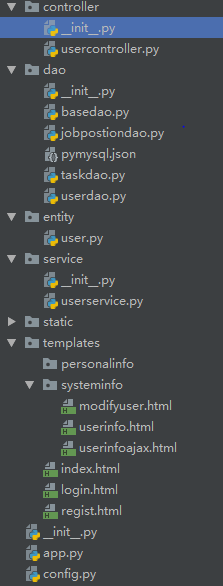
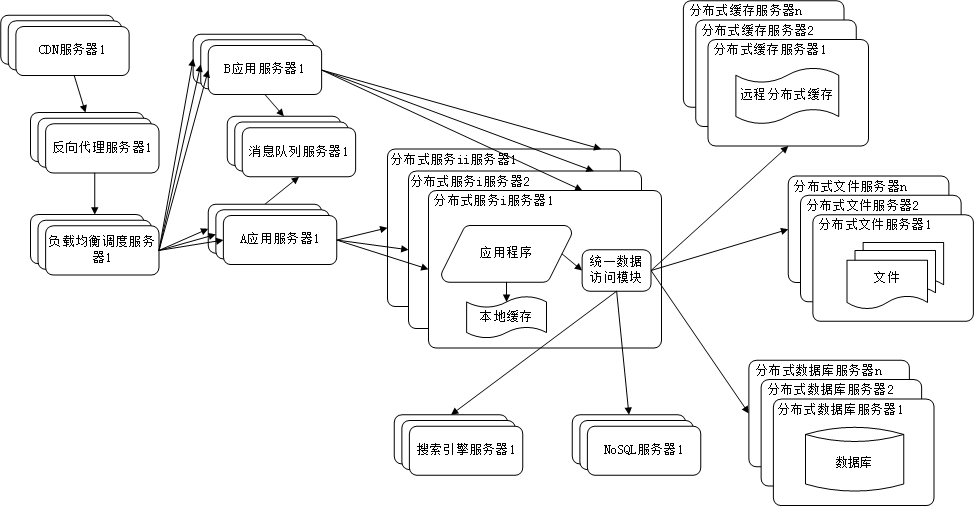
继上一篇的博客scrapy准备工作完成后,今天正式开始scrapy的爬虫项目
ps:先看上一篇博客
scrapy项目----------爬取hao123影视
一、分析各文件含义
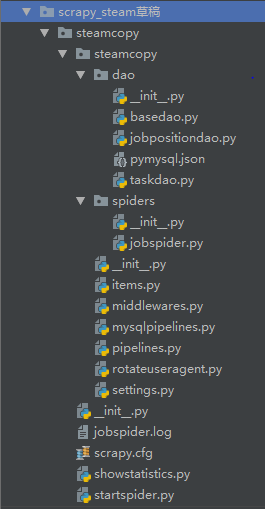
---->所有的__init__.py文件
无实意,内部没有内容,主要用于同一目录下的文件间的互相调用,下面的‘代码实现’中会提到!
---->dao包是手动添加的,里面的文件主要用于与数据库连接
–>basedao.py文件,连接数据库的万金油文件,可直接使用,与pymysql.json文件联用。
–>jobpositiondao.py文件,主要用于创建主要表和详情表(扩展,添加其他方法,sql语句(select),在showstatistics.py文件中可实现,而不存入数据库中),用basedao.py里的方法。
–>pymysql.json文件,连接数据库的具体信息,端口,密码,用户名,ip之类的,只需要改改内容即可。
–>taskdao.py文件,主要用于创建任务表,用basedao.py里的方法。
---->spiders包是自动生成的
–>jobspider.py文件是主程序文件,信息爬取的代码写在此文件里
---->底层steamcopy包
–>items.py文件,是保存爬取到的数据的容器,使用方法与字典类似,将定义字典items,将各key值(要爬取的数据名)通过scrapy.Field()定义。
–>middlewares.py文件,自动生成的,不需要改,在settings.py文件中打开,后面设置代理头的时候还需要将原端口关闭,设置新的。(settings.py文件中详解)
–>mysqlpipelines.py文件,通道,用于将爬取的数据存入数据库,大体结构复制的pipelines.py文件,在settings.py文件中打开pipelines的开关,添加此文件。(settings.py文件中详解)
–>pipelines.py文件,通道,将数据通过控制台输出,可直接看,在settings.py文件中打开。
–>rotateuseragent.py文件,创建动态代理列表,随机选取列表中的用户代理头部信息,伪装请求,防止被封ip,手动添加(可直接使用)
–>settings.py文件,项目的设置文件,内部含已定义的,打开,该添加的添加。(第一步就应该先配置此文件)
---->外层steamcopy包
–>jobspider.log文件,日志文件,将日志信息打印在此,需要在settings.py文件中设置
–>scrapy.cfg文件,项目的配置文件,主要用于连接settings.py文件和主程序文件,是自动生成的,不需要修改。
–>showstatistics.py文件,手动添加的,实现某sql语句,sql语句是在jobpositiondao.py文件中定义的某方法,直接调用可输出。(不进入数据库,可以不写)
–>startspider.py文件,是爬虫启动脚本,设置完后就不用在cmd输入scrapy crawl jobspider来启动了。
二、各文件代码实现
---->basedao.py
import pymysql
import json
import osclass basedao(): #dao:database access object的缩写,主要用于数据库方面的代码应用def __init__(self, configFile='pymysql.json'):self.__connection = Noneself.__cursor = Noneself.__config = json.load(open(os.path.dirname(__file__) + os.sep + configFile, 'r')) # 通过json配置获得数据的连接配置信息(地址用相对的)print(self.__config)pass# 专门用来获取数据库连接的函数方法def getConnection(self):if self.__connection: #如果有连接对象return self.__connection #直接返回连接对象,try:self.__connection = pymysql.connect(**self.__config)#不然,创建新的连接对象return self.__connectionexcept pymysql.MySQLError as e:print("Exception:"+str(e))passpass#用于执行sql语句的通用方法(增删改查) #sql注入的问题def execute(self,sql,params):try:self.__cursor = self.getConnection().cursor()result = self.__cursor.execute(sql,params)return result#print(result) 查的话,需要输出,其他的result是int整数(是修改成功的条数)except (pymysql.MySQLError,pymysql.DatabaseError,Exception)as e:print("出现数据库访问异常" + str(e))self.rollback() #回滚passpass#一般在select的sql语句时用def fetch(self):if self.__cursor:return self.__cursor.fetchall()pass#提交事务,每个sql语句都需要提交然后运行,紧接着closedef commit(self):if self.__connection:self.__connection.commit()pass#回滚,出错的话就返回之前的状态def rollback(self):if self.__connection:self.__connection.rollback()pass#获取最后一行的id标识(用于主要表与详情表的1对1关系)def getLastRowId(self):if self.__cursor:return self.__cursor.lastrowidpass#关闭(只要打开了就需要关闭,否则很快数据库就会报错)def close(self):if self.__cursor:self.__cursor.close()if self.__connection:self.__connection.close()pass
---->pymysql.json
{"host":"127.0.0.1","user" : "root","password" : "root","database" : "db_web_steam","port": 3306,"charset" : "utf8"}
//自动登陆数据库,
