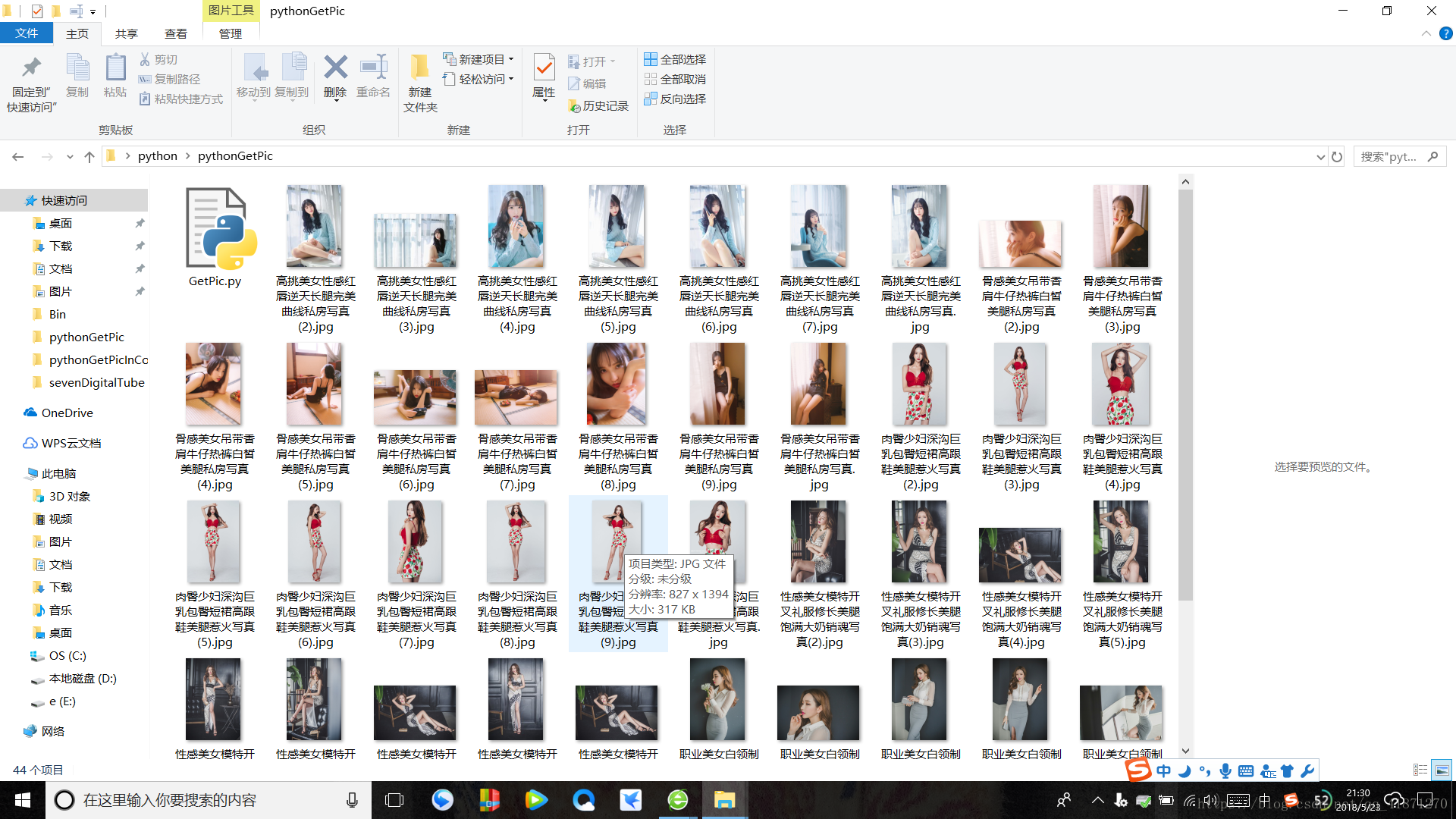
怎么通过主页面的超链接来获取这个网站的照片呢?这里以23730为例子
接下来我们分析一下编写的过程:
第一步:在目录页面得到所有主页面的url
第二步:把这个url放在列表中
第三步:得到照片的url链接放到一个列表中
第四步:得到照片的名字放到一个列表中
第五步:将照片url的列表遍历并且发送request请求,写入文件。
并且文件的名字为照片名字
所以定义4个函数:
defget_content_url(list_con):
这个函数的任务就是得到目录下的所有url
defget_pic_url(List_pic,html):
这个函数的任务是得到所有的照片链接
defget_pic_name(List1_name,html):
得到照片的名字
defwrite_pic(List,List1):
将照片下载到文档中,并且文件的名字就是照片的名字
最后定义一个main函数用来调用所有的函数。
好了,开始第一个函数的编写:
def get_content_url(list_con):
url='http://www.27270.com/tag/63.html'#这是我要下载照片网站的主页urlhtml=requests.get(url)html.encoding='gbk'#将编码该为GBK是为了获取接下来的中文做准备soup=BeautifulSoup(html.text,'lxml')con_url=soup.find_all('a')j=0for i in con_url:#j用来计数,当j的值为30的时候退出这个循环,#因为这个目录有40个照片而我只需要前面30个try:href=i['href']if'http://www.27270.com/ent/meinvtupian/'in href and '.html'in href:#因为最主要的图片的url要满足这2个条件print(href)list_con.append(href[0:48])’’’我只需要他的url而不需要别的东西,href[0:48]就是把他的url给截取出来’’’j=j+1except:continueif(j==30):Break
Ok,第一个函数做完了接下来就是制作得到所有照片链接的函数了
def get_pic_url(List_pic,html):soup=BeautifulSoup(html,'lxml')src=soup.find_all('img')#找所有的img形式的照片try:for i in src:link=i['src']#找src属性的链接if'http://t2.hddhhn.com/uploads/tu/'and '9999'in link:#这是我要的照片的条件List_pic.append(link)except:print('错误')接下来得到照片的名字
def get_pic_name(List1_name,html):soup=BeautifulSoup(html,'lxml')title=soup.find_all('h1',class_="articleV4Tit")name=''.join('%s' %i for i in title)#将列表里面的东西字符化,不然用不了replacename=name.replace('h1','')#将一些杂七杂八的东西丢掉name=name.replace('class="articleV4Tit"','')name=name.replace('</>','')name=name.replace('< >','')List1_name.append(name)#最后放到列表中好了,接下来就是设置写入函数了
def write_pic(List,List1):for i in range(len(List)):#之所以不用for i in List 是为了接下来的提示try:html=requests.get(List[i])with open(List1[i]+'.jpg','wb') as f:f.write(html.content)print('第%d张写入成功'%i)#这就是为什么不用for i in Listf.close()except:print('第%d张写入失败'%i)continuereturn ''Now,就让我们开始编写主函数main()
