本文用于快速入门或者复习selenium的webdriver但不讲解如何安装selenium以及ChromeDriver
先教一些简单功能,各函数功能在注释里
from selenium import webdriver
import time#访问百度首页
first_url = 'http://www.baidu.com'
print("正在访问%s" % (first_url))
driver.get(first_url)#打印网页源码
print(driver.page_source)#访问新闻页面
second_url = 'http://news.baidu.com'
print("正在访问%s" %(second_url))
driver.get(second_url)#回退到百度首页
print("回退到百度首页")
driver.back()#前进到新闻页
print("前进到新闻页")
driver.forward()#刷新当前页面
driver.refresh()#查看当前网页url
print(driver.current_url)#滑动进度条到最低端,使用javaScript
driver.execute_script('window.scrollTo(0, document.body.scrollHeight)')
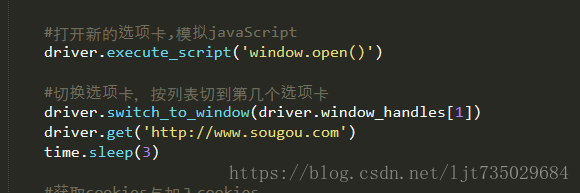
time.sleep(1)#打开新的选项卡,模拟javaScript
driver.execute_script('window.open()')#切换选项卡,按列表切到第几个选项卡
driver.switch_to_window(driver.window_handles[1])
driver.get('http://www.sougou.com')
time.sleep(3)#关闭选项卡
driver.close()
time.sleep(1)
#关闭当前驱动器
driver.quit()selenium的webdriver主要还是定位。。。定位方法有CSS定位器跟XPath或者使用id,这里不详细解释,请自行使用
学校要求挂英语网站时间达到30个小时,但是那破网站一直断。所以,咳咳。。本文简单使用不断刷新的方法保持英语网站的Cookies
#coding = utf-8"""author: 贯穿真Shtime: 2018年5月30日21:50:10"""
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import timedef english_login():"""使用Chrome登录高校外语教学平台返回值 - webdriver"""#创建使用的浏览器driver = webdriver.Chrome()#登录网址driver.get('http://learn.unipus.cn')while True:username = input("请输入账号:")password = input("请输入密码:")#进行登录操作,键入相应的账号密码,定位使用XPATHdriver.find_element_by_xpath('//*[@id="username"]').send_keys(username)driver.find_element_by_xpath('//*[@id="password"]').send_keys(password)#按下一个按钮,定位使用CSS定位器driver.find_element_by_css_selector('#LoginForm > table > tbody > tr:nth-child(3) > td:nth-child(2) > input').click()#隐式等待time.sleep(2)#若登录失败则重新登录try:error = driver.find_element_by_css_selector('body > div:nth-child(3) > div.newlogin_box > div.newlogin_boxnew > div.rightlogin_box > div.third_rightwords > span')if error.text == '您输入的账号/密码有错。\n或是账号已经失效。':print('登录失败,请重新登录')driver.find_element_by_xpath('//*[@id="username"]').clear()except:print('登录成功')return driverdef into_fresh(driver):#显式等待时间设置为10秒wait = WebDriverWait(driver, 10)#创建一个可点击按钮对象link1 = EC.element_to_be_clickable((By.CSS_SELECTOR, '#BookClassDIV > table > tbody > tr > td:nth-child(2) > ul > li:nth-child(10) > a'))#显示等待按钮出现,直到按钮可以被按下wait.until(link1).click()link2 = EC.element_to_be_clickable((By.CSS_SELECTOR, '#ico > ul > p:nth-child(1) > a'))wait.until(link2).click()#隐式等待2stime.sleep(2)#wait.until(EC.frame_to_be_available_and_switch_to_it(driver.window_handles[1])) #不知用显示等待报错#切换选项卡driver.switch_to_window(driver.window_handles[1])link3 = EC.element_to_be_clickable((By.CSS_SELECTOR, 'body > div.box > div:nth-child(2) > ul > li:nth-child(2) > a > img'))wait.until(link3).click()#循环刷新while True:#刷新当前页面driver.refresh()#打印当前时间now = time.strftime("%Y-%m-%d %H:%M:%S",time.localtime())print(now)time.sleep(60)if __name__ == '__main__':driver = english_login()into_fresh(driver)子页面frame
如果你用CSS定位器定位不到,那可能是因为在子页面即frame里, 需要切换到子页面里定位
就一句switch_to_frame。然后用完切回父节点






![[转]开发大型高负载类网站应用的几个要点](http://www.phpchina.com/bbs/images/smilies/smile.gif)
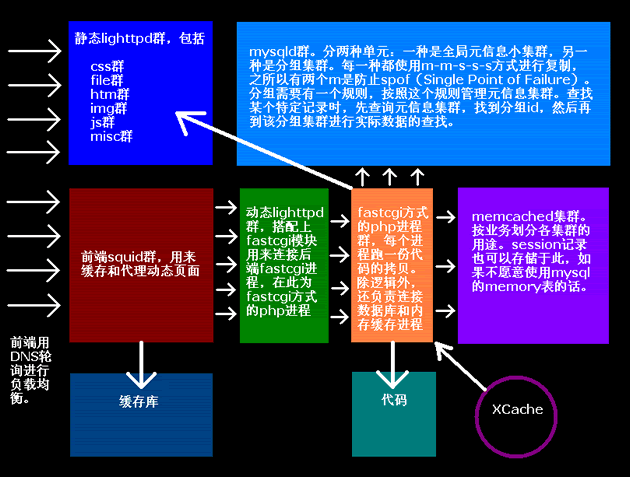
![[转]从LiveJournal后台发展看大规模网站性能优化方法](http://www.example.net.cn/archives/LJ-backend-6.png)
![邀请PHP开发工程师加盟Web3.0新锐网站[工作地点-北京财智国际大厦]](http://static.flickr.com/37/83758606_9404f013c1_m.jpg)