这篇文章是参考李智慧的《大型网站技术架构:核心原理与案例分析》和现蘑菇街CTO曽宪杰的《大型网站系统与Java中间件实践》写的一篇读书笔记。
前言
何谓大型网站?大型网站的特点是什么?大型网站架构发生演变的源动力是什么?大型网站的架构演变经历了哪些阶段?在演变的某个具体阶段使用到常用技术有哪些,为什么要使用这些技术,同时这些技术又解决了什么问题?笔者在初次接触大型网站时思考了以上几个问题,本着缘木求鱼的方式,我打算详细的扒一扒大型网站的演变史。如果对以上的几个问题都理解透彻了,那么可以说对大型网站也有一个基本的认识和理解了,但是我写这篇文章却不局限于此,在文章的后面会从一个中高级程序员的角度去思考,从大型网站的演变史可以得到哪些方法论和技术栈。由于笔者工作时间不长,所以我觉得思考这个问题是很有意思的。
下面将分别从以下几个方面谈谈大型网站:
- 何谓大型网站,大型网站相比非大型网站的特点有哪些?
- 大型网站发生演变的源动力
- 大型网站所历经的演变阶段
- 演变阶段所使用到的技术点
- 程序员价值观
大型网站的特点
从20世纪90年代第一个Web服务的出现,现在互联网的普及,也就短短20来年的时间。互联网极大的改变了人们的生活、学习、生活等方方面面,笔者清晰地记得在2011年刚上大学那会,用着中国移动龟速的2G怨声载道,到现在三大运营商大力推广并普及4G网络,再一次掀起了新一轮的互联网革命,当我们享受着网页秒开,看视频再也不卡的畅快时,却不知道背后的技术人员所付出的巨大努力。举个例子,现在大家人手必装的支付宝、淘宝等软件无不从一个小网站发展起来的,然后逐渐成为一个大型网站。那么大型网站的特点有哪些呢?
- 高并发,大流量
主要是指这类网站需要面对高并发、大流量访问。腾讯QQ的最大在线人数为1.4亿(2011年数据)。
- 高可用
因为高并发的访问,会使得服务器承受巨大的压力,一旦服务器出现过载那么很可能直接挂掉,然后,就没有然后了��。因此,高可用就显得尤为重要,需要保证网站7*24小时不间断提供服务。
- 海量数据
主要是指需要存储、管理海量数据。百度收录的网页数据有数百亿,Google有将近百万台服务器在提供服务。
源动力
既然大型网站是从小型网站发展起来的,那么是什么力量在推动着小网站逐渐向大型网站发展呢?
主要力量是业务的发展。从来没有哪个网站生来就是大型网站,业务驱动技术变革,技术变革反作用于业务,从而使得网站可以支撑业务的快速发展。所以,从CEO(CTO)的角度看,网站的价值在于它所为用户带来了什么,而不是网站是怎么形成的。需要为用户带来价值是因,网站的形成是果,这个因果关系是需要认清楚的。所以,技术从来不是单纯的技术(从价值的角度看),技术虽然可以解决大部分问题,但却不一定能够解决所有的问题。就12306网站售票的例子,如果早点使用分时段售票的做法,就没必要投入大量的技术人员解决这个问题。业务设计也是关乎网站价值的重要方面,所以不要为了技术而技术!
