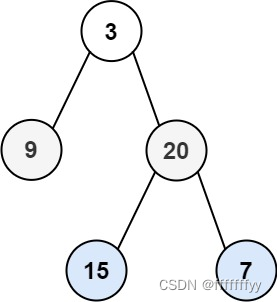
一、synchronized
一、原子性、有序性、可见性
1.1 原子性
数据库的事务:ACID
A:原子性-事务是一个最小的执行的单位,一次事务的多次操作要么都成功,要么都失败。
并发编程的原子性:一个或多个指令在CPU执行过程中不允许中断的。
i++;操作是原子性?
肯定不是:i++操作一共有三个指令
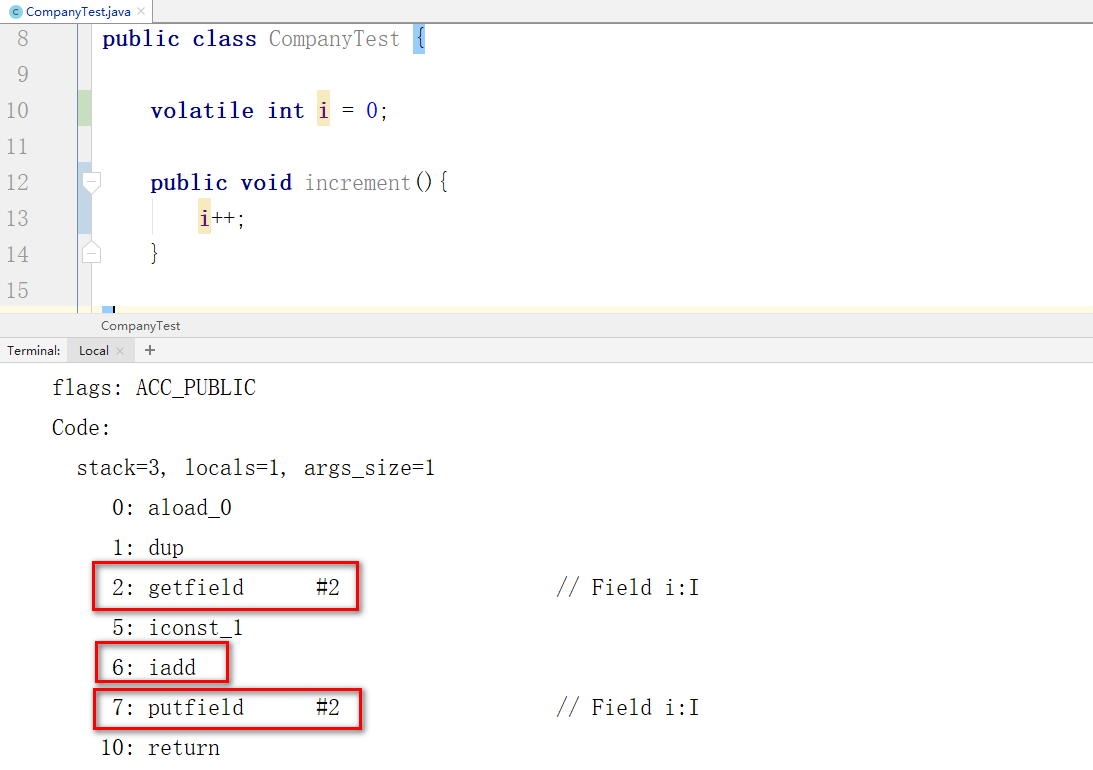
getfield:从主内存拉取数据到CPU寄存器
iadd:在寄存器内部对数据进行+1
putfield:将CPU寄存器中的结果甩到主内存中
如何保证i++是原子性的。
锁:synchronized,lock,Atomic(CAS)
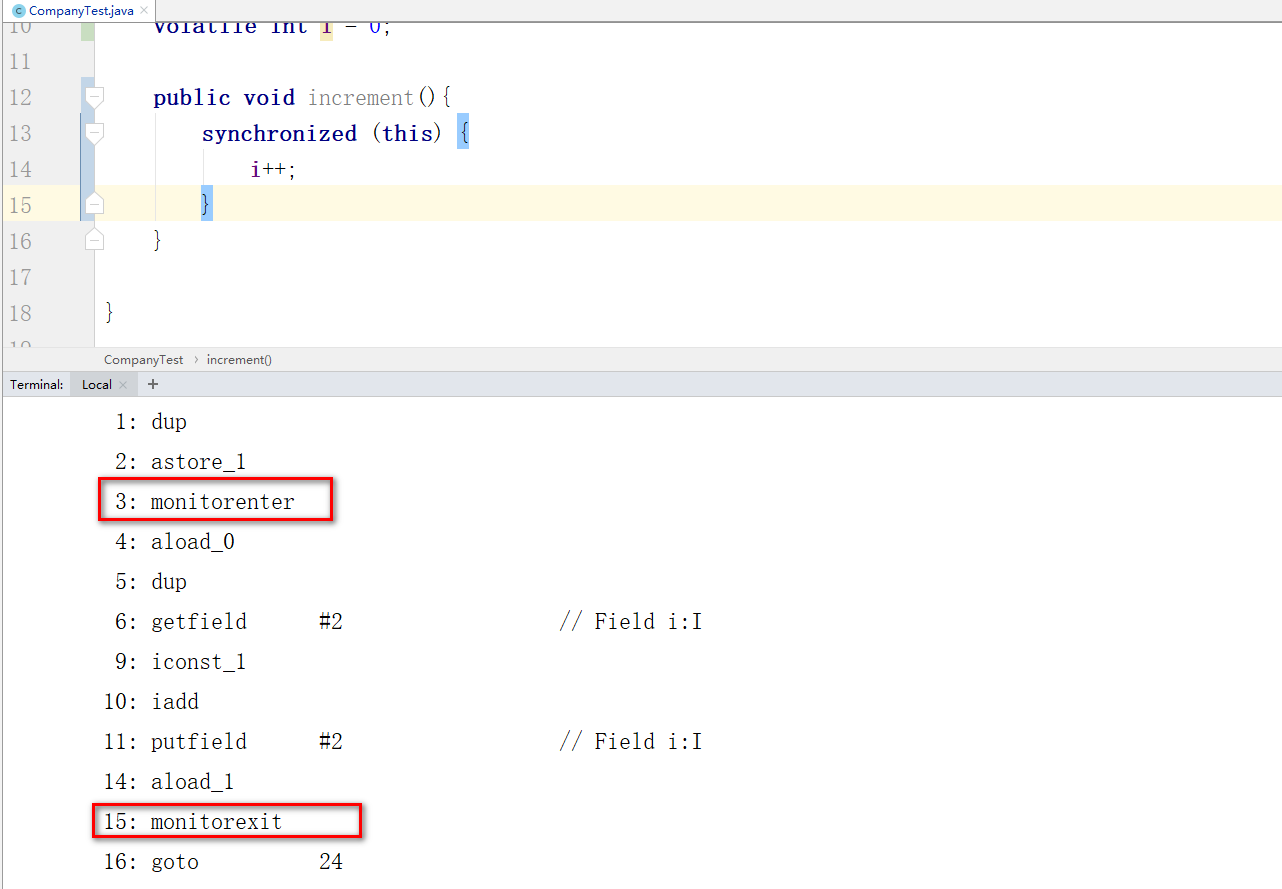
使用lock锁也会有类似的概念,也就是在操作i++的三个指令前,先基于AQS成功修改state后才可以操作
使用synchronized和lock锁时,可能会触发将线程挂起的操作,而这种操作会触发内核态和用户态的切换,从而导致消耗资源。
CAS方式就相对synchronized和lock锁的效率更高(也说不定),因为CAS不会触发线程挂起操作!
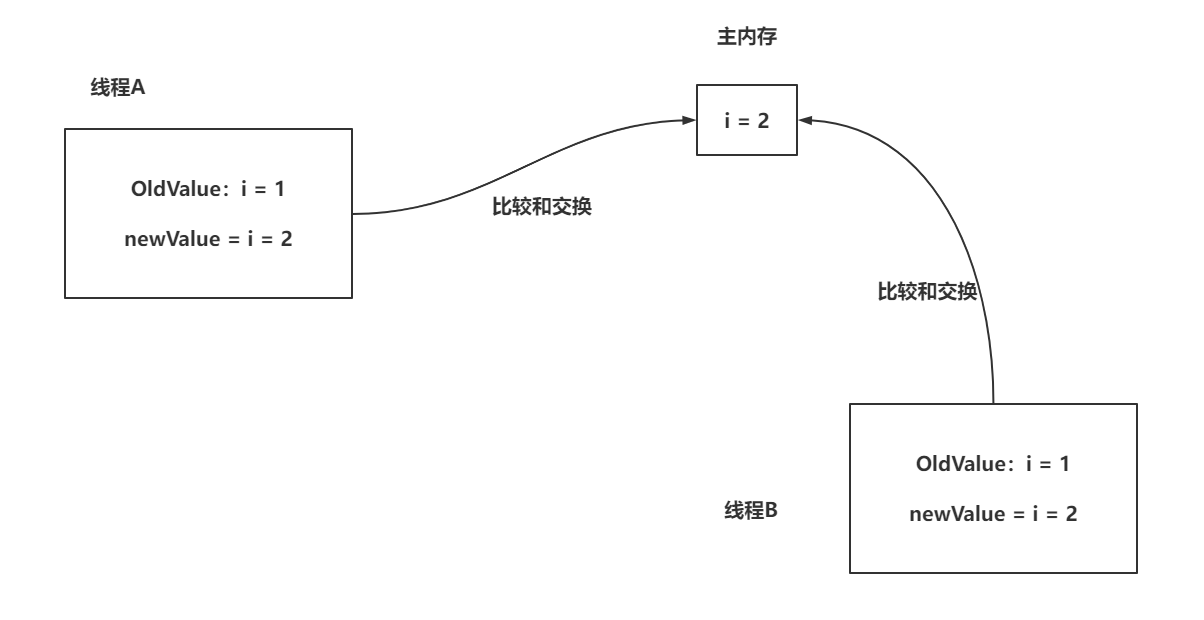
CAS:compare and swap
线程基于CAS修改数据的方式:先获取主内存数据,在修改之前,先比较数据是否一致,如果一致修改主内存数据,如果不一致,放弃这次修改
CAS就是比较和交换,而比较和交换是一个原子操作
CAS在Java层面就是Unsafe类中提供的一个native方法,这个方法只提供了CAS成功返回true,失败返回false,如果需要重试策略,自己实现!
CAS问题:
- CAS只能对一个变量的修改实现原子性。
- CAS存在ABA问题。
- A线程修改主内存数据从1~2,卡在了获取1之后。
- B线程修改主内存数据从1~2,完成。
- C线程修改主内存数据从2~1,完成。
- A线程执行CAS操作,发现主内存是1,没问题,直接修改
- 解决方案:加版本号
- 在CAS执行次数过多,但是依旧无法实现对数据的修改,CPU会一直调度这个线程,造成对CPU的性能损耗
- synchronized的实现方式:CAS自旋一定次数后,如果还不成,挂起线程
- LongAdder的实现方式:当CAS失败后,将操作的值,存储起来,后续一起添加
CAS:在多核情况下,有lock指令保证只有一个线程在执行当前CAS
1.2 有序性
指令在CPU调度执行时,CPU会为了提升执行效率,在不影响结果的前提下,对CPU指令进行重新排序。
如果不希望CPU对指定进行重排序,怎么办?
可以对属性追加volatile修饰,就不会对当前属性的操作进行指令重排序。
什么时候指令重排:满足happens-before原则,即可重排序
单例模式-DCL双重判断。
申请内存,初始化,关联是正常顺序,如果CPU对指令重排,可能会造成
申请内存,关联,初始化,在还没有初始化时,其他线程来获取数据,导致获取到的数据虽然有地址引用,但是内部的数据还没初始化,都是默认值,导致使用时,可能出现与预期不符的结果
1.3 可见性
可见性:前面说过CPU在处理时,需要将主内存数据甩到我的寄存机中再执行指令,指向完指令后,需要将寄存器数据扔回到主内存中。倒是寄存器数据同步到主内存是遵循MESI协议的,说人话就是,
不是每次操作结束就将CPU缓存数据同步到主内存。造成多个线程看到的数据不一样。
volatile每次操作后,立即同步数据到主内存。
synchronized,触发同步数据到主内存。
final,也可以解决可见性问题。
二、synchronized使用
2.1 synchronized的使用方式
synchronized方法
synchronized代码块
类锁和对象锁:
类锁:基础当前类的Class加锁
对象锁:基于this对象加锁
synchronized是互斥锁,每个线程获取synchronized时,基于synchronized绑定的对象去获取锁!
synchronized锁是基于对象实现的!
synchronized是如何基于对象实现的互斥锁,先了解对象再内存中是如何存储的。
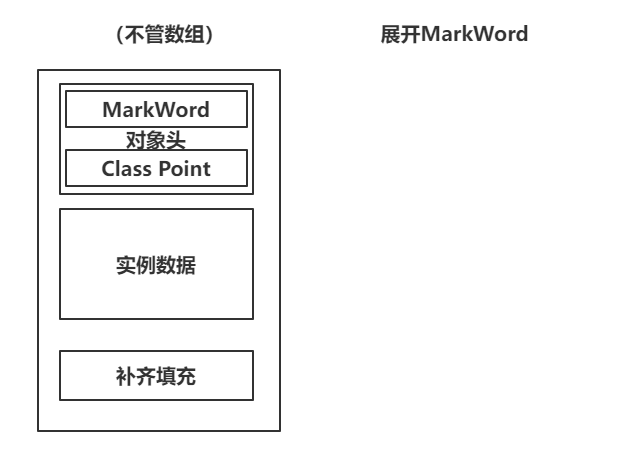

在Java中查看。
导入依赖:
<dependency><groupId>org.openjdk.jol</groupId><artifactId>jol-core</artifactId><version>0.9</version>
</dependency>
查看对象信息
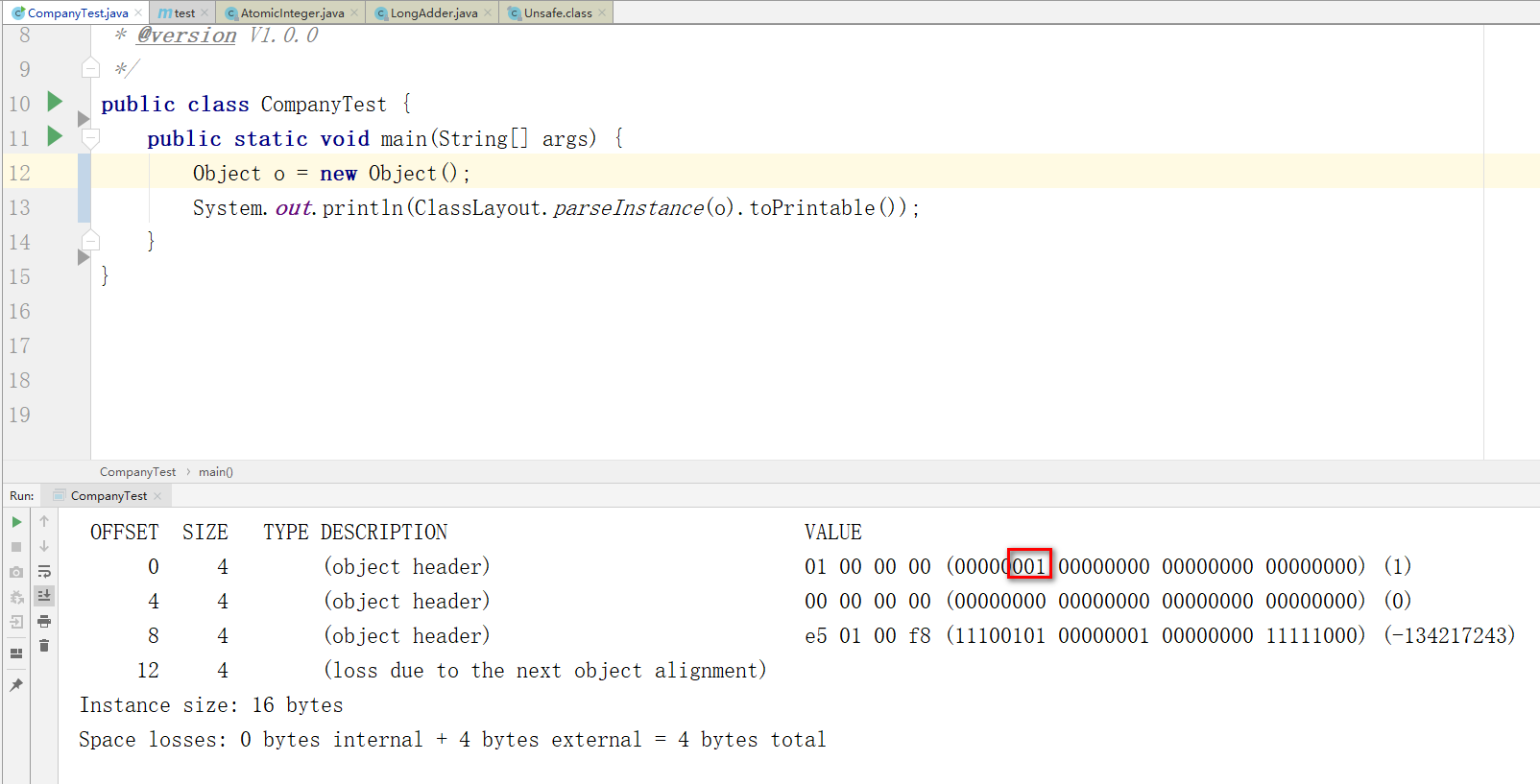
初始化的对象是无锁状态
三、synchronized锁升级
synchronized在jdk1.6之前,一直是重量级锁:只要线程获取锁资源失败,直接挂起线程(用户-内核)
在jdk1.6之前synchronized效率贼低,再加上Doug Lea推出了ReentrantLock,效率比synchronized快多了,导致JDK团队不得不在jdk1.6将synchronized做优化
锁升级:
- 无锁状态、匿名偏向状态:没有线程拿锁。
- 偏向锁状态:没有线程的竞争,只有一个线程再获取锁资源。
线程竞争锁资源时,发现当前synchronized没有线程占用锁资源,并且锁是偏向锁,使用CAS的方式,设置o的线程ID为当前线程,获取到锁资源,下次当前线程再次获取时,只需要判断是偏向锁,并且线程ID是当前线程ID即可,直接获得到锁资源。 - 轻量级锁:偏向锁出现竞争时,会升级到轻量级锁(触发偏向锁撤销)。
轻量级锁的状态下,线程会基于CAS的方式,尝试获取锁资源,CAS的次数是基于自适应自旋锁实现的,JVM会自动的基于上一次获取锁是否成功,来决定这次获取锁资源要CAS多少次。 - 重量级锁:轻量级锁CAS一段次数后,没有拿到锁资源,升级为重量级锁(其实CAS操作是在重量级锁时执行的)。
重量级锁就是线程拿不到锁,就挂起。
偏向锁是延迟开启的,并且在开启偏向锁之后,默认不存在无锁状态,只存在匿名偏向synchronized因为不存在从重量级锁降级到偏向或者是轻量。
synchronized在偏向锁升级到轻量锁时,会涉及到偏向锁撤销,需要等到一个安全点,stw,才可以撤销,并发偏向锁撤销比较消耗资源
在程序启动时,偏向锁有一个延迟开启的操作,因为项目启动时,ClassLoader会加载.class文件,这里会涉及到synchronized操作,
为了避免启动时,涉及到偏向锁撤销,导致启动效率变慢,所以程序启动时,默认不是开启偏向锁的。
如果在开启偏向锁的情况下,查看对象,默认对象是匿名偏向。
编译器优化的结果,出现了下列效果
锁消除:线程在执行一段synchronized代码块时,发现没有共享数据的操作,自动帮你把synchronized去掉。
锁膨胀:在一个多次循环的操作中频繁的获取和释放锁资源,synchronized在编译时,可能会优化到循环外部。
四、synchronized-ObjectMonitor
涉及ObjectMonitor一般是到达了重量级锁才会涉及到。
在到达重量级锁之后,重量级锁的指针会指向ObjectMonitor对象。
http://hg.openjdk.java.net/jdk8u/jdk8u/hotspot/file/69087d08d473/src/share/vm/runtime/objectMonitor.hpp
ObjectMonitor() {_header = NULL;_count = 0; // 抢占锁资源的线程个数_waiters = 0, // 调用wait的线程个数。_recursions = 0; // 可重入锁标记,_object = NULL; _owner = NULL; // 持有锁的线程_WaitSet = NULL; // wait的线程 (双向链表)_WaitSetLock = 0 ;_Responsible = NULL ;_succ = NULL ; // 假定的继承人(锁释放后,被唤醒的线程,有可能拿到锁资源)_cxq = NULL ; // 挂起线程存放的位置。(单向链表)FreeNext = NULL ;_EntryList = NULL ; // _cxq会在一定的机制下,将_cxq里的等待线程扔到当前_EntryList里。 (双向链表)_SpinFreq = 0 ;_SpinClock = 0 ;OwnerIsThread = 0 ;_previous_owner_tid = 0;}
偏向锁会降级到无锁状态嘛?怎么降?
会,当偏向锁状态下,获取当前对象的hashcode值,会因为对象头空间无法存储hashcode,导致降级到无锁状态。
二、ReentrantLock源码
一、ReentrantLock介绍
Java中提供锁,一般就是synchronized和lock锁,ReentrantLock是互斥锁,跟synchronized一样。
如果竞争比较激烈,推荐lock锁,效率更高
如果几乎没有竞争,推荐synchronized
原因:synchronized只有锁升级,当升级到重量级锁后,无法降级到轻量级、偏向锁。
lock锁的使用相对synchronized成本更高。
synchronized是非公平锁,lock是公平+非公平锁
lock锁提供的功能更完善,lock可以使用tryLock指定等待锁的时间
lock锁还提供了lockInterruptibly允许线程在获取锁的期间被中断。
synchronized基于对象实现,lock锁基于AQS+CAS实现
public static void main(String[] args) {ReentrantLock lock = new ReentrantLock();lock.lock();try{// 业务代码}finally{lock.unlock();}
}
二、ReentrantLock的lock方法源码
清楚lock方法是如何实现让当前线程获取到锁资源(什么效果算是拿到了锁资源)
非公平锁:上来先尝试将state从0修改为1,如果成功,代表获取锁资源。如果没有成功,调用acquire
公平锁:调用acquire
state是个什么鬼?
state是AQS中的一个由volatile修饰的int类型变量,多个线程会通过CAS的方式修改state,在并发情况下,只会有一个线程成功的修改state(从0~1)
如果线程修改state失败怎么办?
