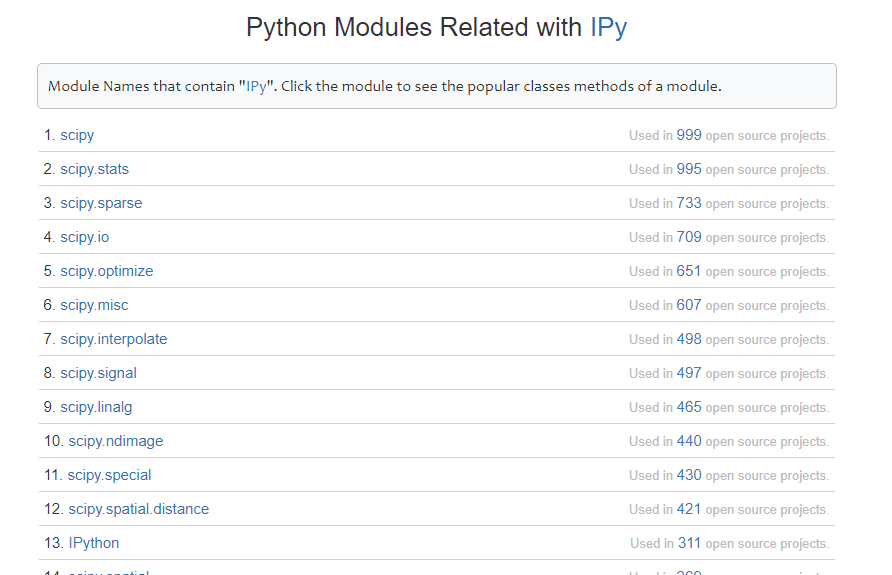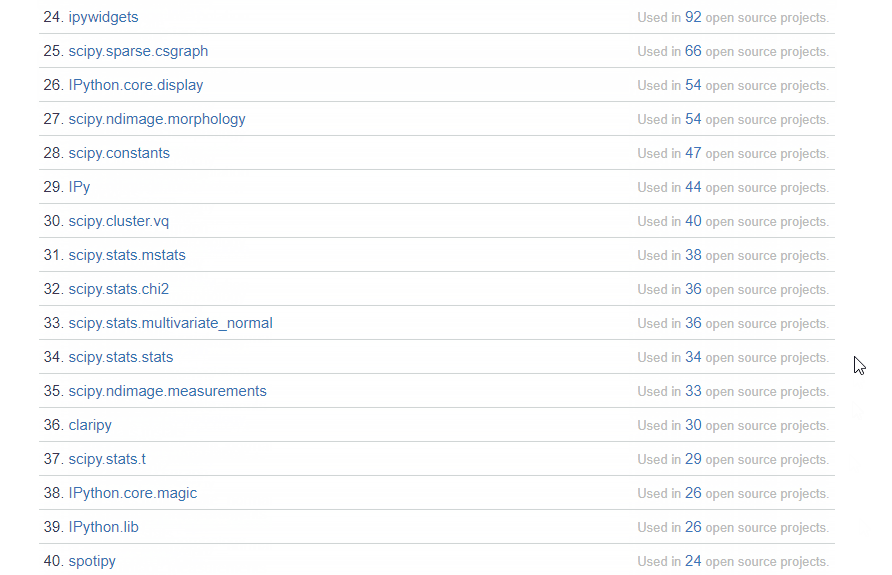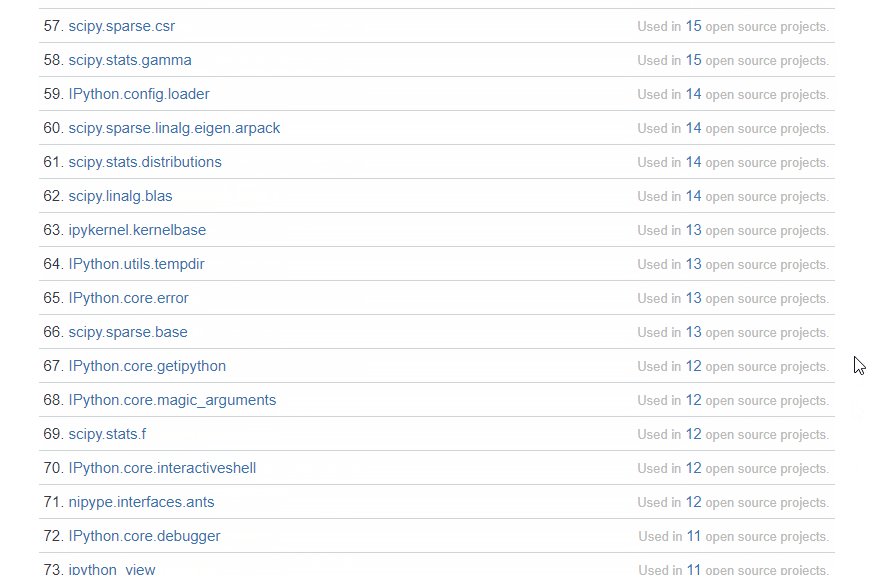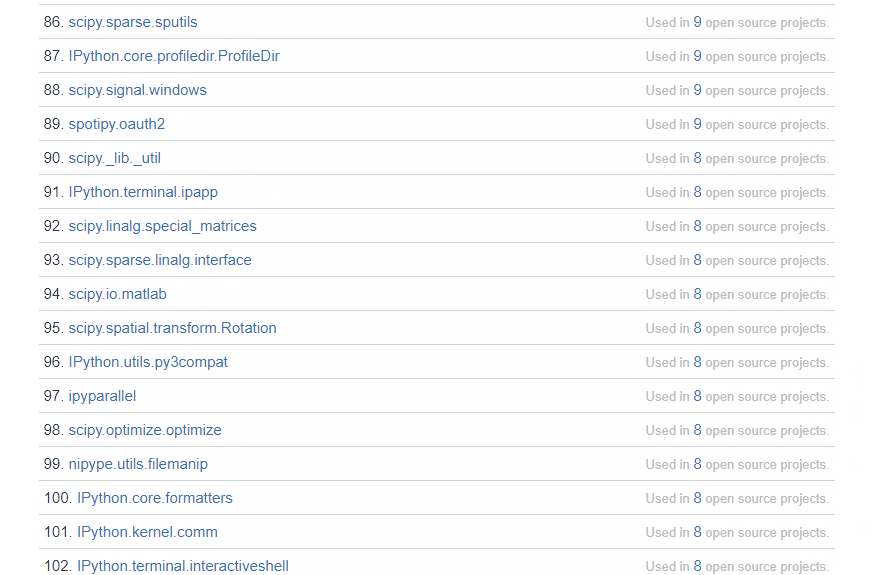
以下链接都来自知乎问答
- python如何通过请求json文件,实现高效爬取动态加载页面?
完整模拟http请求即可,推荐requests库,写程序自动生成requests就行了。我现在的分布式爬虫系统就是这个策略,各大OTA都抓过了,没问题
- 像天眼查这种网站怎么进行全爬虫?
哎呀,竟然有个专利叫反爬虫系统及方法~哎呀,专利居然是北京金堤科技有限公司的~哎呀,北京金堤科技有限公司的产品竟然叫天眼查~
- python怎么爬取天眼查工商基本信息?
这里我们看向右侧,其中一个是你的请求,另一个是服务端响应你的请求而制作的头信息
之后咱们模拟一下这个主页请求,首先弄清他的所有格式和数据
然后我们开始写一个简单的代码请求一下主页
- [已重置]:简单爬取天眼查数据 附代码
爬取企业注册信息查询_企业工商信息查询_企业信用信息查询平台_发现人与企业关系的平台-天眼查该页面的基础信息。
- 朱卫军:干货!python爬虫100个入门项目
天涯论坛文章天眼查爬虫 (链接已失效)
乌云公开漏洞
微信公众号
- 猿人学:如何让Python爬虫一天抓取100万张网页
所以千万级网页的抓取是需要先设计的,先来做一个计算题。共要抓取一亿张页面,一般一张网页的大小是400KB左右,一亿张网页就是1亿X200KB=36TB 。这么大的存储需求,一般的电脑和硬盘都是没法存储的。所以肯定要对网页做压缩后存储,可以用zlib压缩,也可以用压缩率更好的bz2或pylzma 。但是这样还不够,我们拿天眼查的网页来举例。天眼查一张公司详情页的大小是700KB 。




![堆积密度怎么做_[SEO优化]关键词究竟应该怎么优化?](https://img-blog.csdnimg.cn/img_convert/2a7a65229045ef96c6e02dfc765a9091.png)
![[翻译]避免常见 ASP.NET 缺陷,使网站平稳运行](http://www.microsoft.com/china/msdn/library/webservices/asp.net/art/fig05.gif)


![一个网站的组成[信息图]](https://pic002.cnblogs.com/images/2011/322635/2011102902413922.jpg)