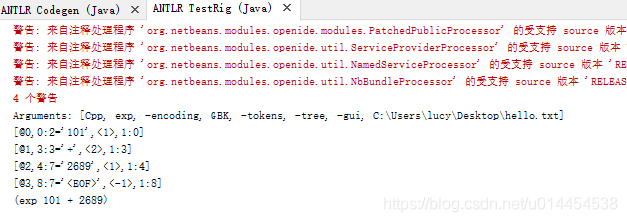
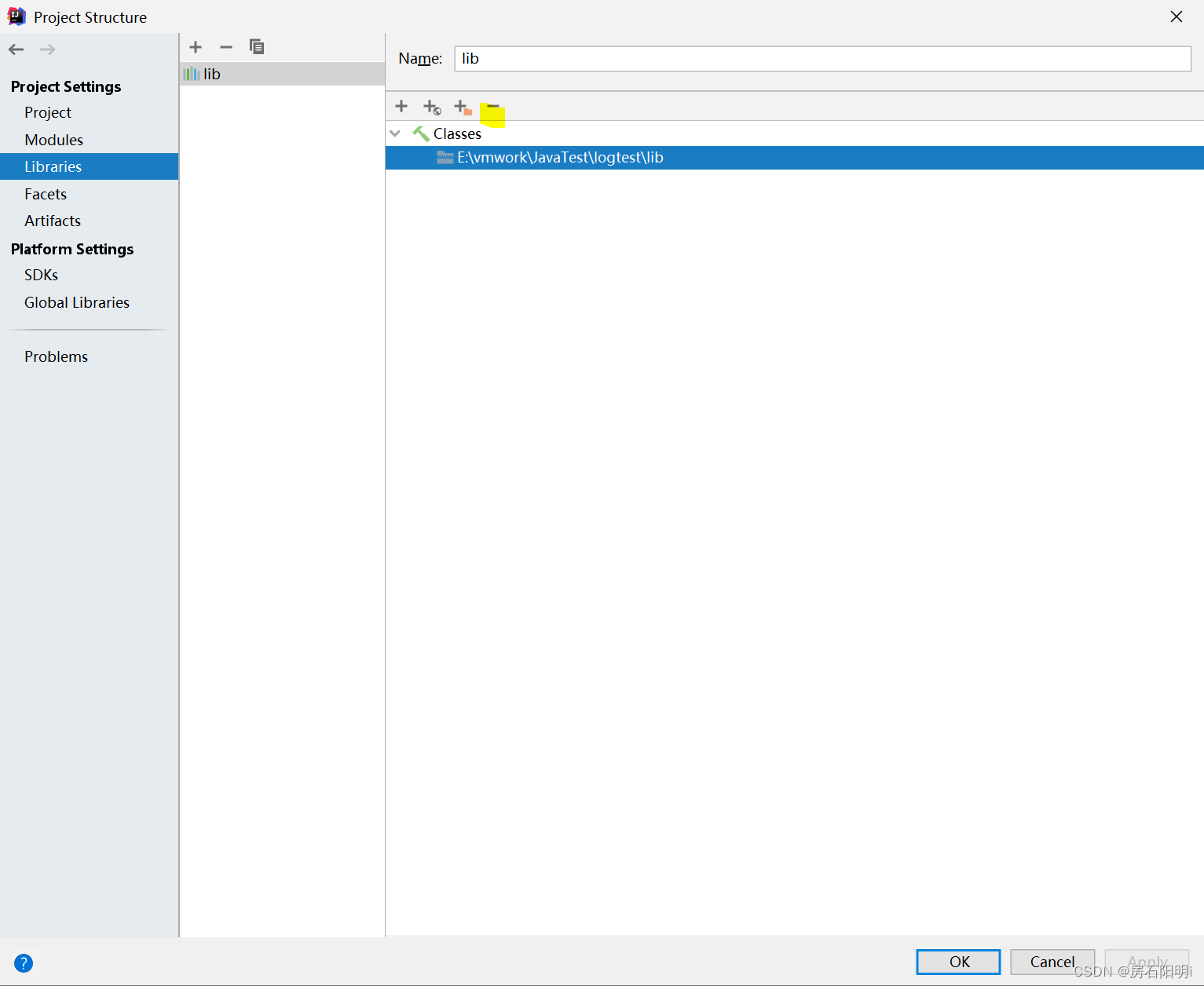
日前,全球市场分析机构 Gartner发布《2022 云数据库管理系统魔力象限》报告。其中,在Gartner本次魔力象限报告评估的20家供应商中,亚马逊云科技在纵轴“执行能力”和横轴“愿景完整性”两个维度分别处于最高、最右位置,这也是亚马逊云科技连续八年在Gartner云数据库管理系统魔力象限报告中被评为“领导者”。
Gartner云数据库管理系统魔力象限报告,无疑是业内最严苛的厂商综合能力评估之一,评估对象包括亚马逊云科技、微软、阿里云、谷歌、甲骨文等全球领先的厂商,其涵盖了前瞻性和执行力两大维度共15个核心指标以及200多项细则,可以说是全球各大数据库厂商的必争之地。
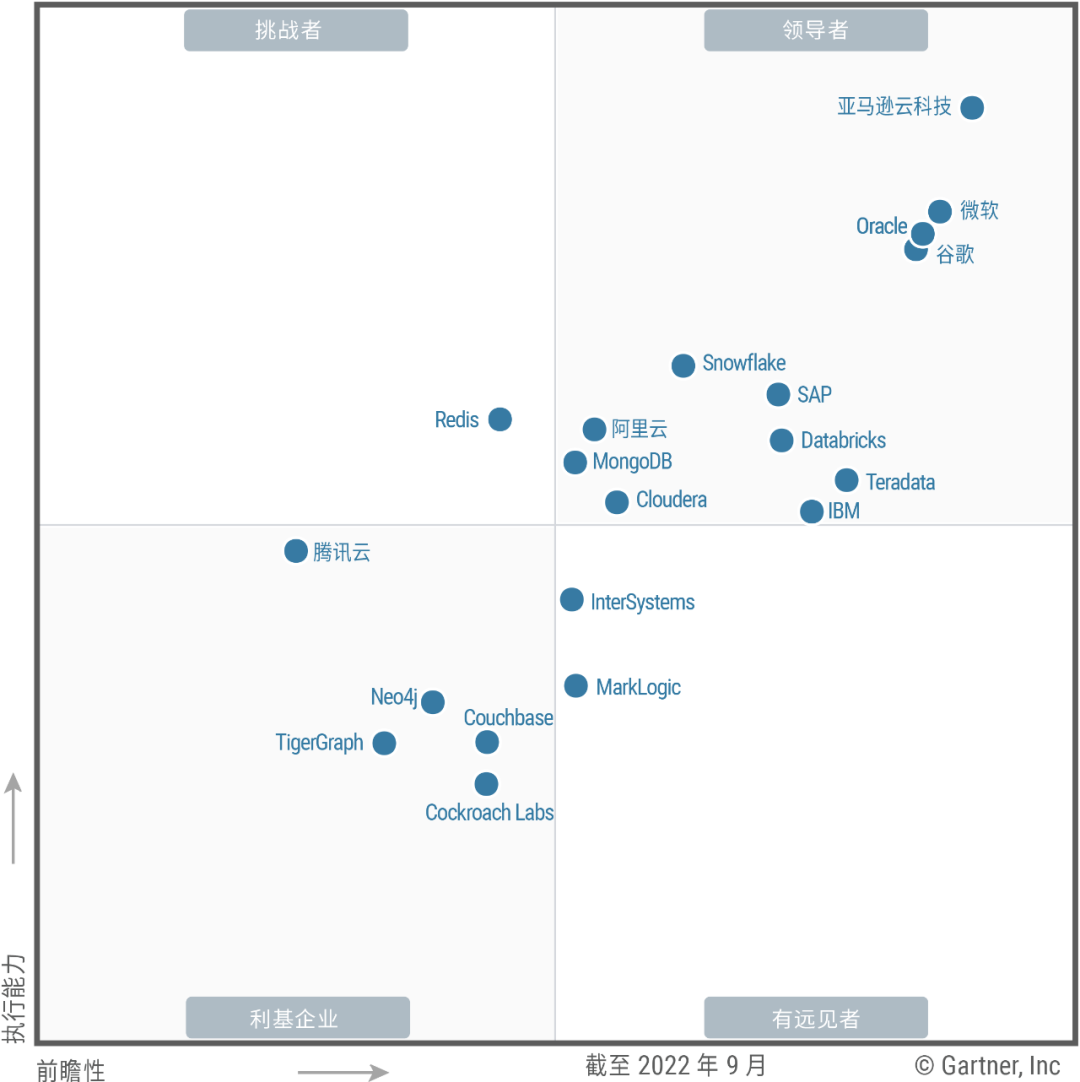
资料来源:Gartner(2022年12月)
从这个角度来说,入选Gartner云数据库魔力象限报告本身就是一种实力的体现,更何况是连续八年入选“领导者”象限,亚马逊云科技的云数据库产品的技术和战略在全球市场的竞争力和领导力可见一斑。
那么,亚马逊云科技为何连续八年“霸榜”Gartner云数据库领导者?在这背后,它究竟有何与众不同的优势和竞争力?更为关键的是,在数据已成为生产要素的今天,亚马逊云科技能否继续把其优势转换为胜势,并将全球云数据库市场的发展带到一个全新的高度呢?
软硬件融合创新实现引领
作为全球最大的云数据库服务提供商,亚马逊云科技在推出第一项云数据库服务不到10年的时间里,就实现了对市场的全面引领,背后的重要原因究竟是什么呢?其实在Gartner云数据库魔力象限报告中,就点出了关键——那就是“亚马逊云科技拥有支持其领先地位的底层基础设施,以及业内最大的生产用户群体。”
换句话说,亚马逊云科技基于其强大的底层基础设施的集成和优化,奠定了其云数据库软硬件的融合创新,由此不仅提升了云数据库的高性能,更引领了全球云数据库的未来发展之路。
确实如此,不是随便一个数据库从物理机搬到云环境里,做一些资源调度的接口,通过云平台能够向外提供数据库服务,就可以称之为云数据库,真正的云数据库需要和其底层的基础设施,或者“云底座”能力实现有机融合,才是云数据库区别于其他数据库最为重要的特征。
在这方面,亚马逊云科技为了增强其云数据库的极致性能,就做了大量的软硬件融合的创新,而自研芯片就是亚马逊云科技高度重视硬件底层技术创新的证明。自2013年推出Amazon Nitro系统以来,亚马逊云科技已经推出了多款自研芯片,包括五代Nitro系统、致力于为各种工作负载提升性能和优化成本的三代Graviton芯片、用于加速机器学习推理的两代Inferentia芯片,以及用于加速机器学习训练的Trainium芯片。
以虚拟化芯片Nitro为例,其最早可追溯到2012年,历经十年的发展其目前已演进到第五代Nitro 5,其晶体管数量是上一代Nitro的两倍,整个数据包的转发能力提升了60%,延迟减少了30%,每瓦特的性能提升了40%,而其强大的性能优势可以说又为云数据库释放其能力夯实了底座的能力。
在此基础上,亚马逊云科技又持续的对云数据库做迭代和优化。以Amazon RDS为例,作为全球云数据库托管服务的“标杆”,在推出Amazon RDS for MySQL 后,亚马逊云科技也持续不断的对该服务在不同维度上进行着不断的创新。如在支持数据库方面,亚马逊云科技从MySQL开始,陆续为Amazon RDS添加了 MariaDB、Oracle、SQL Server 或 PostgreSQL 等;而在性能方面,去年12月,亚马逊云科技也引入了Amazon RDS Optimized Writes(优化写入)及 Amazon RDS Optimized Reads(优化读取)两个功能,将用户最为关注的数据库写入性能及读取性能全面地进行了大幅提升。

