不登录打开网页:
import urllib2
request = urllib2.Request('http://www.baidu.com')
response = urllib2.urlopen(request).read()
print response保存网页图片(https://www.baidu.com/img/bd_logo1.png):

picurl = 'https://www.baidu.com/img/bd_logo1.png' #定义图片的url地址
req = urllib2.Request(picurl)
data = urllib2.urlopen(req).read()file=open('d:\\zaa.jpg','wb') #将图片保存为名为zaa.jpg的图片
file.write(data)
file.flush()
file.close()
模拟自动登录zabbix:
import urllib2,cookielib,urllib
#定义登录地址
login_url = 'http://10.16.2.4/zabbix/index.php'
#定义登录所需要用的信息,如用户名、密码等,详见下图,使用urllib进行编码
login_data = urllib.urlencode({"name": 'admin',"password": 'password',"autologin": 1,"enter": "Sign in"})#设置一个cookie处理器,它负责从服务器下载cookie到本地,并且在发送请求时带上本地的cookie
cj = cookielib.CookieJar() #获取Cookiejar对象(存在本机的cookie消息)
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj)) #自定义opener,并将opener跟CookieJar对象绑定
urllib2.install_opener(opener) #安装opener,此后调用urlopen()时都会使用安装过的opener对象
response=opener.open(login_url,login_data).read() #访问登录页,自动带着cookie信息
print response #返回登陆后的页面源代码zabbix登录页面内容:

有的页面登录时会post到其他页面,查看登录页面的form中的action地址,可能需要构造header头信息:
#发送头信息
headers = {'Referer':'http://10.16.2.4/zabbix/index.php','Host':'10.16.2.4', #可以不要,一般两项就可以'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko'
}
#定义登录地址
login_url = 'http://10.16.2.4/zabbix/index.php'
#定义登录所需要用的信息,如用户名、密码等,使用urllib进行编码
login_data = urllib.urlencode({"name": 'admin',"password": 'password',"autologin": 1,"enter": "Sign in"})#设置一个cookie处理器,它负责从服务器下载cookie到本地,并且在发送请求时带上本地的cookie
cj = cookielib.CookieJar() #获取Cookiejar对象(存在本机的cookie消息)
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj)) #自定义opener,并将opener跟CookieJar对象绑定
urllib2.install_opener(opener) #安装opener,此后调用urlopen()时都会使用安装过的opener对象urllib2.urlopen(login_url)#打开登录主页面(他的目的是从页面下载cookie,这样我们在再送post数据时就有cookie了,否则发送不成功) #通过urllib2提供的request方法来向指定Url发送我们构造的数据,并完成登录过程
req=urllib2.Request(post_url,login_data,headers) #post_url需要在请求过程中自己得出
response=urllib2.urlopen(req)
print response.read()
response.close()在ie中手动登录后,可以看到相应的header头信息,如下:

模拟登录piao.x.com(先使用chrome抓包,输入一个错误的账号密码):
import urllib,urllib2,cookielibusername='name'
password='pass'
loginurl='http://piao.x.com/loginHandler.ashx' #此为在登录过程中post到的页面cj = cookielib.CookieJar()
opener=urllib2.build_opener(urllib2.HTTPCookieProcessor(cj))headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Maxthon/4.4.8.1000 Chrome/30.0.1599.101 Safari/537.36','Referer':'http://piao.x.com/login/login','Content-Type':'text/html'}
for key in headers: #增加多个headeropener.addheaders.append((key,headers[key]))data = urllib.urlencode({"username":username,"password":password}) #使用google可以看到此处的用户密码为明文发送,格式为username=username&password=password,如下图所示。
opener.open(loginurl,data)
print opener.open('http://piao.x.com/#dGlja2V0').read() #登录成功后可以打开其他页面。Form Data部分为需要Post到Server的参数,piao登录需要Post的参数是2个,zabbix登录需要Post的参数是4个 。
piao login:

