有时,当第二次访问网站时,看起来比较怪,样式不正常。
通常,是因为 cache control 缓存控制策略定义不正确,导致服务端最新部署之后客户端没有接收到最新的更改。
本文将向您展示正确的缓存设置,以便在每次部署后使所有用户的网站保持最新状态。
缓存在后台如何工作?
浏览器为了提高性能,向服务器请求资源时,都尽量多从本地缓存获取,尽量少从服务器获取。
具体行为我们可以通过指令来控制,通过设置 HTTP 响应头来实现。
缓存处理相关的最常用指令包括:
- Cache-Control
- Expires
- Etag
- Last-Modified
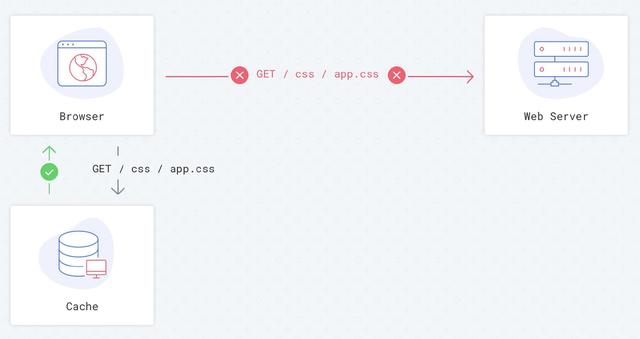
如果没有设置缓存控制指令,浏览器将从服务器获取每个资源,这会增加页面的加载时间。
没有缓存设置的请求流程:
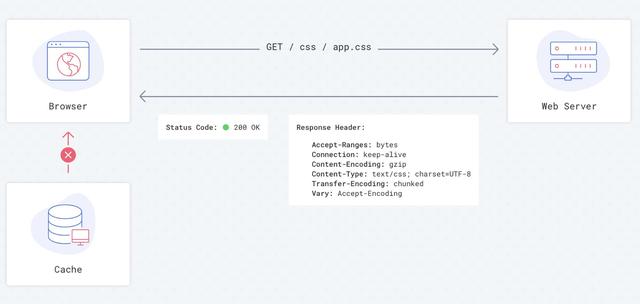
由浏览器决定如何在没有服务器指示的情况下缓存信息。
不同浏览器策略不同,例如 Chrome 和 Safari 每次都从后端下载数据。
为了清楚地定义缓存的处理方式,让我们深入了解一下缓存控制指令。
Etag(实体标签)
Etag 可以让我们在不用下载资源的情况下,就知道服务器上的资源是否变更了。
服务器在给浏览器发送资源文件时(例如 css 文件),会对此资源内容计算出一个 hash 值,作为此文件的 tag,一起发送给浏览器。
浏览器下次请求此资源文件时,先把这个 tag 发给服务器,HTTP header 信息例如:
If-None-Match: W/“1d2e7–1648e509289”服务器和本地文件的 hash 值对比。
如果一样,就告诉浏览器没有变化,可以使用缓存文件,否则浏览器下载新文件。
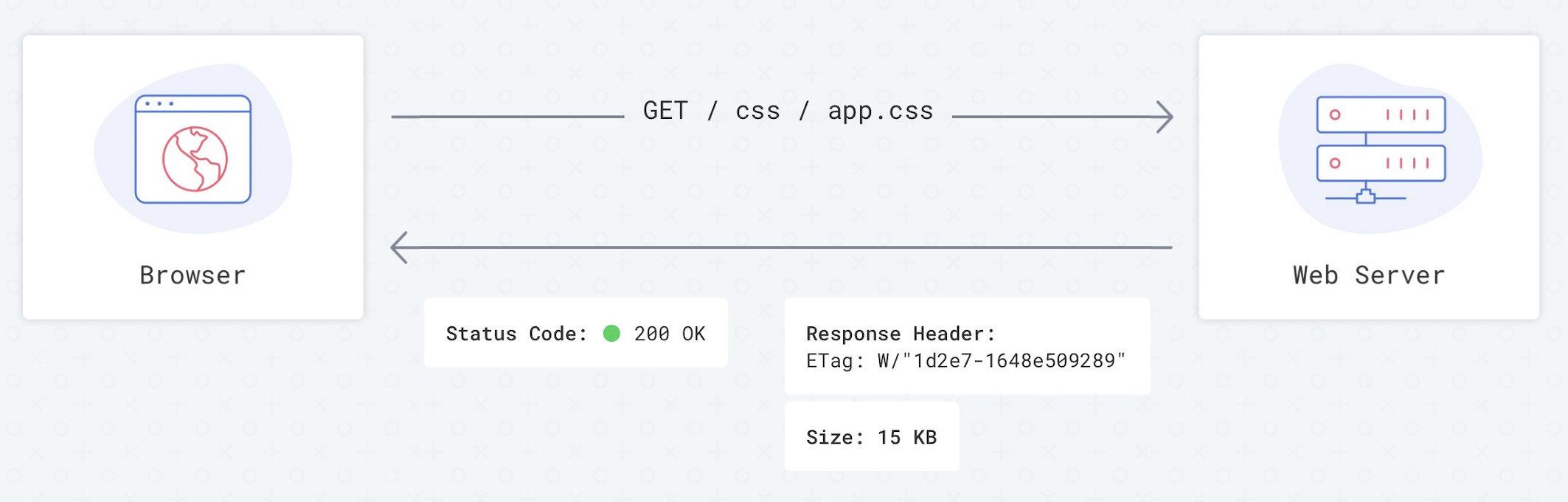
使用Etag请求流-第一次加载:
使用Etag请求流-第二次加载:

启用 Etag 缓存策略后,我们总是会去服务器检查文件的哈希值,然后浏览器才会决定从缓存中提取文件或将其完全加载。
如果未修改,则无论您要请求的是10KB还是10MB的文件,只需80–100字节即可进行验证。
Last Modified
服务器有每个文件的最后修改时间戳,在第一次文件加载之后,客户端会向服务器询问此文件在某时间之后是否更改过。
HTTP header 信息例如:
If-Modified-Since: Fri, 13 Jul 2018 10:49:23 GMT如果改了,就下载新文件,否则使用缓存。
