如图:
kenne
我们点击查看网页原代码,发现隐藏的数据并不在原代码中,

我们点击检查-network-再点击展开阅读全文
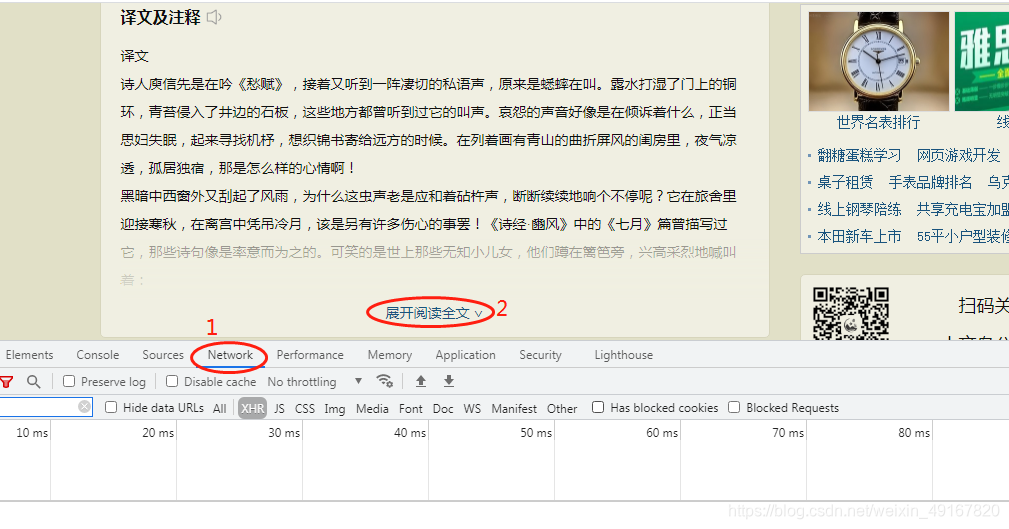
在又加载出来的数据中,找到下图椭圆框中的Response,发现这里有完整的译文及注释。由此我打开其Headers中的url,并确认这就是完整的译文及注释的目标url:
https://so.gushiwen.cn/nocdn/ajaxfanyi.aspx?id=C72E5FE381F0B4E0
我们再找一个:https://so.gushiwen.cn/nocdn/ajaxfanyi.aspx?id=F1E16D76441AA037
发现目标url的后缀没有什么数学规律,那么我们要去哪里获取后缀呢?
在网页原代码中,我们发现了该后缀。

所以,方法就是获取原代码的response后用正则表达式匹配获取完整译文及注释的url后缀,拼接出该目标url。
完整代码如下:
import re
from lxml import etree
import scrapy
import requests
from gsSpider.items import GsspiderItemclass GsSpider(scrapy.Spider):name = 'gs'allowed_domains = ['gushiwen.cn']start_urls = ['https://www.gushiwen.cn/default_1.aspx']def parse_data(self, response):html_text = response.xpath('//div[@id="sonsyuanwen"][1]/div[@class="cont"]')title = html_text.xpath('./h1/text()').get()author = html_text.xpath('./p[@class="source"]/a[1]/text()').get()dynasty = html_text.xpath('./p[@class="source"]/a[2]/text()').get()content_list = html_text.xpath('./div[@class="contson"]//text()').getall()content = ''.join(content_list).strip()# 取得“展开阅读全文”链接,如果有则提取ajax页的译文和注释,没有则提取本页上的译文和注释html_href = response.xpath('//a[@style="text-decoration:none;"]/@href').get()if html_href:html_href_id = re.match(r"javascript:.*?,'(.*?)'.*?", str(html_href)).group(1)html_href_url = 'https://so.gushiwen.cn/nocdn/ajaxfanyi.aspx?id=' + html_href_idparse_html = etree.HTML(requests.get(html_href_url).text)html_fanyi = parse_html.xpath('//div[@class="contyishang"]//text()')else:html_fanyi = response.xpath('//div[@class="left"]/div[@class="sons"][2]/div[@class="contyishang"]//text()').getall()html_fanyi = ''.join(html_fanyi).replace('\n', '').replace('译文及注释', '').replace('译文', '').replace('注释', '|')if html_fanyi:fanyi = html_fanyi.split('|')translation = fanyi[0]notes = fanyi[1]else:translation = ''notes = ''item = GswItem(title=title,author=author,dynasty=dynasty,content=content,translation=translation,notes=notes)yield itemdef parse(self, response):html = response.xpath('//div[@class="left"]/div[@class="sons"]')gsw_divs = html.xpath('./div[@class="cont"]')# 过滤非正常诗文,并提取诗文详细内容链接if gsw_divs:for gsw_div in gsw_divs:if gsw_div.xpath('./div[@class="yizhu"]'):href = gsw_div.xpath('./p/a/@href').get()href_url = response.urljoin(href)yield scrapy.Request(url=href_url, callback=self.parse_data)# 取得下一页链接next_page = response.xpath('//a[@id="amore"]/@href').get()if next_page:next_url = response.urljoin(next_page)yield scrapy.Request(url=next_url, callback=self.parse)
结果:

补充: