爬取boss数据并保存到mysql
boss的反爬虫控制尤其恶心 cookies大概用3次左右就不能用了
所以爬取不了太多东西 只可用来学习
等学习完逆向爬虫课程 再来挑战挑战
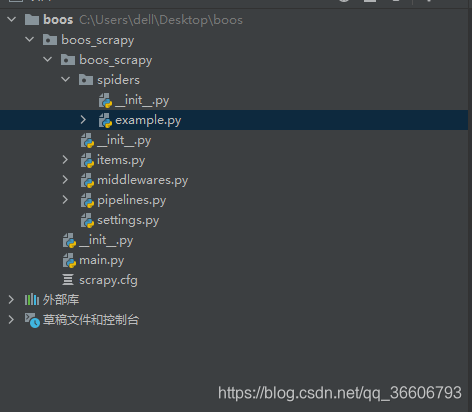
example.py
import scrapy
from bs4 import BeautifulSoup
from boos_scrapy.items import BoosScrapyItem
from time import sleepclass ExampleSpider(scrapy.Spider):name = 'example'# allowed_domains = ['example.com']start_urls = ['https://www.zhipin.com/c101280100/?query=%E8%BD%AF%E4%BB%B6%E6%B5%8B%E8%AF%95%E5%B7%A5%E7%A8%8B%E5%B8%88&page=1&ka=page-1']url = "https://www.zhipin.com/c101280100/?query=%E8%BD%AF%E4%BB%B6%E6%B5%8B%E8%AF%95%E5%B7%A5%E7%A8%8B%E5%B8%88&page={0}&ka=page-{1}"page_num = 2def parse(self, response):li_list = response.xpath('//*[@class="job-list"]/ul/li')for li in li_list:job_tags = li.xpath('.//div/div[2]/div[2]/text()').extract_first()#福利待遇title = li.xpath('.//div/div[1]/div[1]/div/div[1]/span[1]/a/text()').extract_first()#招聘职位salary = li.xpath('.//div/div[1]/div[1]/div/div[2]/span/text()').extract_first() #薪资待遇particulars = li.xpath('.//div[1]/div[1]/div/div[1]/span[1]/a/@href').extract_first() #详情地址boos_url = "https://www.zhipin.com" + particulars item = BoosScrapyItem()item['job_tags'] = job_tagsitem['title'] = titleitem['salary'] = salary#回调函数yield scrapy.Request(boos_url,callback=self.parse_detail,meta={'item':item})if self.page_num <= 3:new_url = format(self.url%(self.page_num,self.page_num))self.page_num+=1yield scrapy.Request(new_url,callback=self.parse)#进行详情页爬取def parse_detail(self,response):item = response.meta['item']job_sec = ''.join(response.xpath('//*[@id="main"]/div[3]/div/div[2]/div[2]/div[1]/div/text()').extract()).strip() #职位描述company = ''.join(response.xpath('//*[@id="main"]/div[3]/div/div[2]/div[2]/div[2]/div/text()').extract()).strip() #公司介绍job_location = ''.join(response.xpath('//*[@id="main"]/div[3]/div/div[2]/div[2]/div[6]/div/div[1]/text()').extract()).strip()#公司地址item['job_sec'] = job_secitem['company'] = companyitem['job_location'] = job_locationyield item
items.py
import scrapyclass BoosScrapyItem(scrapy.Item):company=scrapy.Field()job_location=scrapy.Field()job_tags=scrapy.Field()title=scrapy.Field()salary=scrapy.Field()job_sec=scrapy.Field()
middlewares.py
from scrapy import signals
import random,json
from itemadapter import is_item, ItemAdapterclass BoosScrapySpiderMiddleware:@classmethoddef from_crawler(cls, crawler):s = cls()crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)return sdef process_spider_input(self, response, spider):return Nonedef process_spider_output(self, response, result, spider):for i in result:yield idef process_spider_exception(self, response, exception, spider):passdef process_start_requests(self, start_requests, spider):for r in start_requests:yield rdef spider_opened(self, spider):spider.logger.info('Spider opened: %s' % spider.name)class BoosScrapyDownloaderMiddleware:user_agent_list = ["Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 ""(KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1","Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 ""(KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 ""(KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6","Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 ""(KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6","Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 ""(KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1","Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 ""(KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5","Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 ""(KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 ""(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3","Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 ""(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3","Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 ""(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3","Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 ""(KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 ""(KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3","Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 ""(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 ""(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3","Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 ""(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3","Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 ""(KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3","Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 ""(KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24","Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 ""(KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"]#可用代理池PROXY_http = ['127.0.0.1:7890']PROXY_https = ['127.0.0.1:7890']@classmethoddef from_crawler(cls, crawler):# This method is used by Scrapy to create your spiders.s = cls()crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)return s#拦截请求def process_request(self, request, spider):#UA伪装cookies="填写自己cookies"cookies = {i.split("=")[0]:i.split("=")[1] for i in cookies.split("; ")}request.cookies = cookiesrequest.headers['User-Agent'] = random.choice(self.user_agent_list)return Nonedef process_response(self, request, response, spider):return responsedef process_exception(self, request, exception, spider):if request.url.split(':')[0] == 'http':#代理request.meta['proxy'] = 'http://'+random.choice(self.PROXY_http)else:request.meta['proxy'] = 'https://' + random.choice(self.PROXY_https)return request #将修正之后的请求对象进行重新的请求发送def spider_opened(self, spider):spider.logger.info('Spider opened: %s' % spider.name)
pipelines.py
import pymysqlclass BoosScrapyPipeline:def process_item(self, item, spider):return itemclass mysqlPileLine(object):conn = Nonecursor = Nonedef open_spider(self,spider):self.conn = pymysql.Connect(host='127.0.0.1',port=3306,user='root',passwd='123456',db='taobao',charset='utf8')def process_item(self,item,spider):self.cursor = self.conn.cursor()try:self.cursor.execute('insert into boos values(null,"%s","%s","%s","%s","%s","%s")'%(item['title'],item['salary'], item['job_sec'],item['company'],item['job_location'],item['job_tags']))self.conn.commit()except Exception as e:print("mysql插入数据失败",e)self.conn.rollback()return itemdef close_spider(self,spider):self.cursor.close()self.conn.close()
settings.py
BOT_NAME = 'boos_scrapy'SPIDER_MODULES = ['boos_scrapy.spiders']
NEWSPIDER_MODULE = 'boos_scrapy.spiders'ROBOTSTXT_OBEY = False
LOG_LEVEL = 'ERROR'
COOKIES_ENABLED = TrueDEFAULT_REQUEST_HEADERS = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8','Accept-Language': 'zh-CN,zh;q=0.9,zh-HK;q=0.8',
}DOWNLOADER_MIDDLEWARES = {'boos_scrapy.middlewares.BoosScrapyDownloaderMiddleware': 543,
}#开启访问频率限制
AUTOTHROTTLE_ENABLED = True
#设置访问开始的延迟
AUTOTHROTTLE_START_DELAY = 8
#设置访问之间的最大延迟
AUTOTHROTTLE_MAX_DELAY = 60
#设置Scrapy 并行发给每台远程服务器的请求数量
AUTOTHROTTLE_TARGET_CONCURRENCY= 1.0
#设置下裁之后的自动延迟
DOWNLOAD_DELAY = 3ITEM_PIPELINES = {'boos_scrapy.pipelines.BoosScrapyPipeline': 300,'boos_scrapy.pipelines.mysqlPileLine' : 301
}
main.py
运行
from scrapy import cmdlinecmdline.execute("scrapy crawl example".split())
创建数据库sql语句
CREATE TABLE `boos` (`id` int(11) NOT NULL AUTO_INCREMENT,`title` varchar(100) DEFAULT NULL,`salary` varchar(1000) DEFAULT NULL,`job_sec` varchar(1000) DEFAULT NULL,`company` varchar(1000) DEFAULT NULL,`job_location` varchar(1000) DEFAULT NULL,`job_tags` varchar(1000) DEFAULT NULL,PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=99 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;







![网站安装打包 webconfig修改[三]](https://images.cnblogs.com/OutliningIndicators/ExpandedBlockStart.gif)