其中,Amazon RDS Optimized Writes功能,就可以帮助用户在不收取额外费用的情况下将写入事务吞吐量提高多达两倍,且能保持相同的预调配的IOPS 水平。具体来说,亚马逊云科技通过底层EC2上引入 Nitro卡,让EC2 能够自动处理16KiB 的页面刷新,从而无需再将16KiB 的数据切分到4KiB 再进行写入,从而能够显著降低 IO,提升写入的性能。也就是说,通过Amazon RDS Optimized Writes,用户可以使用统一的16KiB 数据库页面、文件系统块和操作系统页面,并以原子方式将它们写入存储(全部成功或全部失败),从而最高可以将性能提高至未开启的 Optimized Writes 的两倍。

而Amazon RDS Optimized Reads功能,同样可以帮助用户更加有效地利用实例本地高速 SSD 缓存临时表空间,以更低延迟和更高吞吐量对临时表空间进行高效访问,从而能够最高提升数据库50%的读取性能。也正因此,Amazon RDS Optimized Reads的引入,将在用户的以下场景中起到更多的作用,包括括复杂表表达式、派生表和分组操作的分析查询;处理未优化的应用程序查询的只读副本;具有复杂操作的按需或动态报告查询,无法始终使用适当的索引等等。
值得一提的是,Amazon RDS Optimized Writes和Amazon RDS Optimized Reads的加入,结合MySQL 8.0版本优势能够为使用者提供更极致性价比的 RDS 服务。MySQL 8.0在性能方面本身也实现了极大的提升,其速度本身将比 MySQL 5.7快2倍,官方测试数据也显示,MySQL 8.0 全内存访问可以轻松跑到200W QPS,I/O 极端高负载场景可以跑到16W QPS,无论是在读/写工作负载、IO 密集型工作负载、以及“hot spot”工作负载场景面,MySQL 8.0都有其显著的优势。
