UpdateStateByKey操作(按照key更新状态)
其它案例都是之前spark用到过的,以下是特殊RDD
(之前案例统计的是5秒内的总次数,并不是wordcount的总次数,此Rdd可以统计整个流 流过的内容的wordcount总次数)
该updateStateByKey操作允许您在使用新信息不断更新时保持任意状态。要使用它,您必须执行两个步骤。
- 定义状态 - 状态可以是任意数据类型。
- 定义状态更新功能 - 使用函数指定如何使用先前状态和输入流中的新值更新状态。
在每个批处理中,Spark都会对所有现有Key状态更新功能,无论它们是否在批处理中,都有新数据。
如果更新函数返回None,则将删除键值对。
请注意,使用updateStateByKey需要配置检查点目录
让我们举一个例子来说明这一点。
假设您要维护文本数据流中看到的每个单词的运行计数(单词统计, 根据key操作)
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object updateStateByKeyStreaming {def main(args: Array[String]): Unit = {val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")//批次,时间切片val ssc = new StreamingContext(conf, Seconds(5))//1.增加检查点,会在E盘生成aaa文件夹 每次计算结果保存,也就是需要做updateStateByKey就必须有检查点将流上次内容保存到检查点中ssc.checkpoint("E://aaa") //ssc.checkpoint("hdfs://master:9000/aaa") 如报权限问题,修改hdfs创建文件的权限//使用自定义的接收器val lines = ssc.receiverStream(new CustomReceiver("master", 9999))val words = lines.flatMap(_.split(" "))val pairs = words.map(word => (word, 1))val wordCount = pairs.reduceByKey(_ + _) //3.用wordCount调用updateStateByKey函数val wordCounts = wordCount.updateStateByKey(updateFunction)wordCounts.print()ssc.start() // 开始计算ssc.awaitTermination() // 等待计算结束}//2.当前计数器结果 //上一个计数器结果,第一次进来没有值 Option【None 、Some】def updateFunction(newValues: Seq[Int], runningCount: Option[Int]): Option[Int] = {val newCount = runningCount.getOrElse(0) // 使用前一个正在运行的计数添加新值,以获得新计数Some(newCount+newValues.sum) //相加/*val newCounts = runningCount.getOrElse(0) + newValues.foldLeft(0)(_+_)Some(newCounts)*/}
}spark-submit提交
[hyxy@master Desktop]$ spark-submit --help
Options:
--class CLASS_NAME Your application's main class (for Java / Scala apps).
--master spark:7077 独立
--master local[*] 本地
--master client spark on yarn
案例1,通过nc发送消息, spark-submit运行SparkStreaming程序
1)编写sparkStreaming程序 package 打包
【package com.hyxy.sparkStreaming】
import org.apache.spark._
import org.apache.spark.streaming._
object NcSparkStreaming{def main(args: Array[String]): Unit = {val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")val ssc = new StreamingContext(conf, Seconds(5))val lines = ssc.socketTextStream("master", 9999)val words = lines.flatMap(_.split(" "))val pairs = words.map(word => (word, 1))val wordCounts = pairs.reduceByKey(_ + _)// Print the first ten elements of each RDD generated in this DStream to the consolewordCounts.print()ssc.start() // Start the computationssc.awaitTermination()}}2) 打包 package右键Run 项目名(第二项)
生成目录target下
将spark01-1.0-SNAPSHOT.jar拷贝到Liunx下
3)开启nc -l 9999
4)spark-submit提交
spark-submit --class com.hyxy.NcSparkStreaming Spark01-1.0-SNAPSHOT.jar
查看nc输入内容
5)clear清除jar包
说明,clear后没有class文件, 需要生成class才可以打包,如果IDEA的编译不能生成class
需要在IDEA运行一遍程序,并且nc 开启后,控制台不报错时才会生成class,具体操作一遍即可!!
6)查看winodws下sparkStreamingWebUI
http://master:4040/streaming/
分析日志:
- 通过日志可以分析出来很多有用的东西, 例如网站内哪个网址是最受欢迎的,即取出网址排名
- 从哪个页面来访问我的网站,例如从百度搜索引擎来的,可以根据日志来分析很多东西最后可以做一个柱状图,UI页面展示
- 统计哪个浏览器用的人数最多
- 访问网站的字节数,即可以统计出每个网页的流量,定期的分析哪个网站占用的流量大,
- 可以对该网站进行分析,空格也是占流量的
---------------------------------------------------------------------------------------------------------------------------------------------
案例1:如果我们是网站的管理员,需要禁止爬虫的场景
以下案例学习知识点
- 分析网站日志
- 熟练掌握API一些RDD
例如每10秒钟,相同IP访问的次数,如果10秒钟内同一个IP访问了50次, 非人访问(手抽筋),
所以认为它是一个爬虫 需检查服务器日志
1.判断是爬虫
打印出10秒内所有的日志访问次数 ,找出其中爬虫的ip和次数
验证爬虫条件:单位时间10秒内访问次数大于5的
思路: 取出要的数据IP,词频统计IP count,过滤count大于5的打印输出
$> nc -lk 9999
58.254.203.49 - - [04/Jan/2012:00:00:08 +0800] "GET /home.php?mod=spacecp&ac=pm&op=checknewpm&rand=1325606408 HTTP/1.1" 200 31 "http://www.itpub.net/forum-72-4.html?ts=30" "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/535.7 (KHTML, like Gecko) Chrome/16.0.912.63 Safari/535.7"
114.112.141.6 - - [04/Jan/2012:00:00:08 +0800] "GET /home.php?mod=spacecp&ac=pm&op=checknewpm&rand=1325606408 HTTP/1.1" 200 5 "http://www.itpub.net/ctp080113.php?action=getgold" "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; InfoPath.3; .NET4.0C; .NET4.0E; .NET CLR 2.0.50727; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)"
123.126.50.81 - - [04/Jan/2012:00:00:09 +0800] "GET /home.php?mod=magic&mid=namepost&idtype=pid&id=9805890:950965 HTTP/1.1" 200 5224 "-" "Sogou web spider/4.0(+http://www.sogou.com/docs/help/webmasters.htm#07)"
123.126.50.68 - - [04/Jan/2012:00:00:09 +0800] "GET /thread-837469-1-1.html HTTP/1.1" 200 5251 "-" "Sogou web spider/4.0(+http://www.sogou.com/docs/help/webmasters.htm#07)"
219.80.140.242 - - [04/Jan/2012:00:00:09 +0800] "GET /forum.php?mod=ajax&action=forumchecknew&fid=2&time=1325606279&inajax=yes HTTP/1.1" 200 75 "http://www.itpub.net/forum-2-1.html?ts=21" "Mozilla/5.0 (Windows NT 6.1; rv:8.0) Gecko/20100101 Firefox/8.0"
110.6.179.88 - - [04/Jan/2012:00:00:09 +0800] "GET /forum.php?mod=attachment&aid=NTczNzU3fDFjNDdjZTgzfDEzMjI4NzgwMDV8MTMzOTc4MDB8MTEwMTcxMA%3D%3D&mobile=no HTTP/1.1" 200 172 "http://www.itpub.net/forum.php?mod=attachment&aid=NTczNzU3fDFjNDdjZTgzfDEzMjI4NzgwMDV8MTMzOTc4MDB8MTEwMTcxMA%3D%3D&mobile=yes" "Mozilla/5.0 (Linux; U; Android 2.2; zh-cn; ZTE-U V880 Build/FRF91) UC AppleWebKit/530+ (KHTML, like Gecko) Mobile Safari/530"
112.245.248.62 - - [04/Jan/2012:00:00:09 +0800] "GET /popwin_js.php?fid=7 HTTP/1.1" 200 32 "http://www.itpub.net/forum.php?gid=7" "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; Trident/4.0; GTB7.2; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729)"
110.6.179.88 - - [04/Jan/2012:00:00:09 +0800] "GET /forum.php?mod=attachment&aid=NTczNzU3fDFjNDdjZTgzfDEzMjI4NzgwMDV8MTMzOTc4MDB8MTEwMTcxMA%3D%3D&mobile=no HTTP/1.1" 200 172 "http://www.itpub.net/forum.php?mod=attachment&aid=NTczNzU3fDFjNDdjZTgzfDEzMjI4NzgwMDV8MTMzOTc4MDB8MTEwMTcxMA%3D%3D&mobile=yes" "Mozilla/5.0 (Linux; U; Android 2.2; zh-cn; ZTE-U V880 Build/FRF91) UC AppleWebKit/530+ (KHTML, like Gecko) Mobile Safari/530"
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreaming01 {def main(args: Array[String]): Unit = {val conf = new SparkConf().setMaster("local[*]").setAppName("ip")val ssc = new StreamingContext(conf,Seconds(10))val ds = ssc.socketTextStream("master",9999)//求出IP在10秒内超过5次的打印输出.//知识点,map和flatMap区别ds.map(_.split(" ")(0)).map(x =>(x,1)).reduceByKey(_+_).filter(x => x._2 > 5).print()ssc.start()ssc.awaitTermination()}
}
运行结果
-------------------------------------------
Time: 1560908320000 ms
-------------------------------------------
(207.46.195.242,7)
(114.112.141.6,124)
(202.108.36.125,6)
(123.125.71.116,6)
(211.144.198.146,6)
(203.208.60.216,7)
(110.75.173.34,11)
(199.255.44.5,22)
(38.99.172.70,6)
(203.208.60.187,9)
...