//分别是 ip地址、用户名、密码、数据库名、端口、语言
//直接用的话:需要改 host(默认127.0.0.1) user password database(定义的数据库名,建数据库时注意保持一致) port(默认都是3306) charset(不能有‘-’)
---->taskdao.py
from .basedao import basedao #调用同一目录下的basedao类,以便于用里面的方法class TaskDao(basedao): #继承父类才可以调用各种方法def create(self, params):sql = "insert into task (task_title, task_url) values (%s, %s)" #sql语句,创建任务表result = self.execute(sql, params)lastRowId = self.getLastRowId()self.commit() #提交self.close() #关闭return result, lastRowIdpasspass
---->jobpositiondao.py
from .basedao import basedao # . '点' 代表当前文件夹#定义一个操作电影数据的数据库访问类
class steamdao(basedao): #继承basedao.py,直接调用已封装好的方法def __init__(self):super().__init__() #用super调用父类的init方法pass#向数据库插入电影信息def create(self,params):sql = "insert into steam(steamname,steamtime,steamweb,steamnote,taskid,steamplayer) values(%s,%s,%s,%s,%s,%s)" #创建主表result = self.execute(sql,params)lastRowId = self.getLastRowId()self.commit()return result,lastRowIddef createdetail(self,params):sql = "insert into detail(detail_desciption,detail_positionid) values(%s,%s)" #该表与主表1对1,可以不建,建的话,通过lastrowid同步,以免信息错误result = self.execute(sql,params)self.commit()return resultpassdef PositionClassify(self): #在showstatistics.py中调用该方法返回对应的数据内容,查找不用新建表sql = "select t1.steamname,t2.task_title,t1.steamnote,t1.taskid from task t2 left join steam t1 on t1.taskid = t2.task_id order by t1.steamnote desc"result = self.execute(sql,params=None)self.commit()return self.fetch() #查找用fench方法passpass
---->startspider.py
#此脚本是爬虫启动脚本 不用在cmd输入scrapy crawl jobspiderfrom scrapy.cmdline import execute
from scrapy_steam草稿.steamcopy.steamcopy.dao.taskdao import TaskDao #调用任务表
#启动爬虫
td = TaskDao()
result,taskid = td.create(('日本电影','http://v.hao123.baidu.com/v/search?channel=movie&area=%E6%97%A5%E6%9C%AC&pn=1'))
if result:execute(['scrapy','crawl','jobspider','-a','start_urls=http://v.hao123.baidu.com/v/search?channel=movie&area=%E6%97%A5%E6%9C%AC&pn=1','-a','taskid=' + str(taskid)])passresult,taskid = td.create(('印度电影','http://v.hao123.baidu.com/v/search?channel=movie&area=%E5%8D%B0%E5%BA%A6&pn=1'))
if result:execute(['scrapy','crawl','jobspider','-a','start_urls=http://v.hao123.baidu.com/v/search?channel=movie&area=%E5%8D%B0%E5%BA%A6&pn=1','-a','taskid=' + str(taskid)])pass'''用线程启动程序
# coding:utf-8
import threading# 在项目外用脚本启动爬虫
from twisted.internet import reactor
from scrapy.crawler import CrawlerRunner
from scrapy.settings import Settings# 配置文件在这里手动实现
def runSpider():settings = Settings({'SPIDER_MODULES': ['jobspiders.spiders'],'ROBOTSTXT_OBEY': False,'SPIDER_MIDDLEWARES': {'jobspiders.middlewares.JobspidersSpiderMiddleware': 543},# 启用pipelines组件'ITEM_PIPELINES': {'jobspiders.pipelinesmysql.JobspidersPipeline': 400, },'DOWNLOADER_MIDDLEWARES': {'jobspiders.middlewares.JobspidersDownloaderMiddleware': 543,'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware': None, # 这一行是取消框架自带的useragent'jobspiders.rotateuseragent.RotateUserAgentMiddleware': 400 },'CONCURRENT_REQUESTS': 1, #'DOWNLOAD_DELAY': 5 #})runner = CrawlerRunner(settings) # 通过程序对爬虫进行设置d = runner.crawl('jobsspider') # 启动爬虫d.addBoth(lambda _: reactor.stop())reactor.run()return 0def spiderThread():# 启动线程执行爬虫程序threading.Thread(target=runSpider())if __name__ == '__main__':spiderThread()