如果线程没有拿到锁资源,会到AQS的双向链表中排队等待(在期间,线程可能会挂起)
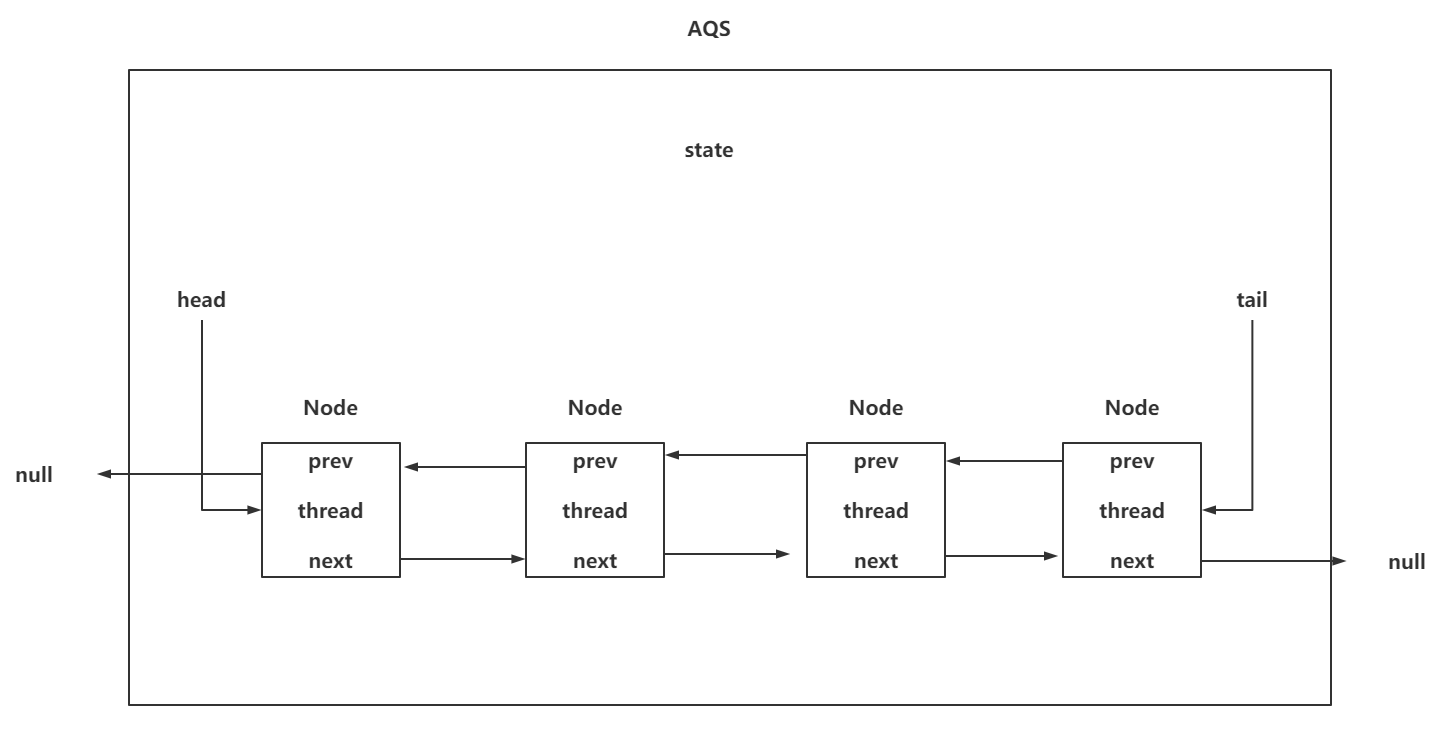
AQS的双向链表(队列)是个啥?
AQS中的双向链表是基于内部类Node在维护,Node中包含prev,next,thread属性,并且在AQS中还有两个属性,分别是head,tail。
画一下AQS的核心
公平&非公平的方法源码
// 公平锁的sync的lock方法
final void lock() {acquire(1);
}// 非公平锁的sync的lock方法
final void lock() {if (compareAndSetState(0, 1))setExclusiveOwnerThread(Thread.currentThread());elseacquire(1);
}
三、ReentrantLock的acquire方法源码
acquire是一个业务方法,里面并没有实际的业务处理,都是在调用其他方法
// 核心acquire arg = 1
public final void acquire(int arg) {//1. 调用tryAcquire方法:尝试获取锁资源(非公平、公平),拿到锁资源,返回true,直接结束方法。 没有拿到锁资源,// 需要执行&&后面的方法//2. 当没有获取锁资源后,会先调用addWaiter:会将没有获取到锁资源的线程封装为Node对象,// 并且插入到AQS的队列的末尾,并且作为tail//3. 继续调用acquireQueued方法,查看当前排队的Node是否在队列的前面,如果在前面(head的next),尝试获取锁资源// 如果没在前面,尝试将线程挂起,阻塞起来!if (!tryAcquire(arg) &&acquireQueued(addWaiter(Node.EXCLUSIVE), arg))selfInterrupt();
}
四、ReentrantLock的tryAcquire方法
tryAcquire分为公平和非公平两种、
tryAcquire主要做了两件事:
- 如果state为0,尝试获取锁资源
- 如果state不为0,看一下是不是锁重入操作
非公平:
// 非公平锁实现!
final boolean nonfairTryAcquire(int acquires) {// 拿到当前线程!final Thread current = Thread.currentThread();// 拿到AQS的stateint c = getState();// 如果state == 0,说明没有线程占用着当前的锁资源if (c == 0) {// 没人占用锁资源,我直接抢一波(不管有没有线程在排队)if (compareAndSetState(0, acquires)) {// 将当前占用这个互斥锁的线程属性设置为当前线程setExclusiveOwnerThread(current);// 返回true,拿锁成功return true;}}// 当前state != 0,说明有线程占用着锁资源// 判断拿着锁的线程是不是当前线程(锁重入)else if (current == getExclusiveOwnerThread()) {// 将state再次+1int nextc = c + acquires;// 锁重入是否超过最大限制// 01111111 11111111 11111111 11111111 + 1// 10000000 00000000 00000000 00000000// 抛出errorif (nextc < 0) throw new Error("Maximum lock count exceeded");// 将值设置给statesetState(nextc);// 返回true,拿锁成功return true;}return false;
}公平锁:
// 公平锁实现
protected final boolean tryAcquire(int acquires) {// 拿到当前线程!final Thread current = Thread.currentThread();// 拿到AQS的stateint c = getState();// 阿巴阿巴~~~~if (c == 0) {// 判断是否有线程在排队,如果有线程排队,返回true,配上前面的!,那会直接不执行返回最外层的falseif (!hasQueuedPredecessors() &&// 如果没有线程排队,直接CAS尝试获取锁资源compareAndSetState(0, acquires)) {setExclusiveOwnerThread(current);return true;}}else if (current == getExclusiveOwnerThread()) {int nextc = c + acquires;if (nextc < 0)throw new Error("Maximum lock count exceeded");setState(nextc);return true;}return false;
}
五、ReentrantLock的addWaiter方法
在获取锁资源失败后,需要将当前线程封装为Node对象,并且插入到AQS队列的末尾
// 将当前线程封装为Node对象,并且插入到AQS队列的末尾
private Node addWaiter(Node mode) {// 将当前线程封装为Node对象,mode为null,代表互斥锁Node node = new Node(Thread.currentThread(), mode);// pred是tail节点Node pred = tail;// 如果pred不为null,有线程正在排队if (pred != null) {// 将当前节点的prev,指定tail尾节点node.prev = pred;// 以CAS的方式,将当前节点变为tail节点if (compareAndSetTail(pred, node)) {// 之前的tail的next指向当前节点pred.next = node;return node;}}// 添加的流程为, 自己prev指向、tail指向自己、前节点next指向我// 如果上述方式,CAS操作失败,导致加入到AQS末尾失败,如果失败,就基于enq的方式添加到AQS队列enq(node);return node;
}// enq,无论怎样都添加进入
private Node enq(final Node node) {for (;;) {// 拿到tailNode t = tail;// 如果tail为null,说明当前没有Node在队列中if (t == null) { // 创建一个新的Node作为head,并且将tail和head指向一个Nodeif (compareAndSetHead(new Node()))tail = head;} else {// 和上述代码一致!node.prev = t;if (compareAndSetTail(t, node)) {t.next = node;return t;}}}
}
六、ReentrantLock的acquireQueued
acquireQueued方法会查看当前排队的Node是否是head的next,如果是,尝试获取锁资源,如果不是或者获取锁资源失败那么就尝试将当前Node的线程挂起(unsafe.park())
在挂起线程前,需要确认当前节点的上一个节点的状态必须是小于等于0,
如果为1,代表是取消的节点,不能挂起
如果为-1,代表挂起当前线程
如果为-2,-3,需要将状态改为-1之后,才能挂起当前线程
// acquireQueued方法
// 查看当前排队的Node是否是head的next,
// 如果是,尝试获取锁资源,
// 如果不是或者获取锁资源失败那么就尝试将当前Node的线程挂起(unsafe.park())
final boolean acquireQueued(final Node node, int arg) {// 标识。boolean failed = true;try {// 循环走起for (;;) {// 拿到上一个节点final Node p = node.predecessor();if (p == head && // 说明当前节点是head的nexttryAcquire(arg)) { // 竞争锁资源,成功:true,失败:false// 进来说明拿到锁资源成功// 将当前节点置位head,thread和prev属性置位nullsetHead(node);// 帮助快速GCp.next = null; // 设置获取锁资源成功failed = false;// 不管线程中断。return interrupted;}// 如果不是或者获取锁资源失败,尝试将线程挂起// 第一个事情,当前节点的上一个节点的状态正常!// 第二个事情,挂起线程if (shouldParkAfterFailedAcquire(p, node) &&// 通过LockSupport将当前线程挂起parkAndCheckInterrupt())}} finally {if (failed)cancelAcquire(node);}
}// 确保上一个节点状态是正确的
private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {// 拿到上一个节点的状态int ws = pred.waitStatus;// 如果上一个节点为 -1if (ws == Node.SIGNAL)// 返回true,挂起线程return true;// 如果上一个节点是取消状态if (ws > 0) {// 循环往前找,找到一个状态小于等于0的节点do {node.prev = pred = pred.prev;} while (pred.waitStatus > 0);pred.next = node;} else {// 将小于等于0的节点状态该为-1compareAndSetWaitStatus(pred, ws, Node.SIGNAL);}return false;
}
七、ReentrantLock的unlock方法
释放锁资源:
- 将state-1。
- 如果state减为0了,唤醒在队列中排队的Node。(一定唤醒离head最近的)
释放锁不分公平和非公平,就一个方法。
// 真正释放锁资源的方法
public final boolean release(int arg) {// 核心的释放锁资源方法if (tryRelease(arg)) {// 释放锁资源释放干净了。 (state == 0)Node h = head;// 如果头节点不为null,并且头节点的状态不为0,唤醒排队的线程if (h != null && h.waitStatus != 0)、// 唤醒线程unparkSuccessor(h);return true;}// 释放锁成功,但是state != 0return false;
}
// 核心的释放锁资源方法
protected final boolean tryRelease(int releases) {// 获取state - 1int c = getState() - releases;// 如果释放锁的线程不是占用锁的线程,抛异常if (Thread.currentThread() != getExclusiveOwnerThread())throw new IllegalMonitorStateException();// 是否成功的将锁资源释放利索 (state == 0)boolean free = false;if (c == 0) {// 锁资源释放干净。free = true;// 将占用锁资源的属性设置为nullsetExclusiveOwnerThread(null);}// 将state赋值setState(c);// 返回true,代表释放干净了return free;
}// 唤醒节点
private void unparkSuccessor(Node node) {// 拿到头节点状态int ws = node.waitStatus;// 如果头节点状态小于0,换为0if (ws < 0)compareAndSetWaitStatus(node, ws, 0);// 拿到当前节点的nextNode s = node.next;// 如果s == null ,或者s的状态为1if (s == null || s.waitStatus > 0) {// next节点不需要唤醒,需要唤醒next的nexts = null;// 从尾部往前找,找到状态正常的节点。(小于等于0代表正常状态)for (Node t = tail; t != null && t != node; t = t.prev)if (t.waitStatus <= 0)s = t;}// 经过循环的获取,如果拿到状态正常的节点,并且不为nullif (s != null)// 唤醒线程LockSupport.unpark(s.thread);
}
为什么唤醒线程时,为啥从尾部往前找,而不是从前往后找?
因为在addWaiter操作时,是先将当前Node的prev指针指向前面的节点,然后是将tail赋值给当前Node,最后才是能上一个节点的next指针,指向当前Node。
如果从前往后,通过next去找,可能会丢失某个节点,导致这个节点不会被唤醒~
如果从后往前找,肯定可以找到全部的节点。
三、ReentrantReadWriteLock读写锁源码
一、为什么要出现读写锁
因为ReentrantLock是互斥锁,如果有一个操作是读多写少,同时还需要保证线程安全,那么使用ReentrantLock会导致效率比较低。
因为多个线程在对同一个数据进行读操作时,也不会造成线程安全问题。
所以出现了ReentrantReadWriteLock锁:
读读操作是共享的。
写写操作是互斥的。
读写操作是互斥的。
写读操作是互斥的。
单个线程获取写锁后,再次获取读锁,可以拿到。(写读可重入)
单个线程获取读锁后,再次获取写锁,拿不到。(读写不可重入)
使用方式:
public class XxxTest {// 读写锁!static ReentrantReadWriteLock lock = new ReentrantReadWriteLock();// 写锁static ReentrantReadWriteLock.WriteLock writeLock = lock.writeLock();// 读锁static ReentrantReadWriteLock.ReadLock readLock = lock.readLock();public static void main(String[] args) throws InterruptedException {readLock.lock();try {System.out.println("拿到读锁!");} finally {readLock.unlock();}writeLock.lock();try {System.out.println("拿到写锁!");} finally {writeLock.unlock();}}
}
二、读写锁的核心思想
ReentrantReadWriteLock还是基于AQS实现的。很多功能的实现和ReentrantLock类似
还是基于AQS的state来确定当前线程是否拿到锁资源
state表示读锁:将state的高16位作为读锁的标识
state表示写锁:将state的低16位作为写锁的标识
锁重入问题:
- 写锁重入怎么玩:因为写操作和其他操作是互斥的,代表同一时间,只有一个线程持有着写锁,只要锁重入,就对低位+1即可。而且锁重入的限制,从原来的2^31 - 1,变为了2 ^ 16 -1。变短了~~
- 读锁重入怎么玩:读锁的重入不能仿照写锁的方式,因为写锁属于互斥锁,同一时间只会有一个线程持有写锁,但是读锁是共享锁,同一时间会有多个线程持有读锁。所以每个获取到读锁的线程,记录锁重入的方式都是基于自己的ThreadLocal存储锁重入次数。
读锁重入的时候就不操作state了?不对,每次锁重入还要修改state,只是记录当前线程锁重入的次数,需要基于ThreadLocal记录
00000000 00000000 00000000 00000000 : state
写锁:
00000000 00000000 00000000 00000001
写锁:
00000000 00000000 00000000 00000010
A读锁:拿不到,排队
00000000 00000000 00000000 00000010
写锁全部释放(唤醒)
00000000 00000000 00000000 00000000
A读锁:
00000000 00000001 00000000 00000000
B读锁:
00000000 00000010 00000000 00000000
B再次读锁:
00000000 00000011 00000000 00000000
每个读操作的线程,在获取读锁时,都需要开辟一个ThreadLocal。读写锁为了优化这个事情,做了两手操作:
- 第一个拿到读锁的线程,不用ThreadLocal记录重入次数,在读写锁内有有一个firstRead记录重入次数
- 还记录了最后一个拿到读锁的线程的重入次数,交给cachedHoldCounter属性标识,可以避免频繁的在锁重入时,从TL中获取
三、写锁的操作
3.1 写锁加锁-acquire
public final void acquire(int arg) {// 尝试获取锁资源(看一下,能否以CAS的方式将state 从0 ~ 1,改成功,拿锁成功)// 成功走人// 不成功执行下面方法if (!tryAcquire(arg) &&// addWaiter:将当前没按到锁资源的,封装成Node,排到AQS里// acquireQueued:当前排队的能否竞争锁资源,不能挂起线程阻塞acquireQueued(addWaiter(Node.EXCLUSIVE), arg))selfInterrupt();
}
因为都是AQS的实现,主要看tryAcquire
// state,高16:读,低16:写
00000000 00000000 00000000 0000000000000000 00000001 00000000 00000000 - SHARED_UNIT00000000 00000000 11111111 11111111 - MAX_COUNT00000000 00000000 11111111 11111111 - EXCLUSIVE_MASK
&
00000000 00000000 00000000 00000001 static final int SHARED_SHIFT = 16;
static final int SHARED_UNIT = (1 << SHARED_SHIFT);
static final int MAX_COUNT = (1 << SHARED_SHIFT) - 1;
static final int EXCLUSIVE_MASK = (1 << SHARED_SHIFT) - 1;// 只拿到表示读锁的高16位。
static int sharedCount(int c) { return c >>> SHARED_SHIFT; }
// 只拿到表示写锁的低16位。
static int exclusiveCount(int c) { return c & EXCLUSIVE_MASK; }// 读写锁的写锁,获取流程
protected final boolean tryAcquire(int acquires) {// 拿到当前线程Thread current = Thread.currentThread();// 拿到stateint c = getState();// 拿到了写锁的低16位标识wint w = exclusiveCount(c);// c != 0:要么有读操作拿着锁,要么有写操作拿着锁if (c != 0) {// 如果w == 0,代表没有写锁,拿不到!拜拜!// 如果w != 0,代表有写锁,看一下拿占用写锁是不是当前线程,如果不是,拿不到!拜拜!if (w == 0 || current != getExclusiveOwnerThread())return false;// 到这,说明肯定是写锁,并且是当前线程持有// 判断对低位 + 1,是否会超过MAX_COUNT,超过抛Errorif (w + exclusiveCount(acquires) > MAX_COUNT)throw new Error("Maximum lock count exceeded");// 如果没超过锁重入次数, + 1,返回true,拿到锁资源。setState(c + acquires);return true;}// 到这,说明c == 0// 读写锁也分为公平锁和非公平锁// 公平:看下排队不,排队就不抢了// 走hasQueuedPredecessors方法,有排队的返回true,没排队的返回false// 非公平:直接抢!// 方法实现直接返回falseif (writerShouldBlock() ||// 以CAS的方式,将state从0修改为 1!compareAndSetState(c, c + acquires))// 要么不让抢,要么CAS操作失败,返回falsereturn false;// 将当前持有互斥锁的线程,设置为自己setExclusiveOwnerThread(current);return true;
}
剩下的addWaiter和acquireQueued和ReentrantLock看的一样,都是AQS自身提供的方法
3.2 写锁-释放锁操作
读写锁的释放操作,跟ReentrantLock一致,只是需要单独获取低16位,判断是否为0,为0就释放成功
// 写锁的释放锁
public final boolean release(int arg) {// 只有tryRealse是读写锁重新实现的方法,其他的和ReentrantLock一致if (tryRelease(arg)) {Node h = head;if (h != null && h.waitStatus != 0)unparkSuccessor(h);return true;}return false;
}// 读写锁的真正释放
protected final boolean tryRelease(int releases) {// 判断释放锁的线程是不是持有锁的线程if (!isHeldExclusively())// 不是抛异常throw new IllegalMonitorStateException();// 对state - 1int nextc = getState() - releases;// 拿着next从获取低16位的值,判断是否为0boolean free = exclusiveCount(nextc) == 0;// 返回trueif (free)// 将持有互斥锁的线程信息置位nullsetExclusiveOwnerThread(null);// 将-1之后的nextc复制给statesetState(nextc);return free;
}
四、读锁的操作
4.1 读锁的加锁操作
// 读锁加锁操作
public final void acquireShared(int arg) {// tryAcquireShared,尝试获取锁资源,获取到返回1,没获取到返回-1if (tryAcquireShared(arg) < 0)// doAcquireShared 前面没拿到锁,这边需要排队~doAcquireShared(arg);
}// tryAcquireShared方法
protected final int tryAcquireShared(int unused) {// 获取当前线程Thread current = Thread.currentThread();// 拿到stateint c = getState();// 那写锁标识,如果 !=0,代表有写锁if (exclusiveCount(c) != 0 &&// 如果持有写锁的不是当前线程,排队去!getExclusiveOwnerThread() != current)// 排队!return -1;// 没有写锁!// 获取读锁信息int r = sharedCount(c);// 公平锁: 有人排队,返回true,直接拜拜,没人排队,返回false// 非公平锁:正常的逻辑是非公平直接抢,因为是读锁,每次抢占只要CAS成功,必然成功// 这就会出现问题,写操作无法在读锁的情况抢占资源,导致写线程饥饿,一致阻塞…………// 非公平锁会查看next是否是写锁的,如果是,返回true,如果不是返回falseif (!readerShouldBlock() &&// 查看读锁是否已经达到了最大限制r < MAX_COUNT &&// 以CAS的方式,对state的高16位+1compareAndSetState(c, c + SHARED_UNIT)) {// 拿到锁资源成功!!!if (r == 0) {// 第一个拿到锁资源的线程,用first存储firstReader = current;firstReaderHoldCount = 1;} else if (firstReader == current) {// 我是锁重入,我就是第一个拿到读锁的线程,直接对firstReaderHoldCount++记录重入的次数firstReaderHoldCount++;} else {// 不是第一个拿到锁资源的// 先拿到cachedHoldCounter,最后一个线程的重入次数HoldCounter rh = cachedHoldCounter;// rh == null: 我是第二个拿到读锁的!// 或者发现之前有最后一个来的,但是不我,将我设置为最后一个。if (rh == null || rh.tid != getThreadId(current))// 获取自己的重入次数,并赋值给cachedHoldCountercachedHoldCounter = rh = readHolds.get();// 之前拿过,现在如果为0,赋值给TLelse if (rh.count == 0)readHolds.set(rh);// 重入次数+1,// 第一个:可能是第一次拿// 第二个:可能是重入操作rh.count++;}return 1;}return fullTryAcquireShared(current);
}// 通过tryAcquireShared没拿到锁资源,也没返回-1,就走这
final int fullTryAcquireShared(Thread current) {HoldCounter rh = null;for (;;) {// 拿stateint c = getState();// 现在有互斥锁,不是自己,拜拜!if (exclusiveCount(c) != 0) {if (getExclusiveOwnerThread() != current)return -1;// 公平:有排队的,进入逻辑。 没排队的,过!// 非公平:head的next是写不,是,进入逻辑。 如果不是,过!} else if (readerShouldBlock()) {// 这里代码特别乱,因为这里的代码为了处理JDK1.5的内存泄漏问题,修改过~// 这个逻辑里不会让你拿到锁,做被阻塞前的准备if (firstReader == current) {// 什么都不做} else {if (rh == null) {// 获取最后一个拿到读锁资源的rh = cachedHoldCounter;if (rh == null || rh.tid != getThreadId(current)) {// 拿到我自己的记录重入次数的。rh = readHolds.get();// 如果我的次数是0,绝对不是重入操作!if (rh.count == 0)// 将我的TL中的值移除掉,不移除会造成内存泄漏readHolds.remove();}}// 如果我的次数是0,绝对不是重入操作!if (rh.count == 0)// 返回-1,等待阻塞吧!return -1;}}// 超过读锁的最大值了没?if (sharedCount(c) == MAX_COUNT)throw new Error("Maximum lock count exceeded");// 到这,就CAS竞争锁资源if (compareAndSetState(c, c + SHARED_UNIT)) {// 跟tryAcquireShared一模一样if (sharedCount(c) == 0) {firstReader = current;firstReaderHoldCount = 1;} else if (firstReader == current) {firstReaderHoldCount++;} else {if (rh == null)rh = cachedHoldCounter;if (rh == null || rh.tid != getThreadId(current))rh = readHolds.get();else if (rh.count == 0)readHolds.set(rh);rh.count++;cachedHoldCounter = rh; }return 1;}}
}
4.2 加锁-扔到队列准备阻塞操作
// 没拿到锁,准备挂起
private void doAcquireShared(int arg) {// 将当前线程封装为Node,当前Node为共享锁,并添加到队列的模式final Node node = addWaiter(Node.SHARED);boolean failed = true;try {boolean interrupted = false;for (;;) {// 获取上一个节点final Node p = node.predecessor();if (p == head) {// 如果我的上一个是head,尝试再次获取锁资源int r = tryAcquireShared(arg);if (r >= 0) {// 如果r大于等于0,代表获取锁资源成功// 唤醒AQS中我后面的要获取读锁的线程(SHARED模式的Node)setHeadAndPropagate(node, r);p.next = null; if (interrupted)selfInterrupt();failed = false;return;}}// 能否挂起当前线程,需要保证我前面Node的状态为-1,才能执行后面操作if (shouldParkAfterFailedAcquire(p, node) &&//LockSupport.park挂起~~parkAndCheckInterrupt())interrupted = true;}} finally {if (failed)cancelAcquire(node);}
}
四、线程池源码
一、线程池介绍
Java构建线程的方式
- new Thread
- new Runnable
- new Callable
为了避免频繁创建和销毁线程造成不必要的性能,一般在使用线程时,会采用线程池
核心线程数设置的方案:

线程池使用方式:
public static void main(String[] args) {// 线程池的核心线程数如何设置// 任务可以分为两种:CPU密集,IO密集。ThreadPoolExecutor executor = new ThreadPoolExecutor(1,2,1,TimeUnit.SECONDS,new ArrayBlockingQueue<>(1),new ThreadFactory() {@Overridepublic Thread newThread(Runnable r) {Thread t = new Thread(r);// ...return t;}},new ThreadPoolExecutor.AbortPolicy());executor.execute(任务);executor.submit(有返回结果的任务);
}
二、线程池核心属性认知
// AtomicInteger,就是一个int,写操作用CAS实现,保证了原子性
// ctl维护这线程池的2个核心内容:
// 1:线程池状态(高3位,维护着线程池状态)
// 2:工作线程数量(核心线程+非核心线程,低29位,维护着工作线程个数)
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
// COUNT_BITS=29
private static final int COUNT_BITS = Integer.SIZE - 3;
// 工作线程的最大个数
// 00100000 00000000 00000000 00000000 - 1
// 000111111111111111111111111111111
private static final int CAPACITY = (1 << COUNT_BITS) - 1;private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS;// 拿到线程池状态
// 011...