演变阶段
- 阶段一:单台服务器搞定一切
- 阶段二:应用服务与数据隔离
- 阶段三:使用缓存改善性能
- 阶段四:搭建应用服务器集群改善并发
- 阶段五:数据库读写分离减轻数据读写压力
- 阶段六:使用CDN和反向代理改善网站响应
- 阶段七:使用分布式文件系统和分布式数据库进一步改善读写压力
- 阶段八:使用NoSQL和搜索引擎优化检索性能
- 阶段九:业务拆分让网站维护更简单
- 阶段十:抽取公共服务
阶段一:单台服务器搞定一切
由于早期用户量不多,所以使用一台服务器就可以支撑业务。应用、数据、文件都在一台机器上完成。这个阶段的典型架构就是LAMP(Linux + Apache + MySQL + PHP(Java))。搞过开发的应该都经历过这个阶段。操作系统采用Linux,使用Java或者PHP作为开发语言,使用MySQL作为数据库,开发完后部署在Apache上。淘宝早期的架构也是这样的。
那会阿里因为开发资源不足,所以就购买了外国的一个网上商城,把源码和版权都买下了(花了大概几十万吧),那会的淘宝的架构就是LAMP架构。
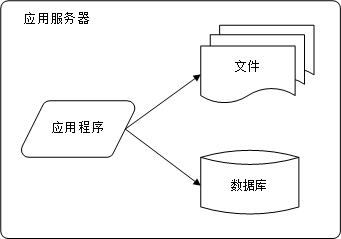
阶段二:应用服务与数据隔离
随着业务量的增长,存储的数据越来越多而造成存储空间的不足。这时候就把应用和数据拆分,分别部署在应用服务器、数据库服务器和文件服务器。应用服务器由于需要处理复杂的业务逻辑,因此需要更强大的CPU,数据库由于需要快速读写数据,因此需要更快的磁盘和更大的内存,文件服务器由于需要存储大量的数据,因此需要更大容量的硬盘。需要注意的是,虽然三台服务器承担了不同的角色,同时也大大改善了网站的性能,但是在整个应用中,需要的服务都是通过直连的方式完成的。直连的意思是指,当需要读写数据库的数据时,是直接访问的。虽然有压测数据表明,在不使用任何第三方组件直接使用MySQL的并发可以达到10000多。所以,如果并发数小于这个值,直连的方式也没有什么问题。所以,如果并发数超过了10k,那么数据库的压力就比较大了,造成的问题就是访问时延增大,进而影响整个网站的性能。