def main():list_pic=[]list_name=[]list_con=[]get_content_url(list_con)for j in list_con:for i in range(1,10):#我是下载这个套图的前面10章照片url=j+'_'+str(i)+'.html'html=requests.get(url)html.encoding='gbk'html=html.textget_pic_url(list_pic,html)get_pic_name(list_name,html)write_pic(list_pic,list_name)print(list_pic)print(list_name)list_pic=[]’’’为什么要将这两个列表初始化?因为我已经收集了一套的图片,如 果我不初始化的话,函数依然会调用那些我已经收集照片的url, 这就造成了资源的浪费’’’list_name=[]最后调用main()函数
接下来给出所有的代码,注意!网站会更新它的系统,也就是说会更新它的代码!!!所以这个方法如果不行的话,是网站的原因不是我的原因,我自己是下载了的!
import requests
import re
from bs4 import BeautifulSoup
'''
第一步:在目录页面得到所有主页面的url
第二步:把这个url放在列表中
第三步:得到照片的url链接放到一个列表中
第四步:得到照片的名字放到一个列表中
第五步:将照片url的列表遍历并且发送request请求,写入文件。并且文件的名字为照片名字
'''
def get_content_url(list_con):url='http://www.27270.com/tag/63.html'html=requests.get(url)html.encoding='gbk'soup=BeautifulSoup(html.text,'lxml')con_url=soup.find_all('a')j=0for i in con_url:#j用来计数,当j的值为30的时候退出这个循环,#因为这个目录有40个照片而我只需要前面30个try:href=i['href']if'http://www.27270.com/ent/meinvtupian/'in href and '.html'in href:print(href)list_con.append(href[0:48])j=j+1except:continueif(j==30):breakdef get_pic_url(List_pic,html):soup=BeautifulSoup(html,'lxml')src=soup.find_all('img')try:for i in src:link=i['src']if'http://t2.hddhhn.com/uploads/tu/'and '9999'in link:List_pic.append(link)except:print('错误')def get_pic_name(List1_name,html):soup=BeautifulSoup(html,'lxml')title=soup.find_all('h1',class_="articleV4Tit")name=''.join('%s' %i for i in title)name=name.replace('h1','')name=name.replace('class="articleV4Tit"','')name=name.replace('</>','')name=name.replace('< >','')List1_name.append(name)def write_pic(List,List1):for i in range(len(List)):try:html=requests.get(List[i])with open(List1[i]+'.jpg','wb') as f:f.write(html.content)print('第%d张写入成功'%i)f.close()except:print('第%d张写入失败'%i)continuereturn ''def main():list_pic=[]list_name=[]list_con=[]get_content_url(list_con)for j in list_con:for i in range(1,10):url=j+'_'+str(i)+'.html'html=requests.get(url)html.encoding='gbk'html=html.textget_pic_url(list_pic,html)get_pic_name(list_name,html)write_pic(list_pic,list_name)print(list_pic)print(list_name)list_pic=[]list_name=[]main()