一、piplines文件的使用
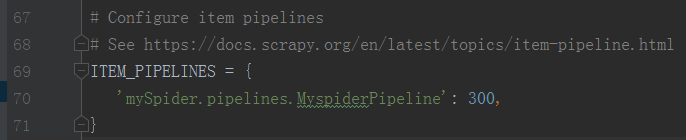
1、 开启管道
在settings.py文件中取消以下注释:
ITEM_PIPELINES = {
‘mySpider.pipelines.MyspiderPipeline’: 300,
}
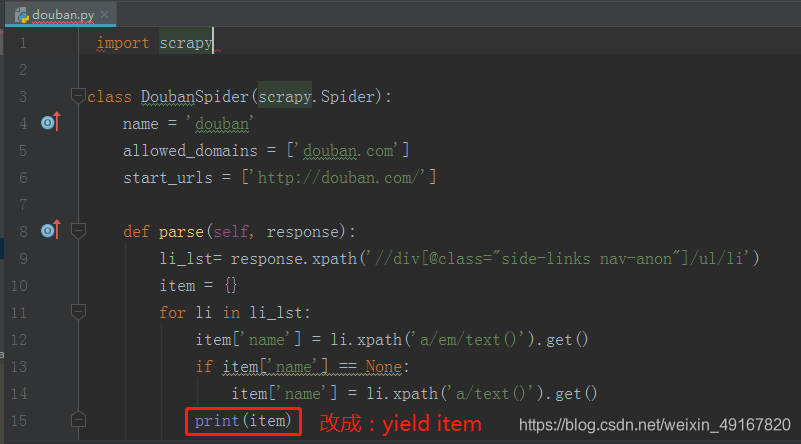
2 、回到爬虫文件当中,把数据yield 给管道。
为什么是yield的原因:
- 不会浪费内存
- 翻页的逻辑 scrapy.Requst(url,callback,…) 通过yield来返回
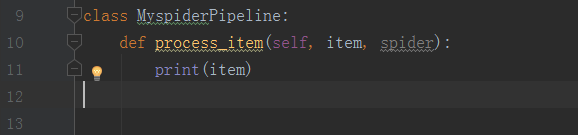
3、在管道文件中打印或者保存等
(1)打印举例
(2)保存到txt文件举例
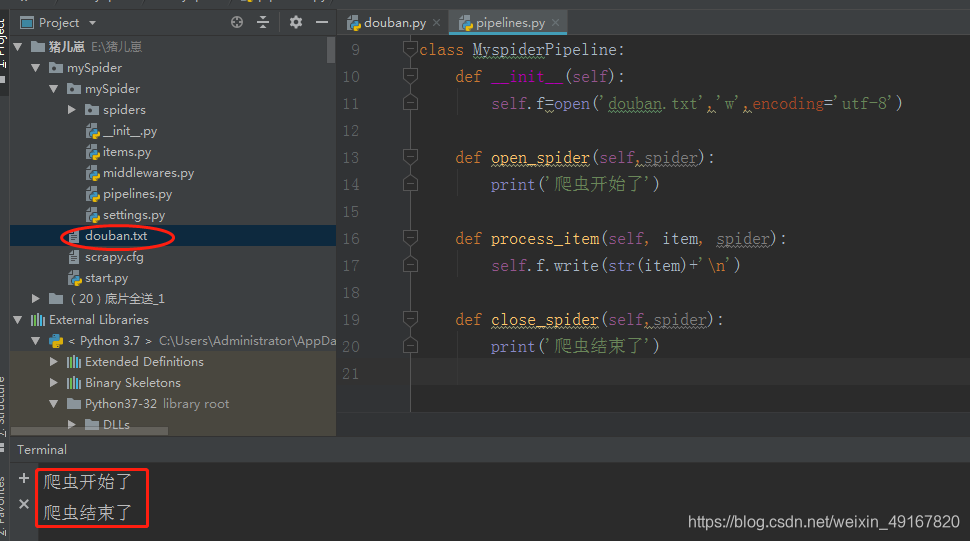
补充:(1)pipeline中process_item方法名不能修改为其他的名称
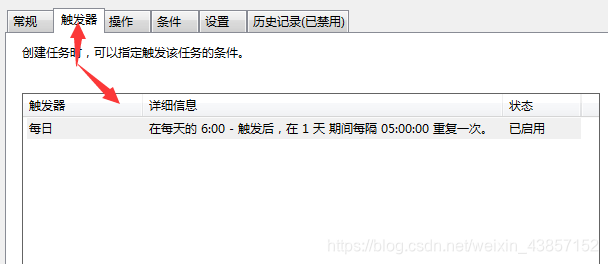
(2)管道当中的参数spider是什么?如下图:
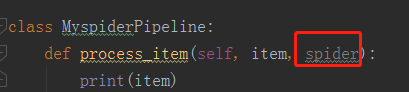
从下图可知,它就是爬虫文件中的class DoubanSpider
