final_data为脱敏后的数据
final_data. head( )
user_id item_id behavior_type user_geohash item_category time 0 54007195 79633535 1 NaN 3940 2014-11-24 16 1 136952642 337800294 1 NaN 4830 2014-11-22 12 2 121255158 108926788 1 NaN 1970 2014-11-22 08 3 72256073 144090786 1 NaN 4008 2014-12-09 20 4 65645933 250029185 1 9t4qqgn 2825 2014-11-25 17
data = final_data[ [ 'user_id' , 'item_id' , 'behavior_type' , 'time' ] ]
data. head( )
user_id item_id behavior_type time 0 54007195 79633535 1 2014-11-24 16 1 136952642 337800294 1 2014-11-22 12 2 121255158 108926788 1 2014-11-22 08 3 72256073 144090786 1 2014-12-09 20 4 65645933 250029185 1 2014-11-25 17
data. shape
(12256906, 4)
data[ 'date' ] = data[ 'time' ] . map ( lambda x: x. split( ' ' ) [ 0 ] )
data[ 'hour' ] = data[ 'time' ] . map ( lambda x: x. split( ' ' ) [ 1 ] )
data. head( )
C:\work\software\Anaconda5.3.0\lib\site-packages\ipykernel_launcher.py:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value insteadSee the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy"""Entry point for launching an IPython kernel.
user_id item_id behavior_type time date hour 0 54007195 79633535 1 2014-11-24 16 2014-11-24 16 1 136952642 337800294 1 2014-11-22 12 2014-11-22 12 2 121255158 108926788 1 2014-11-22 08 2014-11-22 08 3 72256073 144090786 1 2014-12-09 20 2014-12-09 20 4 65645933 250029185 1 2014-11-25 17 2014-11-25 17
data. drop( [ 'time' ] , axis= 1 , inplace= True )
data. head( )
user_id item_id behavior_type date hour 0 54007195 79633535 1 2014-11-24 16 1 136952642 337800294 1 2014-11-22 12 2 121255158 108926788 1 2014-11-22 08 3 72256073 144090786 1 2014-12-09 20 4 65645933 250029185 1 2014-11-25 17
map函数是Series对象的一个函数,DataFrame中没有map(),map()的功能是将一个自定义函数作用于Series对象的每个元素。 apply()函数的功能是将一个自定义函数作用于DataFrame的行或者列 applymap()函数的功能是将自定义函数作用于DataFrame的所有元素 data. shape
(12256906, 5)
data. dtypes
user_id int64
item_id int64
behavior_type int64
date object
hour object
dtype: object
data[ 'date' ] = pd. to_datetime( data[ 'date' ] )
data[ 'hour' ] = data[ 'hour' ] . astype( 'int32' )
data. dtypes
user_id int64
item_id int64
behavior_type int64
date datetime64[ns]
hour int32
dtype: object
data[ 'user_id' ] . nunique( )
10000
data. isnull( ) . sum ( )
user_id 0
item_id 0
behavior_type 0
date 0
hour 0
dtype: int64
平均在线时间:平均每个UV访问页面的停留时间 平均访问深度:平均每个UV的PV数量 跳失率:浏览某个页面后就离开的访问次数/该页面的全部访问次数
total_pv = data. shape[ 0 ]
total_pv
12256906
pv = data. groupby( [ 'date' ] ) [ 'user_id' ] . count( ) . reset_index( )
pv
