本文原创作者:鲲之鹏(http://www.site-digger.com)
本文原始链接:http://www.site-digger.com/html/articles/20180821/653.html
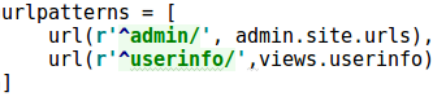
使用selenium模拟浏览器进行数据抓取无疑是当下最通用的数据采集方案,它通吃各种数据加载方式,能够绕过客户JS加密,绕过爬虫检测,绕过签名机制。它的应用,使得许多网站的反采集策略形同虚设。由于selenium不会在HTTP请求数据中留下指纹,因此无法被网站直接识别和拦截。
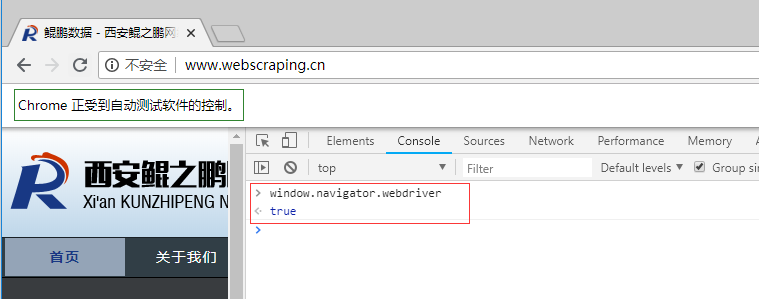
这是不是就意味着selenium真的就无法被网站屏蔽了呢?非也。selenium在运行的时候会暴露出一些预定义的Javascript变量(特征字符串),例如"window.navigator.webdriver",在非selenium环境下其值为undefined,而在selenium环境下,其值为true(如下图所示为selenium驱动下Chrome控制台打印出的值)。
除此之外,还有一些其它的标志性字符串(不同的浏览器可能会有所不同),常见的特征串如下所示:
-
webdriver
-
__driver_evaluate
-
__webdriver_evaluate
-
__selenium_evaluate
-
__fxdriver_evaluate
-
__driver_unwrapped
-
__webdriver_unwrapped
-
__selenium_unwrapped
-
__fxdriver_unwrapped
-
_Selenium_IDE_Recorder
-
_selenium
-
calledSelenium
-
_WEBDRIVER_ELEM_CACHE
-
ChromeDriverw
-
driver-evaluate
-
webdriver-evaluate
-
selenium-evaluate
-
webdriverCommand
-
webdriver-evaluate-response
-
__webdriverFunc
-
__webdriver_script_fn
-
__$webdriverAsyncExecutor
-
__lastWatirAlert
-
__lastWatirConfirm
-
__lastWatirPrompt
-
