相信大家在学习大数据的时候都不知道怎么来学习,因为知识点太多了,也太杂了,没有一个系统的路线来引导大家学习. 为了解决大家这个困惑,小编整理了从Linux基础到大型网站高并发处理项目实战的学习路线和知识点,希望大家能够喜欢,文末还有小编整理的视频和电子书籍,也希望大家能够喜欢。
Linux理论
1.Linux入门
—Linux简介、VMWare workstation安装 —整理各大Linux发行版本的区别 —Linux系统安装 —基本配置 MySQL、Python、Java等常用软件环境安装
2.Linux常用命令通讲
—常用基本命令介绍与使用、扩展讲解常用命令的选项含义 —基于已掌握的命令实现简易版的单机WordCount —Linux高级命令通讲 VI VIM AWK等 —Linux常用及高级命令快捷键,高效使用Linux系统
3.Linux用户管理
—Linux用户和组账户管理介绍、Linux 用户的管理(新增、删除、修改账号等操作) —创建系统用户、普通用户并授权相应的权限,为后期搭建大数据集群做准备 —Linux组管理实践、批量用户管理操作
4.Linux磁盘管理
—Linux文件系统介绍、Linux文件系统常用命令 —搭建NFS服务器,并且针对不同的文件夹设置对应的权限,以实现数据的安全与共享功能 —Linux lvm逻辑卷、NFSs详解 —Linux系统文件权限管理介绍、系统文件权限的操作
5.Linux RPM安装包
—Linux的RPM包的介绍 —基于RPM包安装对应的MySQL、Python、Java等软件环境 —Linux RPM包安装、卸载
6.Linux yum源
—yum介绍及简单使用、各大互联网公司提供的yum源介绍 —使用Nginx服务器搭建本地私有yum源 —配置开源的yum源、搭建私有yum源
7.Linux网络
—Linux网络的介绍、网络类型的区分与详解 —配置已有的Linux系统的网络,能够ping通外部服务器 —Linux网络的配置与维护
8.Linux Shell脚本
—Shell脚本的介绍及运行原理 —使用shell脚本编写简易版的MapReduce —Shell脚本的基本语法 —Shell脚本运行的多种方式
9.负载均衡LVS
—Lvs负载均衡介绍、Lvs负载均衡的负载算法 —搭建一套属于自己的LVS负载均衡器 —Lvs负载均衡的NAT模式、直接路由模式(DR)、隧道模式(TUN)、F5负载均衡器介绍 —第七层负载均衡-Nginx、第七层负载均衡-Apache Haproxy的介绍及Haproxy的使用 —Lvs+nginx+tomcat+redis|memcache构建二层负载均衡
编程语言
1.Scala环境安装及基本语法
—Scala语法介绍、数据类型 —基于已经掌握的语法实现冒泡、快速排序算法 —Scala的条件表达式、输入输出、循环等控制结构 —数组、变长数组、多维数组、set、list、元组等集合操作
2.Scala类与面向对象
—Scala的类,包括辅助构造器、主构造器 —对冒泡、快速排序算法代码重构 —Scala的对象、单例对象、伴生对象、扩展类、apply方法 —Scala的包、引入、继承 —Scala的特质trait的定义与使用 —Scala的操作符、Scala的高阶函数、匿名函数、嵌套函数
3.Scala并发编程(Actor)
—Actor简介及应用场景、ActorSystem的层次结构 —实现多actor之间消息传输案例 —Actor和ActorSystem介绍及基本使用
4.Python环境安装及基本语法
—Python介绍及安装、Anaconda运行环境安装及使用 —使用Python语言实现归并排序算法 —Python数据类型、集合类型、集合高级特性、函数
5.Python类与面向对象
—类和实例、访问限制、继承和多态、多重继承、枚举类 —重构归并排序算法
6.IO编程
—文件读写、StringIO和BytesIO、操作文件和目录、序列化 —写程序递归查询目录下包含指定字符串的文件,并将文件的路径保存到指定文件中
分布式存储
1.Hadoop技术栈概念及历史
—Hadoop生态环境介绍、Hadoop在云计算中的位置和关系 —以介绍为主,无实战案例 Hadoop应用场景、成功案例介绍、Hadoop发展历史 —Hadoop生态圈的架构及重要组件介绍
2.HDFS分布式文件系统
—HDFS介绍及分布式存储的核心思想、伪分布的详细安装步骤 —模仿百度云盘,实现一个属于自己的云盘系统,基本功能包含:文件上传、下载、移动、复制、粘贴、文件夹的创建以及修改、在线修改文本内容等功能 —采用HDFS shell的方式管理HDFS、使用WEBUI查看管理HDFS分布式存储集群 —HDFS的架构模型、存储模型、副本放置策略 —HDFS Federation机制、HDFS读写流程 —HA-HDFS介绍、HA集群搭建、HDFS-开发环境搭建及开发API讲解 —HDFS中心缓存管理介绍及缓存适用场景、HDFS CacheAdmin命令使用 —HDFS快照概念及相关命令、HDFS内部的快照管理机制、HDFS-BlockToken认证、HDFS-Sasl认证 —HDFS-DiskChecker坏盘检测服务、HDFS-DirectoryScanner目录扫描服务、HDFS-VolumeScanner磁盘目录扫描服务 —HDFS块检查命令fsck、HDFS如何检测并删除多余副本块、HDFS的流量处理、读写限流方案 —HDFS数据迁移解决方案
分布式数据库
1.HBase集群搭建
—关系型数据库的极限及HBase数据的必要性 —熟练搭建HBase集群、并且熟练操作HBase集群 —搭建HBase的伪分布式、搭建HBase的完全分布式 —HBase WebUI控制台、HBase操作命令及 shell的使用、HBase集群的管理
2.HBase表设计及优化
—HBase树形表设计、一对多表设计、多对多表设计 —HBase微博数据的存储方案,rowKey设计方案及存储优化 —针对不同业务场景,rowKey设计方案、表级优化、读写数据优化
3.Hive介绍及搭建模式
—数据仓库基础知识、Hive定义及架构的介绍 —熟练搭建Hive客户端并且熟练操作Hive数据仓库 —基于derby的本地搭建模式、基于MySQL的本地搭建模式、基于MySQL的远程搭建模式 —HQL DDL、DML与CLI客户端演示
4.Hive数据类型、表类型、索引
—内部表、外部表、临时表、分区表、分桶表 —微博数据导入到Hive中的内部表、外部表、临时表、分区表、分桶表中 —Hive创建、重建、显示、删除索引
5.Hive函数
—Hive内置函数、自定义UDF、UDAF、UDTF函数 使用HQL语句实现WordCount
分布式集群协调工具
1.Zookeeper
—集群角色、会话、数据节点、版本、watcher、ACL 权限控制 —使用ZooKeeper (1)开发分布式锁 (2)服务器动态感知上下线 (3)服务器主备切换 (4)数据的发布订阅 —集群环境、单机环境、伪集群、Zookeeper内部选举算法详解 —ZooKeeper 服务的启动和停止及常见异常 —客户端对于ZooKeeper 节点的创建、查询、删除和修改 —JAVA API 完成 创建会话、创建节点、删除节点、读取数据、节点检测等操作 —ZkClient 和 Curator 的使用方法 、zkClient 的会话创建、节点创建、节点删除 —节点数据读取等、zkClient 的节点修改、权限管理等基本使用方法 —Curator 的会话创建、节点创建、节点删除和节点数据读取等基本使用方法 —Curator 的节点修改、权限管理等基本使用方法 —Zookeeper RMI高可用分布式集群开发、实现SOA高可用架构框架 —Mycat的简介和安装、Mycat架构模型、Mycat概念详解、Mycat主键自增
2.yarn
—YARN的起源、架构、任务提交流程 —ResourceManager、NodeManager、ApplicationMaster、Container重要组件详解
3.Oozie
—Oozie安装配置、HPDL语言学习、HPDL流程定义 —基于Oozie调度MapReduce程序 —Oozie工作流配置、Oozie元数据库定义、Oozie定时任务调度、Oozie API操作
分布式缓存
—Redis Cluster —Redis系统应用场景、安装Redis集群、Redis shell使用介绍 (1)Redis + Lua 实现秒杀与抢红包实例 (2)Redis 实现分布式锁与消息队列 —Redis的数据类型、Java访问Redis数据库、Redis的事务 —Redis的管道、Redis持久化(AOF+RDB)、Redis性能优化 —Redis的主从复制、Redis的Sentinel哨兵高可用架构、Redis与Twemproxy整合 —Redis与Codis整合、Redis cluster 海量数据高速缓存架构、RedisCluster去中心化系统架构 —Jedis操作Redis、RedisCluster集群事务管理器 —SpringDataRedis、Redis 企业级备份方案、Redis 缓存失效应对策略 —分布式系统中的数据一致性模型
消息中间件
—Kafka —Kafka架构介绍、Kafka配置详解、Kafka体系结构、存储策略、分区、发布与订阅 —使用java、scala操作kafka —Kafka的存储策略、Kafka分区特点、Kafka的发布与订阅、
数据融合工具
1.Sqoop
—Sqoop的安装、将RDBMS表中的数据导入到Hive表、导入parquet、sanppy格式的数据 —MySQL中数据导入到HDFS中,并且以parquet格式来存储 —使用query自定义导入数据
2.Flume
—Flume部署方式、source相关配置及测试、sink相关配置及测试、selector相关配置及测试 —采集Apache服务器中的日志数据到Kafka中 —Sink Processors相关配置、Interceptors相关配置、Flume和Kafka的整合
分布式批处理
1.MapReduce
—分布式计算出现的背景、MapReduce分布式计算的架构 —基于MapReduce框架实现pagerank网页推荐算法 —MapReduce shuffle的流程、shuffle中Partitioner、Sort、Group、Combiner原理 —MapReduce shuffle的源码剖析、Mapper计算原理以及源码剖析、Reducer计算原理以及源码剖析 Mapreduce案例-二次排序、倒排序索引、最优路径、社交好友推荐算法
2.SparkCore
—Spark与MapReduce的对比、运行模式之间的对比 (1)基于Spark算子实现最短路径优化算法(Dijkstra) (2)统计页面的PV、UV、HotChannel、最活跃的用户等指标 —Spark中RDD的五大特性详解、Spark数据本地化的原理 —Standalone集群的架构介绍,集群运行原理、集群的搭建步骤、集群配置信息的详解、通过WEBUI监控管理集群 Transformation类的算子特点及使用(map、flatMap、filter、groupByKey、reduceByKey、distinct、updateStateByKey、join、union等算子) —Action类的算子特点及使用(collect、foreach、countByKey、reduce、first、top、take、takeOrdered、saveAsTextFile、saveAsSequenceFile) —精解Spark的任务提交流程、任务运行流程 cache持久化、persist持久化以及持久化级别、持久化的注意事项 —Client与Cluster两种提交方式的区别、两种提交方式分别适应场景 —配置Standalone集群客户端的必要性、如何配置Standalone集群的客户端 —spark-submit提交任务命令的选项详解、Spark-shell的使用方式 RDD的依赖关系 —宽依赖 窄依赖的区别、RDD宽窄依赖的作用、Stage的运行原理、Spark pipeline计算的底层揭秘 DAGScheduler、TaskScheduler(高层调度器)对象的作用 —任务调度的重试机制、Spark任务调度重试机制的注意点、控制重试机制的配置信息,以及配置信息的配置方式 —推测执行原理、判定拖后腿的task的标准、推测执行带来的问题以及解决方案 —任务调度源码分析-Master资源调度源码分析、Worker资源管理源码分析、Driver任务调度源码分析、Executor运行源码分析、Task运行源码分析、修改开源框架源码的三种方式以及三种方式优劣对比 —Spark常用的两种Shuffle-HashShuffle的原理、SortShuffle的原理、HashShuffle合并机制的原理、SortShuffle —bypass机制的原理、shuffle过程磁盘小文件的寻址流程 —MapOutputTracker BlockManager原理、Shuffle的优化 —搭建Standalond的HA集群、集群WEBUI详解、如何通过WEBUI查找任务的性能问题
3.SparkSQL
—什么是SparkSQL,Shark与SparkSQL的区别、DataSet与RDD的区别 —SparkSQL运行的底层原理、处理json、parquet格式的文件、RDD转成DataSet的两种方式-动态创建schema、对象反射 —自定义UDF、自定义UDAF、开窗函数的使用方式 —解决Spark数据倾斜方案-数据预处理、提高计算的并行度、双重聚合、随机前缀拆分数据
分布式流式处理
1.Storm
—流式处理与批处理的区别、Storm的基本概念、应用场景 —分别使用Storm、SparkStreaming、Flink实时统计当前网站的PV、UV、转换率、跳转率等网站流量统计指标 —搭建Storm集群、Storm配置文件详解、集群搭建常见问题以及注意事项 —Storm常用组件Topology、Spout、Bolt、Storm —API编程流程、Storm分组策略、Storm事物处理 Storm消息可靠性、Storm容错原理、Storm Trident概念、Trident state原理、Trident开发实例 —Storm DRPC(分布式远程调用)介绍、实战讲解、Storm on Yarn实战、Storm+Kafka的必要性 Kafka和Storm的整合、
2.SparkStreaming