// 111...
private static int runStateOf(int c) { return c & ~CAPACITY; }
// 拿到工作线程个数
// ...0000000111111
// ...1111111111111
private static int workerCountOf(int c) { return c & CAPACITY; }
线程池状态
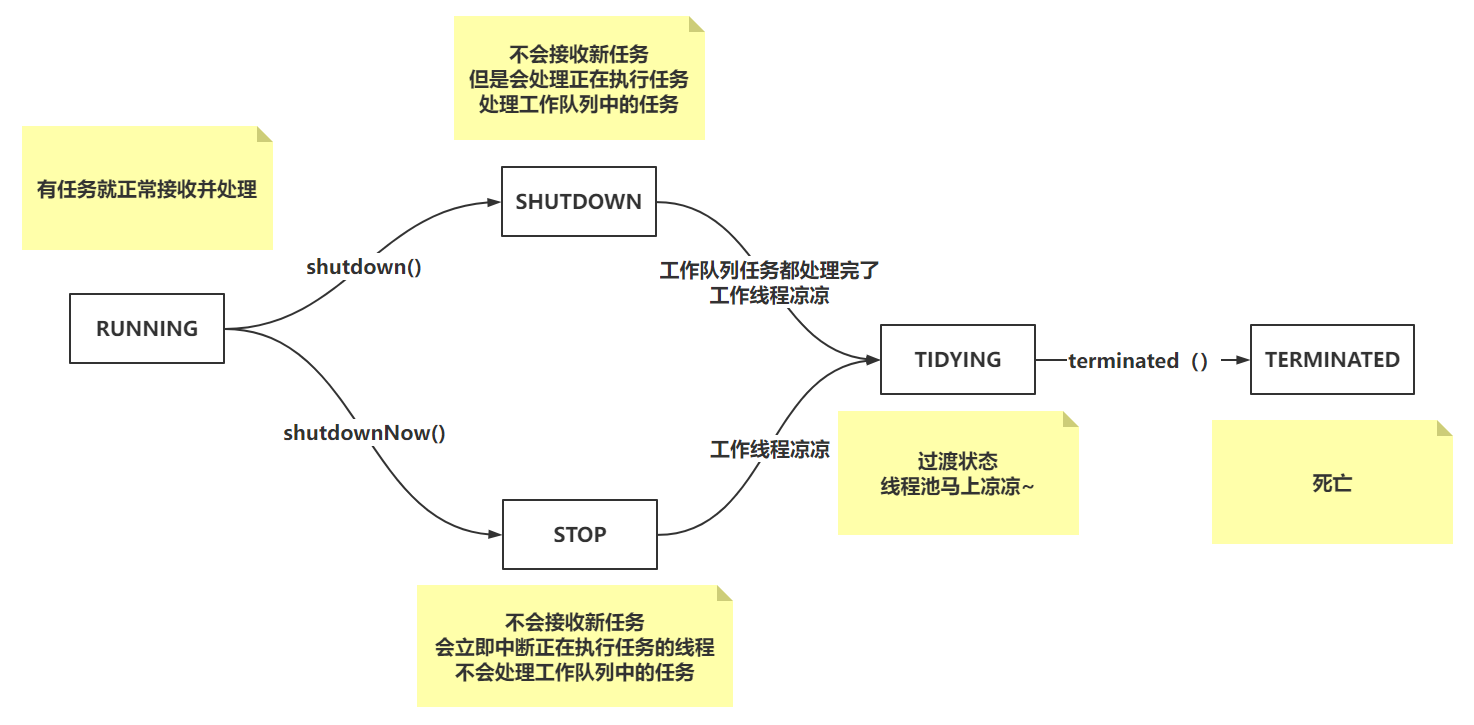
三、execute方法
通过execute方法,可以看到线程池处理任务的整体执行流程
public void execute(Runnable command) {// 非空!!if (command == null)throw new NullPointerException();// 拿到ctlint c = ctl.get();// 通过ctl获取当前工作线程个数if (workerCountOf(c) < corePoolSize) {// true:代表是核心线程,false:代表是非核心线程if (addWorker(command, true))// 如果添加核心线程成功,return结束掉return;// 如果添加失败,重新获取ctlc = ctl.get();}// 核心线程数已经到了最大值、添加时,线程池状态变为SHUTDOWN/STOP// 判断线程池是否是运行状态 && 添加任务到工作队列if (isRunning(c) && workQueue.offer(command)) {// 再次获取ctl的值int recheck = ctl.get();// 再次判断线程池状态。 DCL// 如果状态不是RUNNING,把任务从工作队列移除。if (! isRunning(recheck) && remove(command))// 走一波拒绝策略。reject(command);// 线程池状态是RUNNING。// 判断工作线程数是否是0个。// 可以将核心线程设置为0,所有工作线程都是非核心线程。// 核心线程也可以通过keepAlived超时被销毁,所以如果恰巧核心线程被销毁,也会出现当前效果else if (workerCountOf(recheck) == 0)// 添加空任务的非核心线程去处理工作队列中的任务addWorker(null, false);}// 可能工作队列中的任务存满了,没添加进去,到这就要添加非核心线程去处理任务else if (!addWorker(command, false))// 执行拒绝策略!reject(command);
}
四、addWorker添加工作线程
private boolean addWorker(Runnable firstTask, boolean core) {xxx:for (;;) {// 阿巴阿巴…………int c = ctl.get();int rs = runStateOf(c);// 判断线程池状态if (rs >= SHUTDOWN &&// 判断如果线程池的状态为SHUTDOWN,还要处理工作队列中的任务// 如果你添加工作线程的方式,是任务的非核心线程,并且工作队列还有任务! (rs == SHUTDOWN && firstTask == null && ! workQueue.isEmpty()))return false;// 判断工作线程个数for (;;) {// 阿巴阿巴……int wc = workerCountOf(c);// 判断1:工作线程是否已经 == 工作线程最大个数// 判断2-true判断:判断是核心线程么?如果是判断是否超过核心线程个数// 判断2-false判断:如果是非核心线程,查看是否超过设置的最大线程数if (wc >= CAPACITY || wc >= (core ? corePoolSize : maximumPoolSize))return false;// 对工作线程进行 + 1操作if (compareAndIncrementWorkerCount(c))// +1成功,跳出外层循环,执行添加工作线程的业务// 以CAS方式,对ctl+1,多线程并发操作,只有会有一个成功break xxx;// 重新拿ctl,c = ctl.get();// 判断线程池状态是否有变化if (runStateOf(c) != rs)continue xxx;}}// 添加工作线程的业务 // 工作线程启动了吗?boolean workerStarted = false;// 工作线程添加了吗?boolean workerAdded = false;// Worker就是工作线程Worker w = null;try {// 创建工作线程,将任务传到Worker中w = new Worker(firstTask);final Thread t = w.thread;// 只有你写的线程工厂返回的是null,这里才会为nullif (t != null) {// 获取锁资源final ReentrantLock mainLock = this.mainLock;// 加锁。 因为我要在启动这个工作线程时,避免线程池状态发生变化,加锁。mainLock.lock();try {// 重新获取ctl,拿到线程池状态int rs = runStateOf(ctl.get());// DCL i think you know~~~if (rs < SHUTDOWN ||(rs == SHUTDOWN && firstTask == null)) {// 判断Worker中的thread是否已经启动了,一般不会启动,除非你在线程工厂把他启动了if (t.isAlive()) throw new IllegalThreadStateException();// 将工作线程存储到hashSet中workers.add(w);// 获取工作线程个数,判断是否需要修改最大工作线程数记录。int s = workers.size();if (s > largestPoolSize)largestPoolSize = s;// 工作线程添加成功 0workerAdded = true;}} finally {mainLock.unlock();}// 如果添加成功if (workerAdded) {// 启动工作线程t.start();// 设置标识为trueworkerStarted = true;}}} finally {// 如果工作线程启动失败if (! workerStarted)addWorkerFailed(w);}return workerStarted;
}// 如果添加工作线程失败,执行
private void addWorkerFailed(Worker w) {final ReentrantLock mainLock = this.mainLock;mainLock.lock();try {// 说明worker可能存放到了workers的hashSet中。if (w != null)// 移除!workers.remove(w);// 减掉workerCount的数值 -1decrementWorkerCount();// 尝试干掉自己tryTerminate();} finally {mainLock.unlock();}
}
五、runWorker执行任务
final void runWorker(Worker w) {// 拿到当前线程对象Thread wt = Thread.currentThread();// 拿到worker中存放的RunnableRunnable task = w.firstTask;// 将worker中的任务清空w.firstTask = null;// 揍是一个标识boolean completedAbruptly = true;try {// 如果Worker自身携带任务,直接执行// 如果Worker携带的是null,通过getTask去工作队列获取任务while (task != null || (task = getTask()) != null) {w.lock();// 判断线程池状态是否大于等于STOP,如果是要中断当前线程if ((runStateAtLeast(ctl.get(), STOP) ||// 中断当前线程(DCL)(Thread.interrupted() && runStateAtLeast(ctl.get(), STOP))) && !wt.isInterrupted())wt.interrupt();try {// 前置钩子beforeExecute(wt, task);Throwable thrown = null;try {// 执行任务task.run();} catch (RuntimeException x) {thrown = x; throw x;} catch (Error x) {thrown = x; throw x;} catch (Throwable x) {thrown = x; throw new Error(x);} finally {// 后置钩子afterExecute(task, thrown);}} finally {task = null;// 当前工作执行完一个任务,就++w.completedTasks++;w.unlock();}}completedAbruptly = false;} finally {processWorkerExit(w, completedAbruptly);}
}
六、getTask工作线程排队拿任务
private Runnable getTask() {// 超时-falseboolean timedOut = false; // Did the last poll() time out?for (;;) {// 阿巴int c = ctl.get();int rs = runStateOf(c);// 线程池状态判断// 如果线程池状态为SHUTDOWN && 工作队列为空// 如果线程池状态为STOPif (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {// 对工作线程个数--decrementWorkerCount();return null;}// 对数量的判断。int wc = workerCountOf(c);// 判断核心线程是否允许超时?// 工作线程个数是否大于核心线程数boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;// 判断工作线程是否超过了最大线程数 && 工作队列为nullif ((wc > maximumPoolSize || (timed && timedOut)) && (wc > 1 || workQueue.isEmpty())) {// 工作线程数有问题,必须-1,干掉当前工作线程// 工作线程是否超过了核心线程,如果超时,就干掉当前线程// 对工作线程个数--if (compareAndDecrementWorkerCount(c))return null;continue;}try {// 如果是非核心,走poll,拉取工作队列任务,// 如果是核心线程,走take一直阻塞,拉取工作队列任务Runnable r = timed ?workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :// 当工作队列没有任务时,这时就会被Condition通过await阻塞线程// 当有任务添加到工作线程后,这是添加完任务后,就会用过Condition.signal唤醒阻塞的线程workQueue.take();if (r != null)return r;// 执行的poll方法,并且在指定时间没拿到任务,timedOut = true;} catch (InterruptedException retry) {timedOut = false;}}
}
七、processWorkerExit工作线程告辞~
private void processWorkerExit(Worker w, boolean completedAbruptly) {// 如果是不正常操作,需要先对工作线程数-- (如果正常情况,getTask就--了)if (completedAbruptly) decrementWorkerCount();final ReentrantLock mainLock = this.mainLock;mainLock.lock();try {// 将当前工作线程完整的任务个数赋值给整个线程池中的任务数completedTaskCount += w.completedTasks;// 干掉当前工作线程workers.remove(w);} finally {mainLock.unlock();}// 线程池是否可以中止,线程池状态是否发生变化。tryTerminate();int c = ctl.get();//如果当前线程池状态小于STOPif (runStateLessThan(c, STOP)) {// 判断线程池中的工作队列是否还有任务,并且工作线程是否还在。if (!completedAbruptly) {int min = allowCoreThreadTimeOut ? 0 : corePoolSize;if (min == 0 && ! workQueue.isEmpty())min = 1;if (workerCountOf(c) >= min)return; // replacement not needed}// 添加非核心空任务的线程处理工作队列中的任务addWorker(null, false);}
}
拒绝策略:线程池提供的拒绝策略,一般不适合你的业务场景时,你就自己定义即可。
- AbortPolicy:抛出异常!
- CallerRunsPolicy:让提交任务的线程处理这个任务!
- DiscardPolicy:啥也不做,任务没了!
- DiscardOldestPolicy:扔掉队列最前面的任务,尝试把当前任务添加进去!
任务处理流程:
主线程执行execute添加任务,线程池创建工作线程,执行任务,执行任务,再次拉取工作队列任务,直到工作队列没有任务,阻塞工作线程
工作线程阻塞在工作队列,主线程执行execute添加任务到工作队列,工作线程被唤醒,拿到工作队列中的任务执行,执行完毕,再次拉取工作队列任务,直到工作队列没有任务,阻塞工作线程
五、ConcurrentHashMap源码分析(一)
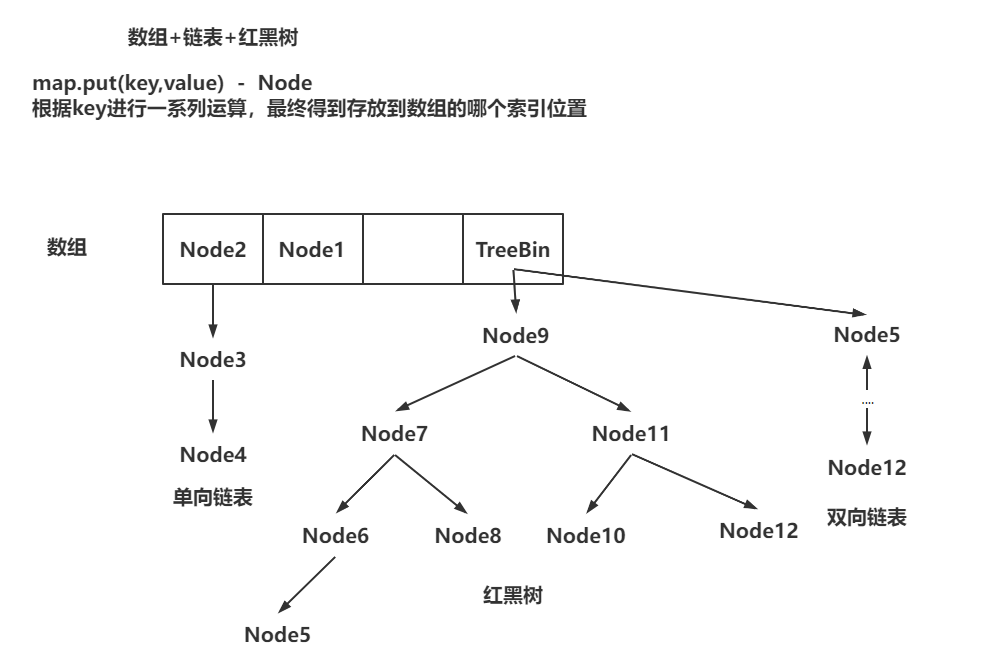
一、结构介绍
HashMap和ConcurrentHashMap的存储结构是一致的。
ConcurrentHashMap是线程安全的。
存储结构
关于put和putIfAbsent的区别
// put和putIfAbsent都是想ConcurrentHashMap中存储值。
// 如果出现key一致的,将新数据覆盖老数据,并且返回老数据
public V put(K key, V value) {return putVal(key, value, false);
}// 如果出现key一致的,什么都不做,返回老数据。 最只有key不存在时,才会正常的添加数据
public V putIfAbsent(K key, V value) {return putVal(key, value, true);
}
二、散列算法
散列算法是为了让hashCode的高16位参与到索引位置的计算中,从而尽可能的打散数据存放到数组上。从而减少Hash冲突
ConcurrentHashMap中,还会将hash值对HASH_BITS进行&运算,让hash值一定是一个正数。
// ConcurrentHashMap存储数据的核心方法
final V putVal(K key, V value, boolean onlyIfAbsent) {// key和value不能为null。 HashMap中是允许为null的。if (key == null || value == null) throw new NullPointerException();// 散列算法就是基于key进行hash运算,并且根据散列算法的结果,确定当前key-value存储到数组的哪个索引位置。int hash = spread(key.hashCode());
}// 散列算法
// 散列算法是为了让hashCode的高16位参与到索引位置的计算中,从而尽可能的打散数据存放到数组上。从而减少Hash冲突
// ConcurrentHashMap中,还会将hash值对HASH_BITS进行&运算,让hash值一定是一个正数。
// 因为ConcurrentHashMap中数组上的数据的hash值,如果为负数,有特殊含义
// static final int MOVED = -1; // 代表当前位置数据在扩容,并且数据已经迁移到了新数组
// static final int TREEBIN = -2; // 代表当前索引位置下,是一个红黑树。 转红黑树,TreeBin有参构造
// static final int RESERVED = -3; // 代表当前索引位置已经被占了,但是值还没放进去呢。 compute方法
static final int spread(int h) {return (h ^ (h >>> 16)) & HASH_BITS;;
}00011000 00000110 00111000 00001100 h
^
00000000 00000000 00011000 00000110 h >>> 1600011000 00000110 00111000 00001100
&
00000000 00000000 00000111 11111111 2048 - 1ConcurrentHashMap是如何根据hash值,计算存储的位置?
(数组长度 - 1) & (h ^ (h >>> 16))00011000 00000110 00110000 00001100 key1-hash
00011000 00000110 00111000 00001100 key2-hash
&
00000000 00000000 00000111 11111111 2048 - 1三、初始化数组
final V putVal(K key, V value, boolean onlyIfAbsent) { // 死循环~~~~// tab是ConcurrentHashMap的数组for (Node<K,V>[] tab = table;;) {// 一堆变量Node<K,V> f; int n, i, fh;// 代表当前数组没有初始化。if (tab == null || (n = tab.length) == 0)// 初始化数组 (ConcurrentHashMap在new时,不会创建数组,在使用时,才会创建)tab = initTable();}return null;
}/*
sizeCtl是标识数组初始化和扩容的标识信息。
= -1:代表正在初始化!
< -1:代表正在扩容!
= 0:代表没有初始化!
> 0:①当前数组没有初始化,这个值,就代表初始化的长度! ②如果已经初始化了,就代表下次扩容的阈值!
