文章目录
- 一.了解页面信息
- 二.爬取数据代码
- 三.获取数据结果
一.了解页面信息
这里我们以酷狗音乐古风榜为例

由此可见我们需要我曲目和歌手的信息都在框住的class里面
二.爬取数据代码
#导入requests和BeautifulSoup库
import requests
from bs4 import BeautifulSoupurl = "https://www.kugou.com/yy/rank/home/1-33161.html?from=rank"
#获取所有网页信息
response = requests.get(url)
#利用.text方法提取响应的文本信息
r=requests.get(url)
html = r.text
soup =BeautifulSoup(html,'html.parser')
#解析出歌名,find_all()函数返回的是tag的列表
names = soup.find_all('a',class_='pc_temp_songname')
# 打印names
print(names)
for name in names:#利用split方法把歌手和曲目分隔返回成列表形式赋值给itemitem = name.get_text().split('-')#q巧妙利用数组格式化依次输出曲名和歌手print("曲名:{} 歌手:{} ".format(item[1],item[0]))
三.获取数据结果
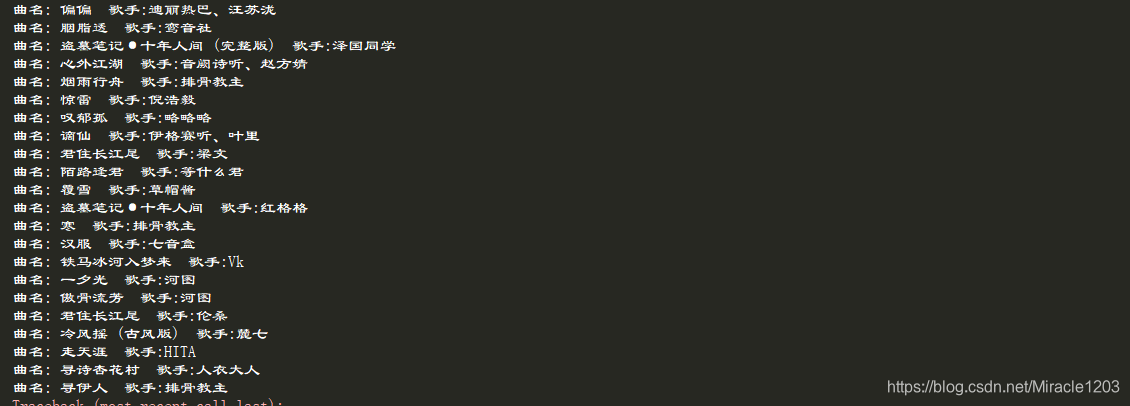 到这就结束了,一起学习共同进步 😃
到这就结束了,一起学习共同进步 😃


![[网站动态]年轻态SNS席卷台湾](http://blog.yam.com/ixblog/b89be867.jpg)