码农三哥愿与大家每日分享java开发过程中笔记和互联网人工智能技术文章,愿你我互交流,共同成长!
目前,许多网站采取了各种各样的措施来反爬虫,通常一个网站都会使用下面的多种反爬,越是数据价值高的网站反爬做的越复杂。常见的反爬措施及解决方案如下:
1.通过网页请求头反爬
这是网站最基本的反爬措施,也是最容易实现的反爬,但是破解起来也容易,只需要合理添加请求头即可正常访问目标网站获取数据。
2.IP反爬
- 服务器会检测某个IP在单位时间内的请求次数,如果超过了这个阈值,就会直接拒绝服务,返回一些错误信息,这种情况可以称为封IP。封IP也分为永久被封和短时被封。
- 永久被封:进入黑名单中的IP永久不能访问
- 固定时段被封:IP一段时间失效
解决方案:
采用代理突破IP访问限制,常规方法就是购买代理服务或者购买VPS服务器自己构建代理IP池
代理的原理:
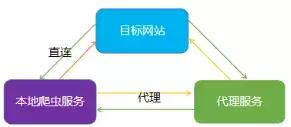
IP代理池架构:
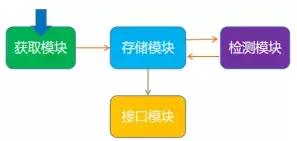
- 存储模块一般使用Redis的有序集合,用来做代理去重和状态标识,存储模块为中心模块,连接其他模块
- 获取模块定时从代理网站获取代理,将获取的代理传递给存储模块,并保存数据到Redis
- 检测模块定时获取存储模块中的所有代理,并对代理进行检测,根据不同的检测结果对代理设置不同的标识
- 接口模块通过WebAPI提供服务接口,接口通过连接Redis获取数据并返回可用代理
ADSL拨号代理:
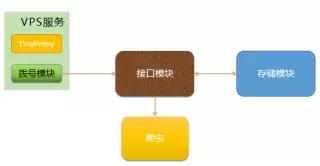
- 拨号模块:定时拨号,生成的IP发送给接口模块,接口模块调用存储模块存储IP数据
- 接口模块:接收拨号模块的IP,给爬虫提供接口返回IP数据
- TingProxy:代理服务,就是一个软件,安装到VPS启动即可
- 存储模块:负责存取IP
- 爬虫:通过调用接口获取IP,添加代理访问目标网站获取数据
3.验证码反爬
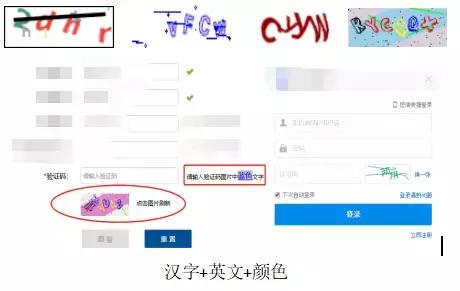
- 验证码反爬也是目前很多网站常用的一种反爬机制,随着技术的发展,验证码的花样也越来越多。验证码最初是几个数字组合的图形验证码,后来加入英文字母和混淆曲线。有的网站还可能加入中文字符验证码.
- 遇到有验证码的网页,目前就两种解决方案,一种是购买验证码识别服务,这些识别服务本身也是他们后台人工去识别之后通过接口返回识别结果;另一种是自己训练识别模型进行识别。此处主要介绍自己处理验证码的方案,对接服务的方式可以找对应识别平台依据API文档完成识别对接。
1)字符验证码:
- 普通字符识别,目前深度学习可以做到比人眼识别更高的准确率。可以通过深度学习来自己开发识别服务接口,流程如下:
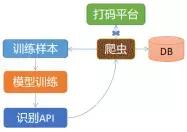
- 一般训练样本都是通过爬虫对接实际的打码平台,进行数据的采集,保存正确的样本作为模型训练样本。目前训练样本所需量和样本类别大概关系为:样本类别数X 500,比如数字加字母36个类别训练所需要的样本量为36*500=18000。训练样本越多,得到的模型识别率越高,但是相对来说成本越高。实际训练中发现,针对字母+数字形式验证码10000以上样本就可以得到一个可用的识别模型。如何训练一个可用模型,可以阅读我写的另一篇文章《基于python+深度学习构建验证码识别服务系列文章》juejin.im/post/5da81e…
- 汉字识别和普通字符识别一样,仅仅需要的样本量比较大,模型结构和训练过程一样。上图中有一种验证码是需要输入指定颜色的字符,这种验证码和字符验证码识别类似,但是需要两个模型进行配合处理,及颜色识别模型和字符识别模型。颜色识别模型负责输出图片字符对应颜色序列,字符输出模型负责输出对应图片字符。实际训练中发现颜色识别模型很少样本就可以得到99.99%的识别率,模型收敛很快;但是字符验证码由于加入了3500种汉字,实际训练时训练样本100万(由代码模拟生成),识别率95%以上,训练时间相对很长(GPU会快很多)。
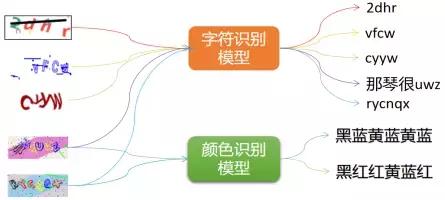
深度学习训练验证码识别模型一些心得:
- 模型设计可以设计成通用结构,每次只需要修改输出类别个数,模型可以复用。对于图片大小不一致问题可以采取缩放到统一尺寸来解决。
- 字符验证码目前都是不需要区分大小写的,同时每个平台的字符验证码可能把容易混淆的字符剔除了,所以字符验证码实际的类别输出并没有36种。通过对训练样本进行统计就可以找到缺失字符,这样可以减少输出类别数。另外一个注意点就是,有些网站的字符验证码可能不是定常的,每次返回的验证码是可变长度的,对于这种验证码可以按照最大长度设计模型,长度不够的用下划线补齐,但是一定要合理选择补齐位置,才能得到较好的识别准确率。
2)行为验证码:
a.坐标点选:
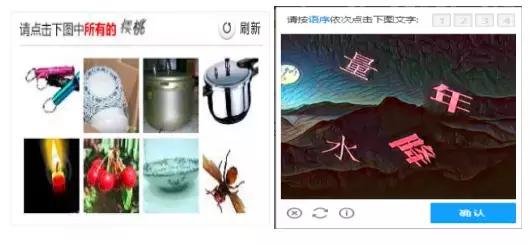
- 坐标点选也可以直接对接打码平台,提交图片数据到打码平台,打码平台返回坐标值,通过Seleniun、PhantomJS模拟点击对应坐标,完成验证。或者直接构造参数提交即可。
- 深度学习训练模型进行识别,自己训练模型需要的样本量比较大,训练成本比较高。汉字点选验证码相对需要的训练样本比较少。针对汉字点选验证码提供一种识别思路:
- 这种验证码在获取到图片中的字符之后,最关键的一步是需要按照正确的语序去点击图片中的字符,所以需要有一个语序模块依据输入的字符给出正确的语序顺序,最简单的方式就是对字符所有的排序通过Jieba库进行分词,得到最长分词序列即为正确结果。或者基于自然语言处理训练语序模型进行排序。
- 最后一步也就是模拟点击过程,简单的方式是采用浏览器模拟点击,这种通过率相对较高,实现容易。另一种方式为分析参数加密过程,直接构造参数提交,JS逆向有一定难度,技术要求较高,优点是程序执行效率较高。
b.滑动验证:
- 滑动验证码识别的关键是确定缺口需要滑动的距离、构造滑动轨迹。轨迹计算最通用的方式就是通过OpenCV库使用图像处理算法来计算滑块滑动距离,目前网上主流的几家滑动验证码都可以采用这种算法来计算得到滑动距离。轨迹构造,轨迹构造的原则就是尽量模拟人滑动的过程,比如网上常见的先加速后减速或者利用正态分布曲线构造轨迹(实际实现效果较好,参数方便修改)。得到距离和轨迹之后,采用Seleniun、PhantomJS模拟滑动,但是这种方式存在的问题就是效率比较低。
- 更好的办法是在得到滑动距离和滑动轨迹之后直接分析JS参数构造过程,逆向JS,得到提交参数,直接向后台提交数据通过验证。技术要求比较高,需要一定的JS逆向能力,但是爬取效率较高。
4.JS混淆动态参数反爬
- JS参数加密也是目前很多网站常会采用的一种反爬机制。最简单的方式是通过Seleniun、PhantomJS直接抓取,优点是不需要分析JS,缺点是采集效率较低。
- 另一种方案是直接逆向分析JS,改写加密JS或者直接用JS执行引擎(PyV8、pyexecjs、PhantomJs)执行JS得到加密参数后直接提交参数。
5.账号反爬
- 常见的就是每次访问都需要先登录才可以正常浏览数据,这种网站数据采集就需要准备大量账号,同时需要注意每个账号最大请求次数,有的网站也会在同一个账号短时间内发起大量请求时采取封号策略,解决方式就是大量账号切换采集;每个账号发送一定量请求之后及时切换另一个账号采集。
- 解决账号反爬的第一步就是模拟登陆,模拟登陆常见方式有两种:一种是用Seleniun、PhantomJS模拟登陆,这种方式实现较简单,不需要分析JS,由于很多需要登陆的网站都有对应JS参数混淆机制。另一种比较直接的方式就是逆向JS,模拟提交数据完成模拟登陆,保存Cookie数据供爬虫爬取数据用。
Cookie代理池模块一般架构:
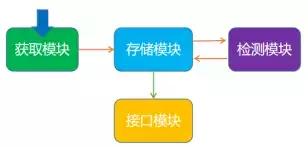
- 获取模块:负责生成每个账号对应的Cookie
- 存储模块:存储账号及账号对应的Cookie信息,同时还需要实现一些方便存取的操作
- 检测模块:定时检查Cookie,不同站点检测链接不同,检测模块拿对应Cookie去请求链接,返回状态有效则Cookie有效,否则Cookie失效并移除。
- 接口模块:对外提供API调用,随机返回Cookie保证每个Cookie都能被取到,Cookie越多被取到的概率越小,从而减少被封号的风险。
6.自定义字体库反爬
目前有些网站通过自定义字体库的方式实现反爬,主要表现在页面数据显示正常,但是页面获取到的实际数据是别的字符或者是一个编码。这种反爬需要解析网站自己的字体库,对加密字符使用字体库对应字符替换。需要制作字体和基本字体间映射关系。
7.总结
- 目前很多网站都有基本的反爬策略,常见就是验证码、JS参数加密这两种。爬取量不大优先推荐Seleniun、PhantomJS、Splash这样的工具,可以很快实现数据抓取。对数据量较大的爬取任务还是建议构造参数方式抓取,程序稳定性较高,同时效率高,尤其对目前很多前后端分离网站数据抓取更适合。
- 爬虫本身会对网站增加一定的压力,所以也应该合理设定爬取速率,尽量避免对目标网站造成麻烦,影响网站正常使用,一定注意自己爬虫的姿势。
推荐大家一篇关于爬虫合法还是违法的文章:mp.weixin.qq.com/s/rO24Mi5G5…

敬畏法律,遵纪守法,从我做起










![网站URL路径的中文问题[中文路径编码]【转】](http://hiphotos.baidu.com/iqpkeq/pic/item/4a71bc7e48de6f4d0dd7da52.jpg)
