因为网站比较敏感, 所以具体网站就不说了, 直接说逻辑部分
为了降低数据提取的错误率, 所以使用了python的slimit库对js代码进行提取处理
对网站源码的JavaScript进行分析后, 发现在其中一个script标签内的js代码是利用抽取混淆的, 并用flashvars开头的变量存储
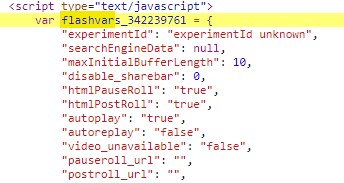
首先用python将该js代码进行提取
response = requests.get(url=url, proxies=proxies)
script = filter(lambda x: 'flashvars' in x, response.html.xpath('//script//text()')).__next__()
将该部分代码格式化后可以看到键名为mediaDefinitions的值是数组, 数组内存储着videoUrl,
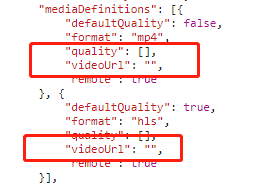
在这里可以看到, 链接是被抽取的进行拼接后即可还原真实地址

下面会使用到python的slimit库的ast进行还原
# 将js代码转成结构树
tree = Parser().parse(script)
通过smlit的Parser类的parse方法, 对js代码转换为ast结构树
获取到结构树后, 需要自定义类, 并继承ASTVisitor, 自定义访问者遍历节点对节点进行抽取
下面代码我先对mediaDefinitions和qualityItems对象进行抽取还原
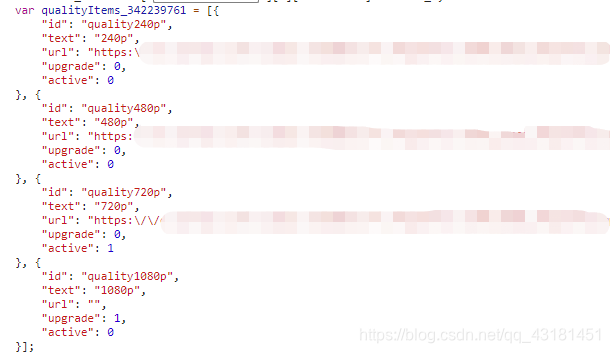
class VarStatement_Visitor(ASTVisitor):# 自定义访问者,重写VarStatement节点访问逻辑def visit_VarStatement(self, node):Identifier, Object = node.children()[0].children()# 获取flashvars的节点if 'flashvars' in Identifier.value:for i in Object.properties:left, right = i.children()# mediaDefinitions数组if left.value == '"mediaDefinitions"':# 还原字典for item in right.items:media_data = dict()for medias in item.properties:media_left, media_right = medias.children()if isinstance(media_right, ast.Array):data_list = [i.value for i in media_right.items]media_data[media_left.value[1:-1]] = data_listelse:if media_left.value == '"defaultQuality"' or media_left.value == '"remote"':media_data[media_left.value[1:-1]] = media_right.valueelse:media_data[media_left.value[1:-1]] = media_right.value[1:-1]flashvars.append(media_data)# 获取qualityItems的节点if 'qualityItems' in Identifier.value:for i in Object.items:media_data = dict()for medias in i.properties:media_left, media_right, = medias.children()if isinstance(media_right, ast.Number):media_data[media_left.value[1:-1]] = media_right.valueelse:media_data[media_left.value[1:-1]] = media_right.value[1:-1].replace('\\/', '/')flashvars.append(media_data)
还原mediaDefinitions和qualityItems对象后, 继续创建访问者对抽取链接进行还原
进入的节点仍然是VarStatement, 因为视频的链接由多个变量并且不定数量进行拼接, 所以下面使用递归方式并使用了get_Identifier方法对抽取变量进行获取还原
class Media_Visitor(ASTVisitor):def __init__(self, i, *args, **kwargs):# 视频所在的序号self.i = i# 映射关系self.identifier = {}# 映射顺序self.identifiers_list = []super(*args, **kwargs)# 递归获取映射顺序def get_Identifier(self, node, identifiers_list):left, right = node.children()identifiers_list.append(self.identifier[right.value])if isinstance(left, ast.BinOp):self.get_Identifier(left, identifiers_list)else:identifiers_list.append(self.identifier[left.value])def visit_VarStatement(self, node):Identifier, BinOp = node.children()[0].children()# 获取该函数地址的映射顺序if 'media_' + str(self.i) in Identifier.value:# 计算该视频的真实地址self.get_Identifier(BinOp, self.identifiers_list)# 填充视频地址flashvars[self.i]['videoUrl'] = ''.join(self.identifiers_list[::-1])# 根据映射关系进行恢复elif isinstance(BinOp, ast.String) or (len(BinOp.children()) == 2 and isinstance(BinOp.children()[0], ast.String) and isinstance(BinOp.children()[1], ast.String)):if isinstance(BinOp, ast.String):self.identifier[Identifier.value] = BinOp.value[1:-1]else:self.identifier[Identifier.value] = ''.join([i.value[1:-1] for i in BinOp.children()])