date user_id 0 2014-11-18 366701 1 2014-11-19 358823 2 2014-11-20 353429 3 2014-11-21 333104 4 2014-11-22 361355 5 2014-11-23 382702 6 2014-11-24 378342 7 2014-11-25 370239 8 2014-11-26 360896 9 2014-11-27 371384 10 2014-11-28 340638 11 2014-11-29 364697 12 2014-11-30 401620 13 2014-12-01 394611 14 2014-12-02 405216 15 2014-12-03 411606 16 2014-12-04 399952 17 2014-12-05 361878 18 2014-12-06 389610 19 2014-12-07 399751 20 2014-12-08 386667 21 2014-12-09 398025 22 2014-12-10 421910 23 2014-12-11 488508 24 2014-12-12 691712 25 2014-12-13 407160 26 2014-12-14 402541 27 2014-12-15 398356 28 2014-12-16 395085 29 2014-12-17 384791 30 2014-12-18 375597
pv = pv. rename( columns= { 'user_id' : 'pv' } )
pv. head( )
date pv 0 2014-11-18 366701 1 2014-11-19 358823 2 2014-11-20 353429 3 2014-11-21 333104 4 2014-11-22 361355
uv = data. groupby( [ 'date' ] ) [ 'user_id' ] . apply ( lambda x: x. drop_duplicates( ) . count( ) )
uv. head( )
date
2014-11-18 6343
2014-11-19 6420
2014-11-20 6333
2014-11-21 6276
2014-11-22 6187
Name: user_id, dtype: int64
uv = uv. reset_index( ) . rename( columns= { 'user_id' : 'uv' } )
uv. head( )
date uv 0 2014-11-18 6343 1 2014-11-19 6420 2 2014-11-20 6333 3 2014-11-21 6276 4 2014-11-22 6187
import matplotlib. pyplot as plt
font = { 'family' : 'SimHei' , 'size' : '20' }
plt. rc( 'font' , ** font) plt. figure( figsize= ( 20 , 5 ) )
plt. xticks( rotation= 30 ) plt. plot( pv[ 'date' ] , pv[ 'pv' ] ) plt. title( '日均pv' ) plt. show( )
plt. figure( figsize= ( 20 , 5 ) )
plt. xticks( rotation= 30 ) plt. plot( uv[ 'date' ] , uv[ 'uv' ] ) plt. title( '日均uv' )
plt. savefig( '日UV.png' ) plt. show( )
pv和uv都是在12月12日达到峰值 在双十二前后会有较高波动,而平常的波动比较平稳 data. head( )
user_id item_id behavior_type date hour 0 54007195 79633535 1 2014-11-24 16 1 136952642 337800294 1 2014-11-22 12 2 121255158 108926788 1 2014-11-22 8 3 72256073 144090786 1 2014-12-09 20 4 65645933 250029185 1 2014-11-25 17
pv_hour = data. groupby( [ 'hour' ] ) [ 'user_id' ] . count( )
pv_hour. head( )
hour
0 517404
1 267682
2 147090
3 98516
4 80487
Name: user_id, dtype: int64
pv_hour = pv_hour. reset_index( ) . rename( columns= { 'user_id' : 'pv' } )
pv_hour. head( )
hour pv 0 0 517404 1 1 267682 2 2 147090 3 3 98516 4 4 80487
uv_hour = data. groupby( [ 'hour' ] ) [ 'user_id' ] . apply ( lambda x: x. drop_duplicates( ) . count( ) )
uv_hour = uv_hour. reset_index( ) . rename( columns= { 'user_id' : "uv" } )
uv_hour. head( )
hour uv 0 0 5786 1 1 3780 2 2 2532 3 3 1937 4 4 1765
plt. figure( figsize= ( 20 , 5 ) )
plt. plot( uv_hour[ 'hour' ] , uv_hour[ 'uv' ] ) plt. xticks( rotation= 30 )
plt. title( '每小时UV' )
plt. savefig( '每小时UV.png' ) plt. show( )
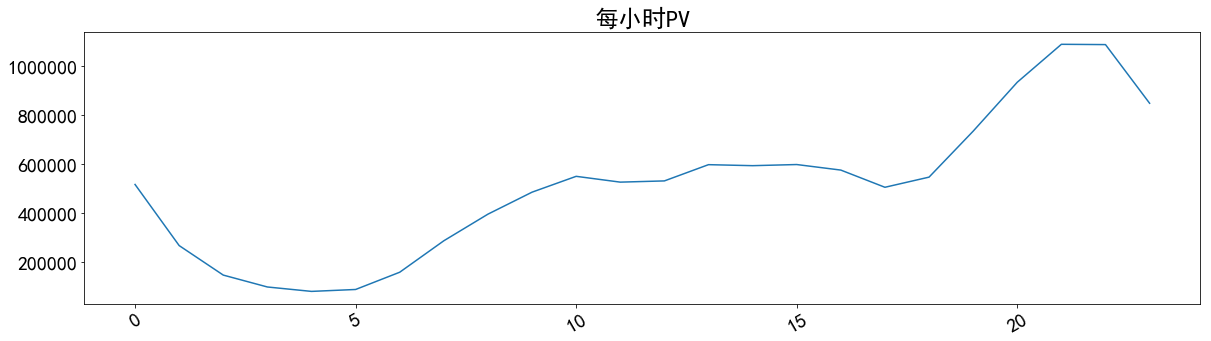
plt. figure( figsize= ( 20 , 5 ) )
plt. plot( pv_hour[ 'hour' ] , pv_hour[ 'pv' ] ) plt. xticks( rotation= 30 )
plt. title( '每小时PV' )
plt. savefig( '每小时PV.png' ) plt. show( )
round ( data. shape[ 0 ] / data[ 'user_id' ] . nunique( ) , 2 )
1225.69
round ( data[ 'user_id' ] . shape[ 0 ] / data[ 'user_id' ] . nunique( ) / data[ 'date' ] . nunique( ) , 2 )
39.54






![[网站动态]年轻态SNS席卷台湾](http://blog.yam.com/ixblog/b89be867.jpg)