$chrome_asyncScriptInfo
-
$cdc_asdjflasutopfhvcZLmcfl_
了解了这个特点之后,就可以在浏览器客户端JS中通过检测这些特征串来判断当前是否使用了selenium,并将检测结果附加到后续请求之中,这样服务端就能识别并拦截后续的请求。
下面讲一个具体的例子。
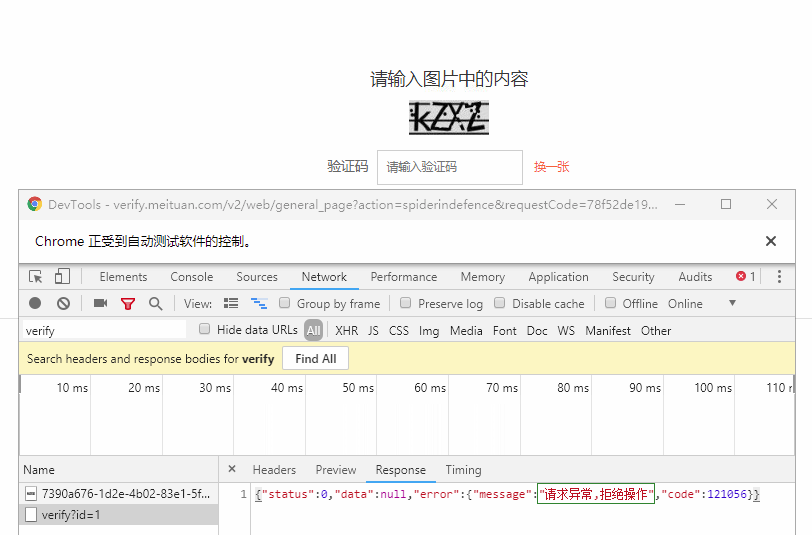
鲲之鹏的技术人员近期就发现了一个能够有效检测并屏蔽selenium的网站应用:大众点评网的验证码表单页,如果是正常的浏览器操作,能够有效的通过验证,但如果是使用selenium就会被识别,即便验证码输入正确,也会被提示“请求异常,拒绝操作”,无法通过验证(如下图所示)。
分析页面源码,可以找到 https://static.meituan.net/bs/yoda-static/file:file/d/js/yoda.e6e7c3988817eb17.js 这个JS文件,将代码格式化后,搜索webdriver可以看到如下代码:
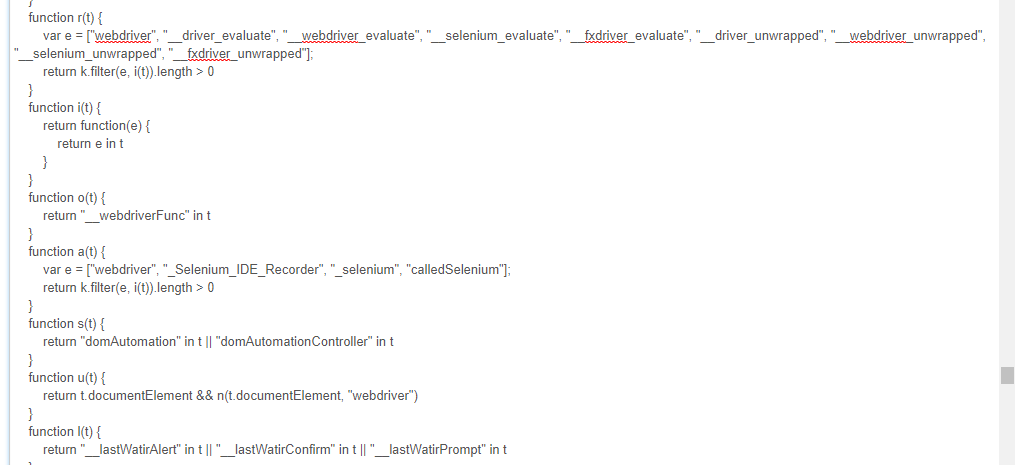
可以看到它检测了"webdriver", "__driver_evaluate", "__webdriver_evaluate"等等这些selenium的特征串。提交验证码的时候抓包可以看到一个_token参数(很长),selenium检测结果应该就包含在该参数里,服务端借以判断“请求异常,拒绝操作”。
现在才进入正题,如何突破网站的这种屏蔽呢?
我们已经知道了屏蔽的原理,只要我们能够隐藏这些特征串就可以了。但是还不能直接删除这些属性,因为这样可能会导致selenium不能正常工作了。我们采用曲线救国的方法,使用中间人代理,比如fidder, proxy2.py或者mitmproxy,将JS文件(本例是yoda.*.js这个文件)中的特征字符串给过滤掉(或者替换掉,比如替换成根本不存在的特征串),让它无法正常工作,从而达到让客户端脚本检测不到selenium的效果。
下面我们验证下这个思路。这里我们使用mitmproxy实现中间人代理),对JS文件(本例是yoda.*.js这个文件)内容进行过滤。启动mitmproxy代理并加载response处理脚本:
-
mitmdump.exe -S modify_response.py
其中modify_response.py脚本如下所示:
view plain copy to clipboard print ?