也正因此,借助Amazon RDS Optimized Writes和Amazon RDS Optimized Reads中的关键特性,同样也能更好地释放MySQL 8.0的性能优势,让用户在任何工作负载场景下都能实现“快人一步”。同时MySQL自1995年发布以来,历经多个版本迭代至MySQL 8.0,已成为MySQL社区体系内的主流版本和事实标准。
由此可见,亚马逊云科技领跑云数据库市场的背后,正是其长期以来坚持软硬件集成优化和融合创新的结果,由此实现了云数据库的高性能,这不仅是其竞争力的关键体现,更为亚马逊云科技连续八年入选Gartner魔力象限“领导者”的坚实基础。
极致高可用性的独特秘密
众所周知,云数据库在运行过程中总会遇到各种各样的问题,例如程序BUG、设备故障、机房断电等,因此理想的容灾架构和机制,就是要在这些问题发生时,能够保证数据的一致性和高可用性。
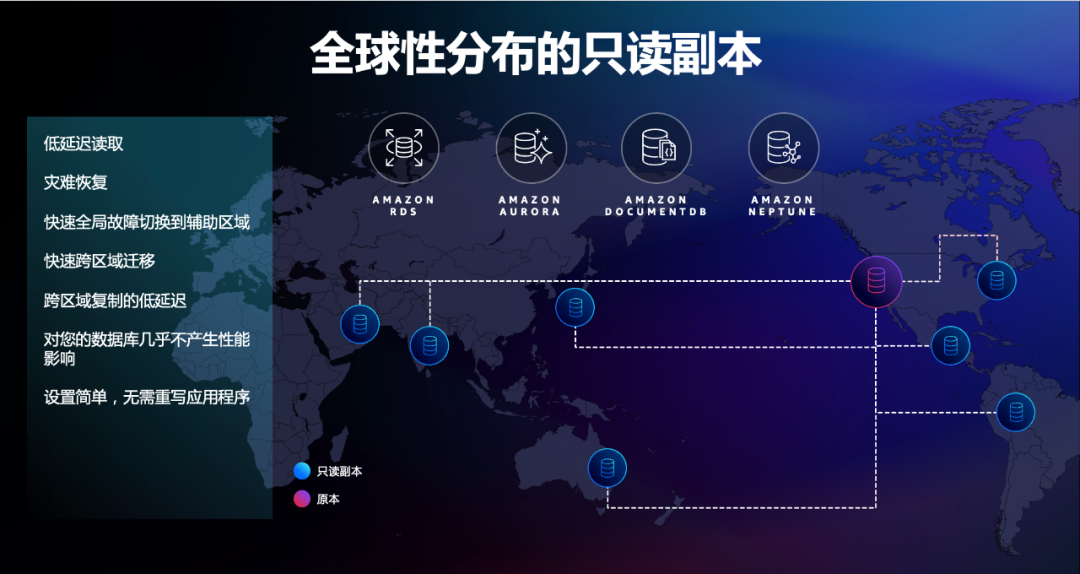
在这方面,亚马逊云科技的云数据库也始终以“极致高可用”作为第一考量,而其构建的Region(区域)内的跨可用区(Multi Availability Zone,Multi-AZ)的高可用能力,正是其独特的优势所在,而这种“全球架构,一键部署”的能力,不仅让用户真正无需担心灾难恢复等问题,同时更为用户构筑了一道云数据库高可用能力的“护城河”。
目前,亚马逊云科技所有的云数据库都具备 Multi-AZ 高可用特性。还是以Amazon RDS Multi-AZ为例,目前Amazon RDS 就为用户提供了丰富的多可用区部署选项,用户可以选择一个备用或两个备用数据库实例。
