程序流程:
1.收集数据:提供文本文件
2.准备数据:使用Python解析文本文件
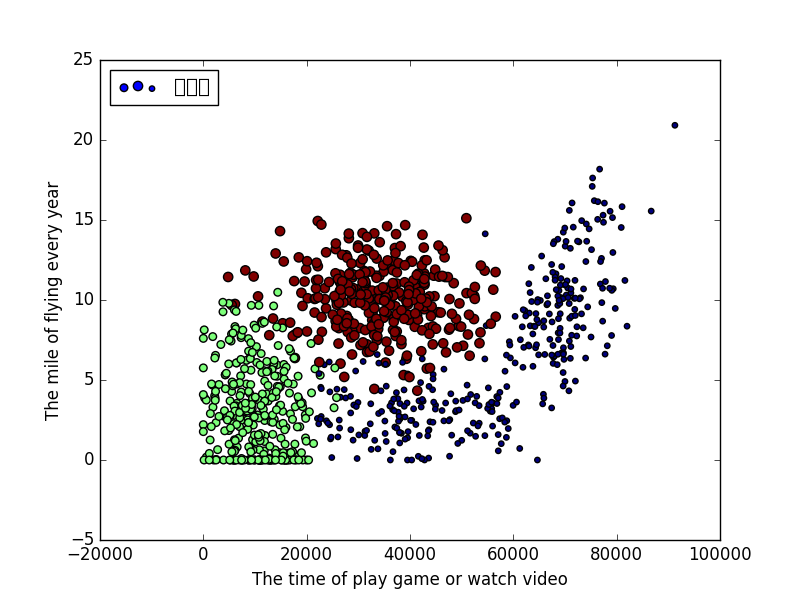
3.分析数据:使用Matplotlib画二维扩散图
4.测试算法:使用提供的部分数据作为测试样本。
测试样本和非测试样本的区别在于:测试样本是已经完成分类的数据,如果预测分类与实际类别不同,则标记为一个错误
5.使用算法:产生简单的命令行程序,然后可以输入一些特征数据以判断结果
本样本共有三种特征:
每年获得的飞行常客里程数:The mile of flying every year
玩视频游戏所耗时间百分比:The time of play game or watch video
每周消费的冰淇淋公升数:The liter of ice-cream every week
代码:
#!/usr/local/env python
#-*- coding: utf-8 -*-from numpy import * #导入科学计算包numpy模块
import operator #导入运算符模块
import matplotlib.pyplot as plt #k-近邻分类算法
def classify0(inX, dataSet, labels, k): #4个输入参数分别为:用于分类的输入向量inX,输入的训练样本集dataSet,标签向量labels,选择最近邻居的数目k#计算距离dataSetSize=dataSet.shape[0] #获取数据集的宽diffMat=tile(inX, (dataSetSize, 1))-dataSet #使用欧式距离度量,故将输入向量和数据集中各向量相减sqDiffMat=diffMat**2 #平方sqDistances=sqDiffMat.sum(axis=1) #计算输入向量和数据集中各向量之间的差的平方和distances=sqDistances**0.5 #计算欧式距离#选择距离最小的k个点 计算所属类别的出现频率sortedDistIndicies=distances.argsort() #取得输入向量和数据集中各向量欧式距离的从小到大排序的下标值classCount={} #定义一个空字典for i in range(k): #取计算欧氏距离排序后最小的前k个值voteIlabel=labels[sortedDistIndicies[i]]classCount[voteIlabel]=classCount.get(voteIlabel,0)+1#排序 选择前k个点中出现最多的那一个类sortedClassCount=sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)return sortedClassCount[0][0]#将文本记录转换为Numpy的array
def file2matrix(filename): #输入为文件名字符串fr=open(filename) #打开文件arrayOLines=fr.readlines() #取得该文件的每行数据的列表numberOfLines=len(arrayOLines) #计算该文件共有多少行(即共有多少个样本)returnMat=zeros((numberOfLines, 3)) #创建返回的Numpy矩阵classLabelVector=[]index=0for line in arrayOLines: #解析文件数据到列表line=line.strip() #去掉首尾空白符listFromLine=line.split('\t') #利用空格符分离字符串returnMat[index, :]=listFromLine[0:3] #将每行样本数据的前3个数据输入返回样本矩阵中classLabelVector.append(int(listFromLine[-1])) #将每行样本数据的最后一个数据加入类标签向量中index+=1 return returnMat, classLabelVector #返回训练样本矩阵和类标签向量#分析数据-数据可视化
def showDateSet(datingDataMat, datingLabels): fig = plt.figure() ax = fig.add_subplot(111) ax.scatter(datingDataMat[:,0], datingDataMat[:,1], c = 15*array(datingLabels), s = 15*array(datingLabels), label=u'散点图') plt.legend(loc = 'upper left') plt.xlabel(u"The time of play game or watch video") plt.ylabel(u"The mile of flying every year") plt.show() #归一化特征值
def autoNorm(dataSet): #输入为数据集数据minVals=dataSet.min(0) #获得数据集中每列的最小值maxVals=dataSet.max(0) #获得数据集中每列的最大值ranges=maxVals-minVals #获取取值范围normDataSet=zeros(shape(dataSet)) #初始化归一化数据集m=dataSet.shape[0] #行normDataSet=dataSet-tile(minVals, (m, 1))normDataSet=normDataSet/tile(ranges, (m, 1)) #特征值相除return normDataSet, ranges, minVals #返回归一化矩阵,取值范围以及最小值#测试程序
def datingClassTest():hoRatio=0.10 #取测试样本占数据集样本的10%datingDataMat,datingLabels=file2matrix('datingTestSet2.txt') #得到样本集,样本标签normMat,ranges,minVals=autoNorm(datingDataMat) #得到归一化样本集,取值范围以及最小值m=normMat.shape[0] #样本集行数numTestVecs=int(m*hoRatio) #测试样本集数量 errorCount=0.0 #初始化错误率for i in range(numTestVecs): #循环,计算测试样本集错误数量classifierResult=classify0(normMat[i,:], normMat[numTestVecs:m,:], datingLabels[numTestVecs:m], 3) #k-近邻算法print "the classifier came back with: %d, the real answer is: %d"%(classifierResult, datingLabels[i]) if (classifierResult != datingLabels[i]):errorCount+=1.0 print "the total error rate is: %f"%(errorCount/float(numTestVecs)) #计算错误率,并输出#自定义分类器:输入信息并得出结果
def classifyPerson():resultList=['not at all', 'in small doses', 'in large doses']percentTats=float(10)ffMiles=float(100)iceCream=float(2.5)# percentTats=float(raw_input("percentage of time spent playing video games?")) #函数raw_input()允许用户输入文本行命令并返回用户输入的命令# ffMiles=float(raw_input("frequent filer miles earned per year?")) # iceCream=float(raw_input("liters of icecream consumed per year?"))datingDataMat,datingLabels=file2matrix('datingTestSet2.txt')normMat,ranges,minVals=autoNorm(datingDataMat)inArr=array([ffMiles, percentTats, iceCream])classifierResult=classify0((inArr-minVals)/ranges,normMat,datingLabels,3)print "You will probably like this person: ",resultList[classifierResult-1]#结果showDateSet(datingDataMat, datingLabels)#绘图classifyPerson()运行结果:
You will probably like this person: in small doses