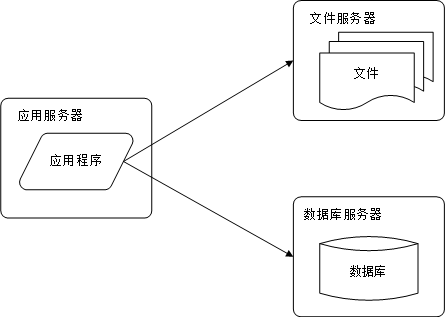
阶段三:使用缓存改善性能
根据“二八定律”:80%的业务访问集中在20%的数据上,也就是说这20%的数据是热点数据,访问频率相比其他数据大数倍甚至更多。所以,如果把这小部分的数据缓存在内存中,用户访问的时候直接从内存中取,就不需要通过数据库,从而大大降低数据库的访问压力。
通常而言,缓存可以分为本地缓存和部署在分布式服务器上的远程缓存。本地缓存存在于应用服务器所在的内存中,可能于应用数据发生争用的情况,而远程缓存则不会存在这种情况,因为所有的数据都是热点数据,没有干扰。本地缓存又可以分为浏览器缓存(Cookie)、操作系统缓存(如CPU的L1、L2和L3)、应用服务器的缓存(本地内存中)。通常可以使用ehcache作为本地缓存、Redis或者Memocached作为分布式缓存
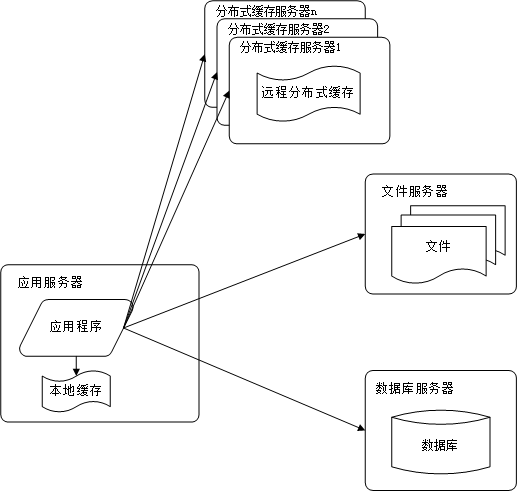
阶段四:搭建应用服务器集群改善并发
截至目前的演变,应用服务器仍然是单兵作战,虽然以上的演变大大改善额网站的性能,但是随着业务量的进一步上升,单台服务器的瓶颈就显现出来了,因为很可能因为负载过高导致应用服务器直接挂掉。这种情况下,更好的做法是使用增加服务器的方式水平扩展,这样就可以实现弹性伸缩,当负载过高的时候增加服务器,当负载降下来的时候,减少服务器。是不是很优雅?阿里在2012年提出的去“IOE”的原因之一就与这点有关。
IOE分别是指IBM、Oracle、EMC
虽然很优雅,但是应用服务器采用集群部署后,原来的请求过来的时候,如何知道调用哪台服务器完成请求呢?这就需要使用到负载均衡服务器了,干嘛的呢?就是负责将请求转发给某台服务器。负载均衡又包括硬负载和软负载。硬负载是硬件解决方案,比如F5,但是通常成本比较高,更常用的解决方案是软负载,就是通常软件实现负载均衡,比如LVS。
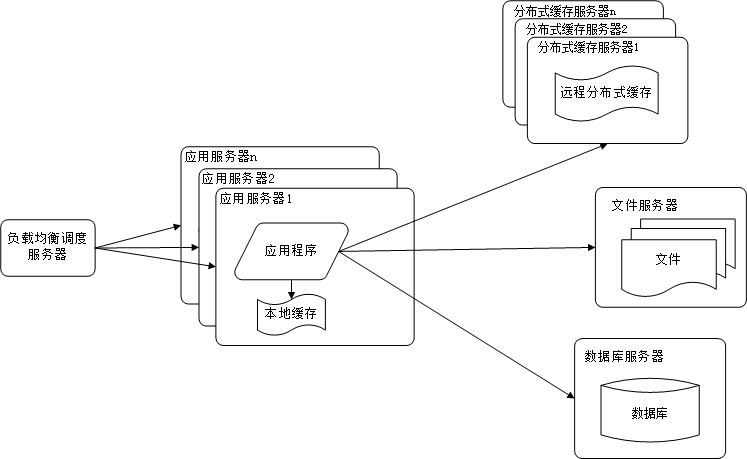
阶段五:数据库读写分离减轻数据读写压力
虽然之前使用缓存将热点数据缓存起来了,但是也存在缓存不命中的情况,这个时候又会直接访问数据库了,当缓存不命中的情况增大到一定规模的时候数据库的压力就又是一个问题了。我们知道都数据库进行的操作无非两种:读和写。由于数据库(比如MySQL)存在事务隔离级别和锁的机制,可能会导致读和写互相阻塞,那么如何实现数据库的读写分离呢?目前的思路将数据库进行主从拆分,所有的写操作操作主库,所有的读操作操作从库,对主库的更新操作会通过binlog同步到从库上,从而在从库也可以拿到最新的数据。如此一来,读写不再互相阻塞,性能至少提升1倍以上。就MySQL而言,主从热备的功能可以通过cobar、mycat之类的框架来完成。
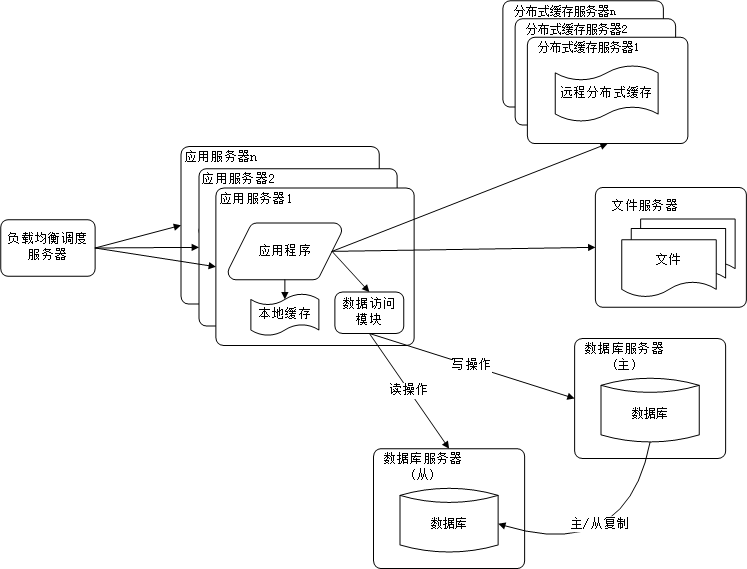
阶段六:使用CDN和反向代理改善网站响应
网站的响应又一个直观的指标(从用户的角度)—— 访问的快慢。这点直接关系到用户体验,因为如果用户执行一个请求老半天都没有响应,很可能就直接失去了这个用户,然后通过口啤效应,后果很严重。CDN和反向代理一种提高网站响应的手段。其基本原理都是缓存。CDN是部署再网络提供商所在的机房,当用户发起一个请求的时候,优先从距离其较近的网络提供商完成请求,而反向代理则是部署再网站的中心机房,当请求到达中心机房时,会首先由反向代理服务器完成请求,如果反向代理服务器存在请求的数据,那么直接返回数据给用户。
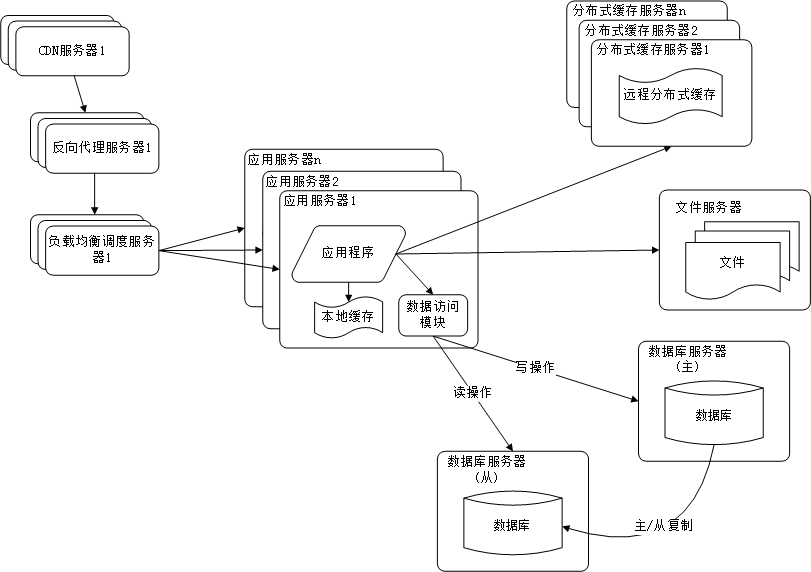
阶段七:使用分布式文件系统和分布式数据库进一步改善读写压力
当单表的数据量达到一定规模的时候,比如过千万,即使使用数据库索引进行优化,完成的性能提升也是有限的。因为当单表的数据量达到千万的时候受限于执行SQL的数据库引擎(比如MySQL的InnoDB),所以需要进行分库分表。通常的做法时根据业务进行分库(垂直拆分),根据单表的数据量限制做分表(水平拆分)。业务分库需要根据具体的业务场景进行确定,相对来说比较好完成,分表就不是这样了。因为在代码中写的SQL就是一张表,现在要分表,那原来的SQL肯定有问题。这个可以通过merge引擎来完成。
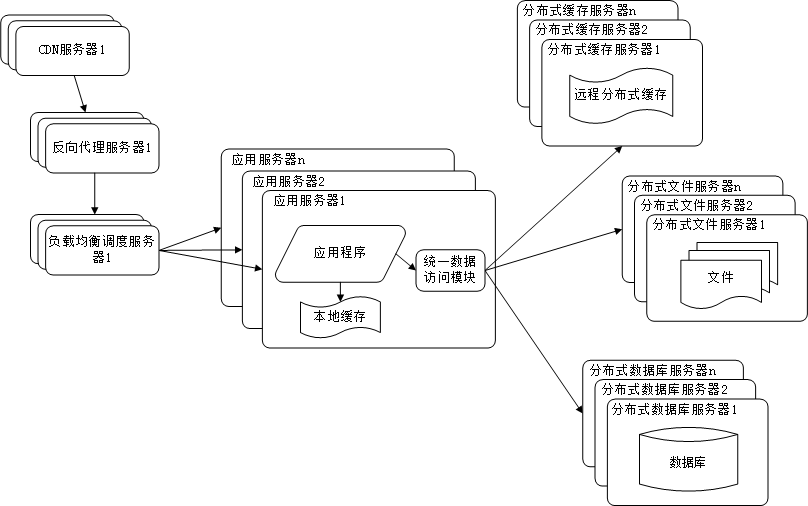
阶段八:使用NoSQL和搜索引擎优化检索性能
使用NoSQL和搜索引擎时为了解决数据查询的需求,比如在淘宝搜索一件商品的时候,总不能使用SQL的like进行匹配吧,效率太低!而搜索引擎可以利用倒排索引这种数据结构很好支持数据查询。常用的解决方案时Lucene/Solr。
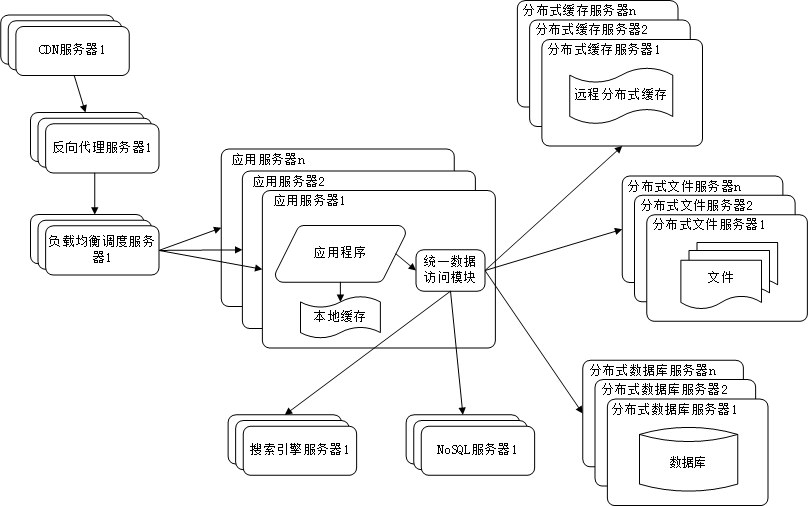
阶段九:业务拆分让网站维护更简单
随着业务场景的复杂化,将不同的业务分成不同的产品,就是把一个网站原来一个项目的情况拆分为根据不同的业务拆分为不同的项目。如果在项目中需要依赖其他项目的服务,比如在Maven工程中可以通过添加依赖的方式获取。
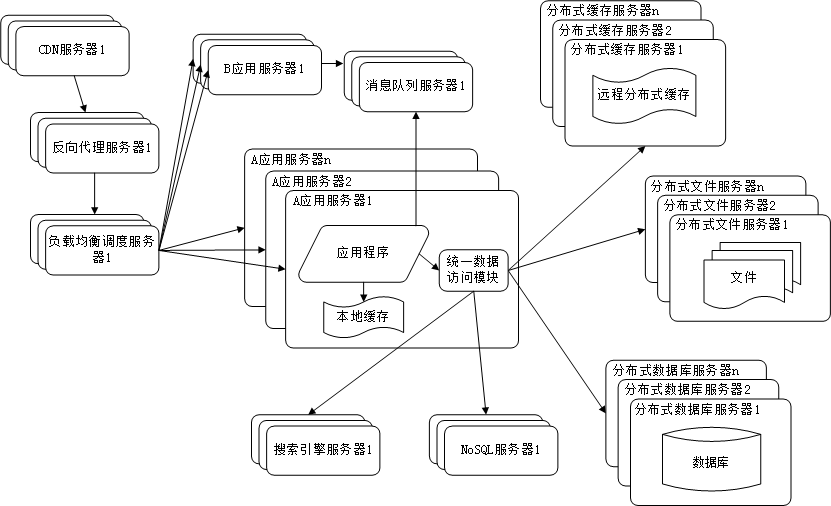
阶段十:抽取公共服务
这点很好理解,比如在不同的业务(项目)中都需要使用用户管理这个业务,那么可以把这个业务抽取出来作为公共服务,需要的时候直接添加依赖即可。
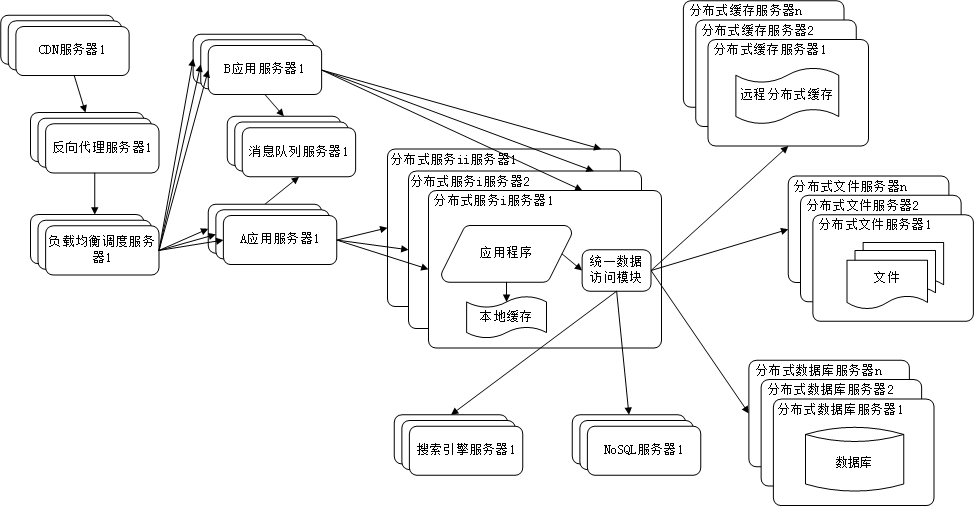
技术点整理
虽然大型网站演变到现在,架构已经非常复杂,但是仍然可以归为以下的架构模型:
前端 ——> 应用层 ——> 服务层 ——> 存储层 ——> 后台架构
大型网站架构要素可以总结为5点:高性能、高可用、伸缩性、可扩展性、安全性。
高性能
主要关注以下几个指标:响应时间(一个请求从发出请求到接收到响应数据需要的时间,是网站最重要的性能指标)、并发数(网站能够同时处理请求的请求数)、吞吐量(单位时间内系统处理的请求数,反映了网站的整体性能)。比如TPS是指每秒的事务数、QPS是指每秒的查询数。并发数在逐渐增大的过程中,系统的吞吐量会先逐渐增加,到达一个极限后,随着并发数的继续增大反而下降,直至系统资源后耗尽,吞吐量为0。这是因为并发数增大的过程实际上系统资源消耗增大的过程。而在这个过程中,响应时间会先保持小幅的上升,到达吞吐量极限后,快速上升,资源耗尽后,系统失去响应。