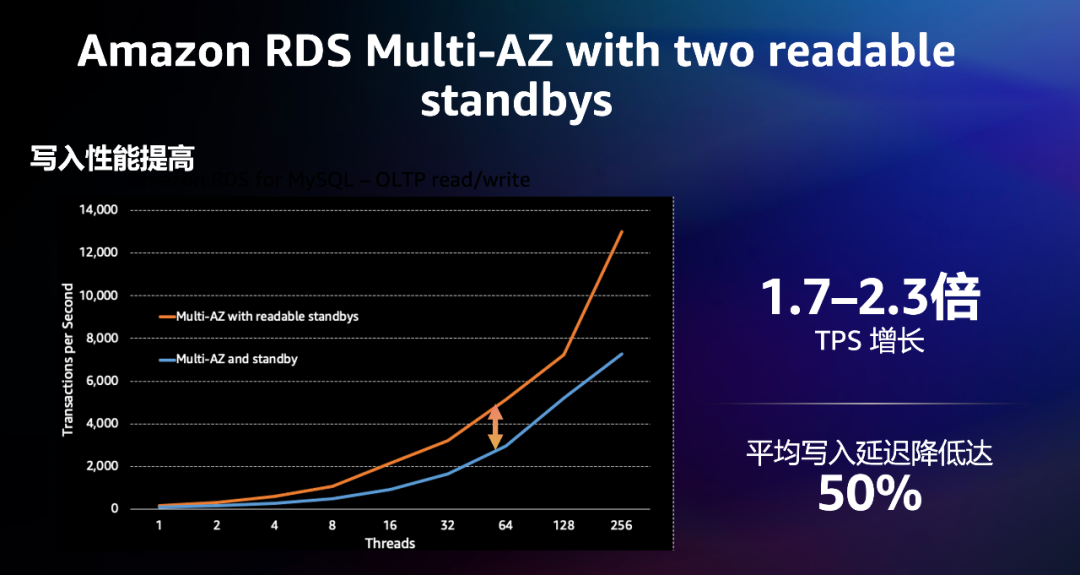
具体来看,Amazon RDS多可用区部署让RDS数据库实例的可用性和持久性得到提升,使其成为生产系统数据库工作负载的“天然搭档”。当用户预置多可用区数据库实例时,Amazon RDS 会自动创建主数据库实例,并将数据同步复制到不同可用区(AZ)中的备用实例。这样,每个可用区在其独立的、不同的基础设施中运行,并具备高可靠性。而如果基础设施出现故障停机,Amazon RDS 会自动执行故障转移到备用设备,以便在故障转移完成后立即恢复数据库操作。由于数据库实例的终端节点在故障转移后保持一致,所以应用程序无需手动管理干预即可恢复数据库操作。
在此过程中,当用户部署有一个备用数据库实例时,称为“多可用区数据库实例部署”,多可用区数据库实例部署有一个备用数据库实例,可提供故障转移支持,但不提供读取流量。当部署有两个备用数据库实例时,称为“多可用区数据库集群部署”,而多可用区数据库集群部署具有备用数据库实例,可提供故障转移支持,还可以提供读取流量。
数据显示,使用 Amazon RDS Multi-AZ 在三个可用区中部署具有高可用性和持久性的 MySQL 或 PostgreSQL 数据库,并提供两个可读备用实例。通常在不到 35 秒的时间内实现自动故障转移,与带一个备用实例的 Amazon RDS Multi-AZ 多可用区数据库实例部署相比,事务提交延迟快2倍,并拥有额外的读取容量。
截止目前,Amazon RDS 多可用区可用于 Amazon RDS for MariaDB、Amazon RDS for MySQL、Amazon RDS for PostgreSQL、Amazon RDS for Oracle 和 Amazon RDS for SQL Server。此外,带两个可读备用实例的 Amazon RDS 多可用区可用于 RDS for MySQL 和 RDS for PostgreSQL。
