这篇文章是利用aiohttp这个库来进行说明的。
如果爬虫需要展现速度,我觉得就是去下载图片吧,原本是想选择去煎蛋那里下载图片的,那里的美女图片都是高质量的,我稿子都是差不多写好了的,无奈今天重新看下,妹子图的入口给关了,至于为什么关呢,大家可以去看看昨天好奇心日报的关停原因吧或者百度下,这里就不多说了,这次我选择了去下载无版权高清图片,因为做自媒体的人很怕侵权,找无版权的图片仿佛成了日常工作,所以这次我选择了这个网站。
学习Python中有不明白推荐加入交流裙
号:735934841
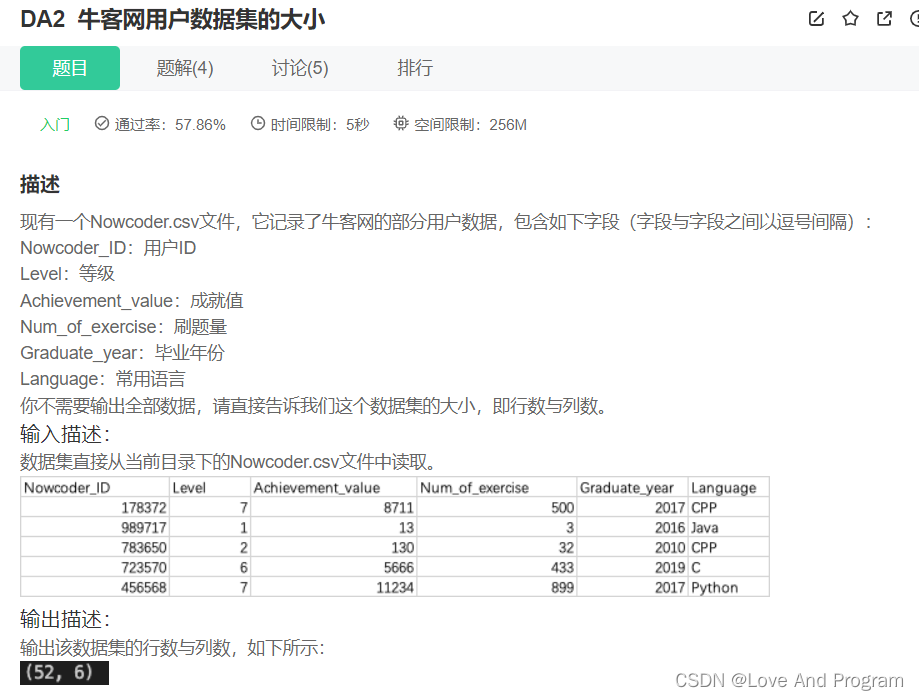
群里有志同道合的小伙伴,互帮互助,
群里有免费的视频学习教程和PDF!

那下面来看看使用异步以及不使用异步的差别?

(右边是使用异步的,左边是没有使用异步的,由于用于测试,所以选择下载12张图片即可)
可以看到,在使用异步之后运行的时间比不使用异步的程序少了差不多6倍的时间,是不是感觉到high了起来?那我们分析下怎样爬取吧。
1.找目标网页
这个网站首页就有一堆图片,而且往下拉时还会自动刷新,很明显是个ajax加载,但不怕,动态加载这东西我们之前讲过了,所以打开开发者工具看下是怎样的请求吧。


往下拉的时候很容易看到这个请求,这个是一个get请求,状态码为200,网址为网页链接photos?page=3&per_page=12&order_by=latest,有三个参数,很容易知道page参数就是页,这个参数是变化的,其他的参数都是不变的。
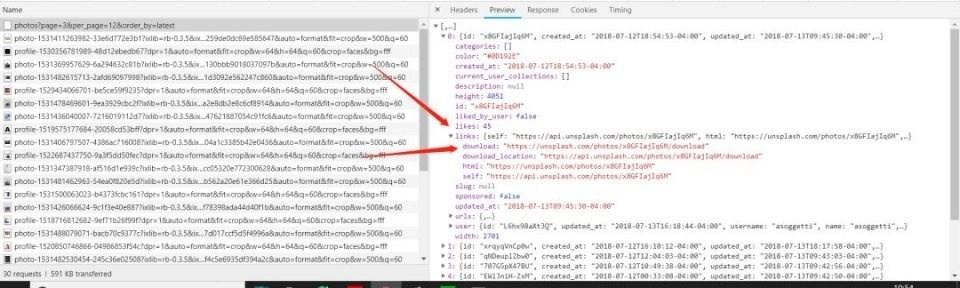
返回来的内容是个json类型,里面的links下的download就是我们图片下载的链接,现在所有东西都清楚了,那下面就是代码了。
2.代码部分
async def __get_content(self, link):
async with aiohttp.ClientSession as session:
response = await session.get(link)
content = await response.read
return content
这个是获取图片的内容的方法,aiohttpClientSession和requests.session的用法是差不多,只不过获取unicode编码的方法变成了read。
下面是完整代码
import requests, os, time
import aiohttp, asyncio
class Spider(object):
def __init__(self):
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99Safari/537.36'}
self.num = 1
if '图片' not in os.listdir('.'):
os.mkdir('图片')
self.path = os.path.join(os.path.abspath('.'), '图片')
os.chdir(self.path) # 进入文件下载路径
async def __get_content(self, link):
async with aiohttp.ClientSession as session:
response = await session.get(link)
content = await response.read
return content
def __get_img_links(self, page):
url = '网页链接photos'
data = {
'page': page,
'per_page': 12,
'order_by': 'latest'
}
response = requests.get(url, params=data)
if response.status_code == 200:
return response.json
else:
print('请求失败,状态码为%s' % response.status_code)
async def __download_img(self, img):
content = await self.__get_content(img[1])
with open(img[0]+'.jpg', 'wb') as f:
f.write(content)
print('下载第%s张图片成功' % self.num)
self.num += 1
def run(self):
start = time.time
for x in range(1, 101): # 下载一百页的图片就可以了,或者自己更改页数
links = self.__get_img_links(x)
tasks = [asyncio.ensure_future(self.__download_img((link['id'], link['links']['download']))) for link in links]
loop = asyncio.get_event_loop
loop.run_until_complete(asyncio.wait(tasks))
if self.num >= 10: # 测试速度使用,如需要下载多张图片可以注释这段代码
break
end = time.time
print('共运行了%s秒' % (end-start))
def main:
spider = Spider
spider.run
if __name__ == '__main__':
main
可以看到不到50行的代码就可以把整个网网站的图片下载下来了,不得不吹一下python的强大~~~