高可用
高可用就是在网站发生故障的时候能够迅速处理,保证网站服务依然可用、数据依然能够被访问。这里包括两点:服务的高可用和数据的高可用。服务的高可用的通常处理策略是分级管理(核心业务使用更好的硬件资源)、超时设置(服务调用超时使用服务超时策略,比如继续重试和服务调用转移,由其他可用的服务提供服务)、异步调用(能晚则晚)、服务降级(在性能下降或者服务宕机的时候,使用拒绝服务以及关闭服务的策略,即使是失败也要迅速返回,而不要让请求一直hung着)、幂等性(保证在重复调用的情况下返回和调用一次的结果相同)。数据的高可用包括数据备份和失效转移(某台服务器宕机,能够路由到其他机器继续提供服务),在分布式环境,数据会被多个节点操作,如何保证数据的一致性是数据高可用的前提,这里涉及的核心技术点是CAP、BASE理论。
伸缩性
在不改变现有系统架构的前提下,仅仅通过增加或者减少机器就可以改变网站的处理能力。
可扩展性
指的是在对现有系统影响最小的情况下,系统功能的可持续扩展或者提升的能力。通常表现在应用之间较少的耦合、对需求变更敏捷响应,符合开闭原则。
安全性
保护网站不受恶意访问和攻击,保护网站的数据不被窃取和篡改。
技术点
下面是我整理的各个要素的核心技能点,更详细的技能图谱将在下篇博客中给出(思维导图)。
高性能:分布式缓存(Redis)、异步调用(NIO/AIO + MQ(消息队列) + JVM + 代码优化)、HDFS
高可用:分布式Session、异步调用 + 服务降级 + 幂等性保证、数据备份 + 失效转移
伸缩性:负载均衡算法、一致性hash、cobar集群、Hbase
可扩展性:分布式消息队列(RabbitMQ、ActiveMQ、ZeroMQ、Kafka)、分布式服务(dubbo、gRPC)
安全性:MD5,SHA(单项散列加密)、DES(对称加密)、RSA,HTTPS(非对称加密)
程序员价值观
可以发现在大型网站的演变中每个阶段需要解决的问题都是围绕业务进行,而这点是直接与产生的价值挂钩的。不过这都是大的方面了,因为作为一个程序员,我们更关心的技术本身以及技术所带给我们的成长与增值空间。虽然我还不是一个有丰富经验的程序员,但是作为程序员很重要的一点就是保持学习、保持进步。我对自己的目标是三到五年内能够具有独立架构设计能力,具有独当一面的能力(包括人脉和自身能力(技能和知识储备))。而我对自己设定的目标是在每天的上班之余坚持看书,不在于能看多少,重要的是有收获,得到了成长。说来忏愧,这点并没有很好的贯彻下去,但是自己以后会慢慢适应这种节奏的。
也许每天上班本来就很累,晚上下班回来还要抽空看书是痛苦的,但如果没有这种毅力如何实现三年目标、五年目标呢?至少现在自己还年轻,有拼搏的本钱,所以就更应该好好珍惜时间,不断地提升自我,争取早日实现目标。
回到主题,首先需要认识到,掌握上述的技能点不是一朝一夕的,这就需要不断在空闲时间升华自己,一点一滴积累。而且,掌握技能仅仅是第一步,真正牛逼的程序员是能够把上述相关知识与技能进行重组,并且很好的解决业务问题,谓之“最佳实践”。而且对每个技能点与知识一定要进行体系化学习,因为体系化的学习可以了解到技术的全貌,而不是仅仅在工作需要时Google就可以的。谓之技术的深度。牛逼的程序员的牛逼之处在于能够对技术的实现细节了然于胸,这样当系统出问题时才能迅速定位问题所在,并快速解决问题。而体系化的学习公认的最佳实践就是看书了,所以千万不要吝啬买书的钱,因为买了,书的价值就在那,一切就等你去挖掘了!
我觉得可以先设立一个小目标,比如每个月至少4篇博客。道阻且长,我心向往之!!
再分享一下我老师大神的人工智能教程吧。零基础!通俗易懂!风趣幽默!还带黄段子!希望你也加入到我们人工智能的队伍中来!https://blog.csdn.net/jiangjunshow