除了Multi-AZ 高可用特性之外,近期亚马逊云科技还推出了Amazon RDS Blue/Green Deployments (蓝/绿部署)功能,蓝/绿部署创建了一个完全托管的暂存环境,用户可以在其中部署和测试生产更改,从而确保当前生产数据库的安全,这样就可以更好地帮助用户更安全、更简单、更快速地更新 Amazon Aurora 和 Amazon RDS 数据库。
不难看出,亚马逊云科技这种Multi-AZ 高可用特性的优势给用户带来的价值体现在——用户能够最多跨三个可用区(AZ)部署高可用性、高耐用性云数据库,从而真正保证业务的一致性和稳定性,这种极致高可用的独特能力无疑是当下的其他云服务商所不具备的,也让亚马逊云科技的云数据库真正能够在企业关键业务中扮演“核心角色”的秘诀和关键所在。
引领时代更创造时代背后
事实上,无论是基于软硬件集成优化实现云数据库的高性能,还是基于Multi-AZ部署实现云数据的高可用性,都是亚马逊云科技在云数据库领域坚持技术创新的“缩影”,而今天其在创新的广度和深度方面,同样也在全球“首屈一指”。
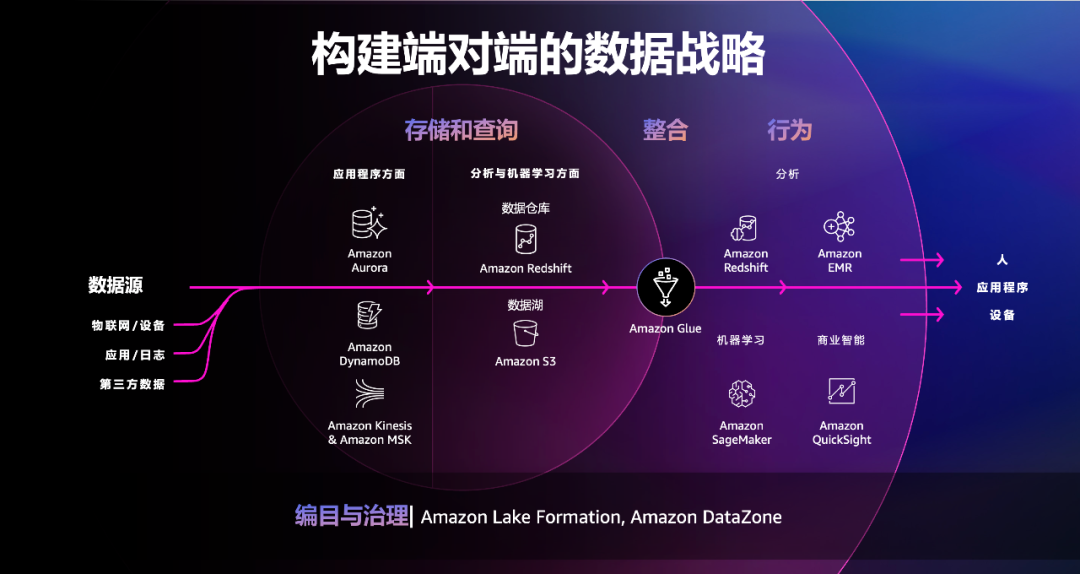
一方面,从创新的“广度”来看,亚马逊云科技从用户的需求入手,目前已构建出云原生端到端的数据战略,让用户可以更便捷、安全地获取数据洞察,而这种端到端的云数据产品的组合创新,也让亚马逊云科技在数据库市场日益受到用户的信赖和欢迎。
可以看到,早在2007年,亚马逊云科技就发布了首个数据库服务,随后在2009年推出了首个完全托管的MySQL数据库服务——关系型数据库Amazon RDS。