知识点1 连接:
Spark Streaming中执行不同类型的连接
val stream1: DStream[String, String] = ...
val stream2: DStream[String, String] = ...
join连接
val joinedStream = stream1.join(stream2)
左外连接
val joinedStream = stream1.leftOuterJoin(stream2)
知识点2:
transform(func)
通过将RDD-to-RDD函数应用于源DStream的每个RDD来返回新的DStream。
这可以用于在DStream上执行任意RDD操作。
transform操作
创建一个新的rdd可以应用于流中的每一个rdd,(对于流中的每一个rdd进行操作)
val spamInfoRDD = ssc.sparkContext.newAPIHadoopRDD(...) // RDD containing spam information
val cleanedDStream = wordCounts.transform { rdd =>
rdd.join(spamInfoRDD).filter(...) // join data stream with spam information to do data cleaning
...
}
案例2:根据上一题的结果创建一个黑名单rdd,禁止加入黑名单的访问
(上一个案例监测日志,查看哪个是爬虫,如果是爬虫的我们有标识,
例如 ip,标识[1] 将不是爬虫的ip让它们正常访问)
思路:用黑名单的ip 和 nc传来的ip做join,ip 不为true 的正常显示
1.将是黑名单的ip 定义一个新的rdd
val iplist= List(("114.112.141.6",1))
2.将黑名单的ip与nc传来的ip做join,如果是黑名单的不显示输出
// join要求两边类型一致 //打印输出是None 如果是None 为true 否则 为false
val conf = new SparkConf().setMaster("local[*]").setAppName("ip")
val ssc = new StreamingContext(conf,Seconds(10))
ssc.sparkContext.setLogLevel("ERROR")
//通过爬虫生成黑名单文件, textFile加载 爬虫IP黑名单文件
val iplist= List(("114.112.141.6",1))
val hrdd = ssc.sparkContext.parallelize(iplist)
val ds = ssc.socketTextStream("master",9999)ds.map(_.split(" ")(0)).map(x => (x,1)).transform{rdd => rdd.leftOuterJoin(hrdd).filter(x => if(x._2._2 == None) true else false)}.map(x=>x._1).print(100)ssc.start()
ssc.awaitTermination()1.nc再次输入数据
120.197.87.247
203.208.60.187
110.6.179.88
110.75.173.35
[114.112.141.6]
123.126.50.73
110.75.173.32
[114.112.141.6]
120.197.87.216
120.197.87.220
116.205.130.2
2.运行结果:在黑名单的中IP禁止输出
Time: 1554510300000 ms
-------------------------------------------
120.197.87.247
203.208.60.187
110.6.179.88
110.75.173.35
123.126.50.73
110.75.173.32
120.197.87.216
120.197.87.220
116.205.130.2
案例3:统计网站的UV访问数
UV访问数(Unique Visitor)指独立访客访问数,一台电脑终端为一个访客。
统计网站单位时间(10秒)的UV数(访问IP去掉重复)(10秒内有多少个IP访问我的网站)
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreaming01 {def main(args: Array[String]): Unit = {val conf = new SparkConf().setMaster("local[*]").setAppName("ip")val ssc = new StreamingContext(conf,Seconds(10))ssc.sparkContext.setLogLevel("ERROR")val ds = ssc.socketTextStream("master",9999)//统计网站单位时间的访问量去掉重复ip(访问量 个数)ds.map(_.split(" ")(0)).map(x => (x,1)).reduceByKey(_+_).count().print()ssc.start()ssc.awaitTermination()}
}测试 nc 输入数据:
30条数据
运行结果:
19条
窗口操作: 【允许您在滑动数据窗口上应用转换】
1.批处理间隔(Batch Duration)
在Spark Streaming中,数据采集是逐条进行的,而数据处理是按批进行的,因此在Spark Streaming中会先设置好
批处理间隔(batch duration),当超过批处理间隔的时候就会把采集到的数据汇总起来成为一批数据交给系统去处理
2.窗口间隔(Window Duration)和滑动间隔(Slide Duration)
- 对于窗口操作,批处理间隔、窗口间隔和滑动间隔是非常重要的3个时间概念,是理解窗口操作的关键所在
- 对于窗口操作而言,在其窗口内部会有N个批处理数据,批处理数据的个数由窗口间隔(Window Duration)决定,其为窗口持续的时间,在窗口操作中只有窗口间隔满足了才会触发批数据的处理,除了窗口的长度,另一个重要的参数就是滑动间隔(Slide Duration),它指的是经过多长时间窗口滑动一次形成新的窗口,滑动窗口默认情况下
- 和批次间隔的相同,而窗口间隔一般设置得要比它们俩都大。特别要注意的是,窗口间隔和滑动间隔的大小一定得设置为批处理间隔的整数倍
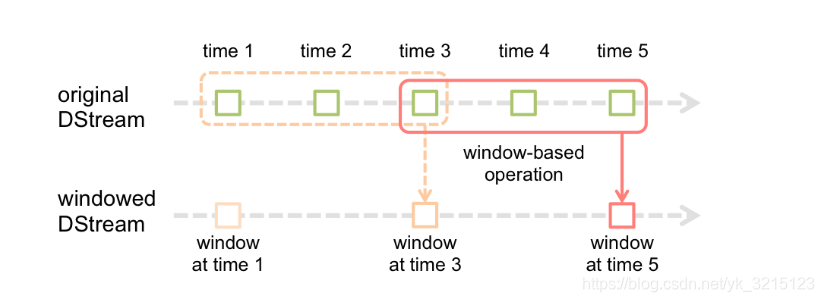
如图所示,批处理间隔是1个时间单位,窗口间隔是3个时间单位,滑动间隔是2个时间单位。
对于初始的窗口time1~time3,只有窗口间隔满足了才触发数据的处理,这里需要注意的一点是,初始的窗口有可能
流入的数据没有撑满,但是随着时间的推进,窗口最终会被撑满,当每2个时间单位,窗口滑动一次后,会有新的
数据流入窗口,这时窗口会移去最早的两个时间单位的数据,而与最新的两个时间单位的数据进行汇总形成
新的窗口(time3~time5)