看着挺好,但现实情况并不一定是这样的,“Last-Modified” 是一个弱缓存头信息,浏览器有自己的缓存策略,会自行决定是否从缓存中获取资源或下载新文件,不同浏览器处理方式也不一样。
使用 Last-Modified 的请求流程 - 第一次加载:

使用 Last-Modified 的请求流程 - 第二次加载(完美情况):
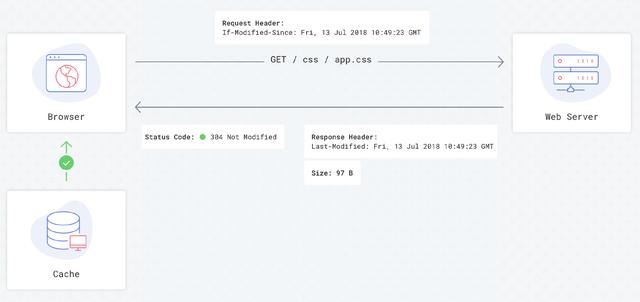
使用 Last-Modified 的请求流程 - 第二次加载(通常情况):
所以,“Last-Modified” 是不可靠的,我宁愿完全不使用他。
Cache-Control max-age
这个指令告诉浏览器此文件在本地缓存多长时间。
以秒为单位,形式为:
Cache-Control: max-age=31536000使用此策略后,浏览器完全不用向服务器发起请求了,直接使用本地缓存,非常快。
但是,没有办法确保这段时间内服务器中的文件不会修改。
因此,为了让浏览器下载最新的文件,我们可以使用一些构建工具,例如 Webpack、Gulp。
每个文件都在服务器中进行预编译,对文件内容进行 hash 计算,把 hash 值添加到文件名中,例如 “app-72420c47cc.css”。
这样,文件内容的变化就可以反应在文件名上,对浏览器来讲就是一个新的文件,旧文件的缓存也就没有了,会从服务器上获取新的。
这个方法适用于 CSS JS 和图片文件。
no-cache
no-cache(无缓存)不意味着根本没有缓存,它只是告诉浏览器在使用缓存之前先验证服务器上的资源。
需要与 Etag 一起使用,因此浏览器将发送一个简单请求并加载额外的80个字节以验证文件的状态。
对于 HTML 文件,就需要使用 “no-cache”。
最终方案
使用 Gulp,Webpack 这类工具将唯一的哈希值添加到 css,js 和图像文件(如app-67ce7f3483.css)。
对于 js,css 和图像文件,设置 Cache-Control:public,max-age = 31536000,不设置 Etag 和 Last-Modified。
对于 HTML 文件,设置 Cache-Control: no-cache 和 Etag。
翻译整理自:
https://medium.com/pixelpoint/best-practices-for-cache-control-settings-for-your-website-ff262b38c5a20