*/
private transient volatile int sizeCtl;// 初始化数组操作
private final Node<K,V>[] initTable() {// 声明tab:临时存数组。 sc:临时存sizeCtlNode<K,V>[] tab; int sc;// 判断数组还没初始化呢吧?while ((tab = table) == null || tab.length == 0) {// sc赋值,并判断是否小于0if ((sc = sizeCtl) < 0)// 线程先让出CPU的执行权。Thread.yield(); // 如果sc大于等于0,没人在执行初始化操作。// 以CAS的方式,将sizeCtl,改为-1,代表当前线程正在执行初始化逻辑else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {try {// 判断数组还没初始化呢吧? DCLif ((tab = table) == null || tab.length == 0) {// 拿到数组的初始化长度int n = (sc > 0) ? sc : DEFAULT_CAPACITY;// 创建数组Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];// 依次给局部变量和成员变量赋值。table = tab = nt;// 计算下次扩容的阈值sc = n - (n >>> 2);}} finally {// 将扩容阈值赋值给sizeCtlsizeCtl = sc;}break;}}return tab;
}
四、添加数据-数组
数据添加到数组上(没有hash冲突)
final V putVal(K key, V value, boolean onlyIfAbsent) {int binCount = 0;for (Node<K,V>[] tab = table;;) {// n: 数组长度。 i:索引位置。 f:i位置的数据。 fh:是f的hash值Node<K,V> f; int n, i, fh;// tabAt(数组,索引位置) = 拿到数组指定索引位置的数据else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {// 当前索引位置数据为null。// 以CAS的方式,将数据放到tab的i位置上,将hash,key,value封装成了一个Node对象if (casTabAt(tab, i, null,new Node<K,V>(hash, key, value, null)))break; }// 说明当前位置数据已经被迁移到了新数组。else if ((fh = f.hash) == MOVED)// 帮你扩容,快点扩容完,我好把数据放到新数组~~~tab = helpTransfer(tab, f);}return null;
}
五、添加数据-链表
final V putVal(K key, V value, boolean onlyIfAbsent) {// 拿到binCountint binCount = 0;for (Node<K,V>[] tab = table;;) {// n: 数组长度。 i:索引位置。 f:i位置的数据。 fh:是f的hash值Node<K,V> f; int n, i, fh;// 到这,说明出现了hash冲突,i位置有数据,尝试往i位置下挂数据else {// 声明oldVal,返回结果V oldVal = null;// 以桶位置数据作为锁,锁住当前桶,锁粒度更细。synchronized (f) {// 再判断一次,数据没有变化,正常挂链表。if (tabAt(tab, i) == f) {// 链表添加操作if (fh >= 0) {// binCount赋值1,记录链表中Node的长度binCount = 1;// e:暂时指向数组位置数据for (Node<K,V> e = f;; ++binCount) {K ek;// 拿到当前数据的hash值,和数组位置数据的hash值比较,if (e.hash == hash &&// 如果相等 , 判断 == 或者 equals 返回true((ek = e.key) == key || (ek != null && key.equals(ek)))) {// 尝试覆盖原数据,先获取老数据oldVal = e.val;// 如果是put方法,进去覆盖值// 如果是putIfAbsent,进去不if逻辑if (!onlyIfAbsent)// 覆盖值e.val = value;break;}// pred暂存eNode<K,V> pred = e;// e指向下一个节点,并且如果e == null,说明下面没节点了if ((e = e.next) == null) {// 将当前的值封装为Node对象,并挂在最后一个节点的后面pred.next = new Node<K,V>(hash, key, value, null);break;}}}// 红黑树添加套路else if (f instanceof TreeBin) {// 省略部分代码}}}// 如果binCount != 0if (binCount != 0) {// 如果binCount >= 8if (binCount >= TREEIFY_THRESHOLD)// 判断是扩容还是转红黑树treeifyBin(tab, i);// 判断是否需要返回if (oldVal != null)return oldVal;break;}}}return null;
}
六、触发扩容
// 判断是否需要转红黑树或者是扩容 tab:数组! index:索引位置!
private final void treeifyBin(Node<K,V>[] tab, int index) {// n:数组长度, sc:sizeCtlNode<K,V> b; int n, sc;// 判断tab不为nullif (tab != null) {// 如果数组长度 小于 64,不转红黑树,先扩容(更希望数据存放在数组上,O1)// 只有数组长度大于等于64并且链表长度达到8,才转为红黑树if ((n = tab.length) < MIN_TREEIFY_CAPACITY)// 扩容前的一些准备和业务判断tryPresize(n << 1);// 转红黑树操作// 将单向链表转换为TreeNode对象(双向链表),再通过TreeBin方法转为红黑树。// TreeBin中保留着双向链表以及红黑树!else if ((b = tabAt(tab, index)) != null && b.hash >= 0) {// 省略部分代码~~}}
}
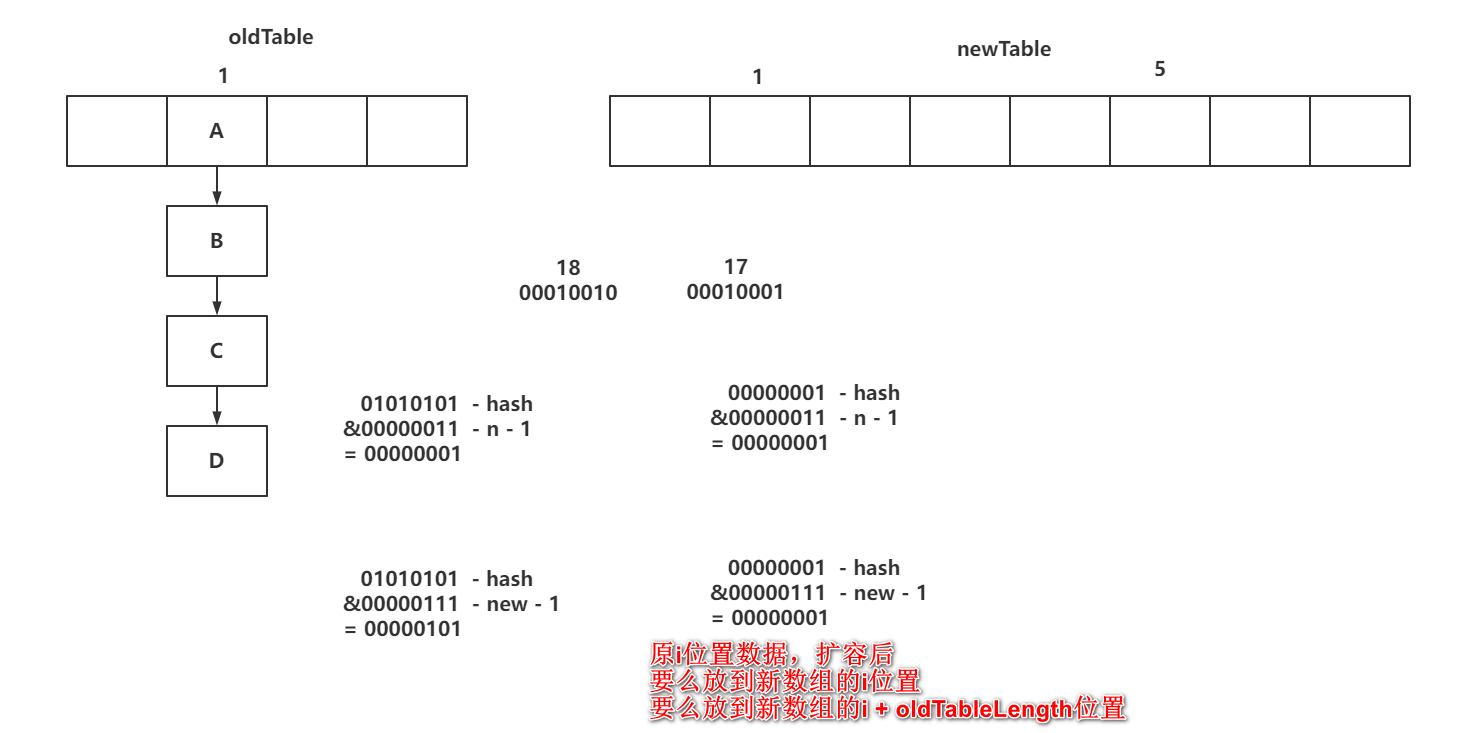
七、HashMap的扩容
六、ConcurrentHashMap扩容
三种触发方式
达到了扩容的阈值
一、tryPreSize方法-初始化数组
// 扩容前操作,putAll,链表转红黑树 插入map的长度(putAll)
private final void tryPresize(int size) {// 这个判断是给putAll留的,要计算当前数组的长度(初始化)// 如果size大于最大长度 / 2,直接将数组长度设置为最大值。// tableSizeFor,将长度设置的2的n次幂// c是初始化数组长度int c = (size >= (MAXIMUM_CAPACITY >>> 1)) ? MAXIMUM_CAPACITY : tableSizeFor(size + (size >>> 1) + 1);// sc是给sizeCtl赋值// -1:正在初始化数组,小于-1:正在扩容,0:代表还没初始化数组,大于0:可能初始化了(代表阈值),也可能没初始化(初始化的长度)int sc;while ((sc = sizeCtl) >= 0) {// 代表没有正在执行初始化,也没有正在执行扩容。、// tab:数组,n:数组长度Node<K,V>[] tab = table; int n;// 判断数组是不是还没初始化呢if (tab == null || (n = tab.length) == 0) {// 初始化数组,和initTable一样的东西// 在sc和c之间选择最大值,作为数组的初始化长度n = (sc > c) ? sc : c;// 要初始化,就直接把sizeCtl设置为-1,代表我要初始化数组if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {try {// DCL!if (table == tab) {// 创建数组Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];// 初始化数组赋值给成员变量table = nt;// sc先设置成阈值sc = n - (n >>> 2);}} finally {// 将sc赋值给sizeCtlsizeCtl = sc;}}}// 要么是c没有超过阈值,要么是超过最大值,啥事不做~~~else if (c <= sc || n >= MAXIMUM_CAPACITY)break;// 省略部分代码。}
}
二、tryPreSize方法-扩容标识戳
// 扩容前操作
private final void tryPresize(int size) {while ((sc = sizeCtl) >= 0) {// 省略部分初始化代码Node<K,V>[] tab = table; int n;if (tab == null || (n = tab.length) == 0) {// 扩容前操作!else if (tab == table) {// 计算扩容标识戳(基于老数组长度计算扩容标识戳,因为ConcurrentHashMap允许多线程迁移数据。)int rs = resizeStamp(n);// 这里是一个BUG,当前sc在while循环中,除了初始化没有额外赋值的前提下,这个sc < 0 永远进不来。// 虽然是BUG,但是清楚sc < 0 代表正在扩容if (sc < 0) {Node<K,V>[] nt; 31 ~ 16 15 ~ 0// 这里是第二个BUGif ((sc >>> RESIZE_STAMP_SHIFT) != rs || // 判断协助扩容线程的标识戳是否一致sc == rs << RESIZE_STAMP_SHIFT + 1 || // BUG之一,在判断扩容操作是否已经到了最后的检查阶段sc == rs << RESIZE_STAMP_SHIFT + MAX_RESIZERS || // BUG之一,判断扩容线程是否已经达到最大值(nt = nextTable) == null || // 新数组为null,说明也已经扩容完毕,扩容完毕后,才会把nextTable置位nulltransferIndex <= 0) // transferIndex为线程领取任务的最大节点,如果为0,代表所有老数据迁移任务都没领干净了break;if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))transfer(tab, nt);}// 还没有执行扩容,当前线程可能是第一个进来执行扩容的线程// 基于CAS的方式,将sizeCtl从原值改为 扩容标识戳左移16位// 10000000 00011010 00000000 00000010 一定是< -1的负数,可以代表当前ConcurrentHashMap正在扩容// 为什么是低位+2,代表1个线程扩容。 低位为5,就代表4个线程正在并发扩容// 扩容分为2部:创建新数组,迁移数据。// 当最后一个线程迁移完毕数据后,对低位-1.最终结果低位还是1,需要对整个老数组再次检查,数据是否迁移干净else if (U.compareAndSwapInt(this, SIZECTL, sc,(rs << RESIZE_STAMP_SHIFT) + 2))// 开始扩容操作,传入老数组~~transfer(tab, null);}}
}static final int resizeStamp(int n) {// 32~64// 00000000 00000000 00000000 00011010// 计算n在二进制表示时,前面有多少个0// 00000000 00000000 10000000 00000000// 00000000 00000000 10000000 00011010// 前面的操作是基于数组长度等到一个标识,方便其他线程参与扩容// 后面的值是为了保证当前扩容戳左移16位之后,一定是一个负数return Integer.numberOfLeadingZeros(n) | (1 << (RESIZE_STAMP_BITS - 1));
}三、transfer方法-构建新数组
transfer方法:
- 计算步长
- 初始化新数组
- 线程领取迁移数据任务
- 判断迁移是否完成,并判断当前线程是否是最后一个完成的
- 查看当前位置数据是否为null
- 查看当前位置数据是否为fwd
- 链表迁移数据-lastRun机制
- 红黑树迁移-迁移完数据长度小于等于6,转回链表
// 扩容操作,以第一个进来执行扩容的线程为例。
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {// 创建新数组流程!// n:老数组长度32, stride:扩容的步长16int n = tab.length, stride;// NCPU:4// 00000000 00000000 00000000 00000000// 00000000 00000000 00000100 00000000 - 1024 512 256 128 / 4 = 32// 如果每个线程迁移的长度基于CPU计算,大于16,就采用计算的值,如果小于16,就用16// 每个线程每次最小迁移16长度数据// stride = 1 < 16// 这个操作就是为了充分发挥CPU性能,因为迁移数据是CPU密集型操作,尽量让并发扩容线程数量不要太大,从而造成CPU的性能都消耗在了切换上,造成扩容效率降低// 如果要做优化的,推荐将扩容线程数设置为和CPU内核数+1一致。if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE) stride = MIN_TRANSFER_STRIDE; // 如果新数组没有初始化if (nextTab == null) { try {// 初始化数组Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];// 新数组赋值给nextTabnextTab = nt;} catch (Throwable ex) { // 要么OOM,要么数组长度达到最大值。sizeCtl = Integer.MAX_VALUE;return;}// 将nextTable成员变量赋值nextTable = nextTab;// transferIndex设置为老数组长度transferIndex = n;}}// n:老数组长度
// stride:步长
// nextTale,nextTab:新数组
// transferIndex:线程领取任务时的核心属性
四、transfer方法-迁移数据
第一步,线程领取迁移数据的任务
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {// 省略部分代码// n:老数组长度 32// stride:步长 16// nextTale,nextTab:新数组// nextn:新数组长度 64 // transferIndex:线程领取任务时的核心属性 32// 先看领取任务的过程!!!// 声明fwd节点,在老数组迁移数据完成后,将fwd赋值上去ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);// 领任务的核心标识boolean advance = true;// 扩容结束了咩?boolean finishing = false;// 扩容的for循环for (int i = 0, bound = 0;;) {Node<K,V> f; int fh;// 领取任务的while循环while (advance) {int nextIndex, nextBound;// 第一个判断是为了迁移下一个索引数据(暂时不管)if (--i >= bound || finishing)advance = false;// 说明没有任务可以领取了(暂时不管)else if ((nextIndex = transferIndex) <= 0) {i = -1;advance = false;}// transferIndex:16// stride:16,nextIndex:32,nextBound:16// bound:16,i:31// 开始领取任务,如果CAS成功,代表当前线程领取了32~16这个范围数据的迁移else if (U.compareAndSwapInt(this, TRANSFERINDEX, nextIndex,nextBound = (nextIndex > stride ?nextIndex - stride : 0))) {bound = nextBound;i = nextIndex - 1;advance = false;}}
第二步:判断是否结束,以及线程退出扩容,并且为空时,设置fwd,并且hash为moved直接移动到下个位置
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {// 省略部分代码// n:老数组长度 32// stride:步长 16// nextTale,nextTab:新数组// nextn:新数组长度 64 // transferIndex:线程领取任务时的核心属性 32// 先看领取任务的过程!!!// 声明fwd节点,在老数组迁移数据完成后,将fwd赋值上去ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);// 领任务的核心标识boolean advance = true;// 扩容结束了咩?boolean finishing = false;// 扩容的for循环for (int i = 0, bound = 0;;) {Node<K,V> f; int fh;// 领取任务的while循环while (advance) {int nextIndex, nextBound;// 第一个判断是为了迁移下一个索引数据(暂时不管)if (--i >= bound || finishing)advance = false;// 说明没有任务可以领取了(暂时不管)else if ((nextIndex = transferIndex) <= 0) {i = -1;advance = false;}// transferIndex:16// stride:16,nextIndex:32,nextBound:16// bound:16,i:31// 开始领取任务,如果CAS成功,代表当前线程领取了32~16这个范围数据的迁移else if (U.compareAndSwapInt(this, TRANSFERINDEX, nextIndex,nextBound = (nextIndex > stride ?nextIndex - stride : 0))) {bound = nextBound;i = nextIndex - 1;advance = false;}}// 迁移最后一段的线程干完活了,或者其他线程没有任务可以领取了。if (i < 0) {int sc;// 判断结束了没,第一次肯定进不来if (finishing) {// 结束扩容,将nextTabl设置为nullnextTable = null;// 将迁移完数据的新数组,指向指向的老数组table = nextTab;// 将sizeCtl复制为下次扩容的阈值sizeCtl = (n << 1) - (n >>> 1);// 结束return;}// 到这,说明当前线程没有任务可以领取了// 基于CAS的方式,将低位-1,代表当前线程退出扩容操作(如果是最后一个,还有一个额外的活)if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {// 判断我是否是最后一个完成迁移数据的线程,如果不是,直接return结束if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)return;// 如果到这,说明我是最后一个结束迁移数据的线程。// finishing结束表示和advance领取任务的标识全部设置为truefinishing = advance = true;// i设置为老数组长度,从头到位再检查一次整个老数组。i = n; }额外分析:当前线程完成领取的迁移任务后,再次进入while循环,查看是否有任务可以领取如果transferIndex变为0了,代表我没有任务可以领取,将i设置为-1没有任务可以领取,退出当前扩容操作:1、基于CAS将sizeCtl - 1代表我退出扩容操作2、-1成功后,还要判断,我是不是最后一个退出扩容的线程(sc - 2值是否是 扩容标识戳 << 16) 如果不是,直接return结束3、如果是最后一个结束迁移的线程,将i复制为老数组长度,重新从末位到头部再次检查一圈}else if ((f = tabAt(tab, i)) == null)// 如果发现迁移为主的数据为null,设置放置一个fwd,代表当前位置迁移完成advance = casTabAt(tab, i, null, fwd);else if ((fh = f.hash) == MOVED)// 是在检查时的逻辑advance = true;
五、transfer方法-lastRun机制
就是迁移链表到新数组时的操作
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {// 省略部分代码// n:老数组长度 32// stride:步长 16// nextTale,nextTab:新数组// nextn:新数组长度 64 // transferIndex:线程领取任务时的核心属性 32// 先看领取任务的过程!!!// 声明fwd节点,在老数组迁移数据完成后,将fwd赋值上去ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);// 领任务的核心标识boolean advance = true;// 扩容结束了咩?boolean finishing = false;// 扩容的for循环for (int i = 0, bound = 0;;) {Node<K,V> f; int fh;// 领取任务的while循环while (advance) {int nextIndex, nextBound;// 第一个判断是为了迁移下一个索引数据(暂时不管)if (--i >= bound || finishing)advance = false;// 说明没有任务可以领取了(暂时不管)else if ((nextIndex = transferIndex) <= 0) {i = -1;advance = false;}// transferIndex:16// stride:16,nextIndex:32,nextBound:16// bound:16,i:31// 开始领取任务,如果CAS成功,代表当前线程领取了32~16这个范围数据的迁移else if (U.compareAndSwapInt(this, TRANSFERINDEX, nextIndex,nextBound = (nextIndex > stride ?nextIndex - stride : 0))) {bound = nextBound;i = nextIndex - 1;advance = false;}}// 迁移最后一段的线程干完活了,或者其他线程没有任务可以领取了。if (i < 0) {int sc;// 判断结束了没,第一次肯定进不来if (finishing) {// 结束扩容,将nextTabl设置为nullnextTable = null;// 将迁移完数据的新数组,指向指向的老数组table = nextTab;// 将sizeCtl复制为下次扩容的阈值sizeCtl = (n << 1) - (n >>> 1);// 结束return;}// 到这,说明当前线程没有任务可以领取了// 基于CAS的方式,将低位-1,代表当前线程退出扩容操作(如果是最后一个,还有一个额外的活)if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {// 判断我是否是最后一个完成迁移数据的线程,如果不是,直接return结束if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)return;// 如果到这,说明我是最后一个结束迁移数据的线程。// finishing结束表示和advance领取任务的标识全部设置为truefinishing = advance = true;// i设置为老数组长度,从头到位再检查一次整个老数组。i = n; }额外分析:当前线程完成领取的迁移任务后,再次进入while循环,查看是否有任务可以领取如果transferIndex变为0了,代表我没有任务可以领取,将i设置为-1没有任务可以领取,退出当前扩容操作:1、基于CAS将sizeCtl - 1代表我退出扩容操作2、-1成功后,还要判断,我是不是最后一个退出扩容的线程(sc - 2值是否是 扩容标识戳 << 16) 如果不是,直接return结束3、如果是最后一个结束迁移的线程,将i复制为老数组长度,重新从末位到头部再次检查一圈}else if ((f = tabAt(tab, i)) == null)// 如果发现迁移为主的数据为null,设置放置一个fwd,代表当前位置迁移完成advance = casTabAt(tab, i, null, fwd);else if ((fh = f.hash) == MOVED)// 是在检查时的逻辑advance = true; else {// 迁移数据,加锁!synchronized (f) {// 拿到当前位置数据if (tabAt(tab, i) == f) {Node<K,V> ln, hn;// 说明当前节点状态正常,不是迁移,不是红黑树,不是预留if (fh >= 0) {// fh与老数组进行&运算,得到runBit// 00001111// 00010000// 这个计算的结果,会决定当前数据在迁移时,是放到新数组的i位置还有新数组的 i + n位置int runBit = fh & n;Node<K,V> lastRun = f;// lastRun机制// 提前循环一次链表,将节点赋值到对应的高低位Node./// 如果链表最后面的值没有变化,那就不动指针,直接复制。for (Node<K,V> p = f.next; p != null; p = p.next) {int b = p.hash & n;if (b != runBit) {runBit = b;lastRun = p;}}if (runBit == 0) {ln = lastRun;hn = null;}else {hn = lastRun;ln = null;}// 再次循环时,就循环到lastRun位置,不再继续往下循环// 这样可以不用每个节点都new,避免GC和OOM问题。for (Node<K,V> p = f; p != lastRun; p = p.next) {int ph = p.hash; K pk = p.key; V pv = p.val;if ((ph & n) == 0)ln = new Node<K,V>(ph, pk, pv, ln);elsehn = new Node<K,V>(ph, pk, pv, hn);}// 放低位setTabAt(nextTab, i, ln);// 放高位setTabAt(nextTab, i + n, hn);// 将当前迁移完的桶位置,设置上fwd,代表数据迁移完毕setTabAt(tab, i, fwd);// advance,代表执行下次循环,i--。advance = true;}// 省略红黑树迁移!}}}}
}六、helpTransfer方法-协助扩容
// 协助扩容
final Node<K,V>[] helpTransfer(Node<K,V>[] tab, Node<K,V> f) {Node<K,V>[] nextTab; int sc;// 老数组不为null,当前节点是fwd,新数组不为nullif (tab != null && (f instanceof ForwardingNode) &&(nextTab = ((ForwardingNode<K,V>)f).nextTable) != null) {// 创建自己的扩容标识戳int rs = resizeStamp(tab.length);// 判断之前赋值的内容是否有变化,并且sizeCtl是否小于0while (nextTab == nextTable && table == tab &&(sc = sizeCtl) < 0) {if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||sc == rs + MAX_RESIZERS || transferIndex <= 0)// 有一个满足,就说明不需要协助扩容了break;// CAS,将sizeCtl + 1,代表来协助扩容了if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1)) {transfer(tab, nextTab);break;}}return nextTab;}return table;
}
七、JUC并发工具
跟着我掌握这些内容,首先你要对AQS有一定了解。(ReentrantLock,ReentrantReadWriteLock)
一、CountDownLatch应用
CountDownLatch本身就好像一个计数器,可以让一个线程或多个线程等待其他线程完成后再执行。
应用方式巨简单
public static void main(String[] args) throws InterruptedException, BrokenBarrierException {// 声明CountDownLatch,有参构造传入的值,会赋值给state,CountDownLatch基于AQS实现// 3 - 1 = 2 - 1 = 1 - 1CountDownLatch countDownLatch = new CountDownLatch(3);new Thread(() -> {System.out.println("111");countDownLatch.countDown();}).start();new Thread(() -> {System.out.println("222");countDownLatch.countDown();}).start();new Thread(() -> {try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}System.out.println("333");countDownLatch.countDown();}).start();// 主线会阻塞在这个位置,直到CountDownLatch的state变为0countDownLatch.await();System.out.println("main");
}
二、CountDownLatch核心源码分析
2.1 从构造方法查看
// CountDownLatch 的有参构造
public CountDownLatch(int count) {// 健壮性校验if (count < 0) throw new IllegalArgumentException("count < 0");// 构建Sync给AQS的state赋值this.sync = new Sync(count);
}
2.2 countDown方法
// countDown方法,本质就是调用了AQS的释放共享锁操作
// 这里的功能都是AQS提供的,只有tryReleaseShared需要实现的类自己去编写业务
public final boolean releaseShared(int arg) {if (tryReleaseShared(arg)) {// 唤醒在AQS队列中排队的线程。doReleaseShared();return true;}return false;
}// countDownLatch实现的业务
protected boolean tryReleaseShared(int releases) {for (;;) {int c = getState();if (c == 0)return false;// state - 1int nextc = c-1;// 用CAS赋值if (compareAndSetState(c, nextc))return nextc == 0;}
}
// 如果CountDownLatch中的state已经为0了,那么再次执行countDown跟没执行一样。
// 而且只要state变为0,await就不会阻塞线程。
2.3 await方法
// await方法
public void await() throws InterruptedException {// 调用了AQS提供的获取共享锁并且允许中断的方法sync.acquireSharedInterruptibly(1);
}// AQS提欧的获取共享锁并且允许中断的方法
public final void acquireSharedInterruptibly(int arg)throws InterruptedException {if (Thread.interrupted())throw new InterruptedException();// countDownLatch操作if (tryAcquireShared(arg) < 0)// 如果返回的是-1,代表state肯定大于0doAcquireSharedInterruptibly(arg);
}// CountDownLatch实现的tryAcquireShared
protected int tryAcquireShared(int acquires) {// state为0,返回1,。否则返回-1return (getState() == 0) ? 1 : -1;
}// 让当前线程进到AQS队列,排队去
private void doAcquireSharedInterruptibly(int arg) throws InterruptedException {// 将当前线程封装为Node,并且添加到AQS的队列中final Node node = addWaiter(Node.SHARED);boolean failed = true;try {for (;;) {final Node p = node.predecessor();if (p == head) {// 再次走上面的tryAcquireShared,如果返回的是的1,代表state为0int r = tryAcquireShared(arg);if (r >= 0) {// 会将当前线程和后面所有排队的线程都唤醒。setHeadAndPropagate(node, r);p.next = null; // help GCfailed = false;return;}}if (shouldParkAfterFailedAcquire(p, node) &&parkAndCheckInterrupt())throw new InterruptedException();}} finally {if (failed)cancelAcquire(node);}
}三、Semaphore应用
也是常用的JUC并发工具,一般用于流控。比如有一个公共资源,多线程都可以访问时,可以用信号量做限制。
连接池,内部的链接对象有限,每当有一个线程获取连接对象时,对信号量-1,当这个线程归还资源时对信号量+1。
如果线程拿资源时,发现Semaphore内部的资源个数为0,就会被阻塞。
Hystrix的隔离策略 - 线程池,信号量
使用方式巨简单。
public static void main(String[] args) throws InterruptedException, BrokenBarrierException {// 声明信号量Semaphore semaphore = new Semaphore(1);// 能否去拿资源semaphore.acquire();// 拿资源处理业务System.out.println("main");// 归还资源semaphore.release();
}
四、Semaphore核心源码分析
4.1 有参构造
// Semaphore有公平和非公平两种竞争资源的方式。
public Semaphore(int permits, boolean fair) {sync = fair ? new FairSync(permits) : new NonfairSync(permits);
}// 设置资源个数,State其实就是信号量的资源个数
Sync(int permits) {setState(permits);
}
4.2 acquire
// 阿巴阿巴~
public final void acquireSharedInterruptibly(int arg)throws InterruptedException {if (Thread.interrupted())throw new InterruptedException();if (tryAcquireShared(arg) < 0)doAcquireSharedInterruptibly(arg);
}// 公平
protected int tryAcquireShared(int acquires) {for (;;) {// 公平方式,先好看队列中有木有排队的,有排队的返回-1,执行doAcquireSharedInterruptibly去排队if (hasQueuedPredecessors())return -1;// 那stateint available = getState();// remaining = 资源数 - 1int remaining = available - acquires;// 如果资源不够,直接返回-1if (remaining < 0 ||// 如果资源够,执行CAS,修改statecompareAndSetState(available, remaining))return remaining;}
}// 非公平
final int nonfairTryAcquireShared(int acquires) {for (;;) {int available = getState();int remaining = available - acquires;if (remaining < 0 ||compareAndSetState(available, remaining))return remaining;}
}
4.3 release
// 两个一起 阿巴阿巴
public void release() {sync.releaseShared(1);
}public final boolean releaseShared(int arg) {if (tryReleaseShared(arg)) {// 唤醒在AQS中排队的Node,去竞争资源doReleaseShared();return true;}return false;
}// 信号量实现的归还资源
protected final boolean tryReleaseShared(int releases) {for (;;) {// 拿stateint current = getState();// state + 1int next = current + releases;// 资源最大值,再+1,变为负数if (next < current)throw new Error("Maximum permit count exceeded");// CAS 改一手if (compareAndSetState(current, next))return true;}
}
4.4 分析AQS中PROPAGATE类型节点(唯一的难点)
JDK1.5中,使用信号量时,可能会造成在有资源的情况下,后继节点无法被唤醒。
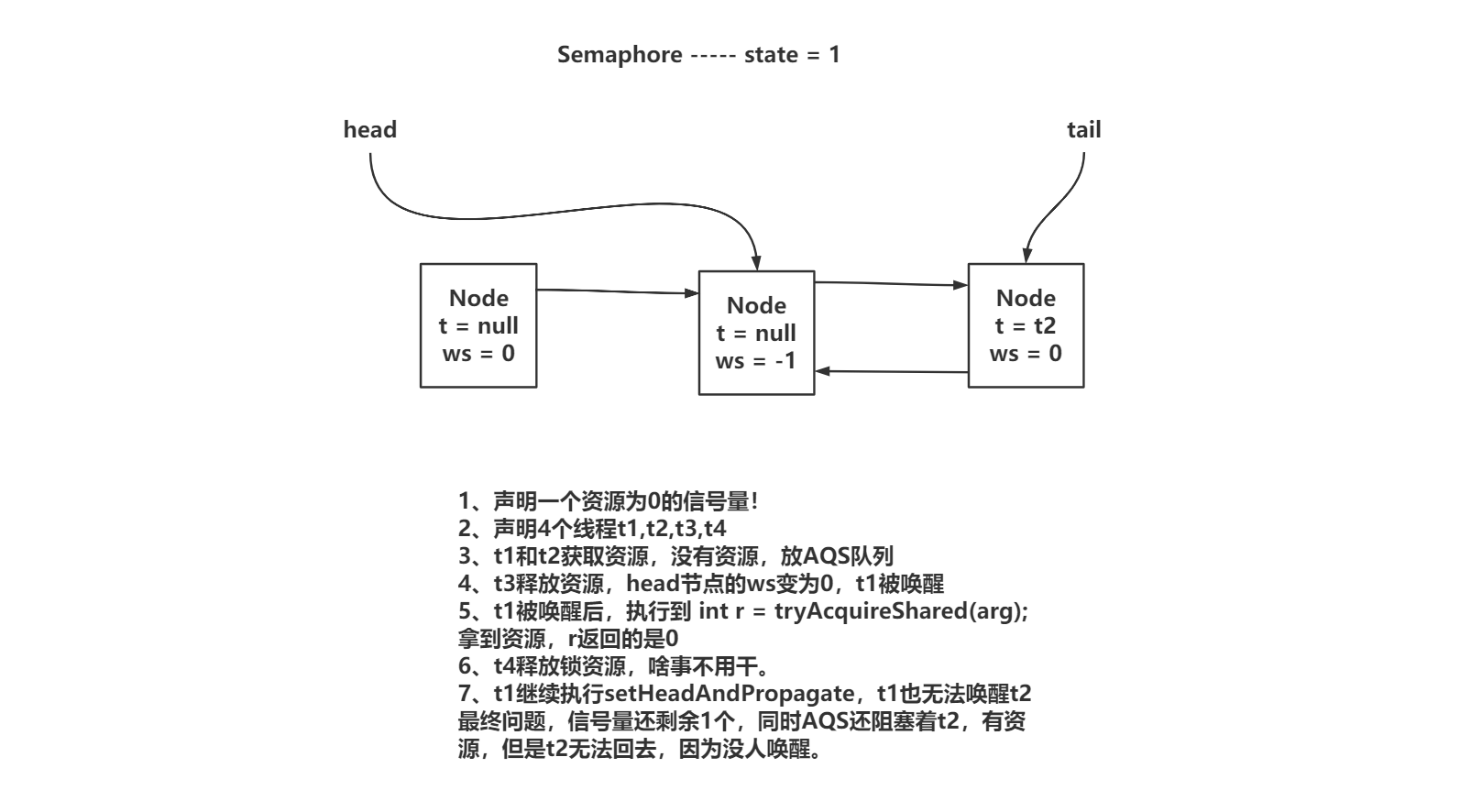
在JDK1.8中,问题被修复,修复方式就是追加了PROPAGATE节点状态来解决。
共享锁在释放资源后,如果头节点为0,无法确认真的没有后继节点。如果头节点为0,需要将头节点的状态修改为-3,当最新拿到锁资源的线程,查看是否有后继节点并且为共享锁,就唤醒排队的线程
五、CyclicBarrier应用
一般称为栅栏,和CountDownLatch很像。
CountDownLatch在操作时,只能使用一次,也就是state变为0之后,就无法继续玩了。
CyclicBarrier是可以复用的,他的计数器可以归位,然后再处理。而且可以在计数过程中出现问题后,重置当前CyclicBarrier,再次重新操作!
应用一波
public static void main(String[] args) throws InterruptedException, BrokenBarrierException {// 声明栅栏CyclicBarrier barrier = new CyclicBarrier(3,() -> {System.out.println("打手枪!");});new Thread(() -> {System.out.println("第一位选手到位");try {barrier.await();System.out.println("第一位往死里跑!");} catch (Exception e) {e.printStackTrace();}}).start();new Thread(() -> {System.out.println("第二位选手到位");try {barrier.await();System.out.println("第二位也往死里跑!");} catch (Exception e) {e.printStackTrace();}}).start();System.out.println("裁判已经到位");barrier.await();
}
六、CyclicBarrier核心源码分析
6.1 有参构造
CyclicBarrier没有直接使用AQS,而是使用ReentrantLock,简介的使用的AQS
// CyclicBarrier的有参
public CyclicBarrier(int parties, Runnable barrierAction) {、// 健壮性判断!if (parties <= 0) throw new IllegalArgumentException();// parties是final修饰的,需要在重置时,使用!this.parties = parties;// count是在执行await用来计数的。this.count = parties;// 当计数count为0时 ,先执行这个Runnnable!在唤醒被阻塞的线程this.barrierCommand = barrierAction;
}
6.2 await
线程执行await方法,会对count-1,再判断count是否为0
如果不为0,需要添加到AQS中的ConditionObject的Waiter队列中排队,并park当前线程
如果为0,证明线程到齐,需要执行nextGeneration,会先将Waiter队列中的Node全部转移到AQS的队列中,并且有后继节点的,ws设置为-1。没有后继节点设置为0。然后重置count和broker标记。等到unlock执行后,每个线程都会被唤醒。
// 选手到位!!!
private int dowait(boolean timed, long nanos) throws InterruptedException, BrokenBarrierException, TimeoutException {// 加锁?? 因为CyclicBarrier是基于ReentrantLock-Condition的await和singalAll方法实现的。// 相当于synchronized中使用wait和notify// 别忘了,只要挂起,会释放锁资源。final ReentrantLock lock = this.lock;lock.lock();try {// 里面就是boolean,默认falsefinal Generation g = generation;// 判断之前栅栏加入线程时,是否有超时、中断等问题,如果有,设置boolean为true,其他线程再进来,直接凉凉if (g.broken)throw new BrokenBarrierException();if (Thread.interrupted()) {breakBarrier();throw new InterruptedException();}// 对计数器count--int index = --count;// 如果--完,是0,代表突破栅栏,干活!if (index == 0) { // 默认falseboolean ranAction = false;try {// 如果你用的是2个参数的有参构造,说明你传入了任务,index == 0,先执行CyclicBarrier有参的任务final Runnable command = barrierCommand;if (command != null)command.run();// 设置为trueranAction = true;nextGeneration();return 0;} finally {if (!ranAction)breakBarrier();}}// --完之后,index不是0,代表还需要等待其他线程for (;;) {try {// 如果没设置超时时间。 await()if (!timed)trip.await();// 设置了超时时间。 await(1,SECOND)else if (nanos > 0L)nanos = trip.awaitNanos(nanos);} catch (InterruptedException ie) {if (g == generation && ! g.broken) {breakBarrier();throw ie;} else {Thread.currentThread().interrupt();}}if (g.broken)throw new BrokenBarrierException();if (g != generation)return index;if (timed && nanos <= 0L) {breakBarrier();throw new TimeoutException();}}} finally {lock.unlock();}
}// 挂起线程
public final void await() throws InterruptedException {// 允许中断if (Thread.interrupted())throw new InterruptedException();// 添加到队列(不是AQS队列,是AQS里的ConditionObject中的队列)Node node = addConditionWaiter();int savedState = fullyRelease(node);int interruptMode = 0;while (!isOnSyncQueue(node)) {// 挂起当前线程LockSupport.park(this);if ((interruptMode = checkInterruptWhileWaiting(node)) != 0)break;}
}// count到0,唤醒所有队列里的线程线程
private void nextGeneration() {// 这个方法就是将Waiter队列中的节点遍历都扔到AQS的队列中,真正唤醒的时机,是unlock方法trip.signalAll();// 重置计数器count = parties;// 重置异常判断generation = new Generation();
}
八、JUC阻塞队列
阻塞队列:
- 队列,先进先出的一个数据结构
- 阻塞,基于ReentrantLock实现的,并且线程的挂起也是通过Condition
从最常用也是最简单的ArrayBlockingQueue,LinkedBlockingQueue
一、ArrayBlockingQueue
ArrayBlockingQueue底层是采用数组实现的一个队列。因为底层是数据,一般被成为有界队列
其次阻塞方式,是基于ReentrantLock实现的。
常用的存取方法
1.1 ArrayBlockingQueue应用
// 存数据操作 add(E),offer(E),put(E),offer(E,time,unit)
// add(E):添加数据到队列,如果满了,扔异常。
// offer(E):添加数据到队列,如果满了,返回false
// put(E):添加数据到队列,如果满了,线程挂起
// offer(E,time,unit):添加数据到队列,如果满了,线程挂起一段时间
// 取数据操作 remove(),poll(),take(),poll(time,unit)
// remove():从队列拿数据,拿到返回,拿到null,甩异常
// poll():从队列拿数据,拿到返回,拿到null,也返回
// take():从队列拿数据,拿到返回,没数据,一直阻塞
// poll(time,unit):从队列拿数据,拿到返回,没数据,阻塞time时间
public static void main(String[] args) throws InterruptedException, BrokenBarrierException, IOException {// ArrayBlockingQueue,因为底层使用数组,必须要指定数组的长度,作为队列的长度ArrayBlockingQueue queue = new ArrayBlockingQueue(1);// 存数据操作 add(E),offer(E),put(E),offer(E,time,unit)// add(E):添加数据到队列,如果满了,扔异常。// offer(E):添加数据到队列,如果满了,返回false// put(E):添加数据到队列,如果满了,线程挂起// offer(E,time,unit):添加数据到队列,如果满了,线程挂起一段时间// 取数据操作 remove(),poll(),take(),poll(time,unit)// remove():从队列拿数据,拿到返回,拿到null,甩异常// poll():从队列拿数据,拿到返回,拿到null,也返回// take():从队列拿数据,拿到返回,没数据,一直阻塞// poll(time,unit):从队列拿数据,拿到返回,没数据,阻塞time时间}
1.2 存数据源码
offer,添加时,先判断队列满了没,满了就返回false
offer(time,unit),添加时,先判断队列满了没,满了先阻塞time时间,自动唤醒,还是满的,也返回false
put,添加时,先判断队列满了没,满了就阻塞,阻塞到被唤醒,或者被中断
// 存数据
public boolean offer(E e) {// 非空校验checkNotNull(e);// 互斥锁final ReentrantLock lock = this.lock;lock.lock();try {// 如果数组中的数据已经达到了数组的长度,没地儿了~,队列满了if (count == items.length)return false;else {// 还有位置enqueue(e);return true;}} finally {lock.unlock();}
}
// 存放数据到数组中
private void enqueue(E x) {// 拿到数组final Object[] items = this.items;// 数组放进去items[putIndex] = x;// 把put指针++, 指针是否已经到了最后一个位置,归位到0位置。if (++putIndex == items.length)// 归位到0位置。putIndex = 0;// 数据条数 + 1count++;// 唤醒在阻塞的取数据线程notEmpty.signal();
}// put方法
public void put(E e) throws InterruptedException {checkNotNull(e);final ReentrantLock lock = this.lock;lock.lockInterruptibly();try {while (count == items.length)notFull.await();enqueue(e);} finally {lock.unlock();}
}
// offer方法,可以阻塞一段时间
public boolean offer(E e, long timeout, TimeUnit unit) throws InterruptedException {checkNotNull(e);long nanos = unit.toNanos(timeout);final ReentrantLock lock = this.lock;lock.lockInterruptibly();try {while (count == items.length) {if (nanos <= 0)return false;nanos = notFull.awaitNanos(nanos);}enqueue(e);return true;} finally {lock.unlock();}
}offer,添加时,先判断队列满了没,满了就返回false
offer(time,unit),添加时,先判断队列满了没,满了先阻塞time时间,自动唤醒,还是满的,也返回false
put,添加时,先判断队列满了没,满了就阻塞,阻塞到被唤醒,或者被中断
1.3 取数据
// 阿巴阿巴~~取数据
public E poll() {final ReentrantLock lock = this.lock;lock.lock();try {// count == 0代表没数据, 就返回null,有数据走dequeuereturn (count == 0) ? null : dequeue();} finally {lock.unlock();}
}// 从数组中那数据
private E dequeue() {final Object[] items = this.items;// 取数据E x = (E) items[takeIndex];// 将取完的位置置位nullitems[takeIndex] = null;// take指针++,如果到头,归位0~~if (++takeIndex == items.length)takeIndex = 0;// 数据条数 - 1count--;// 唤醒队列满的时候,阻塞住的写线程notFull.signal();return x;
}public E take() throws InterruptedException {final ReentrantLock lock = this.lock;lock.lockInterruptibly();try {while (count == 0)notEmpty.await(); // 挂起线程,需要被唤醒return dequeue();} finally {lock.unlock();}
}public E poll(long timeout, TimeUnit unit) throws InterruptedException {long nanos = unit.toNanos(timeout);final ReentrantLock lock = this.lock;lock.lockInterruptibly();try {while (count == 0) {if (nanos <= 0)return null; nanos = notEmpty.awaitNanos(nanos); // 挂起线程,到时间自动唤醒、或者被手动唤醒}return dequeue();} finally {lock.unlock();}
}
二、LinkedBlockingQueue
底层基于链表实现的,会将每个元素封装为Node,Node有当前值,还有一个next指针,一般成为无界队列
LinkedBlockingQueue本质就是一个用Node封装的单向链表。
LinkedBlockingQueue内部提供了读锁和写锁,读写不互斥,而且记录数据条数的属性是Atomic原子类
核心属性
/*** 阻塞队列元素会被封装为Node*/
static class Node<E> {E item;Node<E> next;Node(E x) { item = x; }
}/** 指定队列的长度,如果不传值,默认为Integer.MAX */
private final int capacity;/** 记录数据条数 */
private final AtomicInteger count = new AtomicInteger();transient Node<E> head;private transient Node<E> last;/** 读锁 */
private final ReentrantLock takeLock = new ReentrantLock();
private final Condition notEmpty = takeLock.newCondition();/** 写锁 */
private final ReentrantLock putLock = new ReentrantLock();
private final Condition notFull = putLock.newCondition();
2.1 写操作
// 写操作~
public boolean offer(E e) {// 非空if (e == null) throw new NullPointerException();// 拿到count(记录当前数据条数)final AtomicInteger count = this.count;// 如果count达到了最大值if (count.get() == capacity)// 数据满了。return false;// 声明c int c = -1;// 将当前数据封装为NodeNode<E> node = new Node<E>(e);// 添加写锁~final ReentrantLock putLock = this.putLock;putLock.lock();try {// !!DCL!!// 再次拿到条数判断,如果还有空间,enqueue存数据if (count.get() < capacity) {// 数据放进来enqueue(node);// 拿到count,再自增c = count.getAndIncrement();// 添加完数据之后,长度依然小于最大长度,唤醒可能阻塞的写线程 // 读写不互斥,可能前面在执行时,队列是满的,但是读操作依然在进行if (c + 1 < capacity)notFull.signal();}} finally {putLock.unlock();}// c == 0,说明添加数据之前,队列是空的,唤醒可能阻塞的读线程if (c == 0)signalNotEmpty();// 返回count >= 0return c >= 0;
}// 插入数据到链表~~~
private void enqueue(Node<E> node) {last = last.next = node;
}public void put(E e) throws InterruptedException {if (e == null) throw new NullPointerException();int c = -1;Node<E> node = new Node<E>(e);final ReentrantLock putLock = this.putLock;final AtomicInteger count = this.count;putLock.lockInterruptibly();try {while (count.get() == capacity) {notFull.await();}enqueue(node);c = count.getAndIncrement();if (c + 1 < capacity)notFull.signal();} finally {putLock.unlock();}if (c == 0)signalNotEmpty();
}public boolean offer(E e, long timeout, TimeUnit unit)throws InterruptedException {if (e == null) throw new NullPointerException();long nanos = unit.toNanos(timeout);int c = -1;final ReentrantLock putLock = this.putLock;final AtomicInteger count = this.count;putLock.lockInterruptibly();try {while (count.get() == capacity) {if (nanos <= 0)return false;nanos = notFull.awaitNanos(nanos);}enqueue(new Node<E>(e));c = count.getAndIncrement();if (c + 1 < capacity)notFull.signal();} finally {putLock.unlock();}if (c == 0)signalNotEmpty();return true;
}
2.2 读操作
public E poll() {final AtomicInteger count = this.count;// 为0,没数据,拜拜~~if (count.get() == 0)return null;E x = null;int c = -1;// 读锁final ReentrantLock takeLock = this.takeLock;takeLock.lock();try {// 如果队列有数据 DCLif (count.get() > 0) {x = dequeue();// count --c = count.getAndDecrement();if (c > 1)// c > 1,说明还有数据,唤醒读线程notEmpty.signal();}} finally {takeLock.unlock();}if (c == capacity)// 到这说明还有位置呢,唤醒写线程signalNotFull();return x;
}private E dequeue() {Node<E> h = head;Node<E> first = h.next;h.next = h; // help GChead = first;E x = first.item;first.item = null;return x;
}
三、PriorityQueue
这个就是一个普通的队列,不是阻塞的。
因为DelayQueue和PriorityBlockingQueue都和PriorityQueue有关系,很类似。
先把PriorityQueue搞定,后续再看其他的优先级阻塞队列,效果更佳!
PriorityQueue才是真正而定无界队列。底层是数组实现,会扩容!
PriorityQueue实现优先级的方式,是基于二叉堆实现的
二叉堆:
- 二叉堆是一颗完整的二叉树
- 任意一个节点大于父节点 或者 小于父节点
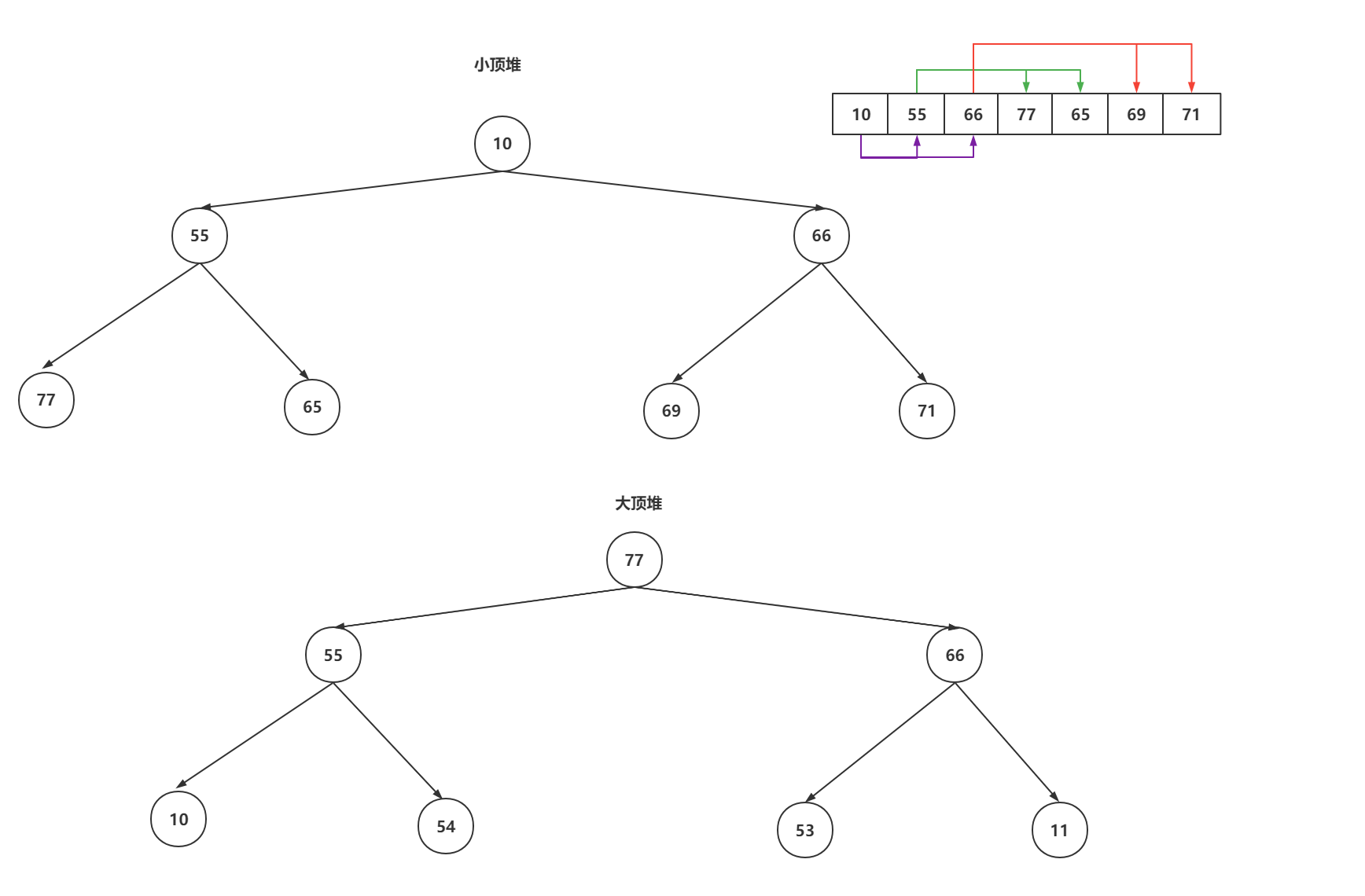
因为这个二叉堆是实现优先级队列的原理,那么队列或有添加和获取的操作,这种操作会影响二叉堆的结构,查看PriorityQueue队列的添加和获取操作如何保证结构
3.1 添加操作上移保证结构
// 优先级队列添加操作,确定如何保证小顶堆结构
public boolean offer(E e) {if (e == null)throw new NullPointerException();modCount++;// size是数组数据条数,大于等于数组长度后,需要扩容int i = size;if (i >= queue.length)// Double size if small; else grow by 50%grow(i + 1);// size + i,数据多一条size = i + 1;// 如果i == 0,说明添加的是第一个数据if (i == 0)queue[0] = e;else// 不是第一个数据,Up上移保证结构siftUp(i, e);return true;
}// 让当前节点和父节点比较,如果当前节点比较小,就上移~~~
private void siftUpUsingComparator(int k, E x) {while (k > 0) {int parent = (k - 1) >>> 1;Object e = queue[parent];if (comparator.compare(x, (E) e) >= 0)break;queue[k] = e;k = parent;}queue[k] = x;
}
3.2 取数据如何保证二叉堆结构
// 取堆顶数据
public E poll() {// 没有数据返回nullif (size == 0)return null;// 最后一个数据的索引int s = --size;// 需要全都的数据E result = (E) queue[0];// 取出最后一个数据E x = (E) queue[s];// 将最后一个数据置位nullqueue[s] = null;if (s != 0)// 下移保证安全siftDown(0, x);return result;
}// 堆顶数据下移,知道last数据可以存放的位置,然后替换即可
private void siftDownUsingComparator(int k, E x) {while (k < half) {int child = (k << 1) + 1;// 找到左子Object c = queue[child];int right = child + 1;if (right < size &&comparator.compare((E) c, (E) queue[right]) > 0)c = queue[child = right];if (comparator.compare(x, (E) c) <= 0)break;queue[k] = c;k = child;}queue[k] = x;
}
四、PriorityBlockingQueue
这个阻塞的优先级队列的实现跟PriorityQueue基本一模一样,只是PriorityBlockingQueue基于Lock锁实现的多线程操作安全并且线程可以挂起阻塞的操作
PriorityBlockingQueue底层基于数组,并且可以扩容,不会基于condition挂起线程,读会阻塞。
4.1 写操作
因为底层基于数组,并且可以扩容,所以写操作的put和poll(time,unit)的方式不会基于condition挂起线程。
并且是多线程基于CAS的方式争抢扩容的标识
// 所有添加都走着,没有await挂起的方式,
public boolean offer(E e) {if (e == null)throw new NullPointerException();final ReentrantLock lock = this.lock;lock.lock();int n, cap;Object[] array;// 扩容,允许多线程并发扩容。一会看~~~while ((n = size) >= (cap = (array = queue).length))tryGrow(array, cap);try {Comparator<? super E> cmp = comparator;if (cmp == null)//添加数据到二叉堆siftUpComparable(n, e, array);elsesiftUpUsingComparator(n, e, array, cmp);size = n + 1;// 唤醒读线程notEmpty.signal();} finally {lock.unlock();}return true;
}// 跟PriorityQueue一样的上移操作
private static <T> void siftUpComparable(int k, T x, Object[] array) {Comparable<? super T> key = (Comparable<? super T>) x;while (k > 0) {int parent = (k - 1) >>> 1;Object e = array[parent];if (key.compareTo((T) e) >= 0)break;array[k] = e;k = parent;}array[k] = key;
}// 尝试扩容
private void tryGrow(Object[] array, int oldCap) {// 允许多线程并发扩容的。(不是协助扩容),但是只有一个线程会成功,基于CAS的方式,避免并发问题lock.unlock();Object[] newArray = null;// 线程将allocationSpinLock从0改为1,得到了扩容的权利,可以创建新数组if (allocationSpinLock == 0 && UNSAFE.compareAndSwapInt(this, allocationSpinLockOffset,0, 1)) {try {// 计算新数组长度int newCap = oldCap + ((oldCap < 64) ? (oldCap + 2) : (oldCap >> 1));// 判断长度是否超过界限if (newCap - MAX_ARRAY_SIZE > 0) { int minCap = oldCap + 1;if (minCap < 0 || minCap > MAX_ARRAY_SIZE)throw new OutOfMemoryError();newCap = MAX_ARRAY_SIZE;}if (newCap > oldCap && queue == array)// 创建新数组newArray = new Object[newCap];} finally {allocationSpinLock = 0;}}if (newArray == null) // 如果newArray是null,说明当前线程没有执行扩容操作// 让出CPU时间片,尽量让扩容的线程先走完扩容操作Thread.yield();lock.lock();if (newArray != null && queue == array) {queue = newArray;// 扩容结束System.arraycopy(array, 0, newArray, 0, oldCap);}
}
4.2 读操作
PriorityBlockingQueue的读操作,是允许使用condition挂起的,因为二叉堆可能没有数据。没有数据,就挂起呗~~
public E poll() {// 基于lock锁保证安全,final ReentrantLock lock = this.lock;lock.lock();try {return dequeue();} finally {lock.unlock();}
}private E dequeue() {int n = size - 1;if (n < 0)return null;else {Object[] array = queue;// 拿到堆顶数据E result = (E) array[0];E x = (E) array[n];array[n] = null;Comparator<? super E> cmp = comparator;if (cmp == null)// 保证结构,下移~~siftDownComparable(0, x, array, n);elsesiftDownUsingComparator(0, x, array, n, cmp);size = n;return result;}
}
public E take() throws InterruptedException {final ReentrantLock lock = this.lock;lock.lockInterruptibly();E result;try {while ( (result = dequeue()) == null)notEmpty.await();} finally {lock.unlock();}return result;
}public E poll(long timeout, TimeUnit unit) throws InterruptedException {long nanos = unit.toNanos(timeout);final ReentrantLock lock = this.lock;lock.lockInterruptibly();E result;try {while ( (result = dequeue()) == null && nanos > 0)nanos = notEmpty.awaitNanos(nanos);} finally {lock.unlock();}return result;
}
九、JUC阻塞队列第二弹
一、DelayQueue
在学习Delay的原理之前,先掌握应用。
如果需要掌握源码的话,需要对PriorityQueue有一定掌握,也就是二叉堆。
1.1 掌握DelayQueue应用
DelayQueue是无界队列
延迟的操作,可以向延迟队列中追加任务,这个任务需要指定延迟时间。
只有延迟时间到了,才可以将任务从队列中获取出来。
任务可以指定延迟时间,所以需要任务满足一定的需求
发现DelayQueue中的任务需要实现Delayed接口,重写getDelay和compareTo方法
getDelay:任务什么时候可以出队列
compareTo:存放任务到队列时,放在二叉堆的哪个位置
class Task implements Delayed{private String name;/** 执行时间 (单位毫秒) */private Long time;/**** @param name 任务名称* @param delayTime 传入延迟时间*/public Task(String name, Long delayTime) {this.name = name;this.time = System.currentTimeMillis() + delayTime;}/** 任务可以出队列的核心方法 */@Overridepublic long getDelay(TimeUnit unit) {return unit.convert(time - System.currentTimeMillis(),TimeUnit.MILLISECONDS);}/** 通过这个方法,来比较,将任务存放到二叉堆的指定位置 */@Overridepublic int compareTo(Delayed o) {// 基于执行时间比较return (int) (this.time - ((Task)o).getTime());}
}
测试效果
public static void main(String[] args) throws InterruptedException {DelayQueue queue = new DelayQueue();queue.offer(new Task("A",4000L));queue.offer(new Task("B",2000L));queue.offer(new Task("C",3000L));queue.offer(new Task("D",1000L));System.out.println(queue.take());System.out.println(queue.take());System.out.println(queue.take());System.out.println(queue.take());
}
1.2 分析源码
首先,想掌握延迟队列的源码信息,你需要先掌握优先级队列。
PriorityQueue,这个优先级队列是基于二叉堆。
二叉堆跟二叉树结构很像,二叉堆就是满二叉树。
优先级队列是基于数组实现的, 在队列内部会对每个节点做排序
二叉堆存放数据的顺序是固定的,并且没插入一个数据,会基于上移操作保证小顶堆的结构
如果取出数据,要涉及到下移来保证小顶堆结构
延迟队列就是基于优先级队列实现的
看延迟队列的添加任务方法
因为DelayQueue是无界队列,空间不够会扩容,生产者不需要挂起线程,空间肯定可以存放下当前的任务节点
只需要查看offer即可,其他的方法也都是调用的offer
// 延迟队列,就这么一个添加任务的方法
public boolean offer(E e) {final ReentrantLock lock = this.lock;lock.lock();try {// 调用优先级队列,添加任务q.offer(e);// 拿到第一个数据,看看我是不是第一个,如果是第一个,可能有消费者挂起了,唤醒一波if (q.peek() == e) {// 一会说!!!!leader = null;// condition啊,await挂起线程,signal唤醒线程available.signal();}// ok~返回truereturn true;} finally {lock.unlock();}
}// 这个是优先级队列的添加,延迟队列是基于优先级队列实现的功能
public boolean offer(E e) {if (e == null)throw new NullPointerException();modCount++;int i = size;// 空间不够,扩容数组if (i >= queue.length)grow(i + 1);size = i + 1;if (i == 0)// 放第一个数据,不需要上移queue[0] = e;else// 不是一个数据,判断是否需要上移siftUp(i, e);return true;
}
数据怎么从延迟队列拿出来的
浅尝的poll()
// 消费者浅尝一下拿数据,如果有数据,并且延迟时间已经到了,返回,否则啥也不干
public E poll() {final ReentrantLock lock = this.lock;lock.lock();try {// 拿到堆顶数据E first = q.peek();// 如果没数据,或者数据的延迟时间没到,返回nullif (first == null || first.getDelay(NANOSECONDS) > 0)return null;else// 如果有数据,并且时间到了,基于优先级队列,把任务取出来。 return q.poll();} finally {lock.unlock();}
}
浅尝一会的poll(time,unit)
// 尝一小会~~~尝 timeout时间
public E poll(long timeout, TimeUnit unit) throws InterruptedException {// 纳秒判断long nanos = unit.toNanos(timeout);final ReentrantLock lock = this.lock;// 这里加锁,允许中断。lock.lockInterruptibly();try {for (;;) {// 拿堆顶E first = q.peek();// 没数据,判断等多久if (first == null) {if (nanos <= 0)// 时间没了,告辞!!!!return null;else// 时间还有,等一小会~~nanos = available.awaitNanos(nanos);} else {// 必然有数据!!!!// 取出堆顶数据的剩余时间long delay = first.getDelay(NANOSECONDS);// 如果时间已经到位了,直接调用优先级队列,把数据取出来if (delay <= 0)return q.poll();// 再次判断等待时间if (nanos <= 0)// 不等,告辞!!!!!!!!!!!return null;// 将临时变量置位nullfirst = null; // 如果剩余的等待时间,小于任务的延迟时间,肯定拿不到数据的,等着玩,反正拿不到if (nanos < delay || leader != null)nanos = available.awaitNanos(nanos);else {// 我等待的时间内,必然可以拿到数据,并且没有leaderThread thisThread = Thread.currentThread();// 将当前线程置位leader,说明我是第一个在这等待数据的线程!!!!leader = thisThread;try {// 当前线程先挂起,挂起任务剩余的延迟时间,会释放锁!long timeLeft = available.awaitNanos(delay);// 重新计算剩余的等待时间nanos -= delay - timeLeft;} finally {// 将leader置位nullif (leader == thisThread)leader = null;}}}}} finally {// 如果leader为null,并且堆顶有数据,执行唤醒操作if (leader == null && q.peek() != null)available.signal();lock.unlock();}
}
而take方法,会调用await(),一致阻塞,直到拿到数据。
与poll(time,unit)的区别是,poll(time,unit)会计算剩余额的阻塞时间,take不会。
首先知道了DelayQueue如何用代码实现,首先节点就是任务必须实现Delayed接口,重写任务出队的时间以及任务的排序方式
入队:入队只有一个方法,就是offer,因为DelayQueue是无界队列,所以生产者是不需要阻塞的
出队:
- poll:直接拿堆顶数据,堆顶的延迟时间到了,直接返回任务,如果没到时间,返回null。
- poll(time,unit):
- 直接拿堆顶数据,
- 如果为null,或者阻塞时间已经到了,直接告辞!
- 如果不为null
- 并且延迟时间到了,返回数据
- 如果数据时间没到,查看阻塞剩余的时间到了么,到了直接返回null
- 如果数据的延迟时间没到
- 如果阻塞时间小于延迟时间,或者已经有leader了,直接等待阻塞时间,等待被唤醒即可
- 当前阻塞时间大于等于延迟时间,并且leader为null,这是就阻塞延迟时间即可
- 直接拿堆顶数据,
二、SynchronousQueue
2.1 介绍&应用
SynchronousQueue和其他阻塞队列有点区别,但是也是阻塞的!
SynchronousQueue并不存储数据,队列的长度是0,一个生产者扔数据到SynchronousQueue后,必须等待消费者拿走这个数据才可以。
跟Exchanger很像,Exchanger是两个线程交换数据,SynchronousQueue是传递数据,不是交换
应用的方向是线程间的通讯,可以使用。
使用的方法:
offer():拿着数据到了SynchronousQueue,如果恰巧有消费者在等待拿数据,配对成功!
offer(time,unit):着数据到了SynchronousQueue,可以等一会,如果期间有消费者来了,配对成功!
put():着数据到了SynchronousQueue,死等,直到消费者来了,或者被中断了。
poll,poll(time,unit),take,你懂得!
浅尝一下
public static void main(String[] args) throws InterruptedException {SynchronousQueue queue = new SynchronousQueue();new Thread(() -> {User user = new User();user.setName("jack&rose");System.out.println("publisher:" + user);queue.offer(user);}).start();new Thread(() -> {try {Object user = queue.take();System.out.println("consumer:" + user);} catch (InterruptedException e) {e.printStackTrace();}}).start();
}
2.1 核心内容
首先想要掌握SynchronousQueue,必须了解Transferer。
因为SynchronousQueue无论是消费者还是生产者,都用到了Transferer中的transfer方法
生产者调用transfer方法,需要传递一个参数,也就是数据
消费者调用transfer方法,第一个参数传递为null,代表获取数据
Transferer有两个实现,分别对应了SynchronousQueue的公平操作和不公平操作
- TransferQueue代表公平处理方式
- TransferStack代表不公平处理方式
查看TransferQueue内部的实现,查看核心属性
//这个是 TransferQueue 中的每一个节点
static final class QNode {volatile QNode next; volatile Object item; // 如果执行了put、take方法时,需要挂起线程,而挂起的就是这个线程volatile Thread waiter; // true:生产者// false:消费者final boolean isData;
}
/** Head of queue */
transient volatile QNode head;
/** Tail of queue */
transient volatile QNode tail;// 无参构造
TransferQueue() {// 会先初始化一个QNode,作为head和tail的指向,并且这个QNode不包含线程信息,就一个伪的头结点QNode h = new QNode(null, false); // initialize to dummy node.head = h;tail = h;
}
2.3 生产者和消费者执行套路
生产者:执行transfer方法时,会传递值
- offer:传递的nacos为0
- offer浅等:传递的nacos是指定数值
- put:timed设置为false
消费者:执行transfer方法时,第一个参数会设置为null
- poll,poll浅等,take方法与生产者一致。
分析TransferQueue的transfer方法
// 消费者和生产者都会调用这个房
E transfer(E e, boolean timed, long nanos) {// 声明QNodeQNode s = null; // 判断当前操作的是消费者还是生产者// true:生// false:消boolean isData = (e != null);for (;;) {// 拿到头尾节点QNode t = tail;QNode h = head;// 健壮性判断if (t == null || h == null) continue; // 如果头和尾相等。// 在当前的QNode单向链表中,要么都存放生产者,要么都存放消费者。// 所以第二个判断是,如果队列中有Qnode,查看我当前的isData是否和队列中Qnode的isData一致,一致挂上去if (h == t || t.isData == isData) { // 拿到t.nextQNode tn = t.next;// --------------------避免并发-----------------------------// 出现了并发操作,重新执行for循环if (t != tail) continue;// 如果尾节点的next不为null,有并发情况if (tn != null) { // 直接CAS操作,将tail的next节点设置为tail节点 advanceTail(t, tn);// 重新执行for循环continue;}// timed == true: offer,poll// 进来之后没有立即配对,那就直接告辞!if (timed && nanos <= 0) return null;// 把当前的QNode初始化。if (s == null)s = new QNode(e, isData);// 将tail的next指向的当前QNodeif (!t.casNext(null, s)) continue;// 将tail指向当前QnodeadvanceTail(t, s); // 等!!!(挂起线程),直到被唤醒,拿到指定的item数据Object x = awaitFulfill(s, e, timed, nanos);// 拿到的数据和当前QNode一致,当前节点取消了if (x == s) { // 清除当前节点,告辞!!! clean(t, s);return null;}// 判断是否还在队列中if (!s.isOffList()) { // 将当前节点设置为新的headadvanceHead(t, s); if (x != null) // 我拿到数据了,设置item为当前节点对象s.item = s;// 线程置位nulls.waiter = null;}// 返回数据return (x != null) ? (E)x : e;} else { // 如果逻辑到这,需要跟队列中的Qnode做配对。// 拿到head的next,mQNode m = h.next; // 并发问题,重新循环if (t != tail || m == null || h != head)continue; // 拿到m中的数据。// x == null:队列是消费者// x != null:队列是生产者Object x = m.item;// 1、出现并发问题,装车了// 2、取出的数据,竟然是节点本身,代表节点被取消!// 3、开始交换数据,将当前方法传入数据,替换到head的next,如果操作失败,并发问题if (isData == (x != null) || x == m || !m.casItem(x, e)) { // 配对失败,重新替换head节点 advanceHead(h, m); // 重新for循环 continue;}// 操作成功,也要替换headadvanceHead(h, m); // 唤醒队列中的head的next节点的线程。 LockSupport.unpark(m.waiter);// 操作成功,返回数据!return (x != null) ? (E)x : e;}}
}
十、ScheduledThreadPoolExecutor
一、ScheduledThreadPoolExecutor介绍&应用
ScheduledThreadPoolExecutor是ThreadPoolExecutor的一个子类,在线程池的基础上实现了延迟执行任务以及周期性执行任务的功能。
Java最早提供的是Timer类执行定时任务,串行的,不靠谱,会影响到其他的任务执行,在不采用第三方框架时,需要执行定时任务,ScheduledThreadPoolExecutor是比较好的选择。
ScheduledThreadPoolExecutor就是在线程池的基础上实现的定时执行任务的功能。
ScheduledThreadPoolExecutor提供了比较常用的四种方法执行任务:(不说Callable)
- execute:跟普通线程池执行没区别。
- schedule:可以指定延迟时间,一次性执行任务。
- scheduleAtFixedRate:可以让任务在固定的周期下执行。(任务的处理时间,不影响下次执行时间,如果任务的执行时间超过了设置的延迟时间,按照时间最长的计算)
- scheduleWithFixedDelay:可以让任务在固定的周期下执行。(任务的处理时间,影响下次执行时间)
应用效果:
public static void main(String[] args) throws InterruptedException {ScheduledThreadPoolExecutor executor = new ScheduledThreadPoolExecutor(10);//1. executeexecutor.execute(() -> {System.out.println("execute");});//2. scheduleexecutor.schedule(() -> {System.out.println("schedule");},2000,TimeUnit.MILLISECONDS);//3. AtFixedRateexecutor.scheduleAtFixedRate(() -> {try {Thread.sleep(4000);} catch (InterruptedException e) {e.printStackTrace();}System.out.println("at:" + System.currentTimeMillis());},3000,2000,TimeUnit.MILLISECONDS);//4. WithFixedDelayexecutor.scheduleWithFixedDelay(() -> {try {Thread.sleep(5000);} catch (InterruptedException e) {e.printStackTrace();}System.out.println("with:" + System.currentTimeMillis());},3000,2000,TimeUnit.MILLISECONDS);
}
如果实际开发应用需要使用到定人任务,更推荐一些开源你的框架,比如Quartz,XXL-job,Elastic-Job
因为corn表达式,对时间的控制更加方便!
