1 创建 scrapy startproject shetu 这里我爬的是摄图网
2 cd 到目录
3创建 scrapy genspider -t crawl 爬虫名字 域名

4 在items 指定好对象 根据自己的需求写
import scrapyclass ShetuItem(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()img_name = scrapy.Field()img_url = scrapy.Field()img_time = scrapy.Field()img_looknum = scrapy.Field()img_collect = scrapy.Field()img_down = scrapy.Field()
5在pipelines.py中 将爬去的内容 存入文本中
import json
class ShetuPipeline(object):def open_spider(self,spider): #打开文件self.fp = open('shetu.txt','w',encoding='utf8')def close_spider(self,spiser): #关闭文件self.fp.close()def process_item(self, item, spider): #转化内容格式dic = dict(item)string = json.dumps(dic,ensure_ascii=False)self.fp.write(string + "\n")return item
6 在setting.py中,配置
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36'#配置user-agent
ROBOTSTXT_OBEY = False #是否遵守规则
DOWNLOAD_DELAY = 3#设置爬取时间
ITEM_PIPELINES = {'shetu.pipelines.ShetuPipeline': 300,
}#打开pipelines通道
7最后image.py #image自己创建的
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from shetu.items import ShetuItemclass ImageSpider(CrawlSpider):name = 'image'allowed_domains = ['699pic.com']start_urls = ['http://699pic.com/people.html']xiangxi_link = LinkExtractor(restrict_xpaths='//div[@class = "list"]/a')page_link = LinkExtractor(restrict_xpaths='//div[@class = "pager-linkPage"]/a')rules = (Rule(xiangxi_link, callback='parse_item', follow=False))def parse_item(self, response):item = ShetuItem()# 照片名字img_name = response.xpath('//div[@class="photo-view"]/h1/text()')[0].extract()# 照片urlimg_url = response.xpath('//div[@class="huabu"]/a/img/@src')[0].extract()# 照片发布时间img_time = response.xpath('//div[@class="photo-view"]/div/span[@class="publicityt"]/text()')[0].extract()# 照片浏览量img_looknum = response.xpath('//div[@class="photo-view"]/div/span[@class="look"]/read/text()')[0].extract()# 收藏量img_collect = response.xpath('//div[@class="photo-view"]/div/span[@class="collect"]/text()')[0].extract().strip("收藏")# 下载量img_down = response.xpath('//div[@class="photo-view"]/div/span[@class="download"]/text()')[1].extract().strip("\n\t下载")for field in item.fields.keys(): # 取出所有的键item[field] = eval(field)yield item
8 启动爬虫scrapy crawl image
9 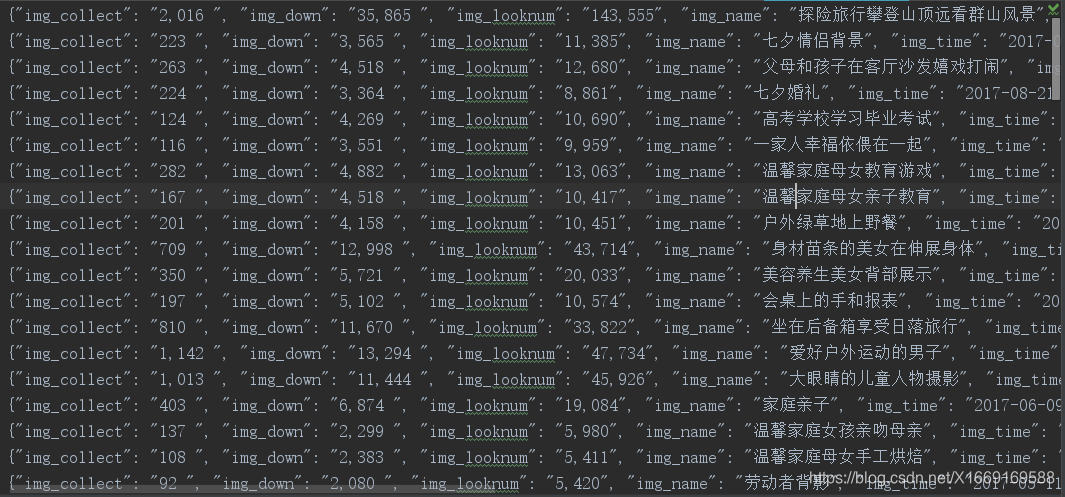
爬去内容






![[HTML CSS JavaScript JQuery Bootstrap 开发] 由浅到深,搭建网站首页,实现轮播图](https://img-blog.csdnimg.cn/20190511104701194.png)