'''
---->showstatistics.py
from scrapy_steam草稿.steamcopy.steamcopy.dao.jobpositiondao import steamdao #调用数据库访问类jp = steamdao() #调用类的方法
print(jp.PositionClassify()) #输出此方法(sql语句)的结果
jp.close() #记得关闭
---->settings.py(将我打开的都打开,添加的按照同样格式添加,注意名字要改对,否则报错)
# -*- coding: utf-8 -*-# Scrapy settings for steamcopy project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://doc.scrapy.org/en/latest/topics/settings.html
# https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
# https://doc.scrapy.org/en/latest/topics/spider-middleware.htmlBOT_NAME = 'steamcopy'SPIDER_MODULES = ['steamcopy.spiders']
NEWSPIDER_MODULE = 'steamcopy.spiders'# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'steamcopy (+http://www.yourdomain.com)'# Obey robots.txt rules
ROBOTSTXT_OBEY = False #打开,防止有些网站爬取不了# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32# Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 3 #打开,不要太大(数据多太慢),也不要太小(容易被封),
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16# Disable cookies (enabled by default)
#COOKIES_ENABLED = False# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}# Enable or disable spider middlewares
# See https://doc.scrapy.org/en/latest/topics/spider-middleware.html
SPIDER_MIDDLEWARES = {'steamcopy.middlewares.SteamcopySpiderMiddleware': 543,
}# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {'steamcopy.middlewares.SteamcopyDownloaderMiddleware': 543,'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware': None, # 这一行是取消框架自带的useragent(请求头)'steamcopy.rotateuseragent.RotateUserAgentMiddleware': 400 #rotateuseragent文件,提供代理头,防止被封ip
}# Enable or disable extensions
# See https://doc.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {'steamcopy.pipelines.SteamcopyPipeline': 300,'steamcopy.mysqlpipelines.SteamcopyPipeline': 301 #将数据输入进数据库中
}# Enable and configure the AutoThrottle extension (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
AUTOTHROTTLE_DEBUG = False #变成False后才不会有各种debug影响心情# Enable and configure HTTP caching (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'#将日志输出到文件(先不要设置,否则报错无法点哪里错,只能看,把下面这两行先注释掉)
LOG_LEVEL = 'ERROR'
LOG_FILE = 'jobspider.log'
---->rotateuseragent.py(不需要修改,直接复制代码即可)
# -*- coding: utf-8 -*-
__author__ = "中软国际教育科技·CTO办公室"
__date__ = "2017年5月15日 10时49分"# 导入random模块
import random
# 导入useragent用户代理模块中的UserAgentMiddleware类
from scrapy.downloadermiddlewares.useragent import UserAgentMiddleware# RotateUserAgentMiddleware类,继承 UserAgentMiddleware 父类
# 作用:创建动态代理列表,随机选取列表中的用户代理头部信息,伪装请求。
# 绑定爬虫程序的每一次请求,一并发送到访问网址。# 发爬虫技术:由于很多网站设置反爬虫技术,禁止爬虫程序直接访问网页,
# 因此需要创建动态代理,将爬虫程序模拟伪装成浏览器进行网页访问。
class RotateUserAgentMiddleware(UserAgentMiddleware):def __init__(self, user_agent=''):self.user_agent = user_agentdef process_request(self, request, spider):#这句话用于随机轮换user-agentua = random.choice(self.user_agent_list)if ua:# 输出自动轮换的user-agentprint(ua)request.headers.setdefault('User-Agent', ua)# the default user_agent_list composes chrome,I E,firefox,Mozilla,opera,netscape# for more user agent strings,you can find it in http://www.useragentstring.com/pages/useragentstring.php# 编写头部请求代理列表user_agent_list = [\"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"\"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",\"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",\"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",\"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",\"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",\"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",\"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",\"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",\"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",\"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",\"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",\"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",\"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",\"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",\"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",\"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",\"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"]
---->items.py
# -*- coding: utf-8 -*-# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.htmlimport scrapyclass SteamcopyItem(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()steamname = scrapy.Field() # 定义key,即爬取数据的名字,放在item字典里steamtime = scrapy.Field()steamweb = scrapy.Field()steamnote = scrapy.Field()detailURL = scrapy.Field()nextURL = scrapy.Field()detail = scrapy.Field()taskid = scrapy.Field()pass---->pipelines.py
# -*- coding: utf-8 -*-# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.htmlclass SteamcopyPipeline(object):def process_item(self, item, spider):print('通过管道输出数据') #将爬取到的数据在控制台输出print(item['steamname'])print(item['steamtime'])print(item['steamweb'])print(item['steamnote'])print(item['detail'])return item
---->mysqlpipelines.py
# -*- coding: utf-8 -*-# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
from scrapy_steam草稿.steamcopy.steamcopy.dao.jobpositiondao import steamdaoclass SteamcopyPipeline(object):def process_item(self, item, spider):steams = steamdao() # 定义一个对象try:steamtime = item['steamtime']steamplayer = steamtime.split(':')[1]result,lastRowId = steams.create((item['steamname'], item['steamtime'], item['steamweb'], item['steamnote'],item['taskid'],steamplayer)) # 调用create方法,将爬取的数据输入进数据库中if result:steams.createdetail((item['detail'],lastRowId)) #lastrowid是为了保证steam表和detail表的同步性(1对1),因为detail表其实可以不需要,直接在steam表中新加一列except Exception as e:print(e)finally:steams.close()return item
---->jobspider.py(主程序)
