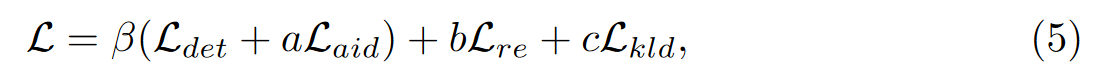目标检测作为计算机视觉的基本任务,随着深度神经网络的出现而取得了显著的进展。然而,很少有研究在各种现实场景中探索目标检测器抵抗对抗攻击的对抗鲁棒性。探测器已经受到不可察觉的扰动的极大挑战,在干净图像上的性能急剧下降,在对抗性图像上的性能极差。在本文中,我们对目标检测中对抗鲁棒性的模型训练进行了实证研究,这在很大程度上归因于学习干净图像和学习对抗图像之间的冲突。为了缓解这一问题,我们提出了一种基于对抗意识卷积的鲁棒检测器(RobustDet),用于在干净的和对抗的图像上解耦模型学习的梯度。RobustDet还采用对抗图像鉴别器(AID)和重建一致性特征(CFR)来确保可靠的鲁棒性。
文章主要贡献
1.通过实验分析了鲁棒目标检测器的鲁棒性瓶颈,验证了学习干净图像与学习对抗图像之间的冲突。
2. 在技术上,我们提出了一种基于对抗感知卷积的鲁棒检测模型(RobustDet),以学习干净图像和对抗图像的鲁棒特征。此外,我们提出了一致性特征与重建(CFR)来约束模型,以提取更健壮的特征,可以重建尽可能干净的图像。
3.实验中,我们进行了全面的实验,以评估所提出的方法在PASCAL VOC和MS-COCO数据集上的对抗检测鲁棒性,在干净图像和对抗图像上都实现了最先进的性能。该方法在干净图像上具有较高的精度,在对抗图像上具有较好的鲁棒性。
检测鲁棒性分析
文章从两方面进行了分析
1)学习对抗图像与干净图像的冲突
鲁棒检测模型在干净图像和对抗图像上都表现不佳。特别是,在干净图像和对抗性图像上进行对抗性训练会导致干净图像上的性能显著下降。这可能表明学习干净形象和学习对抗性形象之间存在冲突;因此,该模型必须在对抗性图像和干净图像之间做出妥协。为了进一步探究模型不能很好地学习两幅图像的原因,我们从两个方面进行了调查。
Loss changes for clean and adversarial images:
学习干净(对抗)图像后,对抗性(干净)图像的损失变化定义为clean→adv (adv→干净)。从图3的实验结果可以看出,clean→adv和adv→clean对于大多数图像都是正的,而clean→clean的负的结果最多。这说明学习干净图像和对抗性图像会增加大多数图像彼此的损失。对抗性图像对干净图像的影响大于干净图像对对抗图像的影响。这一验证表明,学习干净图像和对抗图像在某种程度上是模型的冲突任务。因此,在训练阶段,模型有责任很好地解决这种学习冲突。
Gradient interference analysis.
干净图像和对抗图像来自两个不同的领域,具有不同的模式。它们之间有共同的特点,但也有各自的特点。一个高度鲁棒的模型必须具有提取共享特征的参数,以及提取相互正交的特定特征的另外两个部分参数。对于对抗训练的鲁棒模型,应该已经很好地学习了两种图像的共享特征,只有处理特定特征的部分还需要加强。因此,对于该模型,两种图像生成的梯度应具有较低的相关性,且接近正交
方法
Adversarially-Aware Convolution (AAconv)
我们在我们的RobustDet模型中提出了对抗意识卷积,以学习干净图像和对抗图像的鲁棒特征。
在模型检测图像中对象之前。 对抗性图像鉴别器D首先生成图像的M维向量
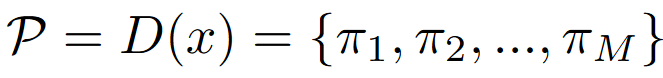
该概率向量用作控制卷积和生成的权重,最终生成的卷积核参数可以写成:
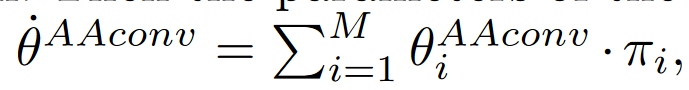
RobustDet使用对抗意识卷积自适应检测不同内核的不同图像,因此它可以有效地学习干净图像和对抗图像的鲁棒特征。它不仅可以提取共享特征,还可以对清晰和对抗性图像的特定特征负责。因此,更有效地缓解检测鲁棒性瓶颈。
Adversarial Image Discriminator (AID)
我们考虑同一类图像(即干净图像或对抗图像)的概率分布尽可能接近,不同类型图像(干净图像或对抗图像)的概率分布尽可能远。引入两种图像输出的概率分布之间的裕度,增强了对抗性图像鉴别器的鲁棒性。
使用JS散度来测量两个概率分布P1和P2之间的距离:
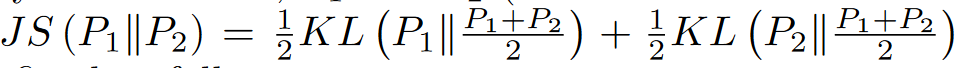
AID的loss:
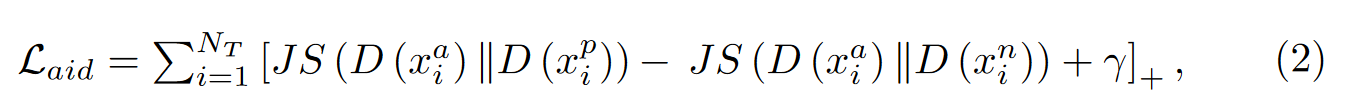
Consistent Features with Reconstruction (CFR)
我们的模型预测特征分布的均值和方差,重构损失可以表示为:
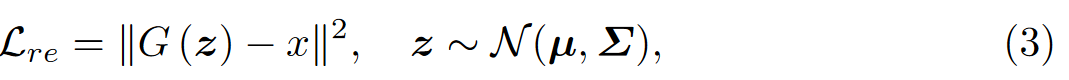
还需要额外约束来防止预测崩溃:‘
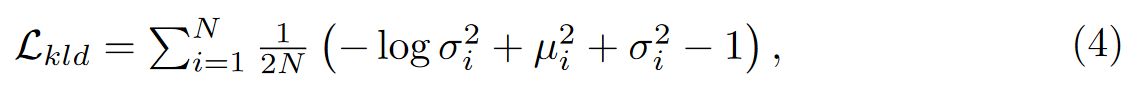
全部损失: