:
#!/bin/bash
HQL="
USE web_log;
DROP TABLE IF EXISTS dwd_web_log;
CREATE TABLE dwd_web_log AS
SELECT path, day, hour
FROM ods_web_log
WHERE day='$1' and hour='$2';
ADD JAR /home/hadoop/web_log/UDFGetShop.jar;
CREATE TEMPORARY FUNCTION GET_SHOP as 'liu.UDFGetShop';
DROP TABLE IF EXISTS dws_web_log;
CREATE TABLE dws_web_log AS
SELECT GET_SHOP(path) shop, day, hour
FROM dwd_web_log;
DROP TABLE IF EXISTS ads_web_log;
CREATE TABLE ads_web_log AS
SELECT shop, COUNT(*) count, day, hour, DENSE_RANK() OVER(ORDER BY COUNT(*) DESC) rank
FROM dws_web_log group by shop,day,hour;
"
hive -e "$HQL"
(3)编写UDF函数
 (4)打包上传UDF架包上传到/home/hadoop/web_log
(4)打包上传UDF架包上传到/home/hadoop/web_log
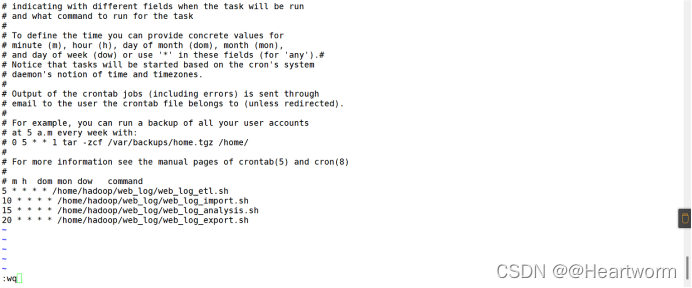
 (5)执行脚本文件
(5)执行脚本文件
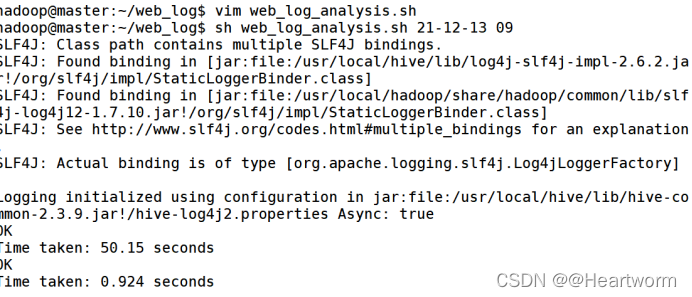
执行web_log_import.sh 脚本
 执行web_log analysis.sh 脚本
执行web_log analysis.sh 脚本