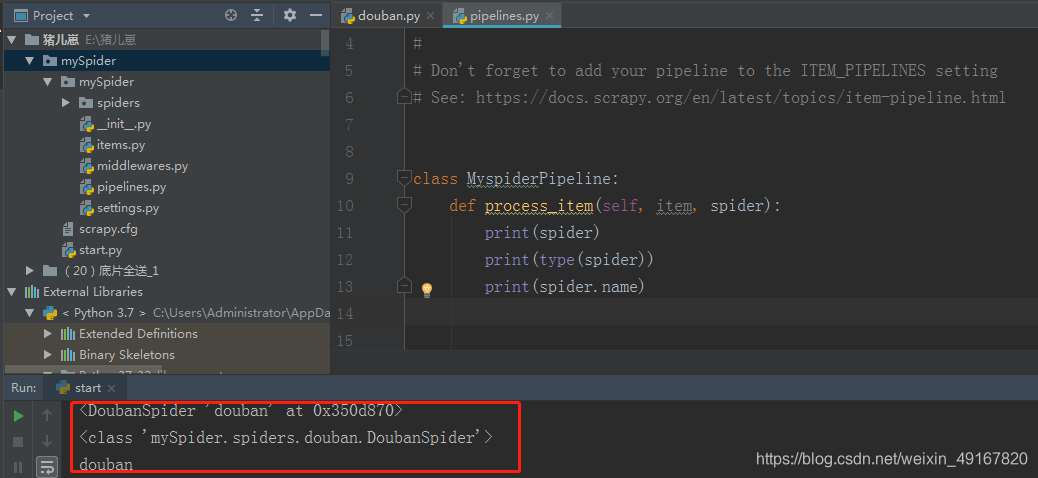
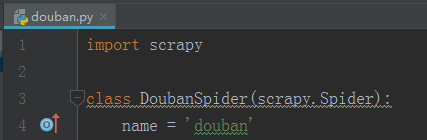
见下图:
二、简单案例:scrapy爬取古诗文网站
需求: 爬取古诗文网站中的 诗词的 标题 作者 朝代 内容 以及翻页 并保存
第一步 页面分析
(1)我们发现有2种翻页方式:(且有不同的url)
点击下一页的方式,url规律如下,
https://www.gushiwen.org/default_1.aspx 第一页
https://www.gushiwen.cn/default_2.aspx 第二页
https://www.gushiwen.cn/default_3.aspx 第三页
那么,输入数字方式的url就可以忽略,https://www.gushiwen.cn/default.aspx?page=2 第二页 。
主域名:’gushiwen.org’、 ‘gushiwen.cn’
(2)通过页面结构分析 :所有的诗词内容都是在class=left的div标签之中, 然后在去找它下面的每一个 sons对应一首诗,然后去遍历我们需要提取的数据。
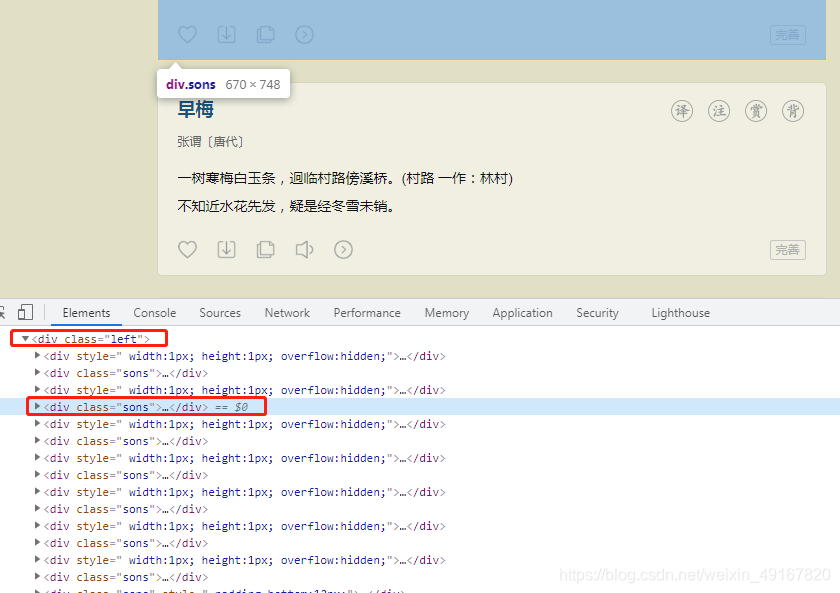
第二步 实现步骤
1 创建scrapy项目