2012年,亚马逊云科技推出了首个无服务器数据库Amazon DynamoDB,并推出了分析数据库Amazon Redshift,继续扩大其云数据库产品的“阵容”;之后,亚马逊云科技在2014年推出了云原生关系数据库Amazon Aurora,与 MySQL 和 PostgreSQL 兼容,性能与商业数据库相同,但成本只有商业数据库的十分之一,而且可以满足用户最苛刻的工作负载需求。
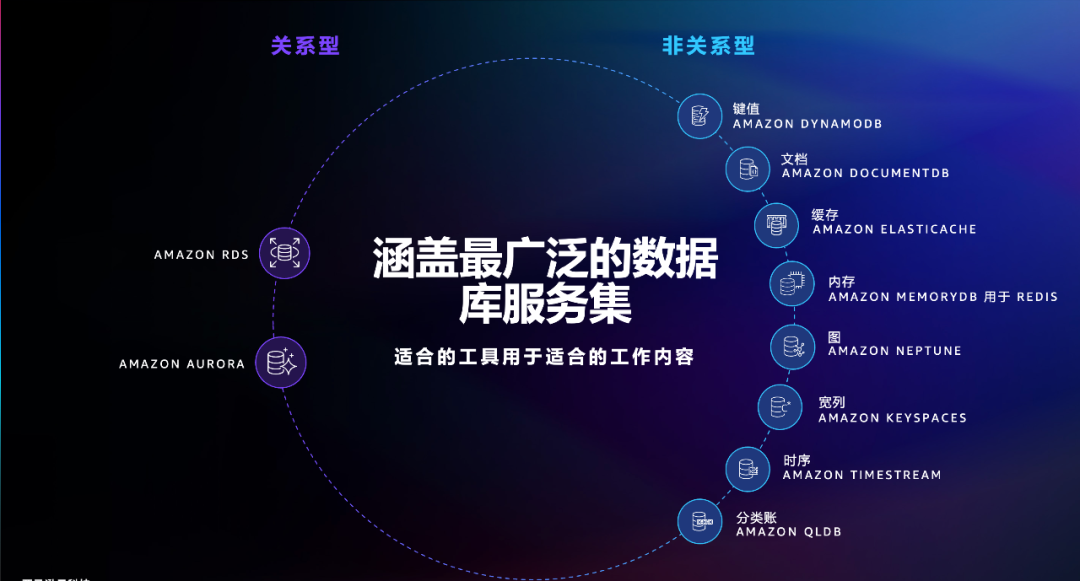
历经16年的发展,今天亚马逊云科技云数据产品线的“广度”是前所未有的。其中,针对运营场景的服务有Amazon RDS(托管式关系数据库)、Amazon Aurora(云原生关系数据库)、Amazon DynamoDB(键值数据库)、Amazon Neptune(图数据库)、Amazon DocumentDB(文档数据库)、Amazon Keyspaces(适用于Apache Cassandra)和Amazon MemoryDB(内存数据库);针对分析场景的服务有Amazon Redshift(数据仓库)、Amazon Athena(交互式数据查询服务)和Amazon EMR(大数据处理服务)。在此基础上,亚马逊云科技还提供专门构建的数据库服务Amazon Timestream(时序数据库)和Amazon Quantum Ledger Database(分类账数据库)等,以及兼容Redis和Memcached的数据库缓存服务Amazon ElastiCache等等,这也是亚马逊云科技在云数据库领域建立起强大“统治力”的关键。
另一方面,从创新的“深度”来看,亚马逊云科技也取得了重要的突破。其中,针对ETL(数据的提取、转换和加载过程),亚马逊云科技在去年也发布了两项全新的集成功能,帮助用户实现“Zero-ETL”。过去,企业业务数据往往需要通过ETL才能进行分析从而提供洞察,但这一过程往往耗时且枯燥。现在,用户可以使用Amazon Redshift近乎实时地分析Amazon Aurora中的数据,无需在不同服务之间进行ETL。