—SparkStremaing介绍以及与Storm的区别 —SparkStremaing Application处理socket、HDFS、Flume等消息源 —SparkStreaming中Transformation类算子讲解(updateStateByKey、reduceByKeyAndWindow) SparkStreaming实现HA Driver —SparkStreaming+kakfa Receiver整合方式的原理、Direct整合方式的原理以及代码实战 —SparkStreaming+kafka零数据丢失的方案、提高吞吐量的优化方案
3.Flink
—Flink的基本原理及场景分析、Flink、Storm、SparkStreaming的区别 —Flink窗口操作、批处理、本地测试模式安装、Standalone模式集群的搭建 —Flink on yarn提交任务、Flink on Standalone集群HA配置、DataStream中partition的使用技巧 DataStream sink、source精讲、广播变量、Counter、WaterMark Flink生产环境配置介绍、序列化及DataType
数据分析平台
—Hue —Hue vs zeppelin、Hue环境需求、Hue编译安装 —熟练搭建Hue平台,基于Hue平台操作HDFS、Hive、Spark等集群 —Hue基于MySQL的metadata管理、Hue关联HDFS、HBase、MapReduce、Hive+测试 —Hue关联Spark生态圈组件+测试、Hue关联Oozie+测试、Hue配置信息介绍
集群管理平台
—CDH —国内外大数据平台介绍、Cloudera产品介绍、什么是CDH、 —熟练搭建CDH集群管理平台,查看集群的各项指标 —集群基础设施配置、什么是cloudera manager、cloudera manager框架原理、部署CDH、管理主机、管理集群服务、管理实例、监控资源 —什么是cloudera manager service、cloudera manager service图表使用和创建、dashboard介绍
机器学习算法+人工智能
—机器学习的应用场景、机器学习的原理及思想、机器学习和人类思考的类比 (1)Spark MLlib-微博精准营销案例 (2)使用线性回归算法预测保险保费 (3)基于多模型融合的方式预测道路拥堵情况 —线性回归算法的介绍、应用场景、目标函数推导、使用优化算法(梯度下降法)来优化目标函数 —模型的欠拟合与过拟合的区别,防止过拟合问题的方案 —简单线性回归算法与多元线性回归算法的区别、使用多元线性回归算法来预测保险的费用 —Spark MLlib的LabelPoint Vector等类型的讲解、使用Spark MLlib来训练线性回归算法模型 —KMeans聚类算法的介绍,以及算法原理、KMeans算法的缺陷以及优化方式 —使用Python numpy来实现KMeans算法、使用Python scikit-learn机器学习库来做KMeans聚类 密度聚类DBScan算法原理及使用
谱聚类算法原理及使用
—朴素贝叶斯算法、拉普拉斯估计 GBDT迭代决策树算法原理、优化 —Xgboost安装、原理、使用方式 —支持向量机SVM算法原理及使用 —PCA主成分分析算法、LDA降维优化、ALS矩阵分解算法 —逻辑回归分类算法原理、公式推导、目标函数的推导、 目标函数的求导,以及最优值的求解、使用优化算法(梯度下降法)来优化目标函数 —逻辑回归算法优化-手动设置分类阈值来规避一些不能接受的风险、设置截距来增加分类的可能性、升维的方式解决线性不可分的问题、使用L1、L2正则化来提高模型的鲁棒性、归一化训练集数据来提高模型的训练效率、调整训练集数据的正负值来提高模型的训练效率、选择不同的优化算法来优化逻辑回归算法 —ROC AUC测试模型的准确率 KNN算法原理、Python numpy实现KNN算法、KNN算法来实现数字识别 决策树算法原理、Python numpy实现决策树算法 —决策树算法的缺点-随机森林、Spark MLlib训练决策树、随机森林算法模型 —TensorFlow安装、训练线性回归算法模型、神经网络模型、TensorBoard可视化 DNN深度神经网络手写图片识别、卷积神经网络深入、AlexNet模型实现
项目
互联网个性实时推荐系统 
IOT流式云平台 
阿里巴巴中台实战 
大数据完整思维导图 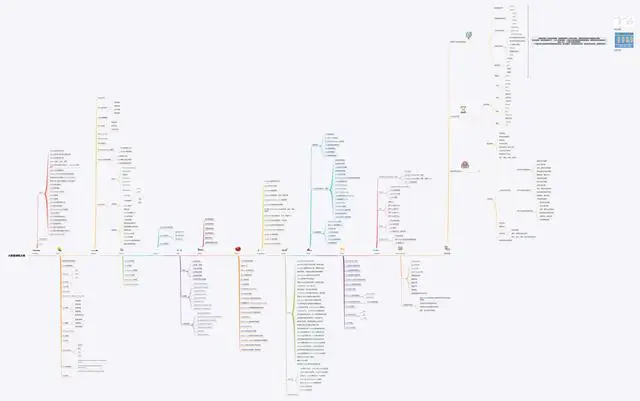
※更多文章和资料|点击后方文字直达 ↓↓↓ 100GPython自学资料包 阿里云K8s实战手册 [阿里云CDN排坑指南]CDN ECS运维指南 DevOps实践手册 Hadoop大数据实战手册 Knative云原生应用开发指南 OSS 运维实战手册 云原生架构白皮书 Zabbix企业级分布式监控系统源码文档 云原生基础入门手册 10G大厂面试题戳领