二、ScheduleThreadPoolExecutor底层结构
两个核心内容
2.1 ScheduledFutureTask
首先看到了核心内容,ScheduledFutureTask间接的实现了Delayed接口,让任务可以放到延迟队列中,并且基于二叉堆做排序,即将执行的时间越短,就往堆顶扔,查看核心内容
private class ScheduledFutureTask<V>extends FutureTask<V> implements RunnableScheduledFuture<V> {// 就是计数器,每个任务进来时,都会有一个全局唯一的序号。// 如果任务的执行时间一模一样,比对sequenceNumberprivate final long sequenceNumber;// 任务执行的时间,单位是纳秒private long time;/** period == 0:表示一次性执行的任务* period > 0:表示使用的是At!* period < 0:表示使用的是With!*/private final long period;// 周期性实行任务时,引用具体任务,方便后面重新扔到阻塞队列RunnableScheduledFuture<V> outerTask = this;// 有参构造。schedule时使用当前有参重载封装任务!ScheduledFutureTask(Runnable r, V result, long ns) {super(r, result);this.time = ns;this.period = 0;this.sequenceNumber = sequencer.getAndIncrement();}// At,With时,使用当前有参重载封装任务!ScheduledFutureTask(Runnable r, V result, long ns, long period) {super(r, result);this.time = ns;this.period = period;this.sequenceNumber = sequencer.getAndIncrement();}// 不考虑这个,有返回结果ScheduledFutureTask(Callable<V> callable, long ns) {super(callable);this.time = ns;this.period = 0;this.sequenceNumber = sequencer.getAndIncrement();}// 实现Delayed接口重写的方法,执行的时间public long getDelay(TimeUnit unit) {return unit.convert(time - now(), NANOSECONDS);}// 实现Delayed接口重写的方法,比较的方式,放在二叉堆内部public int compareTo(Delayed other) {if (other == this) // compare zero if same objectreturn 0;if (other instanceof ScheduledFutureTask) {ScheduledFutureTask<?> x = (ScheduledFutureTask<?>)other;long diff = time - x.time;if (diff < 0)return -1;else if (diff > 0)return 1;else if (sequenceNumber < x.sequenceNumber)return -1;elsereturn 1;}long diff = getDelay(NANOSECONDS) - other.getDelay(NANOSECONDS);return (diff < 0) ? -1 : (diff > 0) ? 1 : 0;}// 判断是否是周期执行public boolean isPeriodic() {return period != 0;}// 省略部分代码
}
2.2 DelayedWorkQueue
阿巴阿巴!!!!
三、execute方法分析
这个方法是白给的。
public void execute(Runnable command) {schedule(command, 0, NANOSECONDS);
}
查看schedule即可
四、schedule方法分析
封装任务-放延迟队列-创建线程准备执行
将传入的command任务和延迟执行的时间封装
// 分析定时任务线程的schedule,延迟一段时间,执行一次command任务
public ScheduledFuture<?> schedule(Runnable command, long delay,TimeUnit unit) {// 非空判断!if (command == null || unit == null)throw new NullPointerException();// 封装任务,将普通的command封住为ScheduledFutureTask、// decorateTask方法默认情况下,什么都没做,就是返回了ScheduledFutureTask// decorateTask方法是线程池给你提供的扩展方法,可以在这个位置修改任务需要执行的具体细节RunnableScheduledFuture<?> t = decorateTask(command,new ScheduledFutureTask<Void>(command, null,triggerTime(delay, unit)));// 延迟执行delayedExecute(t);return t;
}// 查看triggerTime
private long triggerTime(long delay, TimeUnit unit) {return triggerTime(unit.toNanos((delay < 0) ? 0 : delay));
}
// 查看triggerTime方法重载,返回当前任务要执行的系统时间。
long triggerTime(long delay) {// 判断delay时间是否小于Long.MAX_VALUE >> 1,// 如果小于,正常计算执行的时间// 如果大于,可能出现超过long的取值范围问题,做额外处理return now() + ((delay < (Long.MAX_VALUE >> 1)) ? delay : overflowFree(delay));
}// 将command任务封装为ScheduledFutureTask
ScheduledFutureTask(Runnable r, V result, long ns) {super(r, result);// 任务要执行的系统时间this.time = ns;// 任务是否是周期性执行this.period = 0;// 基于AtomicLong计算序列化。this.sequenceNumber = sequencer.getAndIncrement();
}// ScheduleThreadPoolExecutor提供的一个扩展方法,可以在这个位置细粒度的修改任务执行的细节。
protected <V> RunnableScheduledFuture<V> decorateTask(Runnable runnable, RunnableScheduledFuture<V> task) {return task;
}
执行延迟任务
// 分析定时任务线程的schedule,延迟一段时间,执行一次command任务
public ScheduledFuture<?> schedule(Runnable command, long delay,TimeUnit unit) {// 非空判断!if (command == null || unit == null)throw new NullPointerException();// 封装任务,将普通的command封住为ScheduledFutureTask、// decorateTask方法默认情况下,什么都没做,就是返回了ScheduledFutureTask// decorateTask方法是线程池给你提供的扩展方法,可以在这个位置修改任务需要执行的具体细节RunnableScheduledFuture<?> t = decorateTask(command,new ScheduledFutureTask<Void>(command, null,triggerTime(delay, unit)));// 延迟执行delayedExecute(t);return t;
}
// 延迟执行!
private void delayedExecute(RunnableScheduledFuture<?> task) {// 查看线程池是不是已经不是RUNNING状态if (isShutdown())// 如果是,拒绝策略。reject(task);else {// 到这说明线程池状态是RUNNING// 调用阻塞队列,将任务添加进去,将任务扔到了延迟队列中(二叉堆)// 在添加任务到延迟队列的数组时,会记录当前任务所在的索引位置,方便取消任务时,从数组中移除// heapIndex方便取消任务super.getQueue().add(task);// 判断线程池是否不是RUNNING状态,如果不是RUNNING,就根据策略决定任务是否执行// 如果任务不需要执行了,调用remove方法,将任务从延迟队列移除,并且在if内部还会取消任务if (isShutdown() && !canRunInCurrentRunState(task.isPeriodic()) && remove(task))task.cancel(false);else// 线程池状态没毛病,任务是需要执行的!ensurePrestart();}
}
// 如果任务添加到了阻塞队列中,忽然线程池不是RUNNING状态,那么此时这个任务是否执行?
// periodic - true:代表是周期性执行的任务
// periodic - false:代表是一次性的延迟任务
boolean canRunInCurrentRunState(boolean periodic) {return isRunningOrShutdown(periodic ?continueExistingPeriodicTasksAfterShutdown :executeExistingDelayedTasksAfterShutdown);// 默认情况下,如果任务扔到了延迟队列中,有两个策略// 如果任务是周期性执行的,默认为false,// 如果任务是一次性的延迟任务,默认为true
}// 判断当前任务到底执行不执行
final boolean isRunningOrShutdown(boolean shutdownOK) {// 重新拿到线程池的ctlint rs = runStateOf(ctl.get());// 如果线程池是RUNNING,返回true// 如果线程池状态是SHUTDOWN,那么就配合策略返回true、falsereturn rs == RUNNING || (rs == SHUTDOWN && shutdownOK);
}// 准备执行任务
void ensurePrestart() {// 获取线程池中的工作线程个数。int wc = workerCountOf(ctl.get());// 如果工作线程个数,小于核心线程数,if (wc < corePoolSize)// 创建核心线程,一致在阻塞队列的位置take,等待拿任务执行addWorker(null, true);// 如果工作线程数不小于核心线程,但是值为0,创建非核心线程执行任务else if (wc == 0)// 创建非核心线程处理阻塞队列任务,而且只要阻塞队列没有任务了,当前线程立即销毁addWorker(null, false);
}
查看任务放到延迟队列后,是如何被工作线程取出来执行的
执行addWorker方法,会创建一个工作线程,工作线程在创建成功后,会执行start方法。在start方法执行后,会调用Worker的run方法,最终执行了runWorker方法,在runWorker方法中会在阻塞队列的位置执行take方法一直阻塞拿Runnable任务,拿到任务后就返回,然后执行。
所以需要查看的就是延迟队列的take方法,套路和之前讲的DelayQueue没有区别
在拿到任务后,会执行任务,也就是执行任务的run方法。
// 执行任务
public void run() {// 获取任务是否是周期执行// true:周期执行// false:一次的延迟执行boolean periodic = isPeriodic();// 再次判断线程池状态是否不是RUNNING,如果不是RUNNING,并且SHUTDOWN情况也不允许执行,或者是STOP状态if (!canRunInCurrentRunState(periodic))// 取消任务cancel(false);else if (!periodic)// 当前任务是一次性的延迟执行。执行任务具体的run方法,执行完,没了………………ScheduledFutureTask.super.run();// 后面是周期执行、省略部分代码…………
}
五、scheduleAtFixedRate和scheduleWithFixedDelay分析
在执行方法的初期,封装任务时:
- At会将period设置为正数,代表固定周期执行表
- With会将period设置为负数,代表在执行任务完毕后,再计算下次执行的时间
// 固定周期执行任务,如果任务的执行时间,超过周期,任务执行完,立即执行下一次任务。
public ScheduledFuture<?> scheduleAtFixedRate(Runnable command, // 具体任务long initialDelay, // 第一次执行的时间long period, // 周期执行时间TimeUnit unit) { // 时间单位// 阿巴阿巴~~~if (command == null || unit == null)throw new NullPointerException();// 如果传递的周期小于等于0,直接抛异常if (period <= 0)throw new IllegalArgumentException();ScheduledFutureTask<Void> sft =new ScheduledFutureTask<Void>(command, null, triggerTime(initialDelay, unit),unit.toNanos(period));// 扩展RunnableScheduledFuture<Void> t = decorateTask(command, sft);// 将任务设置给outerTask属性,方便后期重新扔到延迟队列sft.outerTask = t;// 嗯哼~delayedExecute(t);return t;
}
// 固定周期执行任务,会在任务执行完毕后,再计算下次执行的时间。
public ScheduledFuture<?> scheduleWithFixedDelay(Runnable command,long initialDelay,long delay,TimeUnit unit) {if (command == null || unit == null)throw new NullPointerException();if (delay <= 0)throw new IllegalArgumentException();ScheduledFutureTask<Void> sft =new ScheduledFutureTask<Void>(command, null, triggerTime(initialDelay, unit),unit.toNanos(-delay));RunnableScheduledFuture<Void> t = decorateTask(command, sft);sft.outerTask = t;delayedExecute(t);return t;
}
最终两个方法都会调用delayedExecute方法区将任务扔到阻塞队列,并尝试是否需要构建工作线程,从而执行任务
工作线程会监听延迟队列,拿到任务后会调用任务的run方法
public void run() {// 查看At和With可确定任务是周期执行boolean periodic = isPeriodic();// 线程池状态对不!!if (!canRunInCurrentRunState(periodic))cancel(false);else if (!periodic)// 一次性的延迟执行ScheduledFutureTask.super.run();// 到这,先执行任务else if (ScheduledFutureTask.super.runAndReset()) {// 设置下一次任务的运行时间setNextRunTime();reExecutePeriodic(outerTask);}
}// 计算任务下次执行时间,time是任务执行的时间,而这里是time的上次的执行时间
private void setNextRunTime() {// 拿到当前任务的periodlong p = period;// period > 0:Atif (p > 0)// 直接拿上次执行的时间,添加上周期时间,来计算下次执行的时间。time = time + p;else// period < 0:With// 任务执行完,拿当前系统时间计算下次执行的时间点time = now() + p;
}// 重新将任务扔到延迟队列中
void reExecutePeriodic(RunnableScheduledFuture<?> task) {// 线程池状态的判断if (canRunInCurrentRunState(true)) {// 将任务扔到了延迟队列中super.getQueue().add(task);// 扔到延迟队列后,再次判断线程池状态,是否需要取消任务!if (!canRunInCurrentRunState(true) && remove(task))task.cancel(false);else// 需要创建线程不~ensurePrestart();}
}
同步、异步、阻塞、非阻塞。
同步:做了同步操作后,被调用者不会主动通知我结果,我需要主动查看结果。
异步:做了异步操作后,被调用者会主动通知我结果是什么。
阻塞:调用功能后,不能做其他事情。
非阻塞:调用功能后,可以做其他事情。
同步阻塞:执行烧水功能时,我不能做其他事情,并且烧水功能执行完后,不会主动通知我。
同步非阻塞:执行烧水功能时,我可以做其他事情,但是烧水功能执行完后,不会主动通知我。
异步阻塞:执行烧水功能时,我不能做其他事情,并且烧水功能执行完后,会主动通知我。(这个操作没有)
异步非阻塞:执行烧水功能时,我可以做其他事情,并且烧水功能执行完后,会主动通知我。
十一、FutureTask源码
一、Future介绍
Future是个什么鬼?
Java创建线程的方式,一般常用的是Thread,Runnable。如果需要当前处理的任务有返回结果的话,
需要使用Callable。Callable运行需要配合Future。
Future是一个接口,一般会使用FutureTask实现类去接收Callable任务的返回结果。
FutureTask存在一些问题的,同步非阻塞执行的任务,他不会主动通知你返回结果是什么。
二、FutureTask使用
Callable是你要执行的任务。
FutureTask是存放任务返回结果的位置。
public static void main(String[] args) throws ExecutionException, InterruptedException {FutureTask<Integer> futureTask = new FutureTask<>(() -> {System.out.println("任务执行");Thread.sleep(2000);return 123+764;});Thread t = new Thread(futureTask);t.start();System.out.println("main线程启动了t线程处理任务");Integer result = futureTask.get();System.out.println(result);
}
三、FutureTask源码分析
要分析FutureTask,首先需要查看一下他的核心属性
/*** NEW -> COMPLETING -> NORMAL 任务正常执行,返回结果是正常的结果* NEW -> COMPLETING -> EXCEPTIONAL 任务正常执行,但是返回结果是异常* NEW -> CANCELLED 任务直接被取消的流程* NEW -> INTERRUPTING -> INTERRUPTED*/
// 代表当前任务的状态
private volatile int state;
private static final int NEW = 0; // 任务的初始化状态
private static final int COMPLETING = 1; // Callable的结果(正常结果,异常结果)正在封装给当前的FutureTask
private static final int NORMAL = 2; // NORMAL任务正常结束
private static final int EXCEPTIONAL = 3; // 执行任务时,发生了异常
private static final int CANCELLED = 4; // 任务被取消了。
private static final int INTERRUPTING = 5; // 线程的中断状态,被设置为了true(现在还在运行)
private static final int INTERRUPTED = 6; // 线程被中断了。// 当前要执行的任务
private Callable<V> callable;
// 存放任务返回结果的属性,也就是futureTask.get需要获取的结果
private Object outcome;
// 执行任务的线程。
private volatile Thread runner;
// 单向链表,存放通过get方法挂起等待的线程
private volatile WaitNode waiters;
t.start后,如何执行Callable的call方法,其实是通过run方法执行的call方法
// run方法的执行流程,最终会执行Callable的call方法
public void run() {// 保证任务的状态是NEW才可以运行// 基于CAS的方式,将当前线程设置为runner。if (state != NEW ||!UNSAFE.compareAndSwapObject(this, runnerOffset,null, Thread.currentThread()))return;// 准备执行任务try {// 要执行任务 cCallable<V> c = callable;// 任务不为null,并且任务的状态还处于NEWif (c != null && state == NEW) {// 放返回结果V result;// 任务执行是否为正常结束boolean ran;try {// 运行call方法,拿到返回结果封装到result中result = c.call();// 正常返回,ran设置为trueran = true;} catch (Throwable ex) {// 结果为nullresult = null;// 异常返回,ran设置为falseran = false;// 设置异常信息setException(ex);}if (ran)// 正常执行结束,设置返回结果set(result);}} finally {// 将执行任务的runner设置空runner = null;// 拿到状态int s = state;// 中断要做一些后续处理if (s >= INTERRUPTING)handlePossibleCancellationInterrupt(s);}
}// 设置返回结果
protected void set(V v) {// 首先要将任务状态从NEW设置为COMPLETINGif (UNSAFE.compareAndSwapInt(this, stateOffset, NEW, COMPLETING)) {// 将返回结果设置给outcome。outcome = v;// 将状态修改为NORMAL,代表正常技术UNSAFE.putOrderedInt(this, stateOffset, NORMAL);// 一会再说,你猜猜~~~finishCompletion();}
}
get方法获取返回结果,到挂起的位置
public V get() throws InterruptedException, ExecutionException {// 拿状态int s = state;// 满足找个状态就代表现在可能还没有返回结果if (s <= COMPLETING)// 尝试挂起线程,等待拿结果s = awaitDone(false, 0L);return report(s);
}// 线程要等待任务执行结束,等待任务执行的状态变为大于COMPLETING状态
private int awaitDone(boolean timed, long nanos) throws InterruptedException {// 计算deadline,如果是get(),就是0, 如果是get(time,unit)那就追加当前系统时间final long deadline = timed ? System.nanoTime() + nanos : 0L;// 构建WaitNodeWaitNode q = null;// queued = falseboolean queued = false;// 死循环for (;;) {// 找个get的线程是否中断了。if (Thread.interrupted()) {// 将当前节点从waiters中移除。removeWaiter(q);// 并且抛出中断异常throw new InterruptedException();}// 拿到现在任务的状态int s = state;// 判断任务是否已经执行结束了if (s > COMPLETING) {// 如果设置过WaitNode,直接移除WaitNode的线程if (q != null)q.thread = null;// 返回当前任务的状态return s;}// 如果任务的状态处于 COMPLETING ,else if (s == COMPLETING)// COMPLETING的持续时间非常短,只需要做一手现成的让步即可。Thread.yield();// 现在线程的状态是NEW,(call方法可能还没执行完呢,准备挂起线程)else if (q == null)// 封装WaitNode存放当前线程q = new WaitNode();else if (!queued)// 如果WaitNode还没有排在waiters中,现在就排进来(头插法的效果)queued = UNSAFE.compareAndSwapObject(this, waitersOffset, q.next = waiters, q);else if (timed) {// get(time,unit)挂起线程的方式// 计算挂起时间nanos = deadline - System.nanoTime();// 挂起的时间,是否小于等于0if (nanos <= 0L) {// 移除waiters中的当前NoderemoveWaiter(q);// 返回任务状态return state;}// 正常指定挂起时间即可。(线程挂起)LockSupport.parkNanos(this, nanos);}else {// get()挂起线程的方式LockSupport.park(this);}}
}
线程挂起后,如果任务执行完毕,由finishCompletion唤醒线程
// 任务状态已经变为了NORMAL,做一些后续处理
private void finishCompletion() {for (WaitNode q; (q = waiters) != null;) {// 拿到第一个节点后,直接用CAS的方式,将其设置为nullif (UNSAFE.compareAndSwapObject(this, waitersOffset, q, null)) {for (;;) {// 基于q拿到线程信息Thread t = q.thread;// 线程不为nullif (t != null) {// 将WaitNode的thread设置为nullq.thread = null;// 唤醒这个线程LockSupport.unpark(t);}// 往后遍历,接着唤醒WaitNode next = q.next;if (next == null)break;q.next = null;// 指向next的WaitNodeq = next;}break;}}// 扩展方法,没任何实现,你可以自己实现done();// 任务处理完了,可以拜拜了!callable = null;
}
拿到返回结果的处理
// 任务结束。
private V report(int s) throws ExecutionException {// 拿到结果Object x = outcome;// 判断是正常返回结束if (s == NORMAL)// 返回结果return (V)x;// 任务状态是大于取消if (s >= CANCELLED)// 甩异常。throw new CancellationException();// 扔异常。throw new ExecutionException((Throwable)x);
}// 正常返回 report
// 异常返回 report
// 取消任务 report
// 中断任务 awaitDone
四、牛批的CompletableFuture
FutureTask存在的问题:
问题1:FutureTask获取线程执行的结果前,主线程需要通过get方法一直阻塞等待子线程执行完call方法,才可以拿到返回结果。
问题2:如果不通过get去挂起线程,通过while循环,不停的判断任务的执行状态是否结束,结束后,再拿结果。如果任务长时间没执行完毕,CPU会一直调度查看任务状态的方法,会浪费CPU资源。
FutureTask是一个同步非阻塞处理任务的方式。
需要一个异步非阻塞处理任务的方式。CompletableFuture在一定程度上就提供了各种异步非阻塞的处理方案,并且提供响应式编程,代码编写上,效果更佳(更漂亮)
