中文编程,用python编写小说网站爬虫 - 乘风龙王的文章 - 知乎 https://zhuanlan.zhihu.com/p/51309019
我比较喜欢看小说,在网络上看小说一般有2种选择,正版或盗版。正版要钱,盗版要么只能在线阅读,要么下载下来一堆广告。既然学了python就应该写点爬虫练练手,把网络小说爬下来。
本文章需要的python第三方库:
- requests(获取网页内容)
- BeautifulSoup4(解析网页内容)
本文章需要读者具备python基础知识,并且我不会对文章中所出现的标准库、第三方库的每个类/函数的作用进行解释,请大家自行查阅资料。我不会对代码中的中文命名进行解释。
寻找目标
由于那些著名的小说网站具有很强的版权意识,防盗版措施做得很好,要把小说内容爬下来不是很容易。所以我选择一个盗版小说网站作为爬虫目标。

嗯,全是盗版。
首先编写代码获取文档内容。
from bs4 import BeautifulSoup #beautifulsoup4
import requests #requestsdef f创建解析器(a文本):return BeautifulSoup(a文本, "html.parser")
def f获取文档(a地址):v请求 = requests.get(url = a地址)v页面 = v请求.textreturn v页面打开其中一本小说目录页,记住地址,然后调用 f获取文档 测试代码是否可以运行。

看起来只输出了一半内容,实际上 v文档 已经包含了所有内容,只不过是字符串太长了被print截断而已。
框架
浏览一下小说网站结构,每个小说页面可以分为目录页、正文页。
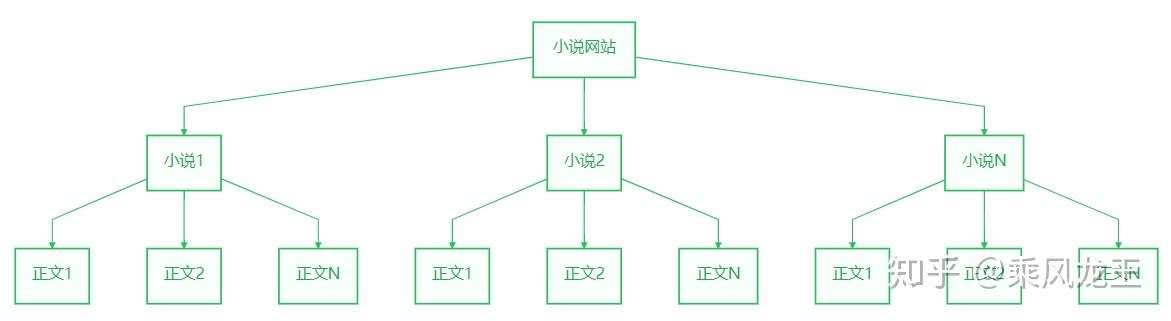
设计2个接口,分别取名 I小说 和 I章节,I小说 用来提取小说信息和目录,I章节 用来提取章节信息和小说正文。同时定义 I文档,负责从网站上获取文档
class I文档:def __init__(self):self.m文档 = Nonedef f重新载入(self):self.m文档 = f创建解析器(f获取文档(self.fg地址()))def f载入(self):if not self.m文档:self.f重新载入()def fg地址(self):raise NotImplementedError()
class I小说:def __init__(self):I文档.__init__(self)def fe目录(self):"返回(章节名, I章节 对象)"raise NotImplementedError()
class I章节:def __init__(self):I文档.__init__(self)def fg正文(self):"返回字符串"raise NotImplementedError()提取目录
先查看一下目录页的内容


从图中可以看到,目录最前面有最新章节,目录最后还有重复章节,这些都是需要去除掉的,保留从正文卷开始的章节。

检查网页元素后可知道,目录包含在<div class="listmain">元素中,章节链接藏在<dd>元素里。然后开始写代码:
c地址前缀 = "https://www.xxxx.com"
class C小说(I文档, I小说):c章节列表类名 = "listmain"def __init__(self, a地址):I文档.__init__(self)I小说.__init__(self)self.m地址 = a地址def fg地址(self):return self.m地址def fe目录(self):self.f载入()v目录元素 = self.m文档.find(name = "div", class_ = C小说.c章节列表类名)va章节列表 = v目录元素.find_all(name = "dd")#去除前面的最新章节和最后的重复章节va章节列表 = va章节列表[12:]for v in va章节列表:v链接 = v.a.get("href") #章节链接v文本 = v.a.string #章节名if "xxxx" in v文本: #去除最后的重复章节continueyield v文本, C章节(c地址前缀 + v链接)
class C章节(I文档, I章节):def __init__(self, a地址):I文档.__init__(self)I章节.__init__(self)self.m地址 = a地址def fg地址(self):return self.m地址提取目录的代码很简单,把上面提到的<div>找出来,再遍历<dd>元素,去除重复项。注意<a>元素的href属性不包含域名,所以创建章节对象时要把地址前面部分加上。
修改一下主函数,运行代码