下面是完整代码:
import re
import time
import traceback
import requests_html
# 将js代码转为AST结构树
from slimit.parser import Parser
# 自定义访问者
from slimit.visitors.nodevisitor import ASTVisitor
# 判断类型
from slimit import ast
import osrequests = requests_html.HTMLSession()
flashvars = list()class VarStatement_Visitor(ASTVisitor):# 自定义访问者,重写VarStatement节点访问逻辑def visit_VarStatement(self, node):Identifier, Object = node.children()[0].children()# 获取flashvars的节点if 'flashvars' in Identifier.value:for i in Object.properties:left, right = i.children()# mediaDefinitions数组if left.value == '"mediaDefinitions"':# 还原字典for item in right.items:media_data = dict()for medias in item.properties:media_left, media_right = medias.children()if isinstance(media_right, ast.Array):data_list = [i.value for i in media_right.items]media_data[media_left.value[1:-1]] = data_listelse:if media_left.value == '"defaultQuality"' or media_left.value == '"remote"':media_data[media_left.value[1:-1]] = media_right.valueelse:media_data[media_left.value[1:-1]] = media_right.value[1:-1]flashvars.append(media_data)# 获取qualityItems的节点if 'qualityItems' in Identifier.value:for i in Object.items:media_data = dict()for medias in i.properties:media_left, media_right, = medias.children()if isinstance(media_right, ast.Number):media_data[media_left.value[1:-1]] = media_right.valueelse:media_data[media_left.value[1:-1]] = media_right.value[1:-1].replace('\\/', '/')flashvars.append(media_data)class Media_Visitor(ASTVisitor):def __init__(self, i, *args, **kwargs):# 视频所在的序号self.i = i# 映射关系self.identifier = {}# 映射顺序self.identifiers_list = []super(*args, **kwargs)# 递归获取映射顺序def get_Identifier(self, node, identifiers_list):left, right = node.children()identifiers_list.append(self.identifier[right.value])if isinstance(left, ast.BinOp):self.get_Identifier(left, identifiers_list)else:identifiers_list.append(self.identifier[left.value])def visit_VarStatement(self, node):Identifier, BinOp = node.children()[0].children()# 获取该函数地址的映射顺序if 'media_' + str(self.i) in Identifier.value:# 计算该视频的真实地址self.get_Identifier(BinOp, self.identifiers_list)# 填充视频地址flashvars[self.i]['videoUrl'] = ''.join(self.identifiers_list[::-1])# 根据映射关系进行恢复elif isinstance(BinOp, ast.String) or (len(BinOp.children()) == 2 and isinstance(BinOp.children()[0], ast.String) and isinstance(BinOp.children()[1], ast.String)):if isinstance(BinOp, ast.String):self.identifier[Identifier.value] = BinOp.value[1:-1]else:self.identifier[Identifier.value] = ''.join([i.value[1:-1] for i in BinOp.children()])def main(url):response = requests.get(url=url)script = filter(lambda x: 'flashvars' in x, response.html.xpath('//script//text()')).__next__()# 将js代码转成结构树tree = Parser().parse(script)VarStatement_Visitor().visit(tree)for i, _ in enumerate(flashvars):Media_Visitor(i).visit(tree)print(flashvars)