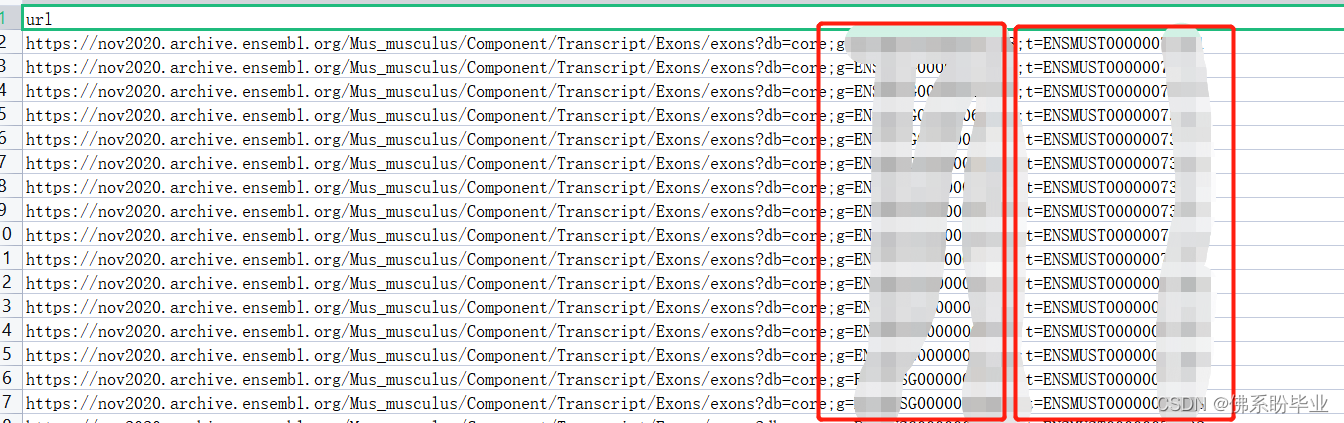
根据url 在ensembl 网站爬取外显子等数据
需要先一步准备好url,我准备的url如下:
主要是g 和 t 两列内容不同

可以准备好g和t两列数据,用python自动补充好url链接,代码如下:
(注意:url不要是列表的形式,否则会报错)此时这个html页面只有一个表格,其他的内容没有,所以可以直接写
tb = pd.read_html(urlValue)
但是如果url里面,除了表格之外,还有其他的内容,则,需要在tb爬取的url后面标注爬取的表格的位置,如爬取第一个表格内容:
tb = pd.read_html(urlValue)[0]
import pandas as pd
import csv
with open('geneid.csv', encoding='utf-8') as file:f_csv = csv.reader(file)for i, rows in enumerate(f_csv):if i >= 1:print(rows)urls = ['https://nov2020.archive.ensembl.org/Mus_musculus/Component/Transcript/Exons/exons?db=core;''g={};t={}'.format(rows[0], rows[1])]for urlValue in urls:print(urlValue)df= pd.read_html(urlValue)print(df)col_name = df.columns.tolist() # 将数据框的列名全部提取出来存放在列表里# print(col_name)col_name.insert(0, 'geneid') # 在列索引为0的位置插入一列,列名为:geneid,刚插入时不会有值,整列都是NaNcol_name.insert(1, 'traid')df = df.reindex(columns=col_name) # DataFrame.reindex() 对原行/列索引重新构建索引值df['geneid'] = rows[0] # geneid列赋值df['traid'] = rows[1] # traid 列赋值# print(df['No.'])df.to_csv(path, mode='a', encoding='utf_8', index=False,header=False)print(str(urlValue) + '抓取完成')df = pd.DataFrame(tb)df.to_csv(r'58748-18094(2).csv', mode='a', encoding='utf_8', index=False)print(str(urlValue) + '抓取完成')
也可以手动整理好url,直接拿来使用即可,但相对比较麻烦些
代码为:边爬取边存入表格
import pandas as pd
import csv
with open('C:/Users/Desktop/50.csv', encoding='utf-8') as file:f_csv = csv.reader(file)for i, rows in enumerate(f_csv):if i >= 1:for j in rows:url = jprint(url)tb = pd.read_html(url)[0]print(tb)df = pd.DataFrame(tb)df.to_csv(r'C:/Users//Desktop/58.csv', mode='a', encoding='utf_8', index=False)print(str(url) + '抓取完成')










![堆积密度怎么做_[SEO优化]关键词究竟应该怎么优化?](https://img-blog.csdnimg.cn/img_convert/2a7a65229045ef96c6e02dfc765a9091.png)
![[翻译]避免常见 ASP.NET 缺陷,使网站平稳运行](http://www.microsoft.com/china/msdn/library/webservices/asp.net/art/fig05.gif)