scrapy startproject gsSpider
2 创建爬虫
scrapy genspider gs gushiwen.cn
3 逻辑的实现
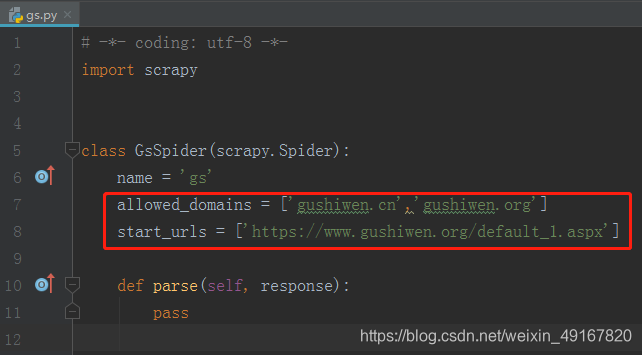
(1)因为有2个主域名,所以打开爬虫文件添加另一个主域名’gushiwen.org’,并将起始的url改成第一页的url
(2)编写解析函数
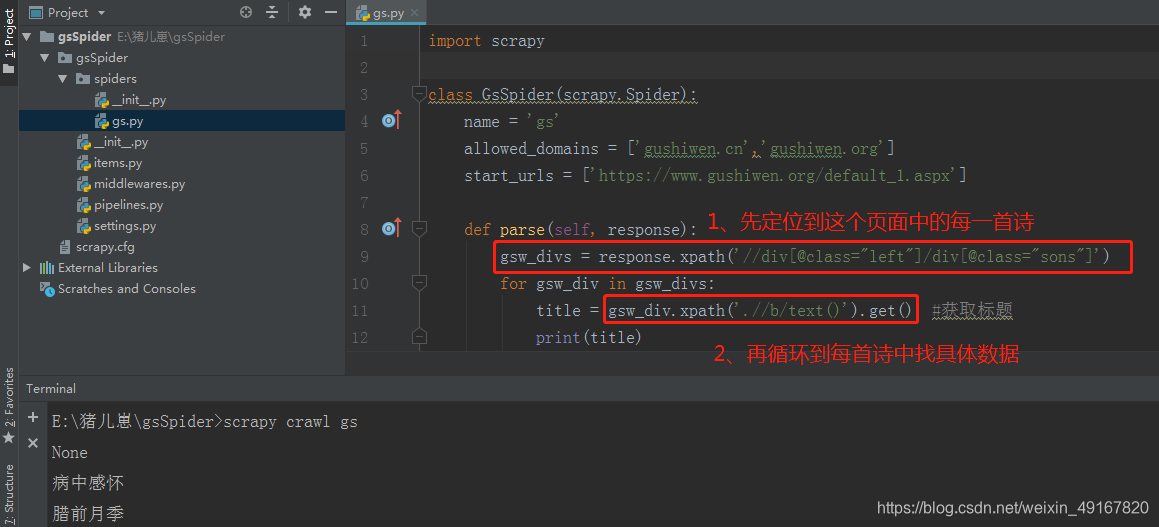
import scrapyclass GsSpider(scrapy.Spider):name = 'gs'allowed_domains = ['gushiwen.cn','gushiwen.org']start_urls = ['https://www.gushiwen.org/default_1.aspx']def parse(self, response):gsw_divs = response.xpath('//div[@class="left"]/div[@class="sons"]')for gsw_div in gsw_divs:title = gsw_div.xpath('.//b/text()').get() #获取标题print(title)# 获取作者和朝代source = gsw_div.xpath('.//p[@class="source"]/a/text()').extract()# author = source[0]# dynasty = source[1]# print(author, dynasty)# 获取内容content_lst = gsw_div.xpath('.//div[@class="contson"]//text()').extract()content = ''.join(content_lst).strip()print(content)
备注:
① extract()是旧方法,其效果和getall()一样。
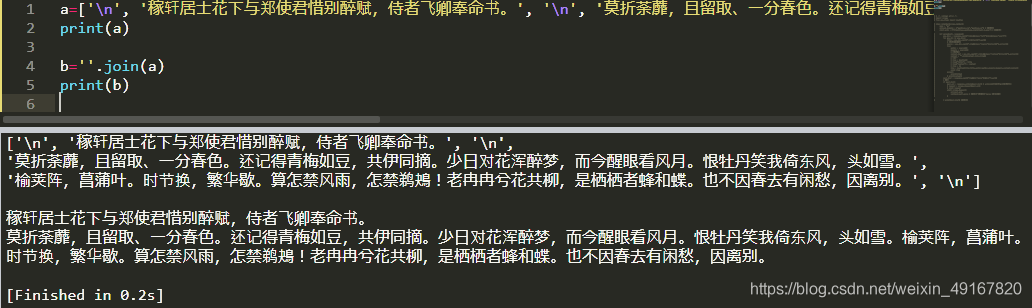
② join() 方法:以指定的方式把字符串或列表连接成一个新的字符串,并返回。
(3)注册items.py文件中的要素,并在爬虫文件中引用,并在管道文件中打印item
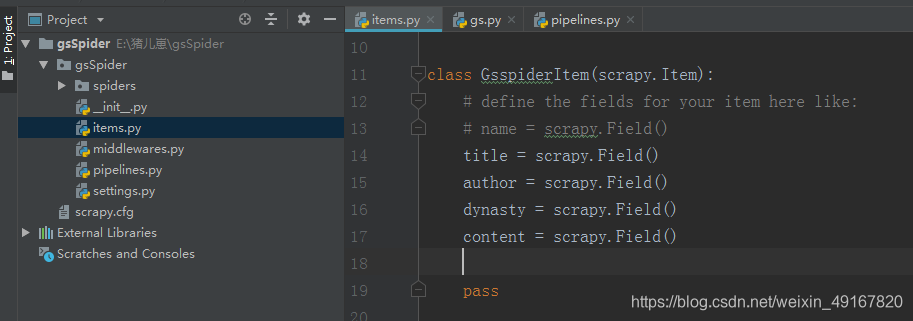

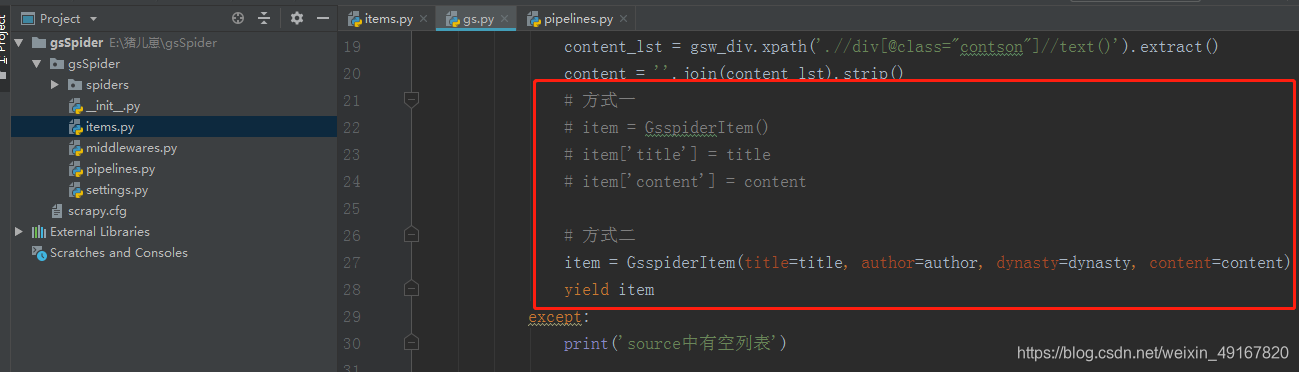

结果:

结果没有问题,那么就保存数据。
(4)在管道中保存数据
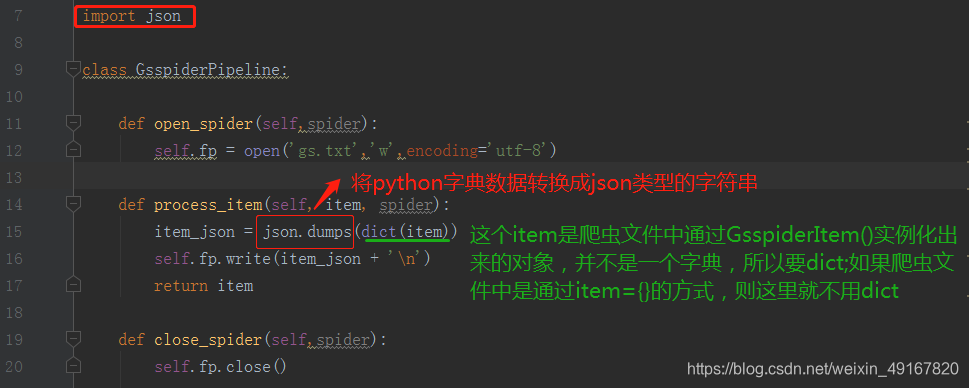