CompletableFuture是JDK1.8,再次又Doug Lea研发,COmpletableFuture也是实现了Future接口实现的功能,可以不使用FutureTask,直接使用CompletableFuture即可。
提供非常丰富的函数去执行各种异步操作。
十二、CompletableFuture应用
回顾:
上次课,玩的FutureTask,应用起来特别简单。
FutureTask他是同步非阻塞。
FutureTask会配合Callable执行有返回结果的任务。
如果需要拿到返回结果,需要执行get方法,获取最终结果
因为无法实现异步非阻塞,JDK1.8中有个CompletableFuture可以实现异步非阻塞的效果
再带有返回结果的线程执行完毕后,提供一个回调。
一、CompletableFuture的应用
CompletableFuture最重要的就是解决了异步回调的问题
CompletableFuture就是执行一个异步任务,异步任务可以有返回结果,也可以没有返回结果
CompletableFuture提供了两个最基本运行的基本方法
函数式编程中,三个最核心的接口
Supplier - 生产者,没有入参,但是有返回结果
Consumer - 消费者,有入参,但是没有返回结果
Function - 函数,有入参,并且有返回结果
supplyAsync(Supplier<U> supplier)异步执行任务,有返回结果
runAsync(Runnable runnable)异步执行任务,没有返回结果
在不指定线程池的前提下,这两个异步任务都是交给ForkJoinPool去执行的。
而ForkJoinPool内部是守护线程,守护线程在主线程结束后,就不干活了。
但是只是用这两个方法,无法实现异步回调的。
如果需要在当前任务执行完毕后,拿着返回结果或者不拿返回结果,继续去执行后续任务操作的话,需要基于其他方法去实现
这里的方法有个特点,都是在前置任务结果后,再执行当前任务
所以后续看的任务都有一个特点,大部分方法一共有三种方法重载、
不带Async,带Async,带Async还可以传入线程池的套路
thenApply(Function<prevResult,currResult>);等待前一个任务处理结束后,拿着前置任务的返回结果,再做处理,并且返回当前结果
thenApplyAsync(Function<prevResult,currResult>[,线程池])跟上面的套路一致,但是再执行后续任务时,采用全新的线程执行
thenAccept(Consumer<preResult>);等待前一个任务处理结束后,拿着前置任务的返回结果,再做处理,当然处理没有返回结果
thenAcceptAsync(Consumer<preResult>[,线程池]);跟上面的套路一致,但是再执行后续任务时,采用全新的线程执行
thenRun(Runnable)等待前一个任务处理结束后,再做处理。不接收前置任务结果,也不返回结果
thenRunAsync(Runnable[,线程池])跟上面的套路一致,但是再执行后续任务时,采用全新的线程执行
其次还有可以执行相对复杂的处理,在前一个任务执行的同时,执行后续任务。等待前置任务和后置任务都搞定之后,再执行最终任务
thenCombine(CompletionStage,Function<prevResult,nextResult,afterResult>)可以让任务1和任务2一起执行,等待任务1和任务2全部搞定,获取前两个任务的结果执行最终处理,最终处理也可以返回结果
thenCombineAsync(CompletionStage,Function<prevResult,nextResult,afterResult>[,线程池])跟上面的套路一致,但是再执行后续任务时,采用全新的线程执行
thenAcceptBoth(CompletionStage,Consumer<prevResult,nextResult>)让前置任务和后续任务同时执行,都执行完毕后,拿到两个任务的结果,再做后续处理,但是没有返回结果
thenAcceptBothAsync(CompletionStage,Consumer<prevResult,nextResult>[,线程池])跟上面的套路一致,但是再执行后续任务时,采用全新的线程执行
runAfterBoth(CompletionStage,Runnble)让前置任务和后续任务同时执行,都执行完毕后,再做后续处理
runAfterBothAsync(CompletionStage,Runnble[,线程池])跟上面的套路一致,但是再执行后续任务时,采用全新的线程执行
后面还提供了可以让两个任务一起执行,但是有一个任务结束,有返回结果后,就做最终处理
applyToEither(CompletionStage,Function<firstResult,afterResult>)前面两个任务同时执行,有一个任务执行完,获取返回结果,做最终处理,再返回结果
acceptEither(CompletionStage,Consumer<firstResult>)前面两个任务同时执行,有一个任务执行完,获取返回结果,做最终处理
runAfterEither(CompletionStage,Runnable)前面两个任务同时执行,有一个任务执行完,做最终处理
Async的不说了。
后面还提供了等到前置任务处理完,再做后续处理,后续处理返回的结果为CompletionStage
thenCompose(Function<prevResult,CompletionStage>)连接两个任务,前置处理完,执行后续,后续可以拿到前置任务的结果,并且做处理,最终返回的是CompletionStage
thenCompose (Function<? super T, ? extends CompletionStage<U>> fn); thenApply (Function<? super T, ? extends U> fn); // 用thenApply其实就足够了
最后还有处理异常的各种姿势
exceptionally(Function<Throwable,currResult>)只有当前这个异常处理方法,可以获取到前面任务的异常信息,有异常才执行当前任务。
exceptionally不存在Async的操作。
whenComplete(Consumer<prevResult,Throwable>)可以拿到上一个任务的返回结果和异常,但是当前处理没有返回结果,无法影响最终让任务的结果内容
这个带有Async操作
hanle(Function<prevResult,Throwable,currResult>)可以拿到上一个任务的返回结果和异常,同时当前处理可以返回内容
二、基于上面阐述做应用
2.1 小一要回家干法,小二去做饭,小一看电视,等到小二昨晚,小一干饭。
public static void main(String[] args) throws InterruptedException {sout("小连回家干饭");CompletableFuture<String> task = CompletableFuture.supplyAsync(() -> {sout("小严做饭!");sleep();return "锅包肉!";});sout("小连看电视!");sout("小连干饭:" + task.join());
}
2.2 小一要回家干法,小二去炒菜,小三去焖饭,小一看电视,等到小二和小三都做好了,小四端菜和饭给小一,小一干饭
public static void main(String[] args) throws InterruptedException {sout("小连回家干饭");CompletableFuture<String> task = CompletableFuture.supplyAsync(() -> {sout("小严去炒菜!");sleep();return "锅包肉!";},executor).thenCombineAsync(CompletableFuture.supplyAsync(() -> {sout("小李去焖饭");sleep();return "大米饭!";},executor),(food,rice) -> {sout("小陈端" + food + "," + rice);sleep();return "饭菜好了!";},executor);sout("小连看电视!");sout("小连干饭:" + task.join());
}
十三、CompletableFuture源码分析
异步回调
一、runAsync方法源码分析
基于当前这个最简单的方法,来分析CompletableFuture是如何执行异步任务的。
以及如何触发后续任务执行
1.1 当前异步任务执行流程
// 异步执行任务
static CompletableFuture<Void> asyncRunStage(Executor e, Runnable f) {// 非空判断。 if (f == null) throw new NullPointerException();// 声明当前任务的CompletableFuture对象// 在看CompletableFuture时,任务执行和后续任务的触发是两个操作// new的这个d,他的目的是为了触发后续任务的执行。CompletableFuture<Void> d = new CompletableFuture<Void>();// 将任务和CompletableFuture封装到一起,作为AsyncRun的对象// 将AsyncRun交给线程池执行e.execute(new AsyncRun(d, f));return d;
}// 封装任务和COmpletableFuture的AsyncRun对象
static final class AsyncRun extends ForkJoinTask<Void> CompletableFuture<Void> dep; Runnable fn;// 存储当前的任务以及CompletableFutureAsyncRun(CompletableFuture<Void> dep, Runnable fn) {this.dep = dep; this.fn = fn;}public void run() {// 声明两个变量,一个存储CompletableFuture,一个存储具体任务CompletableFuture<Void> d; Runnable f;// 非空判断的同时,将成员变量做临时存储if ((d = dep) != null && (f = fn) != null) {// help gcdep = null; fn = null;// 当前任务是否已经有返回结果。if (d.result == null) {// 任务还没有执行try {// 线程池执行异步任务。f.run();// 当然是Runnable任务,没有返回结果的,所以这里直接封装为一个表示null的标识// 为null的结果是NILd.completeNull();} catch (Throwable ex) {// 如果异常结束,将出现的异常封装到返回结果中d.completeThrowable(ex);}}// 执行后续任务d.postComplete();}}
}
1.2 后续任务的触发方式
// 当前任务执行完毕,触发后续任务。
final void postComplete() {// f:当前任务的COmpletableFuture// h:栈顶!CompletableFuture<?> f = this; Completion h;// h拿到栈顶数据。while ((h = f.stack) != null ||(f != this && (h = (f = this).stack) != null)) {// 栈结构中有后续需要处理的任务,进到while循环中,每次循环之后,h的指针都会后移CompletableFuture<?> d; Completion t;// 栈顶换人啦~~if (f.casStack(h, t = h.next)) {if (t != null) {if (f != this) {pushStack(h);continue;}h.next = null; // detach}// 执行栈顶的任务f = (d = h.tryFire(NESTED)) == null ? this : d;}}
}
问题:发现CompletableFuture的后续任务是基于栈结构存储的,但是在测试的代码中,执行的顺序没有按照栈结构的方式,去执行
CompletableFuture不保证后续任务的执行顺序。
从上面的源码分析,发现,不会出现栈结构完全倒序的情况。
二、thenRun方法源码分析
后续任务的触发方式有两种:
- 一种是基于前继任务执行完毕,执行postComplete方法触发
- 另一种是后续任务在压栈之前和之后,会尝试执行后续任务,只要前继任务执行结束的快,后续任务就可以直接执行,不需要前继任务的触发
// 追加任务到栈结构的逻辑
// e:线程池、执行器。 如果是Async异步调用,会传递使用的线程池。 如果是普通的thenRun,不会传递线程池,为null
private CompletableFuture<Void> uniRunStage(Executor e, Runnable f) {// 阿巴阿巴。if (f == null) throw new NullPointerException();// 当前任务的CompletableFutureCompletableFuture<Void> d = new CompletableFuture<Void>();// 如果传递了线程池,代表异步执行,直接走if代码块中的内容// 如果没有传递线程池,同步执行,需要先执行uniRunif (e != null || !d.uniRun(this, f, null)) {// 前继任务还没执行完呢,那就准备压栈!// 将线程池,后续任务,前继任务,后续具体任务UniRun<T> c = new UniRun<T>(e, d, this, f);// 将封装好的c,直接到this的栈结构中// 不确保UniRun对象一定会被压到栈结构中// 在这个位置,可能会出现前继任务已经执行完毕,导致无法压到栈顶。this.push(c);// 尝试执行当前的后续任务c.tryFire(SYNC);}return d;
}// 当前方法的作用:尝试执行任务。
// a:前继任务
// f:后续具体任务
// c:现在是null
final boolean uniRun(CompletableFuture<?> a, Runnable f, UniRun<?> c) {Object r; Throwable x;// 只看第二个判断。 // 如果前继任务没有执行完毕,直接return falseif (a == null || (r = a.result) == null || f == null)return false;// 省略部分代码
}// 压栈方法
final void push(UniCompletion<?,?> c) {// 不为null!!!if (c != null) {// result是前继任务的结果// 只有前继任务还没有执行完毕时,才能将当前的UniRun对象压到栈结构中while (result == null && !tryPushStack(c))lazySetNext(c, null); }
}// 后续任务的执行,以及之前将后续任务封装的UniRun对象
static final class UniRun<T> extends UniCompletion<T,Void> {Runnable fn;// 之前封装后继任务调用的有参构造UniRun(Executor executor, CompletableFuture<Void> dep,CompletableFuture<T> src, Runnable fn) {super(executor, dep, src); this.fn = fn;}// 尝试执行任务// dep:后续任务// src:前继任务// fn:后续具体任务final CompletableFuture<Void> tryFire(int mode) {// d:存储后续任务, a:存储前继任务CompletableFuture<Void> d; CompletableFuture<T> a;if ((d = dep) == null ||// 尝试执行后续任务的位置!d.uniRun(a = src, fn, mode > 0 ? null : this))return null;dep = null; src = null; fn = null;return d.postFire(a, mode);}
}// 尝试执行后续任务的方法
final boolean uniRun(CompletableFuture<?> a, Runnable f, UniRun<?> c) {Object r; Throwable x;// 判断前继任务执行完了么? 如果执行完了,直接走后面执行后续任务// 如果前继任务没执行完,if (a == null || (r = a.result) == null || f == null)// 返回falsereturn false;// 到这,说明前继任务已经执行结束了。// 要执行后续任务,但是要先判断后续任务执行了么? if (result == null) {// 后续任务还木有执行// 如果前继任务是异常结束,后续任务就不需要执行了!if (r instanceof AltResult && (x = ((AltResult)r).ex) != null)// 正常封装异常信息。completeThrowable(x, r);else// 前继任务正常结束,尝试之后后续任务。try {// 如果c == null,代表异步执行// 如果c != null,嵌套执行,同步执行if (c != null && !c.claim())// 异步执行完毕,返回falsereturn false;// 需要同步执行f.run();// 正常封装结果completeNull();} catch (Throwable ex) {// 异常封装结果completeThrowable(ex);}}return true;
}// 执行任务
final boolean claim() {// 拿到线程池Executor e = executor;// 判断当前任务标记,是否执行if (compareAndSetForkJoinTaskTag((short)0, (short)1)) {if (e == null)// 线程池为null,代表同步执行,直接返回truereturn true;// 异步执行,使用线程池执行即可。executor = null; e.execute(this);}return false;
}
三、整体执行流程图
十四、并发编程总结
一、锁
1.1 synchronized(看到Java层面就够了)
对象锁和类锁
synchronized到底是使用普通new出来的对象作为锁,还是Class对象作为锁
对象锁 - new多个对象去操作,无法实现互斥的
类锁 - 无论怎么使用,能保证一个JVM内是互斥的
原理、对象头
synchronized是基于对象作为锁的。
锁信息全部都放在了对象的对象头中的MarkWord中
其中线程竞争锁之前,肯定需要先查看当前锁的标记位,以不同的方式来竞争锁资源。
锁升级
-
初始化状态的对象的锁信息有两种情况**(无锁)**:
- 无锁状态:当前状态没有开启偏向锁。
- 匿名偏向:当前状态开启了偏向锁,没有偏向任何线程。
-
偏向锁:只有一个线程来拿锁资源,没有竞争。
-
轻量级锁:以CAS的方式,去竞争锁资源,不会让线程挂起。(自适应自旋锁)(LockRecord)
-
重量级锁:直接采用MarkWord指向的ObjectMonitor以传统的方式去竞争锁资源。
偏向锁的重入是如何实现的?
- 其实偏向锁时,也用到了LockRecord,只不过内部不会存储hashcode信息等等,在偏向锁重入时,每次都会压栈一个LockRecord,从而实现偏向锁重入。
轻量级锁的CAS是如何实现的?
-
在重量级锁中实现的。基于TryLock方法采用
int ObjectMonitor::TryLock (Thread * Self) {for (;;) {void * own = _owner ;if (own != NULL) return 0 ;if (Atomic::cmpxchg_ptr (Self, &_owner, NULL) == NULL) {// Either guarantee _recursions == 0 or set _recursions = 0.assert (_recursions == 0, "invariant") ;assert (_owner == Self, "invariant") ;// CONSIDER: set or assert that OwnerIsThread == 1return 1 ;}// The lock had been free momentarily, but we lost the race to the lock.// Interference -- the CAS failed.// We can either return -1 or retry.// Retry doesn't make as much sense because the lock was just acquired.if (true) return -1 ;} }
synchronized和ReentrantLock后期更推荐使用谁。
后期肯定是使用synchronized,因为synchronized底层更利于后期版本的优化,而ReentrantLock再怎么玩也是基于Java层面的锁。
锁消除
JMM层面在编译时,如果发展加锁的位置不存在任何的共享资源操作或者是引发线程安全问题的,那么去掉竞争和释放锁资源的操作。
锁膨胀
while(xxx){synchronized(this){// 。。。}
}
synchronized(this){while(xxx){// 。。。}
}
1.2 ReentrantLock
AQS:队列 + 状态位,就是一个JUC下的基础类,大量JUC下的并发工具都是基于AQS实现的。
状态位state:volatile修饰,CAS修改的int类型数值。
队列:双向链表。每个节点是一个Node。
公平锁和非公平锁
lock:非公平锁直接CAS修改state,如果失败,执行acquire。公平锁执行执行acquire。
tryAcquire:在发现state为0时。
- 非公平锁,直接CAS修改state。
- 公平锁,查看队列中是否有排队的Node,如果有,查看head的next是不是当前线程,然后再决定是否CAS修改state
为什么唤醒Node时,要从后往前遍历找到离head最近的Node?
在执行addWaiter方法时,先将当前Node的prev指向前一个节点,再将tail指向当前节点。此时上一个节点的next还有没有指向当前节点,如果存在并发问题,会导致遍历时,丢失节点。
1.3 ReentrantReadWriteLock
读写锁实现实现原理
还是基于AQS实现的,将state的高16位作为读锁的信息,低16位作为写锁的信息。
读锁是共享锁。写锁是互斥锁。
如何避免写锁饥饿的
读锁获取锁资源时,判断当前在AQS中排队的是否是写锁资源,如果是写锁,读锁会直接在AQS中排队
读锁重入如何实现
读锁可能会有多个线程同时持有,如果不清楚每个线程重入的次数,无法确定读锁资源是否释放干净。
ReentrantReadWriteLock就基于ThreadLocal来记录当前线程读锁重入的次数。
当然,同时也要对state的高16位,进行修改。
读锁重入的优化
第一个持有读锁的线程,无需将重入次数设置到ThreadLocal中,直接使用读写锁内部提供的firstReader来记录当前线程,采用firstReaderHoldCount来记录读锁重入的次数。
最后一个来竞争读锁资源的线程(不包含第一个),采用cachedHoldCounter来记录锁重入次数,也会在ThreadLocal中存储一份,但是如果当前线程再次重入,不需要从ThreadLocal中获取,而是直接修改cachedHoldCounter即可
二、ThreadPoolExecutor
线程池的7个核心参数
不会的,出门左转。
线程池的拒绝策略
线程池自带四种,如何可以满足业务需求,直接用即可,如果不满足,可以自行实现RejectedExecutionHandler接口,重写功能。
线程池的状态
RUNNING,SHOTDOWN,STOP,TIDYING,TERMINATED
TIDYING是过渡状态,可以从SHUTDOWN和STOP状态转换过来,其实到了TIDYING,工作线程已经没了,工作队列的任务也处理完了。就差执行一个terminated方法,转换到TERMINATED状态
线程池的ctl属性
高3位存储线程池状态,低29位存储工作线程个数。
线程池的执行流程
不会的,出门右转。
为什么线程池要添加非核心并且没有任务的工作线程addWroker(null,false);
当前工作线程个数为0,但是工作队列中有任务
此时就需要添加一个非核心并且空任务的工作线程去处理阻塞队列中的任务
Worker中的锁是干嘛的
Worker中基于AQS实现了一个非可重入锁。
Worker为了避免中断线程时,Worker还没有初始化完成,导致出现问题。
如何在线程池之前任务前后做额外处理
线程池提供了两个勾子函数。
三、ConcurrentHashMap(1.8)
ConcurrentHashMap在JDK1.8中如何实现线程安全
阿巴阿巴……
ConcurrentHashMap的散列算法
阿巴阿巴……
ConcurrentHashMap的数组长度为何是2的n次幂
阿巴阿巴……
ConcurrentHashMap如何实现并发扩容的
resizeStamp,sizeCtl,扩容线程数 + 1
ConcurrentHashMap中的addCount如何实现
addCount在记录ConcurrentHashMap中元素的个数,因为AtomicLong在高并发情况下,性能较低,所以ConcurrentHashMap中采用了LongAdder的实现方式,其实就是将LongAdder的源码,复制过来改了一改。并且在addCount方法中,还会有扩容的判断。
ConcurrentHashMap红黑树什么情况会转换为链表
扩容时,或者删除红黑树数据长度小于等于6时,都有可能将红黑树转为链表
ConcurrentHashMap在有线程写红黑树时,读操作怎么办
链表在扩容为红黑树的同时,会保留双向链表和红黑树。
此时会查询双向链表,不会查询红黑树。
ConcurrentHashMap的lastRun机制是什么
阿巴阿巴……
四、并发工具
4.1 CountDownLatch
CountDownLatch实现原理
CountDownLatch基于AQS实现的,初始化时给定一个state的值。
每次线程执行countDown方法时,对state - 1。
如果线程在执行await方法时:
- state > 0,此时线程挂起
- state == 0,此时线程被唤醒
4.2 Semaphore
Semaphore实现原理
还是基于AQS实现的,一般用于固定资源,比如连接池,线程池等等。
类似计数器。每次从线程中基于acquire拿到资源,使用完毕后,基于release归还资源。
PROPAGATE类型Node的作用
因为在JDK1.5中,Semaphore存在资源无法被正常使用的情况。
信号量中有资源,但是线程通过acquire无法获取
基于PROPAGATE类型的Node,可以在唤醒当前线程后,继续唤醒后续线程
4.3 CyclicBarrier
CyclicBarrier实现原理
Java中的栅栏
类似CountDownLatch的原理,等待指定数量的线程执行await方法后,一起并行去执行这些线程的后续任务。
CyclicBarrier是可以重置state的,也就是任务执行一次后,可以重新反复使用当前的CyclicBarrier
ReentrantLock的Condition的实现原理
当线程获取到锁资源后,基于Condition挂起线程时,会释放锁资源,并且将当前线程封装到AQS中的Condition中的一个链表中,当基于signal方法唤醒后,会扔到AQS的双向链表中
5、阻塞队列
5.1 ArrayBlockingQueue
基于数组实现的阻塞队列
虚假唤醒
在await挂起线程判断的位置,采用while循环去解决虚假唤醒。
如果使用if判断,会造成多个线程在不满足情况下,去向阻塞队列追加数据,导致安全问题。、
5.2 LinkedBlockingQueue
基于链表实现的阻塞队列
5.3 PriorityQueue
基于数组实现的二叉堆,基于二叉堆实现的优先级队列
5.4 PriorityBlockingQueue
基于PriorityQueue实现的阻塞队列
5.5 DelayedQueue
基于PriorityQueue实现的延迟队列,要求插入的数据要实现Delayed接口。
5.6 SynchronousQueue
不会将数组存放到指定位置,生产者放数据,就要一直等到消费者来消费。
6、ScheduleThreadPoolExecutor
execute,schedule,scheduleAtFixedRate,scheduleWithFixedDelay的区别
- execute:正常执行任务,跟定时执行没关系。
- schedule:延迟一段时间执行。执行一次。
- scheduleAtFixedRate:可以让任务在固定的周期下执行。(如果任务执行时间,超过了延迟时间,采用任务的执行时间作为周期)这里会采用上次任务执行的时间点,加上延迟时间,作为下次任务的时间
- scheduleWithFixedDelay:可以让任务在固定的周期下执行。(任务的处理时间,影响下次执行时间)
7、CompletableFuture
CompletableFuture是什么
实现了异步非阻塞的效果。就是在任务执行完毕后,会主动通知,不需要调用方主动会获取。
CompletableFuture的后续任务是基于什么存储的
栈
CompletableFuture为何不能保证后续任务的执行顺序
因为任务是其他线程执行,业务线程依然可以给CompletableFuture设置后续任务,如果在设置任务到栈结构之前,前置任务已经执行完了,就不需要再存放到栈结构了,直接执行即可。
如果有时间,一定要系统的看一下源码,这样依赖八股文什么的就不用看了。