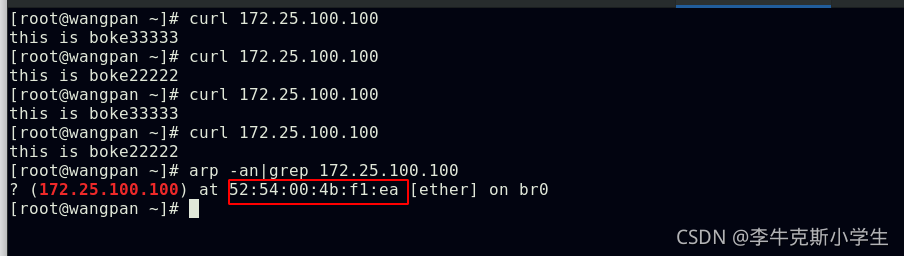
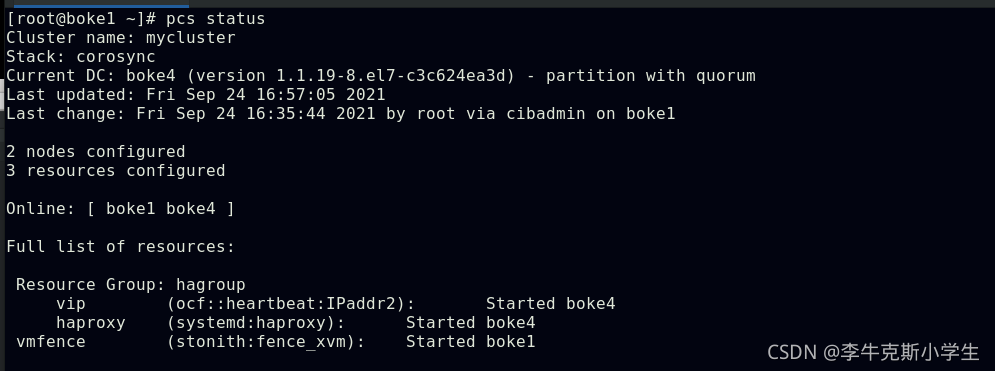
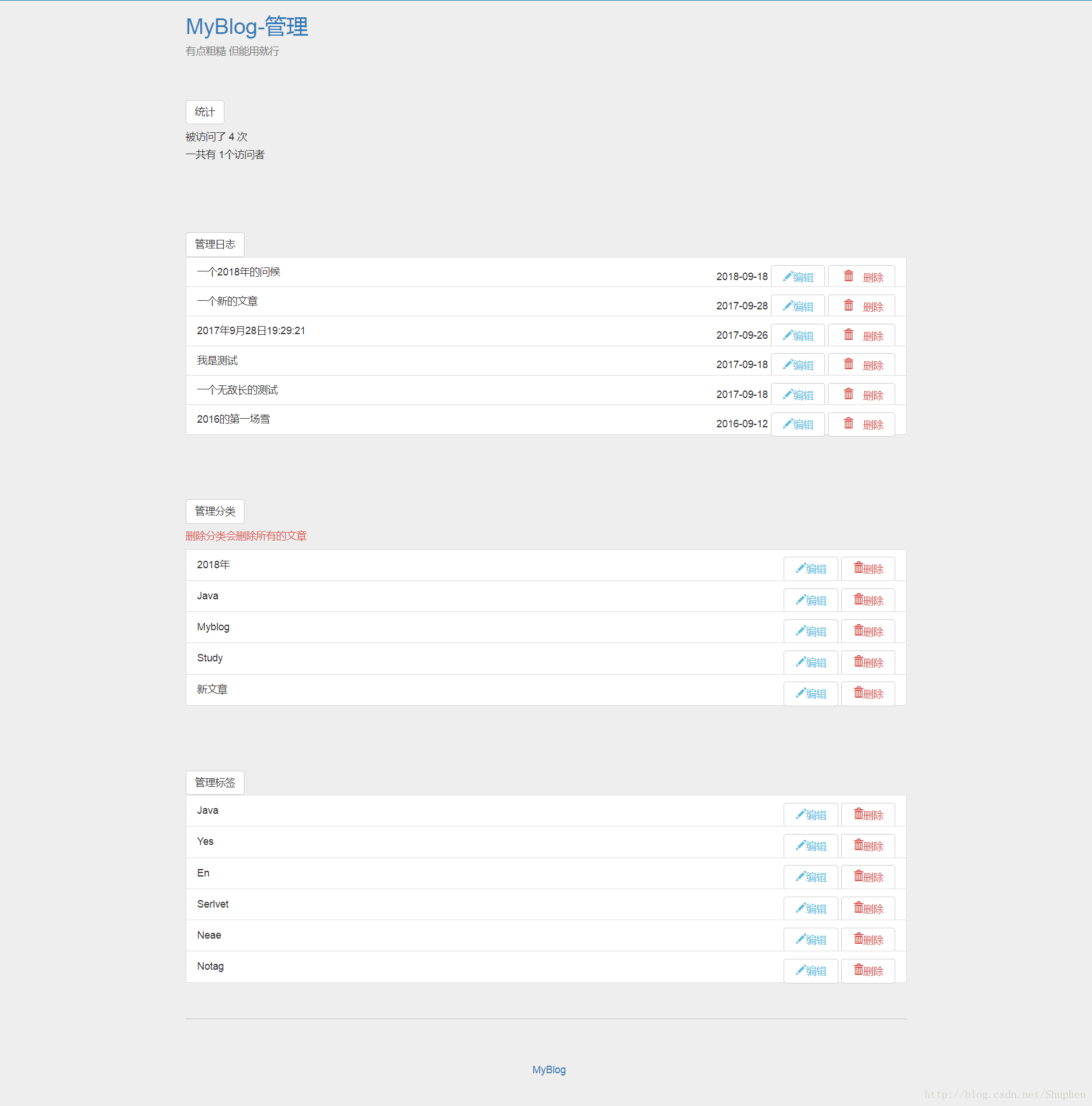
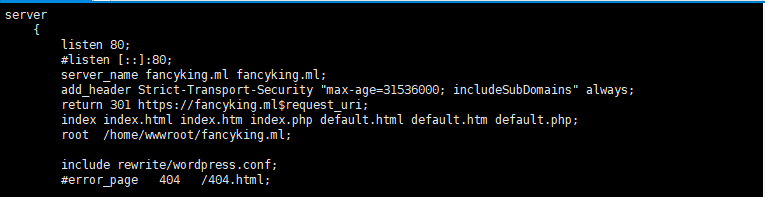
在爬取一个网站之前我们首先需要对目标站点的规模和结构进行一定程度的了解,这里可以通过对网站自身的robots.txt和Sitemap文件进行了解。
robots.txt文件让爬虫了解爬取该网站存在哪些限制,这里以淘宝网为例,如下所示:

里面列出了禁止的用户代理Baiduspider、Yahoo!等等
有些网站还会提供Sitemap文件用于定位网站最新的内容,不过目前很多网站都没有了,估计是防止爬虫吧!
在爬取一个网站之前我们首先需要对目标站点的规模和结构进行一定程度的了解,这里可以通过对网站自身的robots.txt和Sitemap文件进行了解。
robots.txt文件让爬虫了解爬取该网站存在哪些限制,这里以淘宝网为例,如下所示:
里面列出了禁止的用户代理Baiduspider、Yahoo!等等
有些网站还会提供Sitemap文件用于定位网站最新的内容,不过目前很多网站都没有了,估计是防止爬虫吧!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.luyixian.cn/news_show_903830.aspx
如若内容造成侵权/违法违规/事实不符,请联系dt猫网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!