注意:在使用json.dumps()转换数据时,是否要加dict这个小细节
结果:
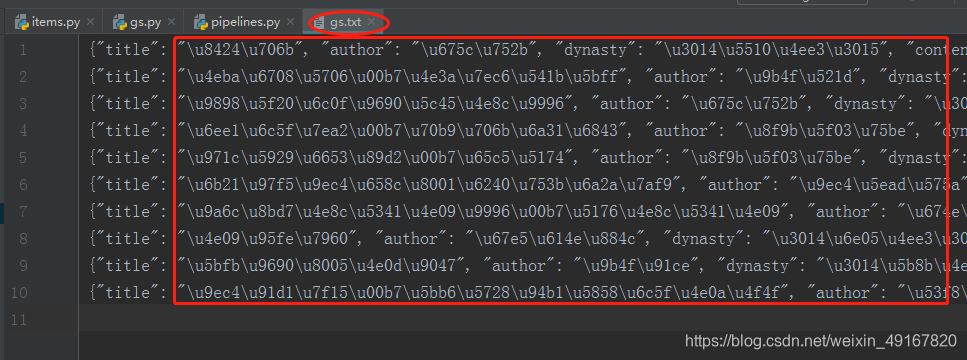
我们在json.dumps()中添加参数:ensure_ascii=False
class GsspiderPipeline:def open_spider(self,spider):self.fp = open('gs.txt','w',encoding='utf-8')def process_item(self, item, spider):item_json = json.dumps(dict(item),ensure_ascii=False)self.fp.write(item_json + '\n')return itemdef close_spider(self,spider):self.fp.close()
补充:
json.dumps()
序列化:将“python字典数据结构”转换为“json字符串”。
json在进行序列化时,默认使用的编码是ASCII,而中文为Unicode编码,ASCII中不包含中文,所以出现了乱码。想要json.dumps()能正常显示中文,只要加入参数ensure_ascii=False即可,这样json在序列化的时候,就不会使用默认的ASCII编码。
结果:

(5)翻页的实现
我们检查发现,下一页按钮中有一个href属性的值,对应的就是下一页的url地址:
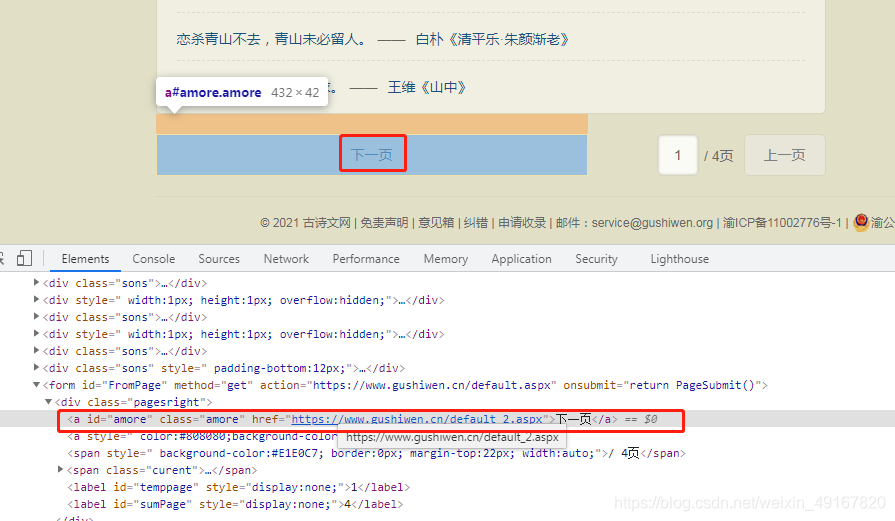
我们把爬虫文件中的解析函数先注释掉后,现在就只简单的实现翻页功能:
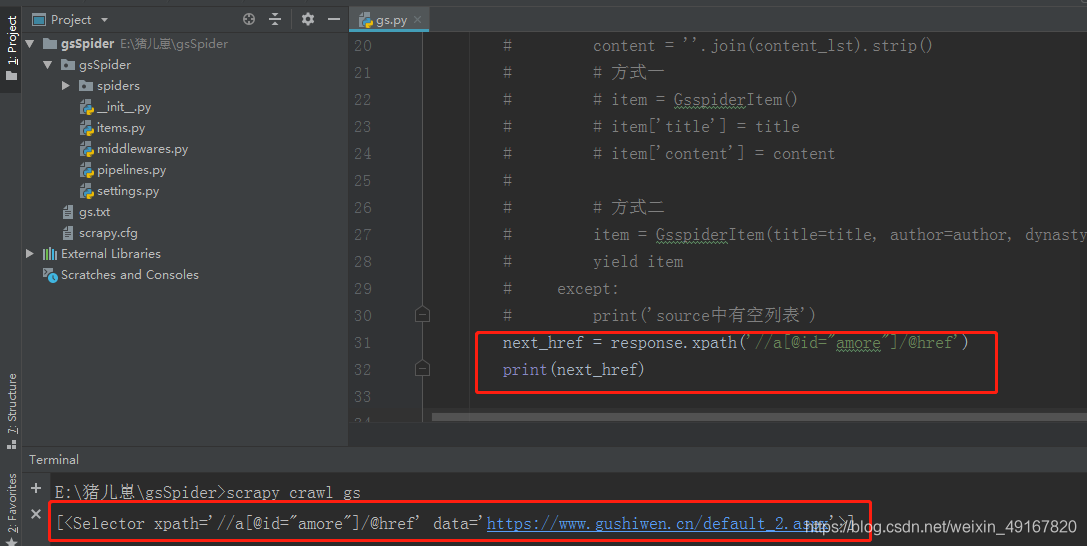
运行后得到的结果是一个selector,那么加上一个get()
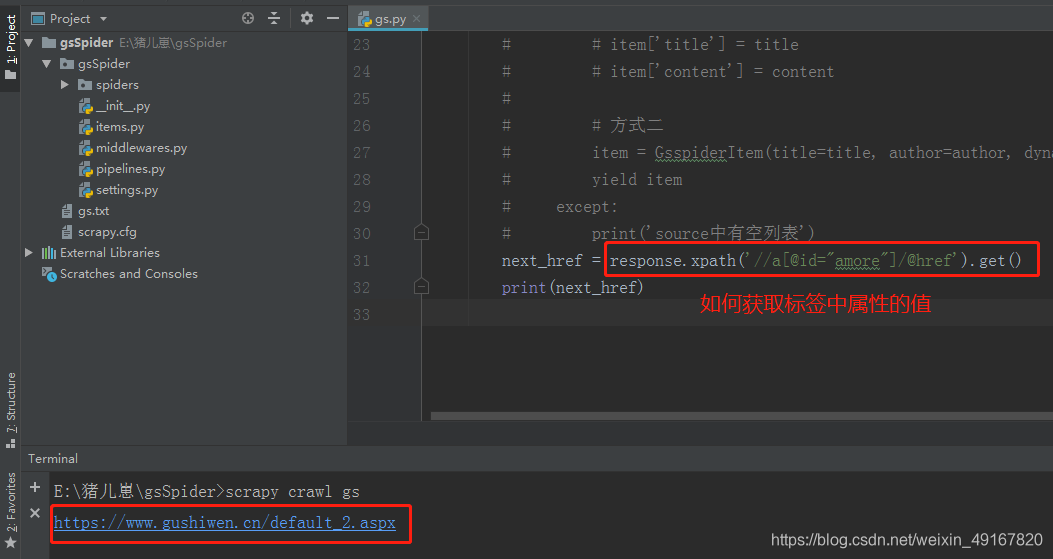
这样就得到了下一页的url,同时我发现在第二页的检查中,得到的可能是下一页url的后缀,所以用urljoin()来补全地址。
因为页数一共有4页,在第4页的时候就没有下一页了,所以我们先用if做个存在的判断:
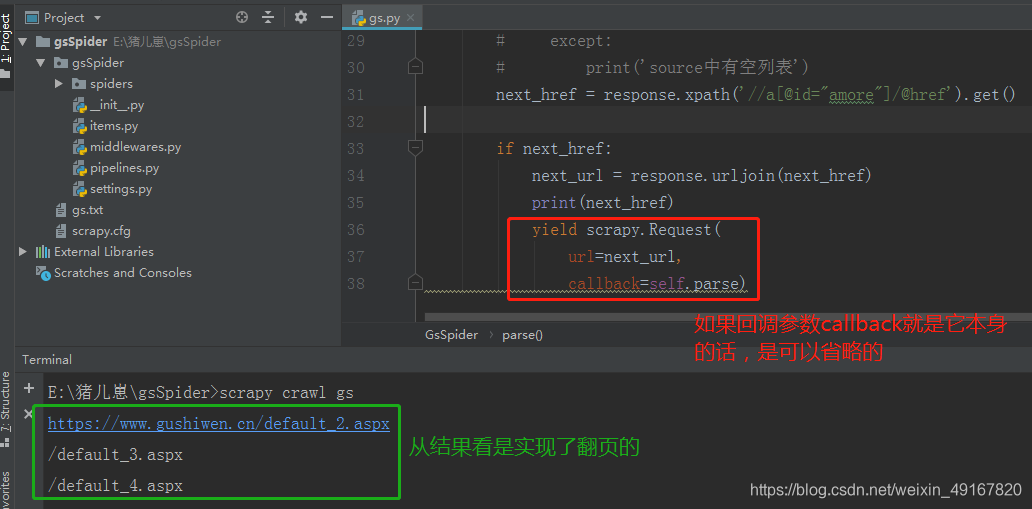
scrapy.Request(url=next_url,callback=self.parse)
url:请求的url
callback:回调函数,用于接收请求后的返回信息(也就是将响应作为参数传递给回调函数),若没指定,则默认为parse()函数
所以可以进一步简写成:
所以打开之前的注释,就是整个爬虫文件的代码:
import scrapy
from gsSpider.items import GsspiderItemclass GsSpider(scrapy.Spider):name = 'gs'allowed_domains = ['gushiwen.cn','gushiwen.org']start_urls = ['https://www.gushiwen.org/default_1.aspx']def parse(self, response):gsw_divs = response.xpath('//div[@class="left"]/div[@class="sons"]')for gsw_div in gsw_divs:title = gsw_div.xpath('.//b/text()').get() #获取标题# 获取作者和朝代source = gsw_div.xpath('.//p[@class="source"]/a/text()').extract()try:author = source[0]dynasty = source[1]# 获取内容content_lst = gsw_div.xpath('.//div[@class="contson"]//text()').extract()content = ''.join(content_lst).strip()# 方式一# item = GsspiderItem()# item['title'] = title# item['content'] = content# 方式二item = GsspiderItem(title=title, author=author, dynasty=dynasty, content=content)yield itemexcept:print('source中有空列表')#翻页 next_href = response.xpath('//a[@id="amore"]/@href').get()if next_href:next_url = response.urljoin(next_href)print(next_href)yield scrapy.Request(next_url)
运行后得到gs.txt文件如下:
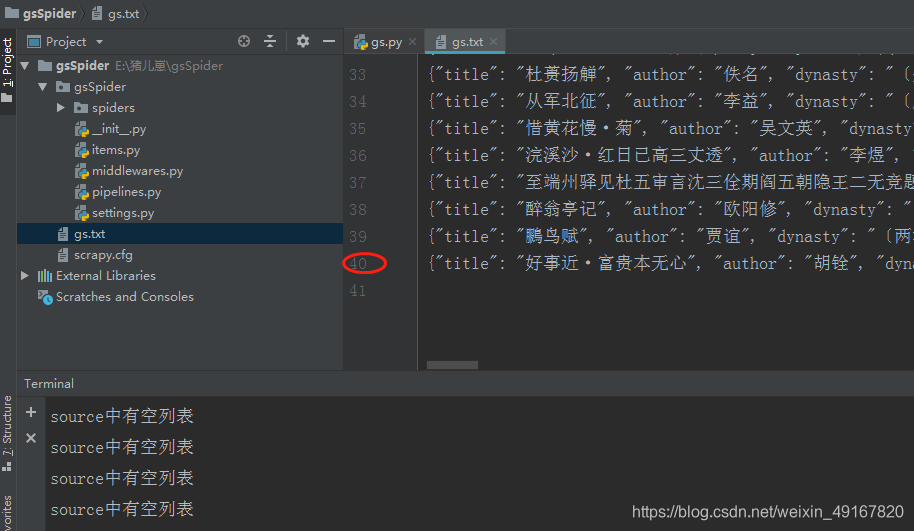
和网页总共的数量40首一致,没有问题。
小结:
1 如何处理 列表为空的数据 :
(1)可以做非空判断 例如豆瓣
(2)可以通过 try语句进行处理
2 翻页处理
(1) 可以找页数的规律
(2)直接找下一页的Url地址 然后 yield scrapy.Request(next_url)
3 遇到Url不全的时候 建议还是补全
(1)拼串
(2)urljoin() 这个是scrapy提供的