-
# coding: utf-8
-
# modify_response.py
-
-
import re
-
from mitmproxy import ctx
-
-
def response(flow):
-
"""修改应答数据
-
"""
-
if '/js/yoda.' in flow.request.url:
-
# 屏蔽selenium检测
-
for webdriver_key in [ 'webdriver', '__driver_evaluate', '__webdriver_evaluate', '__selenium_evaluate', '__fxdriver_evaluate', '__driver_unwrapped', '__webdriver_unwrapped', '__selenium_unwrapped', '__fxdriver_unwrapped', '_Selenium_IDE_Recorder', '_selenium', 'calledSelenium', '_WEBDRIVER_ELEM_CACHE', 'ChromeDriverw', 'driver-evaluate', 'webdriver-evaluate', 'selenium-evaluate', 'webdriverCommand', 'webdriver-evaluate-response', '__webdriverFunc', '__webdriver_script_fn', '__$webdriverAsyncExecutor', '__lastWatirAlert', '__lastWatirConfirm', '__lastWatirPrompt', '$chrome_asyncScriptInfo', '$cdc_asdjflasutopfhvcZLmcfl_']:
-
ctx.log.info( 'Remove "{}" from {}.'.format(webdriver_key, flow.request.url))
-
flow.response.text = flow.response.text.replace( '"{}"'.format(webdriver_key), '"NO-SUCH-ATTR"')
-
flow.response.text = flow.response.text.replace( 't.webdriver', 'false')
-
flow.response.text = flow.response.text.replace( 'ChromeDriver', '')
在selnium中使用该代理(mitmproxy默认监听127.0.0.1:8080)访问目标网站,mitmproxy将过滤JS中的特征符串,如下图所示:
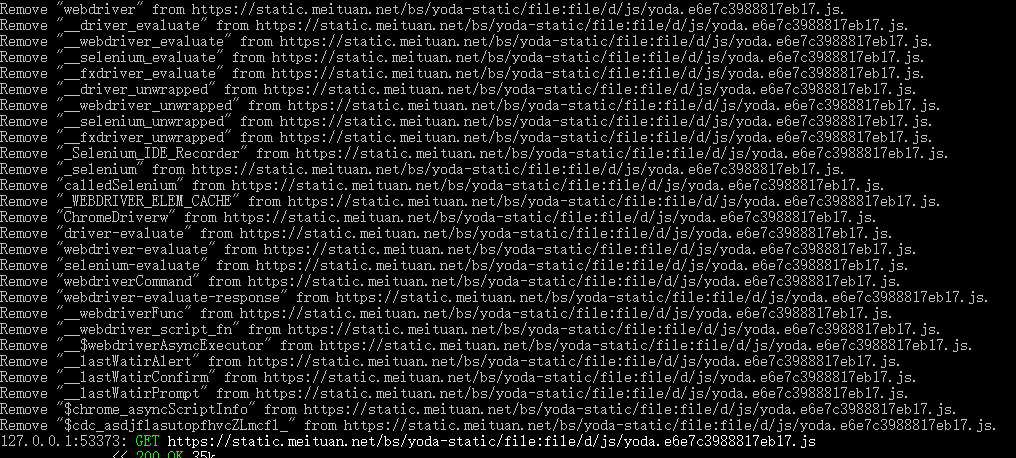
经多次测试,该方法可以有效的绕过大众点评的selenium检测,成功提交大众点评网的验证码表单。
https://stackoverflow.com/questions/33225947/can-a-website-detect-when-you-are-using-selenium-with-chromedriver
http://edmundmartin.com/detecting-selenium/
https://docs.mitmproxy.org/stable/concepts-certificates/
说明:该文章为 鲲之鹏 (http://www.site-digger.com)原创文章 ,您除了可以发表评论外,还可以转载到别的网站,但是请保留源地址,谢谢!!(尊重他人劳动,我们共同努力)
来自 “ ITPUB博客 ” ,链接:http://blog.itpub.net/30303165/viewspace-2212598/,如需转载,请注明出处,否则将追究法律责任。
转载于:http://blog.itpub.net/30303165/viewspace-2212598/