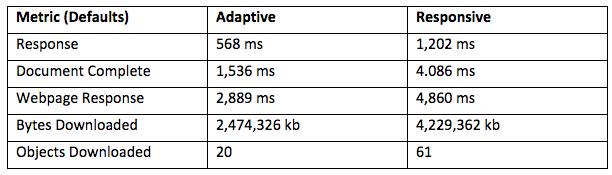
准备工具
既然是用nodejs来抓取, 安装nodejs就是必须的
我们需要用async来控制流程, 用cheerio来解析页面, 用mkdirp来创建目录, 用request来抓取页面
async的具体教程参考 https://github.com/caolan/async
步骤
创建packed.json, 内容如下
{"name": "spider","version": "0.0.1","description": "spider","main": "app.js","scripts": {"test": "echo \"Error: no test specified\" && exit 1"},"repository": {},"keywords": ["spider"],"author": "LinCenYing","license": "MIT","dependencies": {"async": "^2.0.0-rc.5","cheerio": "^0.18.0","colors": "^1.1.2","mkdirp": "^0.5.0","request": "^2.51.0","url": "^0.10.2"}
}执行 npm install 命令安装相关依赖
创建app.js文件, 代码如下
var colors = require('colors');
colors.setTheme({silly: 'rainbow',input: 'grey',verbose: 'cyan',prompt: 'red',info: 'green',data: 'blue',help: 'cyan',warn: 'yellow',debug: 'magenta',error: 'red'
});
var node = {async: require('async'),cheerio: require('cheerio'),fs: require('fs'),mkdirp: require('mkdirp'),path: require('path'),request: require('request'),url: require('url')
};
var Spider = {/*** 配置选项*/options: {// 网站地址uri: 'http://blog.naver.com/PostList.nhn?from=postList&blogId=tomiaaa¤tPage=',// 保存到此文件夹saveTo: './tomiaaa',// 从第几页开始下载startPage: 1,// 到第一页结束endPage: 388,// 图片并行下载上限downLimit: 2},posts: [],/*** 开始下载(程序入口函数)*/start() {var async = node.async;async.waterfall([this.getPages.bind(this),this.downAllImages.bind(this)], (err, result) => {if (err) {console.log('error: %s'.error, err.message);} else {console.log('success: 下载完毕'.info);}});},/*** 爬取所有页面*/getPages(callback) {var async = node.async;var i = this.options.startPage || 1;async.doWhilst((callback) => {var uri = this.options.uri + '' + i;async.waterfall([this.downPage.bind(this, uri, i),this.parsePage.bind(this)], callback);i++;}, (page) => this.options.endPage > page, callback);},/*** 下载单个页面*/downPage(uri, curpage, callback) {console.log('开始下载页面:%s', uri);var options = {url: uri,headers: {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.54 Safari/537.36','Cookie': 'lang_set=zh;'}};node.request(options, (err, res, body) => {if (!err) console.log('下载页面成功:%s'.info, uri);var page = {page: curpage,uri: uri,html: body};callback(err, page);});},/*** 解析单个页面并获取数据*/parsePage(page, callback) {console.log('开始分析页面数据:%s', page.uri);var $ = node.cheerio.load(page.html);var $posts = $('._photoImage');var self = this;var src = [];$posts.each(function() {var href = $(this).attr('src').split("?")[0];src.push(href)});self.posts.push({loc: src,title: "page" + page.page});console.log('分析页面数据成功,共%d张图片'.info, $posts.length);callback(null, page.page);},/*** 下载全部图片*/downAllImages(page, callback) {var async = node.async;console.log('开始全力下载所有图片,共%d篇', this.posts.length);async.eachSeries(this.posts, this.downPostImages.bind(this), callback);},/*** 下载单个页面的图片* @param {Object} post*/downPostImages(post, callback) {var async = node.async;async.waterfall([this.mkdir.bind(this, post),this.downImages.bind(this),], callback);},/*** 创建目录*/mkdir(post, callback) {var path = node.path;post.dir = path.join(this.options.saveTo, post.title);console.log('准备创建目录:%s', post.dir);if (node.fs.existsSync(post.dir)) {callback(null, post);console.log('目录:%s 已经存在'.error, post.dir);return;}node.mkdirp(post.dir, function(err) {callback(err, post);console.log('目录:%s 创建成功'.info, post.dir);});},/*** 下载post图片列表中的图片*/downImages(post, callback) {console.log('发现%d张图片,准备开始下载...', post.loc.length);node.async.eachLimit(post.loc, this.options.downLimit, this.downImage.bind(this, post), callback);},/*** 下载单个图片*/downImage(post, imgsrc, callback) {var url = node.url.parse(imgsrc);var fileName = node.path.basename(url.pathname);var toPath = node.path.join(post.dir, fileName);console.log('开始下载图片:%s,保存到:%s', fileName, post.dir);node.request(encodeURI(imgsrc)).pipe(node.fs.createWriteStream(toPath)).on('close', () => {console.log('图片下载成功:%s'.info, imgsrc);callback();}).on('error', callback);}
};
Spider.start();做一些对应的修改, 然后执行 node app.js
详细说明
var colors = require('colors');
colors.setTheme({silly: 'rainbow',input: 'grey',verbose: 'cyan',prompt: 'red',info: 'green',data: 'blue',help: 'cyan',warn: 'yellow',debug: 'magenta',error: 'red'
});上面的代码, 只是给console.log加个颜色, 好看点, 没其他用处
var node = {async: require('async'),cheerio: require('cheerio'),fs: require('fs'),mkdirp: require('mkdirp'),path: require('path'),request: require('request'),url: require('url')
};加载相关依赖
抓取网站图片的思路很简单, 先大概了解下目标网站的结构, 一般来说结构都是, 1个图片的目录页面, 1个图片的详细页, 当然也有一些网站, 没有目录页, 只有详细页, 这样就更简单了...
下面我们就以http://blog.naver.com/PostList.nhn?from=postList&blogId=tomiaaa 这个博客做例子
这个博客就是没有目录页, 所以抓起来也简单, 点击下分页, 就可以知道分页参数是什么, 这个博客的分页参数是currentPage
简单了解下, 网站结构, 就可以开始写代码了...
var Spider = {}先定义个对象
options: {// 网站地址uri: 'http://blog.naver.com/PostList.nhn?from=postList&blogId=tomiaaa¤tPage=',// 保存到此文件夹saveTo: './tomiaaa',// 从第几页开始下载startPage: 1,// 到第一页结束endPage: 388,// 图片并行下载上限downLimit: 2
}
posts: [],把一些配置文件写一下, posts这个数组, 用来存后面抓到的数据
start() {var async = node.async;async.waterfall([this.getPages.bind(this),this.downAllImages.bind(this)], (err, result) => {if (err) {console.log('error: %s'.error, err.message);} else {console.log('success: 下载完毕'.info);}});
},我们用async.waterfall来控制流程, 这里主要执行2个函数, this.getPages.bind(this)用来抓取页面, 获取图片的地址, this.downAllImages.bind(this)用来把图片下载到本地
getPages(callback) {var async = node.async;var i = this.options.startPage || 1;async.doWhilst((callback) => {var uri = this.options.uri + '' + i;async.waterfall([this.downPage.bind(this, uri, i),this.parsePage.bind(this)], callback);i++;}, (page) => this.options.endPage > page, callback);
},我们用doWhilst来循环抓取所有页面, (page) => this.options.endPage > page的作用是, 当page大于我们设置的最大页数时, 停止抓取
每抓一个页面, 我们分成2个步骤, 1是this.downPage.bind(this, uri, i)抓取html文档, 2是this.parsePage.bind(this)将html文档解析, 并提取出文档中的图片地址