zabbix login:
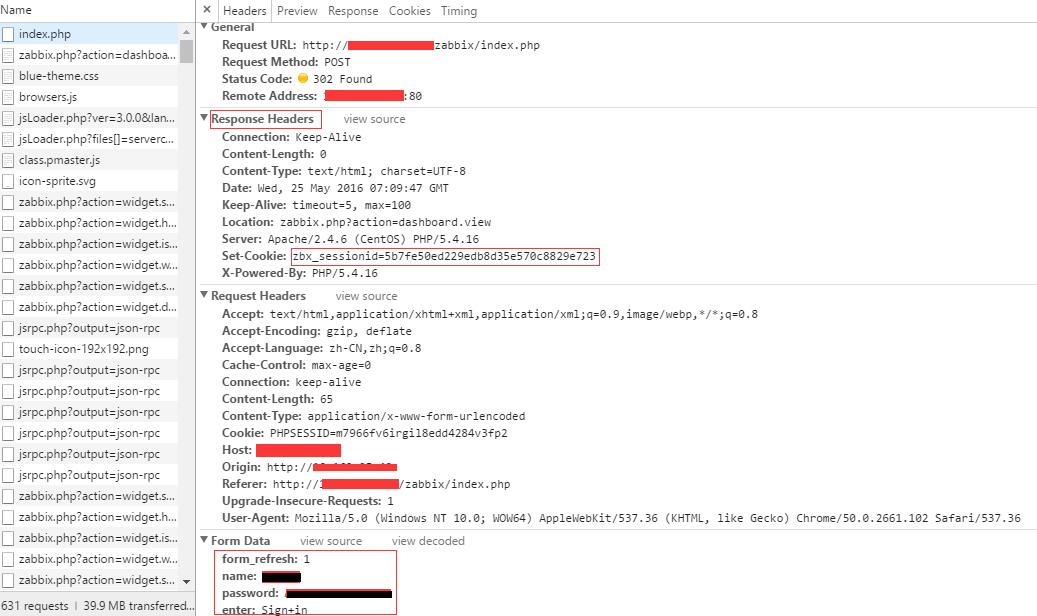
如上图所示,查看Respons Headers部分,可以看到其中的Set-Cookie,该cookie可以在后面的站内访问使用,使用urllib2也可以看到该部分内容:
import cookielib,urllib,urllib2
zabbix_url="http://10.16.2.4/zabbix/index.php"
zabbix_header = {"Content-Type":"application/json"}
zabbix_user = "admin"
zabbix_pass = "password"cj = cookielib.CookieJar()
opener=urllib2.build_opener(urllib2.HTTPCookieProcessor(cj))
data = urllib.urlencode({"name":zabbix_user,"password":zabbix_pass,'form_refresh':1,'enter':'Sign in'})
response = opener.open(zabbix_url,data)
print response.headers #打印Server 的response header头部分内容:返回:
Date: Wed, 25 May 2016 08:07:17 GMT
Server: Apache/2.4.6 (CentOS) PHP/5.4.16
X-Powered-By: PHP/5.4.16
Set-Cookie: zbx_sessionid=bbc97766e8c132a56f2d016a6963219a
Set-Cookie: PHPSESSID=v8sno86fnc19iqgltipae0l2d2; path=/zabbix/
Expires: Thu, 19 Nov 1981 08:52:00 GMT
Cache-Control: no-store, no-cache, must-revalidate, post-check=0, pre-check=0
Pragma: no-cache
Set-Cookie: PHPSESSID=v8sno86fnc19iqgltipae0l2d2; path=/zabbix/
Set-Cookie: PHPSESSID=v8sno86fnc19iqgltipae0l2d2; path=/zabbix/
Set-Cookie: PHPSESSID=v8sno86fnc19iqgltipae0l2d2; path=/zabbix/
Connection: close
Transfer-Encoding: chunked
Content-Type: text/html; charset=UTF-8在urllib2中不再使用用户名密码,直接使用上面得到的cookie访问站内页面:
import cookielib,urllib,urllib2
zabbix_url="http://10.16.2.4/zabbix/index.php"
zabbix_header = {"Content-Type":"application/json"}cj = cookielib.CookieJar()
opener=urllib2.build_opener(urllib2.HTTPCookieProcessor(cj))zabbix_header = {'cookie':'zbx_sessionid=bbc97766e8c132a56f2d016a6963219a'} #使用前面得到的cookie
for key in zabbix_header: #增加多个header,把cookie放到header中,访问server时使用该cookieopener.addheaders.append((key,zabbix_header[key]))print opener.open('http://10.16.2.4/zabbix/tr_status.php?fullscreen=0&groupid=0&hostid=0&show_triggers=1&ack_status=1&show_events=1&show_severity=0&txt_select=&application=&inventory%5B0%5D%5Bfield%5D=type&inventory%5B0%5D%5Bvalue%5D=&filter_set=Filter').read() #该页面可以直接访问,不再需要使用用户名密码等信息。
参考:http://www.cnblogs.com/sysu-blackbear/p/3629770.html 保存cookie到本地文件
http://www.2cto.com/kf/201401/275152.html 详细,带有http具体访问过程
http://www.jb51.net/article/63759.htm 简明
http://www.blogjava.net/hongqiang/archive/2012/08/01/384552.html