Windows 10家庭中文版,Python 3.6.3,Scrapy 1.5.0,
时隔一月,再次玩Scrapy项目,希望这次可以玩的更进一步。
本文展示使用在 Scrapy项目内、项目外scrapy shell命令抓取知乎首页的初步情况,重要的一点是,在项目内抓取时,没有response可用。
在项目【外】执行抓取命令
scrapy shell https://www.zhihu.com
得到结果(部分):因为知乎的反爬虫功能,得到了400错误,访问失败。
INFO: Overridden settings: {'DUPEFILTER_CLASS': 'scrapy.dupefilters.BaseDupeFilter', 'LOGSTATS_INTERVAL': 0}
[]
2018-08-20 09:11:54 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
2018-08-20 09:11:54 [scrapy.core.engine] INFO: Spider opened
2018-08-20 09:11:59 [scrapy.core.engine] DEBUG: Crawled (400) <GET https://www.zhihu.com> (referer: None)
可用对象如下图:存在response!

在项目【内】执行抓取命令
scrapy shell https://www.zhihu.com
注意,项目使用scrapy startproject命令创建,已经在其settings.py中添加了USER_AGENT配置项。
得到结果(部分):多了很多内容,还包括USER_AGENT设置。最后服务器返回200,表示页面访问成功。
INFO: Overridden settings: {'BOT_NAME': 'newssci', 'DUPEFILTER_CLASS': 'scrapy.dupefilters.BaseDupeFilter', 'LOGSTATS_INTERVAL': 0, 'NEWSPIDER_MODULE': 'newssci.spiders', 'ROBOTSTXT_OBEY': True, 'SPIDER_MODULES': ['newssci.spiders'], 'USER_AGENT': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36-480'}
[]
2018-08-20 09:12:23 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
2018-08-20 09:12:23 [scrapy.core.engine] INFO: Spider opened
2018-08-20 09:12:24 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://www.zhihu.com/robots.txt> (referer: None)
2018-08-20 09:12:24 [scrapy.downloadermiddlewares.robotstxt] DEBUG: Forbidden by robots.txt: <GET https://www.zhihu.com>
可用对象如下图:没有response对象!还少了spider对象!
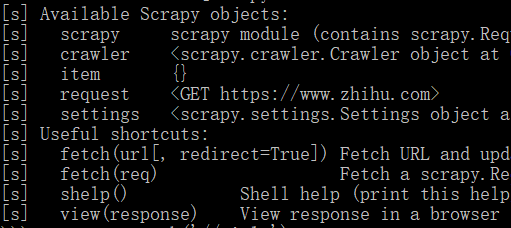
没有response对象,感觉什么也做不了了,网页也无法分析了。
总结
看来,还是需要到 项目外 使用scrapy shell命令来对网页做分析才是。不过,对于这种反爬虫的网站,在命令中添加上USER_AGENT配置项,然后就可以用response来做分析了。
项目外添加USER_AGENT配置项的命令如下:-s
scrapy shell -s USER_AGENT="Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36-480" https://www.zhihu.com
结果如下:发生了一次重定向,所以有302。
INFO: Overridden settings: {'DUPEFILTER_CLASS': 'scrapy.dupefilters.BaseDupeFilter', 'LOGSTATS_INTERVAL': 0, 'USER_AGENT': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36-480'}
[scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (302) to <GET https://www.zhihu.com/signup?next=%2F> from <GET https://www.zhihu.com>
[scrapy.core.engine] DEBUG: Crawled (200) <GET https://www.zhihu.com/signup?next=%2F> (referer: None)
发现了response对象可用:指明是针对其后的那个200网址的
[s] response <200 https://www.zhihu.com/signup?next=%2F>
使用response对象:获取页面title成功!
>>> response.xpath('//title/text()')
[<Selector xpath='//title/text()' data='知乎 - 发现更大的世界'>]