似乎还有重复章节。我点开一些重复章节看了一下,地址不一样但是内容是一样的,应该是网站录入时出了问题。这个我就不管了。
提取正文
提取完目录后,再看一下正文页。


发现正文最底下有广告链接,这个也要去掉。
分析网页元素,可以知道正文全部包含在<div id="content" class="showtext">这个元素中,只要把这个元素找出来,取字符串,过滤广告就行了。
class C章节(I文档, I章节):c正文标识名 = "content"def __init__(self, a地址):I文档.__init__(self)I章节.__init__(self)self.m地址 = a地址def fg地址(self):return self.m地址def fg正文(self):self.f载入()v正文元素 = self.m文档.find("div", id = C章节.c正文标识名)v正文文本 = ""for v行 in v正文元素.strings:if "xxxx" in v行: #去除广告continuev正文文本 += v行 + "\n"return v正文文本修改主函数测试代码是否可用
c章节地址 = "https://www.xxxx.com/xxxx/xxxx.html"
def main():v章节 = C章节(c章节地址)print(v章节.fg正文())
从运行结果看,爬到的正文有空行有缩进。虽然没有问题,但是小说最终是要放进阅读器里慢慢看的,并不是所有的阅读器都能正确处理空行和缩进,所以还要在代码里对正文进一步处理。
写一个函数叫 f处理正文,负责处理乱七八糟的空行和缩进
import re
c开头缩进正则 = re.compile(r"^\s")
def f处理正文(a文本):v正文文本 = a文本v正文文本 = c开头缩进正则.sub("\n", v正文文本) #清除缩进v正文文本 = v正文文本.replace("\xa0", "") #清除缩进v正文文本 = v正文文本.replace("\u3000", "") #清除缩进v正文文本 = v正文文本.replace("\r", "\n") #v正文文本 = v正文文本.replace("\n \n", "\n") #清除多余换行while "\n\n" in v正文文本:v正文文本 = v正文文本.replace("\n\n", "\n") #清除多余换行return v正文文本然后修改 C章节.fg正文,在返回字符串时做一些处理
return f处理正文(v正文文本)这样看起来好多了。
保存
确认可以爬到目录和正文之后,接下来就是把正文保存到电脑上。
def f一键下载(a小说, a保存路径):v小说名 = a小说.fg小说名()#路径v路径 = pathlib.Path(a保存路径)v路径 /= v小说名 + ".txt"v文件名 = str(v路径)print("保存到: " + v文件名)v文件 = open(v文件名, "w", encoding = "utf-8")#循环for v章节名, v章节 in v小说.fe目录():v正文 = v章节.fg正文()v文件.write(v章节名 + "\n" + v正文 + "\n")time.sleep(1) #访问太频繁会被服务器阻止访问,所以加个等待print("下载完成")在实际测试中,网站经常返回503。如果在代码里增加错误重试功能会导致代码变得又臭又长,这里我就不写了。
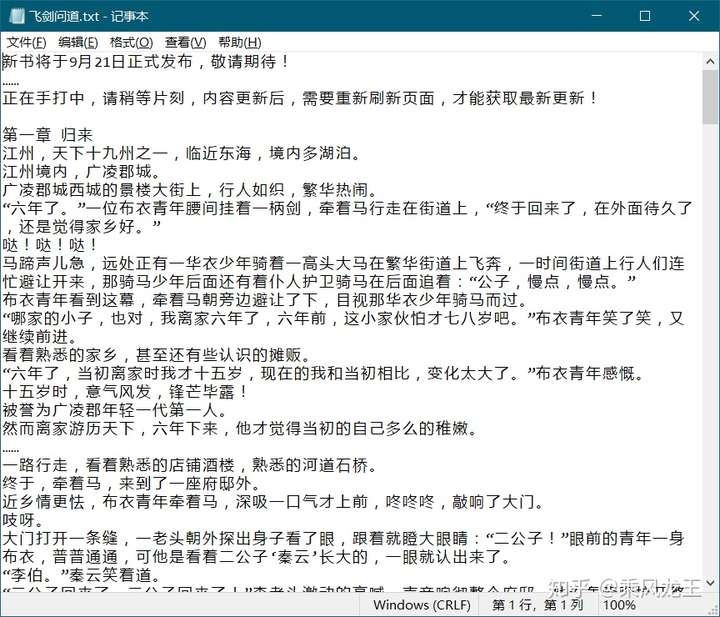
打开下载下来的文本文件看看。因为网站经常503,只爬了前几章就断掉了,所以没爬完。
结尾
上面的代码可以从一个特定的小说网站下载小说。但是这个网站是盗版小说网站,容易被封掉。或者有各式各样的理由需要从另外一个网站下载小说呢?
由于上面已经写过一些代码了,只需要照葫芦画瓢,重新写个 C小说 和 C章节 就行了。其他什么都不用动。
文章里的代码省略了很多细节,比如HTTP请求头、文档编码处理、异常处理,只保留最重要的爬虫代码。完整代码我发到了github上,见:https://github.com/cflw/cflw_py。
最后请大家以学习研究为目的写爬虫,毕竟爬别人的劳动成果是不好的,请大家多多支持正版。