downPage(uri, curpage, callback) {console.log('开始下载页面:%s', uri);var options = {url: uri,headers: {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.54 Safari/537.36','Cookie': 'lang_set=zh;'}};node.request(options, (err, res, body) => {if (!err) console.log('下载页面成功:%s'.info, uri);var page = {page: curpage,uri: uri,html: body};callback(err, page);});
}这个函数就是用request来抓取html文档, 其中options.url是抓取页面的链接, 这个会从上面的循环中传过来, options.headers主要定义请求头, 可以设置浏览器ua, cookies等等, 如果抓取需要登录的页面, 那么这里的cookies就必须要设置了, 将抓取到的html文档,当前页数,地址等信息通过callback返回去
parsePage(page, callback) {console.log('开始分析页面数据:%s', page.uri);var $ = node.cheerio.load(page.html);var $posts = $('._photoImage');var self = this;var src = [];$posts.each(function() {var href = $(this).attr('src').split("?")[0];src.push(href)});self.posts.push({loc: src,title: "page" + page.page});console.log('分析页面数据成功,共%d张图片'.info, $posts.length);callback(null, page.page);
},这个函数的作用就是通过cheerio来解析页面, 执行var $ = node.cheerio.load(page.html);, 后面操作的方法和jq是一样一样的~~~将抓取到的图片地址存成数组, 写到之前定义好的posts数组中
这里需要将page.page传回去, 因为上面的doWhile需要这个值来判断是否到最后页
到这里getPages函数就结束了, 通过parsePage发回去的page.page, 不断循环,判断 直到将所有页面抓取完毕
页面都抓取完了, 图片地址也都有, 那么剩下的就是用downAllImages把图片保存到本地了
downAllImages(page, callback) {var async = node.async;console.log('开始全力下载所有图片,共%d篇', this.posts.length);async.eachSeries(this.posts, this.downPostImages.bind(this), callback);
},这回我们用async.eachSeries来循环我们之前存好的posts数组, 这个函数的格式和$.each很像, 简单说, 就是将posts里的每个对象按顺序放到this.downPostImages.bind(this)里执行一次
downPostImages(post, callback) {var async = node.async;async.waterfall([this.mkdir.bind(this, post),this.downImages.bind(this),], callback);
},还是用async.waterfall来控制流程, 先创建子目录, 然后下载图片
mkdir(post, callback) {var path = node.path;post.dir = path.join(this.options.saveTo, post.title);console.log('准备创建目录:%s', post.dir);if (node.fs.existsSync(post.dir)) {callback(null, post);console.log('目录:%s 已经存在'.error, post.dir);return;}node.mkdirp(post.dir, function(err) {callback(err, post);console.log('目录:%s 创建成功'.info, post.dir);});
},通过我们设置的根目录和抓取到title创建子目录
downImages(post, callback) {console.log('发现%d张图片,准备开始下载...', post.loc.length);node.async.eachLimit(post.loc, this.options.downLimit, this.downImage.bind(this, post), callback);
},这里用async.eachLimit来控制循环, 和async.eachSeries差不多, 不过eachLimit可以设置并发, 如果这个函数的第二个参数设置成1, 那么就和async.eachSeries完全一样了, 将post.loc里的图片, 按顺序放到this.downImage.bind(this, post)里执行
downImage(post, imgsrc, callback) {var url = node.url.parse(imgsrc);var fileName = node.path.basename(url.pathname);var toPath = node.path.join(post.dir, fileName);console.log('开始下载图片:%s,保存到:%s', fileName, post.dir);node.request(encodeURI(imgsrc)).pipe(node.fs.createWriteStream(toPath)).on('close', () => {console.log('图片下载成功:%s'.info, imgsrc);callback();}).on('error', callback);
}通过url,path等插件, 读取图片名称, 通过request抓取图片, 用fs将图片保存到本地