用户还可以使用亚马逊云科技的分析和机器学习服务在Amazon Redshift的数据上轻松运行 Apache Spark应用程序。(深入阅读:《亚马逊云科技:“Zero ETL”迈出关键一步,数据由此实现“无感知”流动)

此外,数据服务Serverless化领域,Amazon OpenSearch也推出了Serverless无服务器功能,可帮助企业在无需配置、扩展或管理底层基础设施的情况下运行搜索和分析工作负载,这一更新也标志着亚马逊云科技数据分析服务的全面无服务器化。
到此为止,亚马逊云科技所有的数据分析服务都实现了Serverless化——除了Amazon OpenSearch Serverless之外,目前亚马逊云科技的“无服务器”数据分析服务已经涵盖了交互式查询服务Amazon Athena、大数据处理服务Amazon EMR、实时数据分析服务Amazon Kinesis和Amazon MSK、数据仓库服务Amazon Redshift、数据集成服务Amazon Glue以及业务智能(BI)服务Amazon QuickSight,而这一系列的产品矩阵,真正做到了让“无服务器”数据分析服务的体验“触手可及”,真正持续引领了Serverless技术创新的范式。
全文总结,连续八年入选Gartner云数据库领导者魔力象限,不仅证明了亚马逊云科技在云数据库领域的技术创新力和前瞻洞察力,以及作为市场领导者和颠覆者的强劲实力。尤为重要的是,通过更大力度的技术创新和落地实践,亚马逊云科技的云数据库也将为全球的企业实现更好的数字化转型构筑基石,而这也是其引领时代更创造时代的真实写照。

申耀的科技观察,由资深科技媒体人申斯基创办,20年企业级科技内容传播工作经验,长期专注产业互联网、企业数字化、ICT基础设施、汽车科技等内容的观察和思考。