# -*- coding: utf-8 -*-
#主程序,改xpath地址即可改变要爬取的数据import scrapyfrom scrapy_steam草稿.steamcopy.steamcopy.items import SteamcopyItem #引入items文件的类class JobspiderSpider(scrapy.Spider):name = 'jobspider'start_urls = [] #在startspider文件中有就不用写了,赋初值为空列表def __init__(self, start_urls=None, taskid=0, *args, **kwargs):super(JobspiderSpider, self).__init__(*args, **kwargs)self.start_urls.append(start_urls)self.taskid = taskidpassdef parse(self, response):steamitems = response.xpath("//div[@class='result clearfix']/ul/li") # 返回的是xpath的选择器列表(所有需要爬取的数据所在的根目录)steamlen = len(steamitems) #下边用来判断一页内容是否爬取完毕的标志steamcount = 0nextURL = response.xpath("//div[@class='c-pagination clearfix']/a[@class='next-btn']/@href").extract() # 取下一页的地址nextText = response.xpath("//div[@class='c-pagination clearfix']/a[@class='next-btn']/text()").extract() #取‘下一页’这几个字# print(nextURL)realURL = ""if nextURL and nextText[-1].strip() == '下一页': #最后一页没有下一页,要避免这种情况realURL = response.urljoin(nextURL[-1])passfor steamitem in steamitems: # 遍历选择器列表steamcount += 1sitem = SteamcopyItem() # 引入类之后,定义一个对象sitem['taskid'] = self.taskid# 解析电影名称steamname = steamitem.xpath("a/span/text()")if steamname:sitem['steamname'] = steamname.extract()[0].strip() # extract返回字符串内容,选第一个,去掉首尾空格passsteamdetail = steamitem.xpath("a/@href") # 返回的是选择器(之所以和下面的地址相同,单纯的详情页需要电影地址,可以不爬电影地址,详情页不能改,除非有另一个链接可以跳转详情页)# 解析电影主演steamtime = steamitem.xpath("p/text()")if steamtime:sitem['steamtime'] = steamtime.extract()[0].strip()pass# 解析电影地址名称steamweb = steamitem.xpath("a/@href")if steamweb:sitem['steamweb'] = steamweb.extract()[0].strip()pass# 解析电影评分steamnote = steamitem.xpath("a/div/span/em/text()")if steamnote:sitem['steamnote'] = steamnote.extract()[0].strip()passif steamname and steamtime and steamweb and steamnote and steamdetail: # 生成器(判断是否全都不为空,如果网站本身的数据出错,那就不需要爬取)detailURL = steamdetail.extract()[0]sitem['nextURL'] = realURL #定义下一页的地址yield scrapy.Request(url=detailURL, callback=self.parse_detail, #callback调用下面的方法meta={'item': sitem, 'steamlen': steamlen, 'steamcount': steamcount},dont_filter=True,encoding='utf-8') # dont_filter是否去重复地址passpasspass# 定义爬取详情页的方法def parse_detail(self, response):sitem = response.meta['item']steamlen = response.meta['steamlen']steamcount = response.meta['steamcount']detaildata = response.xpath("//p[@class='abstract']") #二级页面(详情页)要爬的数据的根目录,即detail表中的数据所在的目录# print('detaildata:', detaildata) 检查是否爬到数据,xpath地址有没有写错if detaildata:contents = detaildata.xpath('em/text()') # 返回当前选择器ct = "" #定义空变量,赋值用if contents: #判断是否为空,即详情页中所需数据是否存在for temp in contents.extract(): #将数据按照规范格式输出,如果本身规范,可以不写if temp.strip() == "" or temp.strip() == "/": #可以用正则表达式continuect += temp + "\n"passsitem['detail'] = ctyield sitem # 保顺序(按照从上到下,不跳着爬取)pass# 判断当前页是否爬取完成了,完成就继续爬取下一页if steamlen == steamcount:if sitem['nextURL']:yield scrapy.Request(sitem['nextURL'], self.parse, dont_filter=False,encoding='utf-8')passpasspass三、MySQL建数据库,数据表(尽量不要添加外键,删数据不好删)
---->数据库名和数据表名
---->detail数据表(详情表:二级页面所需数据的的存储地方,不是必要的,在主要表加一列就不用建详情表了,建的话需要注意‘与主要表1对1的关系’)

---->steam数据表(主要表:一级页面所需数据的存储地方)
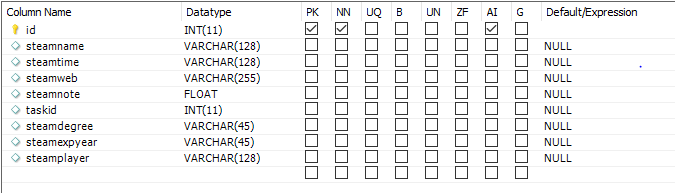
---->task数据表(任务表:所有的数据采集的项目都需要任务表,将所需要的数据任务列出来,’任务表对应多个主要表,是1对多的关系‘)
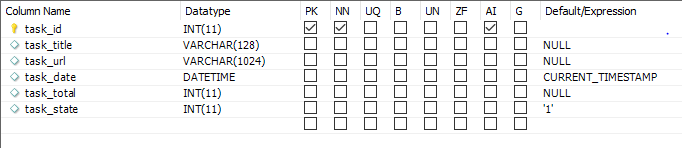
ps:数据表中的数据名与代码中存的相对应,保持一致!
至此,项目完成!
项目报告(未可视化)
点击上方连接转到项目报告获取界面(不黑不吹)