窗口操作(window)
包含多个单位时间的dstream,即窗口操作是跨批次的操作
- batch interval :批次的时间
- windows length :窗口长度,跨批次,包含多少个dstream (一次算多少批次)
- slide interval :滑动间隔,窗口计算的间隔时间 (多长时间算一次)
windows length 、windows length以上两个参数都是batch interval 批次的倍数
官网orginalDStream是原始的数据,能过几秒内切成一个个小的rdd, time3 time4 time5 形成一个windowedDStream的winodws at time5的窗口rdd
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------
案例:reduceByKeyAndWindow
val wordCount = pairs.reduceByKeyAndWindow((a:Int,b:Int)=>(a+b),Seconds(30),Seconds(10))
-------------------------------------------
Time: 1565830045000 ms
-------------------------------------------
(hello,7)
-------------------------------------------
Time: 1565830055000 ms
-------------------------------------------
(hello,10)
以上信息是在一个窗口范围内
不输入hello 时, 按滑动 窗口继续统计
-------------------------------------------
Time: 1565830065000 ms
-------------------------------------------
(hello,7)
-------------------------------------------
Time: 1565830075000 ms
-------------------------------------------
(hello,6)
-------------------------------------------
Time: 1565830085000 ms
-------------------------------------------
----------------------------------------------------------------------------------------------------------------------------------------
案例:window窗口
例如窗口windows设置时间是60秒 lines.window(Seconds(60)).count().print()
批次时间5秒(5秒Rdd的总和) val ssc = new StreamingContext(conf,Seconds(5))
那么窗口DStream统计了12次的是 5秒Rdd的总和
原来是5秒就进行一次RDD计算,现在是窗口时间点是60秒统计一次
每隔5秒钟,统计前一分钟网站PV访问量(也可以统计一天的访问量)
PV访问量(Page View),即页面访问量,每打开一次页面PV计数+1,刷新页面也是。
思路:
- 先求出网站的访问量
- 加上窗口时间(周期)访问量
//创建配置文件val conf = new SparkConf().setAppName("nwc").setMaster("local[2]")//创建流的上下文 每隔5秒中切一个rddval ssc = new StreamingContext(conf,Seconds(5))//设置日志级别ssc.sparkContext.setLogLevel("ERROR")//通过socket获取数据流 val lines = ssc.socketTextStream("master",9999)//按窗口时间60秒统计rdd 12次 * 5秒lines.window(Seconds(60)).count().print()ssc.start()ssc.awaitTermination() 运行结果: nc 复制30条数据,30结果包含重复的IP
Time: 1554517075000 ms
-------------------------------------------
30
再次运行统计前1分钟
-------------------------------------------
Time: 1565448365000 ms
-------------------------------------------
68
再次复制数据
-------------------------------------------
Time: 1565448370000 ms
-------------------------------------------
85
停止复制数据,查看控制台, 统计前一分钟,数据会减少
-------------------------------------------
68
-------------------------------------------
Time: 1565448430000 ms
-------------------------------------------
51
-------------------------------------------
Time: 1565448435000 ms
-------------------------------------------
34
-------------------------------------------
Time: 1565448440000 ms
-------------------------------------------
17
-------------------------------------------
Time: 1565448445000 ms
-------------------------------------------
0
_________________________________________
114.112.141.6 - - [04/Jan/2012:00:00:02 +0800] "GET /ctp080113.php?action=getgold HTTP/1.1" 200 13886 "-" "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; InfoPath.3; .NET4.0C; .NET4.0E; .NET CLR 2.0.50727; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)"